Introduktion
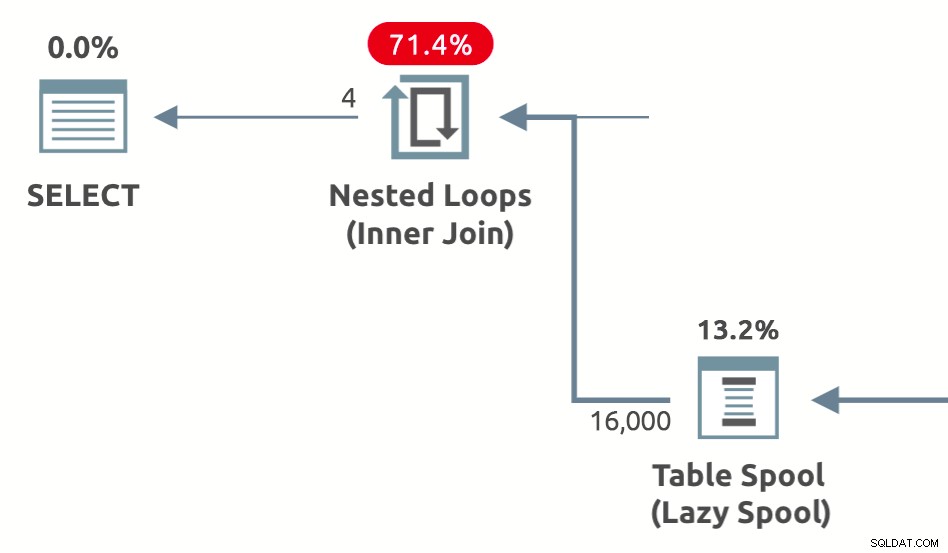
Ydeevnespoler er dovne spoler tilføjet af optimeringsværktøjet for at reducere de estimerede omkostninger på indersiden af indlejrede loops joins . De findes i tre varianter:Lazy Table Spool , Dovne indeksspole , og Lazy Row Count Spool . Et eksempel på en planform, der viser en doven bord-ydelsesspole er nedenfor:
De spørgsmål, jeg satte mig for at besvare i denne artikel, er hvorfor, hvordan og hvornår forespørgselsoptimeringsværktøjet introducerer hver type præstationsspool.
Lige før vi går i gang, vil jeg understrege en vigtig pointe:Der er to forskellige typer indlejrede løkkesammenføjninger i udførelsesplaner. Jeg vil referere til sorten med ydre referencer som en ansøgning , og typen med et join-prædikat på selve join-operatøren som en indlejret loops join . For at være klar handler denne forskel om udførelsesplanoperatører , ikke T-SQL-forespørgselssyntaks. For flere detaljer, se venligst min linkede artikel.
Performancespools
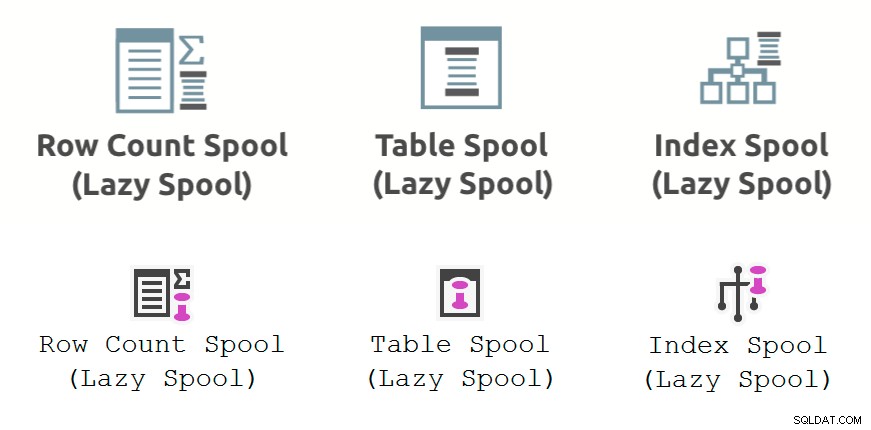
Billedet nedenfor viser ydelsesspolen udførelsesplanoperatører som vist i Plan Explorer (øverste række) og SSMS 18.3 (nederste række):
Generelle bemærkninger
Alle ydelsesspoler er dovne . Spolens arbejdsbord fyldes gradvist, en række ad gangen, efterhånden som rækker strømmer gennem spolen. (Ivrige spoler bruger derimod alt input fra deres underordnede operatør, før de returnerer nogen rækker til deres forælder).
Præstationsspoler vises altid på indersiden (det nederste input i grafiske udførelsesplaner) af en indlejret sløjfe forbinder eller anvender operator. Den generelle idé er at cache og afspille resultater, så gentagne afviklinger af interne operatører gemmes, hvor det er muligt.
Når en spool er i stand til at genafspille cachelagrede resultater, er dette kendt som en tilbagespoling . Når spoolen skal udføre sine underordnede operatører for at opnå korrekte data, vises en genbinding forekommer.
Du kan finde det nyttigt at tænke på en spool rebind som en cache-miss og en tilbagespoling som et cache-hit.
Lazy Table Spool
Denne type performance spool kan bruges med både apply og indlejrede løkker slutter sig til .
Ansøg
En genbinding (cache miss) forekommer hver gang en ydre reference værdiændringer. En doven bordspole binder sig igen ved at trunkere dens arbejdstabel og genudfylder den fuldstændigt fra dens underordnede operatører.
En spol tilbage (cache hit) opstår, når indersiden udføres med samme ydre referenceværdier som umiddelbart foregående loop iteration. En tilbagespoling afspiller cachelagrede resultater fra spolens arbejdsbord, hvilket sparer omkostningerne ved at genudføre planoperatørerne under spolen.
Bemærk:En lazy table spool cacherer kun resultater for ét sæt anvend ydre reference værdier ad gangen.
Indlejrede løkker slutter sig til
Den dovne bordspole udfyldes én gang under den første loop-iteration. Spolen spoler sit indhold tilbage for hver efterfølgende iteration af sammenføjningen. Med indlejrede loops-sammenføjninger er indersiden af sammenføjningen et statisk sæt rækker, fordi sammenføjningsprædikatet er på selve sammenføjningen. Det statiske rækkesæt på indersiden kan derfor cachelagres og genbruges flere gange via spolen. En indlejret sløjfe-joint performance spool genbinder aldrig.
Lazy Row Count Spool
En rækketællerspole er lidt mere end en bordspole uden kolonner. Den cacherer eksistensen af en række, men projicerer ingen kolonnedata. Bortset fra at bemærke dets eksistens og nævne at det kan være en indikation af en fejl i kildeforespørgslen, vil jeg ikke have mere at sige om rækketællerspoler.
Fra dette tidspunkt fremad, når du ser "bordspole" i teksten, bedes du læse det som "tabel (eller rækkeantal) spole", fordi de er så ens.
Lazy Index Spool
Dovne indeksspole operatør er kun tilgængelig med anvende .
Indeksspolen vedligeholder en arbejdstabel, der ikke afkortes når ydre reference værdier ændres. I stedet tilføjes nye data til den eksisterende cache, indekseret af de ydre referenceværdier. En doven indeksspole adskiller sig fra en doven bordspole ved, at den kan afspille resultater fra enhver tidligere loop iteration, ikke kun den seneste.
Det næste trin i at forstå, hvornår præstationsspooler optræder i udførelsesplaner, kræver at man forstår lidt om, hvordan optimizeren fungerer.
Optimeringsbaggrund
En kildeforespørgsel konverteres til en logisk trærepræsentation ved parsing, algebrisering, forenkling og normalisering. Når det resulterende træ ikke kvalificerer sig til en triviel plan, leder den omkostningsbaserede optimering efter logiske alternativer, der garanteret vil give de samme resultater, men til en lavere estimeret pris.
Når optimizeren har genereret potentielle alternativer, implementerer den hver enkelt ved hjælp af passende fysiske operatører og beregner estimerede omkostninger. Den endelige udførelsesplan er bygget ud fra den laveste omkostningsmulighed fundet for hver operatørgruppe. Du kan læse flere detaljer om processen i min Query Optimizer Deep Dive-serie.
De generelle betingelser, der er nødvendige for, at en præstationsspool vises i optimeringsprogrammets endelige plan, er:
- Optimeringsværktøjet skal udforske et logisk alternativ, der inkluderer en logisk spool i en genereret erstatning. Dette er mere komplekst, end det lyder, så jeg vil pakke detaljerne ud i næste hovedafsnit.
- Den logiske spool skal være implementerbar som en fysisk spole operatør i udførelsesmotoren. For moderne versioner af SQL Server betyder dette i det væsentlige, at alle nøglekolonner i en indeksspool skal være sammenlignelige type, ikke mere end 900 bytes* i alt, med 64 nøglekolonner eller færre.
- De bedste komplet plan efter omkostningsbaseret optimering skal indeholde et af spolealternativerne. Med andre ord skal ethvert omkostningsbaseret valg mellem spole- og ikke-spole-optioner komme ud til fordel for spole.
* Denne værdi er hårdkodet i SQL Server og er ikke blevet ændret efter stigningen til 1700 bytes for ikke-klyngede indeksnøgler fra SQL Server 2016 og frem. Dette skyldes, at spoolindekset er et clusteret indeks, ikke et ikke-klynget indeks.
Optimeringsregler
Vi kan ikke specificere en spool ved hjælp af T-SQL, så at få en i en eksekveringsplan betyder, at optimizeren skal vælge at tilføje den. Som et første trin betyder dette, at optimeringsværktøjet skal inkludere en logisk spool i et af de alternativer, den vælger at udforske.
Optimeringsværktøjet anvender ikke udtømmende alle de logiske ækvivalensregler, den kender, på hvert forespørgselstræ. Dette ville være spild i betragtning af optimizerens mål om hurtigt at producere en rimelig plan. Der er flere aspekter af dette. Først fortsætter optimeringsværktøjet i etaper, hvor billigere og oftere gældende regler prøves først. Hvis en rimelig plan findes på et tidligt stadium, eller forespørgslen ikke kvalificerer sig til senere faser, kan optimeringsindsatsen afsluttes tidligt med den laveste omkostningsplan, der er fundet hidtil. Denne strategi hjælper med at forhindre, at du bruger mere tid på optimering, end der spares ved trinvise omkostningsforbedringer.
Regelmatching
Hver logisk operator i forespørgselstræet kontrolleres hurtigt for et mønstermatch i forhold til de tilgængelige regler i det aktuelle optimeringstrin. For eksempel vil hver regel kun matche en delmængde af logiske operatorer og kan også kræve, at specifikke egenskaber er på plads, såsom garanteret sorteret input. En regel kan matche en individuel logisk operation (en enkelt gruppe) eller flere sammenhængende grupper (et underafsnit af planen).
Når den er matchet, bliver en kandidatregel bedt om at generere en løfteværdi . Dette er et tal, der repræsenterer, hvor sandsynligt det er, at den nuværende regel giver et nyttigt resultat, givet den lokale kontekst. For eksempel kan en regel generere en højere løfteværdi, når målet har mange dubletter på sit input, et stort estimeret antal rækker, garanteret sorteret input eller en anden ønskværdig egenskab.
Når lovende udforskningsregler er blevet identificeret, sorterer optimeringsværktøjet dem i løfteværdirækkefølge og begynder at bede dem om at generere nye logiske erstatninger. Hver regel kan generere en eller flere erstatninger, som senere vil blive implementeret ved hjælp af fysiske operatører. Som en del af den proces beregnes en estimeret omkostning.
Pointen med alt dette, som det gælder for præstationsspoler, er, at den logiske planform og egenskaber skal være befordrende for at matche spool-kompatible regler, og den lokale kontekst skal producere en høj nok løfteværdi til, at optimizeren vælger at generere erstatninger ved hjælp af reglen .
Spoolregler
Der er en række regler, der udforsker logiske indlejrede sløjfer join eller ansøg alternativer. Nogle af disse regler kan producere en eller flere erstatninger med en bestemt type præstationsspole. Andre regler, der matcher indlejrede sløjfer, forbinder eller anvender, genererer aldrig et spool-alternativ.
For eksempel reglen ApplyToNL implementerer en logisk anvend som en fysisk sløjfer sammen med ydre referencer. Denne regel kan generere flere alternativer hver gang den kører. Ud over den fysiske join-operatør kan hver erstatning indeholde en doven bordspole, en doven indeksspole eller slet ingen spole. De logiske spoolerstatninger implementeres senere individuelt og beregnes som de korrekt indtastede fysiske spooler, efter en anden regel kaldet BuildSpool .
Som et andet eksempel er reglen JNtoIdxLookup implementerer en logisk joinforbindelse som en fysisk anvend , med en indekssøgning umiddelbart på indersiden. Denne regel aldrig genererer et alternativ med en spolekomponent. JNtoIdxLookup evalueres tidligt og returnerer en høj løfteværdi, når den matcher, så simple indeksopslagsplaner findes hurtigt.
Når optimeringsværktøjet finder et billigt alternativ som dette tidligt, kan mere komplekse alternativer aggressivt beskæres eller springes helt over. Begrundelsen er, at det ikke giver mening at forfølge muligheder, der er usandsynligt at forbedre på et lavpris alternativ, der allerede er fundet. Ligeledes er det ikke værd at udforske yderligere, hvis den nuværende bedste komplette plan allerede har en lav nok totalomkostning.
Et tredje regeleksempel:Reglen JNtoNL ligner ApplyToNL , men den implementerer kun fysisk indlejret løkke join , med enten en doven bordspole, eller slet ingen spole. Denne regel aldrig genererer en indeksspool, fordi den type spool kræver en application.
Spoolgenerering og -omkostningsberegning
En regel, der er egnet at generere en logisk spole vil ikke nødvendigvis gøre det, hver gang det bliver kaldt. Det ville være spild at generere logiske alternativer, der næsten ikke har nogen chance for at blive valgt som billigste. Der er også en omkostning ved at generere nye alternativer, som igen kan producere endnu flere alternativer - som hver især kan have behov for implementering og omkostningsberegning.
For at administrere dette implementerer optimeringsværktøjet fælles logik for alle spool-kompatible regler for at bestemme, hvilke typer spool-alternativer, der skal genereres baseret på lokalplanbetingelser.
Indlejrede løkker slutter sig til
For en indlejret sløjfer join , chancen for at få en doven bordspole stiger i takt med:
- Det estimerede antal rækker på det ydre input af joinforbindelsen.
- De estimerede omkostninger af indvendige planoperatører.
Omkostningerne til spolen betales tilbage af besparelser ved at undgå operatørudførelser på indersiden. Besparelserne stiger med flere indre iterationer og højere omkostninger på den indre side. Dette er især sandt, fordi omkostningsmodellen tildeler relativt lave I/O- og CPU-omkostningstal til tilbagespoling af bordspoler (cache-hits). Husk, at en bordspole på en indlejret sløjfeforbindelse kun oplever tilbagespoling, fordi manglen på parametre betyder, at datasættet på indersiden er statisk.
En spool kan lagre data tættere end de operatører, der fodrer det. For eksempel kan et basistabel-klyngeindeks gemme 100 rækker pr. side i gennemsnit. Lad os sige, at en forespørgsel kun behøver en enkelt heltalskolonneværdi fra hver brede klyngede indeksrække. Lagring af kun heltalsværdien i spool-arbejdsbordet betyder, at der kan gemmes mere end 800 sådanne rækker pr. side. Dette er vigtigt, fordi optimeringsværktøjet vurderer omkostningerne ved bordspolen delvist ved hjælp af et estimat af antallet af arbejdsbordssider havde brug for. Andre omkostningsfaktorer inkluderer CPU-omkostningerne pr. række, der er involveret i at skrive og læse spoolen, over det estimerede antal loop-iterationer.
Optimizeren er uden tvivl lidt for opsat på at tilføje dovne bordspoler til indersiden af en indlejret løkkesammenføjning. Ikke desto mindre giver optimizerens beslutning altid mening i forhold til estimerede omkostninger. Jeg betragter personligt indlejrede løkker som høj risiko , fordi de hurtigt kan blive langsomme, hvis enten join-input-kardinalitetsestimatet er for lavt.
En bordspole kan hjælpe med at reducere omkostningerne, men det kan ikke helt skjule den værst tænkelige ydeevne af en naiv indlejret loops join. En indekseret appliceringsforbindelse er normalt at foretrække og mere modstandsdygtig over for estimeringsfejl. Det er også en god idé at skrive forespørgsler, som optimeringsværktøjet kan implementere med hash eller merge join, når det er relevant.
Anvend Lazy Table Spool
For en ansøg , chancerne for at få en doven bordspole stige med det estimerede antal duplikater forbinde nøgleværdier på det ydre input af applikationen. Med flere dubletter er der en statistisk større chance for, at spolen spole sine aktuelt gemte resultater tilbage ved hver iteration. En påføringsdoven bordspole med en lavere estimeret pris har en bedre chance for at være med i den endelige udførelsesplan.
Når rækkerne, der ankommer på det anvende ydre input, ikke har nogen særlig rækkefølge, foretager optimeringsværktøjet en statistisk vurdering af hvor sandsynligt, at hver iteration vil resultere i en billig tilbagespoling eller en dyr genbinding. Denne vurdering bruger data fra histogramtrin, når de er tilgængelige, men selv dette bedste scenario er mere et kvalificeret gæt. Uden en garanti er rækkefølgen af rækker, der ankommer på det anvendte ydre input, uforudsigelig.
De samme optimeringsregler, der genererer logiske spool-alternativer, kan også angiv, at anvende-operatøren kræver sorterede rækker på dens ydre indgang. Dette maksimerer dovne spole tilbagespoling fordi alle dubletter garanteres at blive stødt på i en blok. Når ydre inputsorteringsrækkefølge er garanteret, enten ved bevaret rækkefølge eller en eksplicit Sortering , er prisen på spolen meget reduceret. Optimeringsværktøjet har indflydelse på sorteringsrækkefølgens indvirkning på antallet af spoletilbage- og genbindinger.
Planer med en Sortering på det ydre input og en Lazy Table Spool på det indre input er ret almindelige. Den ydre-sidesorteringsoptimering kan stadig ende med at være kontraproduktiv. Dette kan f.eks. ske, når estimatet for ydersidekardinalitet er så lavt, at sorteringen ender med at spilde til tempdb .
Anvend Lazy Index Spool
For en ansøg , får en doven indeksspole alternativ afhænger af planens form såvel som omkostninger.
Optimeringsværktøjet kræver:
- Nogle duplikater forbinde værdier på det ydre input.
- En lighed join-prædikat (eller en logisk ækvivalent, som optimeringsværktøjet forstår, såsom
x <= y AND x >= y). - En garanti at de ydre referencer er unikke under den foreslåede dovne indeksspole.
I udførelsesplaner er den påkrævede unikhed ofte tilvejebragt af en samlet gruppering af de ydre referencer eller et skalært aggregat (en uden gruppe efter). Unikhed kan også tilvejebringes på andre måder, f.eks. ved at der findes et unikt indeks eller en begrænsning.
Et legetøjseksempel, der viser planformen, er nedenfor:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
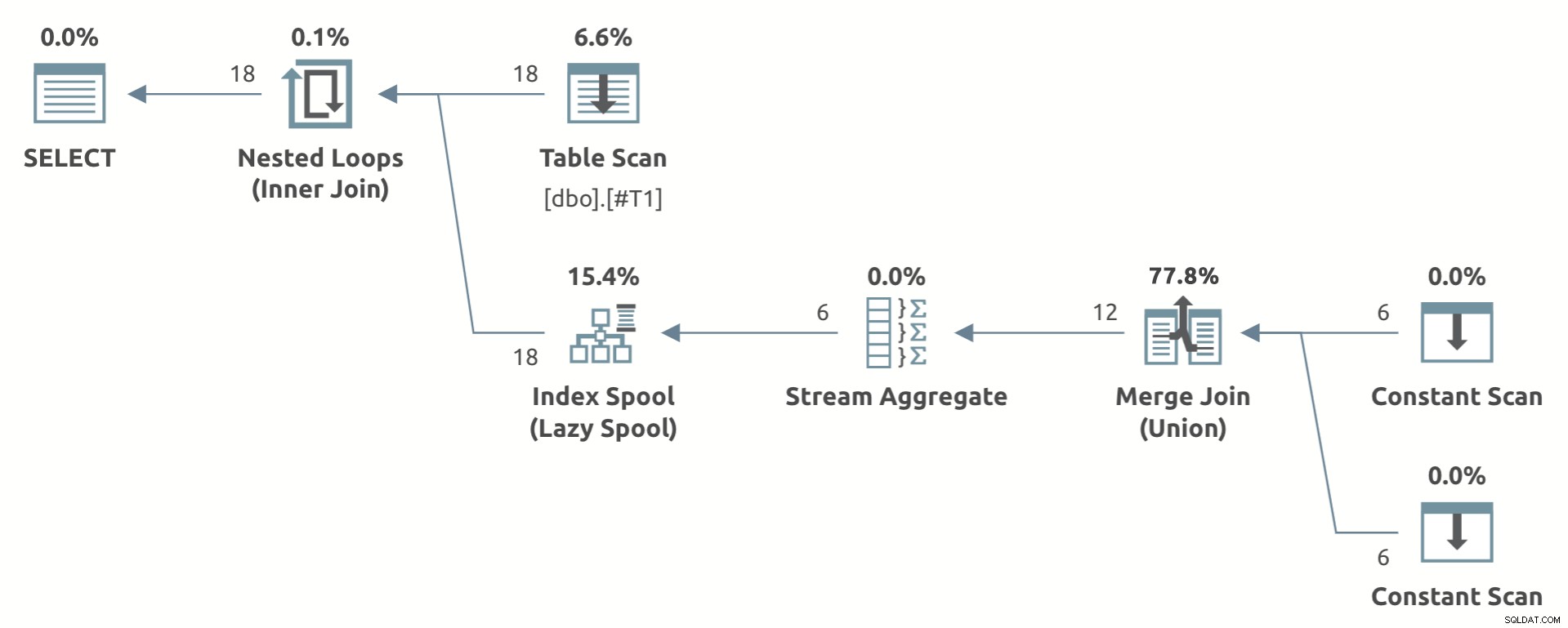
Læg mærke til Strømaggregatet under Dovne indeksspole .
Hvis planformkravene er opfyldt, vil optimeringsværktøjet ofte generere et dovent indeksalternativ (med forbehold for de tidligere nævnte forbehold). Hvorvidt den endelige plan indeholder en doven indeksspole eller ej, afhænger af omkostningerne.
Indeks-spool versus Table Spool
Antallet af estimerede tilbagespolinger og genbinder for en doven indeksspole er det samme som for en doven bordspole uden sorteret anvende ydre input.
Dette kan virke som en ret uheldig situation. Den primære fordel ved en indeksspool er, at den cacher alle tidligere sete resultater. Dette burde få indeksspoolen til at spole tilbage mere sandsynligt end for en bordspole (uden sortering af ydre input) under samme omstændigheder. Min forståelse er, at denne særhed eksisterer, fordi uden den ville optimeringsværktøjet vælge en indeksspole alt for ofte.
Uanset hvad justerer omkostningsmodellen for ovenstående til en vis grad ved at bruge forskellige indledende og efterfølgende række I/O- og CPU-omkostningstal for indeks- og tabelspoler. Nettoeffekten er, at en indeksspole normalt koster lavere end en bordspole uden sorteret ydre input, men husk de restriktive krav til planform, som gør dovne indeksspoler relativt sjælden.
Alligevel er den primære omkostningskonkurrent til et dovenspoleindeks en bordspole med sorteret ydre input. Intuitionen for dette er ret ligetil:Sorteret ydre input betyder, at bordspolen er garanteret at se alle duplikerede ydre referencer sekventielt. Det betyder, at den vil genbinde kun én gang pr. særskilt værdi, og spol tilbage for alle dubletter. Dette er det samme som den forventede opførsel af en indeksspool (logisk set i det mindste).
I praksis er en indeksspool mere tilbøjelig til at blive foretrukket frem for en sorteringsoptimeret tabelspool for færre duplikatanvendelsesnøgleværdier. At have færre dubletter af nøgler reducerer tilbagespoling fordel ved den sorteringsoptimerede bordspole sammenlignet med de "uheldige" indeksspoolestimater, der er nævnt tidligere.
Indeksspole-muligheden er også fordelagtig som den estimerede pris for en bordspole udvendig Sortér stiger. Dette vil oftest være forbundet med flere (eller bredere) rækker på det tidspunkt i planen.
Spor flag og hints
-
Performance spools kan deaktiveres med let dokumenteret sporingsflag 8690 , eller det dokumenterede forespørgselstip
NO_PERFORMANCE_SPOOLpå SQL Server 2016 eller nyere. -
Udokumenteret sporingsflag 8691 kan bruges (på et testsystem) til altid at tilføje en præstationsspool når det er muligt. typen af doven spole du får (rækkeantal, tabel eller indeks) kan ikke tvinges; det afhænger stadig af omkostningsestimat.
-
Udokumenteret sporingsflag 2363 kan bruges sammen med den nye kardinalitetsestimatmodel for at se udledningen af det distinkte estimat på det ydre input til en anvende, og kardinalitetsestimat generelt.
-
Udokumenteret sporingsflag 9198 kan bruges til at deaktivere lazy index performance spools specifikt. Du kan stadig få en doven tabel eller rækketællerspole i stedet (med eller uden sorteringsoptimering), afhængigt af omkostningerne.
-
Udokumenteret sporingsflag 2387 kan bruges til at reducere CPU-omkostningerne af læserækker fra en doven indeksspole . Dette flag påvirker generelle CPU-omkostningsestimater for at læse en række rækker fra et b-træ. Dette flag har en tendens til at gøre valg af indeksspool mere sandsynligt af omkostningsmæssige årsager.
Andre sporingsflag og metoder til at bestemme, hvilke optimeringsregler, der blev aktiveret under forespørgselskompilering, kan findes i min Query Optimizer Deep Dive-serie.
Sidste tanker
Der er rigtig mange interne detaljer, der påvirker, om den endelige udførelsesplan bruger en præstationsspole eller ej. Jeg har forsøgt at dække de vigtigste overvejelser i denne artikel, uden at komme for langt ind i de ekstremt indviklede detaljer i spool-operatørens omkostningsformler. Forhåbentlig er der nok generelle råd her til at hjælpe dig med at bestemme mulige årsager til en bestemt præstationsspoletype i en udførelsesplan (eller mangel på samme).
Performance spools får ofte en dårlig rap, synes jeg det er rimeligt at sige. Noget af dette er uden tvivl fortjent. Mange af jer vil have set en demo, hvor en plan udføres hurtigere uden en "performance spool" end med. Til en vis grad er det ikke uventet. Der findes kantsager, omkostningsmodellen er ikke perfekt, og uden tvivl har demoer ofte planer med dårlige kardinalitetsestimater eller andre optimeringsbegrænsende problemer.
Når det er sagt, ville jeg nogle gange ønske, at SQL Server ville give en form for advarsel eller anden feedback, når den tyer til at tilføje en doven bordspole til en indlejret loops join (eller en ansøgning uden et brugt understøttende indre sideindeks). Som nævnt i hovedteksten, er det de situationer, jeg oftest oplever, at det går slemt galt, når kardinalitetsestimaterne viser sig at være forfærdeligt lave.
Måske en dag vil forespørgselsoptimeringsværktøjet tage højde for et eller andet risikobegreb for at planlægge valg eller give mere "tilpassede" muligheder. I mellemtiden kan det betale sig at understøtte dine indlejrede loops joins med nyttige indekser, og at undgå at skrive forespørgsler, der kun kan implementeres ved hjælp af indlejrede loops, hvor det er muligt. Jeg generaliserer selvfølgelig, men optimizeren har en tendens til at klare sig bedre, når den har flere valgmuligheder, et fornuftigt skema, gode metadata og håndterbare T-SQL-sætninger at arbejde med. Ligesom jeg kommer til at tænke på det.
Andre spoolartikler
Ikke-ydeevne spools bruges til mange formål i SQL Server, herunder:
- Halloween-beskyttelse
- Nogle vinduesfunktioner i rækketilstand
- Beregning af flere aggregater
- Optimering af udsagn, der ændrer data