Denne artikel taler om automatisering af behandlingen af Analysis Services-databasen i SQL Server. Automatisering er en af de vigtigste opgaver, der administreres af databaseadministratorer eller DevOps-ingeniører.
Derudover får vi et overblik over Analysis Services-databaser, og hvordan de adskiller sig fra SQL Server-databaser.
Denne artikel fremhæver også vigtigheden af at automatisere opgaver i SQL Server for at minimere fejlene og maksimere produktiviteten, især når du arbejder med komplekse scenarier som data warehouse business intelligence-løsninger.
Om Analysis Services-databaser
Lad os tage et kig på Analysis Services-databaser, så vi kan forstå vigtigheden af at automatisere dens behandling i forbindelse med data warehouse business intelligence-løsninger og komplekse dataanalysescenarier.
Hvad er en analyseservicedatabase?
En Analysis Services-database er en meget optimeret database til analyse og rapportering, som ofte er udarbejdet og opdateret som en del af datawarehouse business intelligence-løsninger.
Hvordan Analysis Services-databaser er forskellige fra SQL Server-databaser
En Analysis Services-database er forskellig fra en SQL Server-database, fordi den fungerer på et andet sprog (DAX/MDX) og tilbyder mange indbyggede business intelligence-funktioner til analyse og rapportering sammen med funktioner som datamining og tidsintelligens.
Hvor mange typer analyseservicedatabaser findes der
De to hovedtyper af Analysis Services-databaser er som følger:
- Multidimensional tilstand (Cube)
- Tabeltilstand (datamodel)
Så en Analysis Services-database er enten en implementeret kube eller en implementeret datamodel. Men i begge former betjener den anmodninger, der spænder fra simple til komplekse dataanalysescenarier og gør det muligt at bygge rapporter ovenpå det.
Hvad er SQL Server Analysis Services (SSAS)
SQL Server Analysis Services også kendt som SSAS er en Microsoft-serverinstans, som tillader hosting af Analysis Services-databaser.
Hvad er en Analysis Services-database i et datavarehus
En analyseservicedatabase i forbindelse med datavarehus er ofte et slutprodukt, som kan eksponeres for forretningsbrugere til selvbetjeningsrapportering og realtidsanalyse.
Med enkle ord, når først data, der gennemgår forskellige transformationer og stadier i et datavarehus, når Analysis Services-databasen, anses de for at være klar til analyse og rapportering.
Hvad betyder behandling af en analyseservicedatabase?
Behandling af en Analysis Services-database betyder at kontrollere kilderne for nye data, indlæse den til databasen. Analysis Services-databaser skal opdateres med tiden, da den eller de kilder, de henter data fra, ofte får nye data.
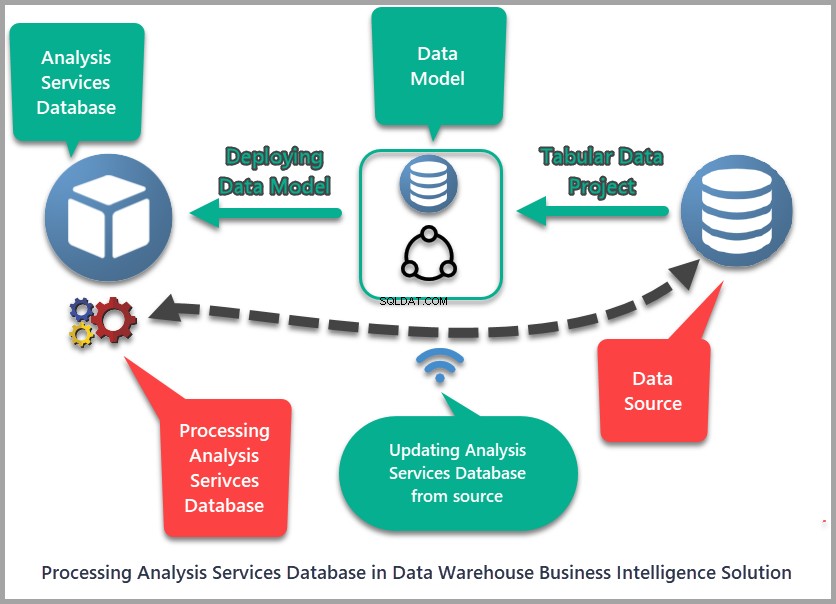
Hvorfor skal vi automatisere behandlingen af analyseservicedatabaser
Det næste vigtige spørgsmål, man kan stille, er dette:hvorfor skal vi automatisere behandlingen af en Analysis Services-database, hvis vi nemt kan køre den manuelt?
Det enkle svar er, at vi skal sikre, at Analysis Services-databasen er opdateret uden manuel indgriben, hvilket sparer både tid og kræfter – især i forbindelse med en data warehouse business intelligence-løsning, når projektet implementeres på en live server.
Automatisering af Analysis Services-databasebehandlingen
Lad os nu gennemgå de vigtigste trin i at automatisere behandlingen af en Azure Analysis Services-database.
Forudsætninger
Denne artikel antager, at læserne er fortrolige med de grundlæggende begreber for datavarehus-business intelligence-løsninger, herunder implementering af datamodeller til en SQL Analysis-server eller Azure Analysis Services.
Da oprettelse og styring af SQL-databaser og analyseserviceprojekter normalt er et udviklerarbejde, vil vi være fokuseret på bearbejdning og automatisering af behandlingen af Analysis Services-databaser eller SSAS-databaser set fra en DBA- eller DevOps-ingeniørs perspektiv.
Denne artikel forudsætter følgende:
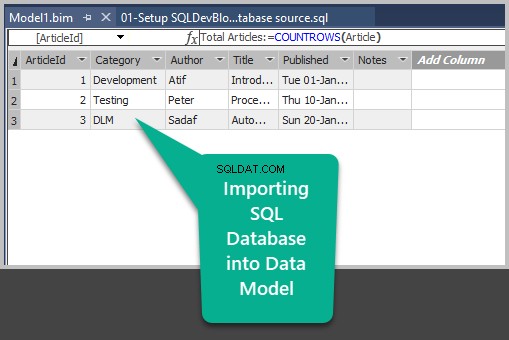
- En eksempeldatabase kaldet SQLDevBlogV5 kilden er allerede konfigureret
- Der er allerede oprettet en tabelformet datamodel, der bruger et Analysis Services-projekt
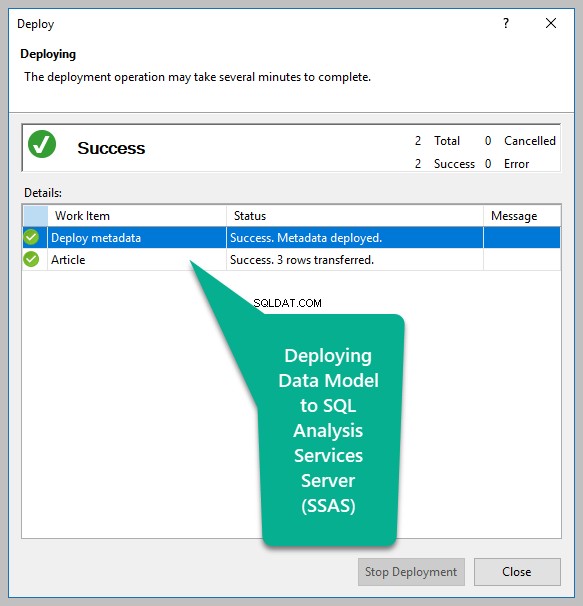
- En Analysis Services-database kaldet SQLDevBlogTabularProject baseret på tabelmodellen er allerede blevet implementeret
Bemærk venligst, at kildedatabasen og en Analysis Services-database, der er nævnt ovenfor, kun er til referenceformål, så du kan ændre disse navne i henhold til dine krav.
Du kan nu hoppe direkte til næste overskrift. Men hvis du ønsker at dække både udvikler- og DBA-perspektivet, kan du udføre de ovennævnte trin ved hjælp af følgende eksempeldatabase:
-- Create the sample database (SQLDevBlogV5) CREATE DATABASE SQLDevBlogV5; GO USE SQLDevBlogV5; -- (1) Create the Article table in the sample database CREATE TABLE Article ( ArticleId INT PRIMARY KEY IDENTITY (1, 1) ,Category VARCHAR(50) ,Author VARCHAR(50) ,Title VARCHAR(150) ,Published DATETIME2 ,Notes VARCHAR(400) ) GO -- (2) Populating the Article table SET IDENTITY_INSERT [dbo].[Article] ON INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (1, N'Development', N'Atif', N'Introduction to SQL Server Analysis Services (SSAS)', N'2019-01-01 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (2, N'Testing', N'Peter', N'Processing SSAS database', N'2019-01-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (3, N'DLM', N'Sadaf', N'Automating Analysis Services Database Processing', N'2019-01-20 00:00:00', NULL) SET IDENTITY_INSERT [dbo].[Article] OFF
Opret derefter en ny Analyseservice tabelprojekt, importer datakilden til modellen og implementer modellen til SSAS-serveren:
Kompatibilitetsniveau
I dette eksempel bruger vi SQL Server 2014 / SQL Server 2012 SP1 (1103) kompatibilitetsniveau for datamodellen. Du kan dog angive et andet kompatibilitetsniveau i henhold til dine krav.
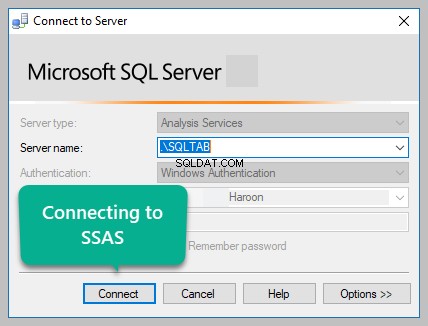
Opret forbindelse til analysetjenester
Åbn SSMS (SQL Server Management Studio) og opret forbindelse til en analyseserver ved at indtaste dine legitimationsoplysninger:
Gå til Analysis Services Database (implementeret)
Når forbindelsen er etableret, skal du udvide Databaserne node i Object Explorer og udvid derefter den implementerede Analysis Services-databaseknude ved at klikke på plus ikon ved siden af:

Behandle Analysis Services-databasen
Højreklik på Analysis Services-databasen, og klik på Process Database:
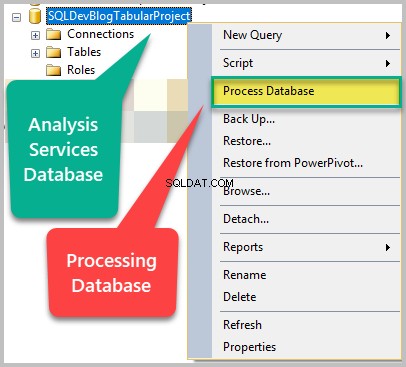
Behold standardbehandlingstilstanden, og klik på OK :
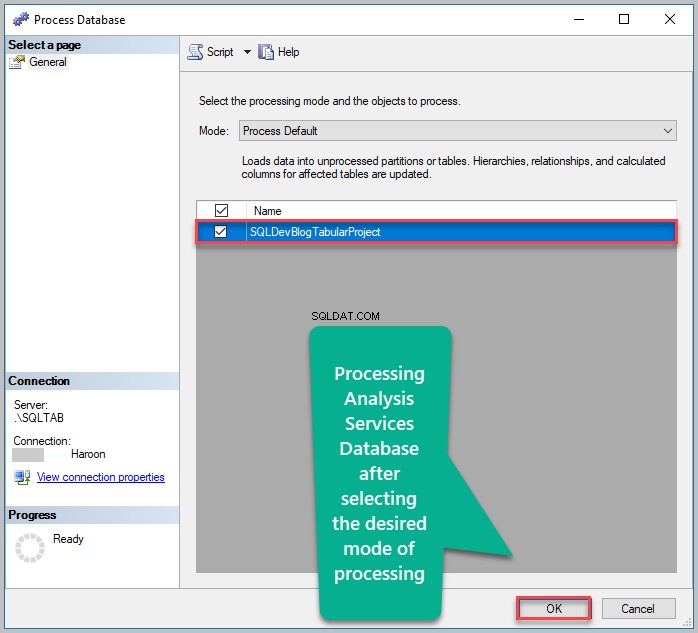
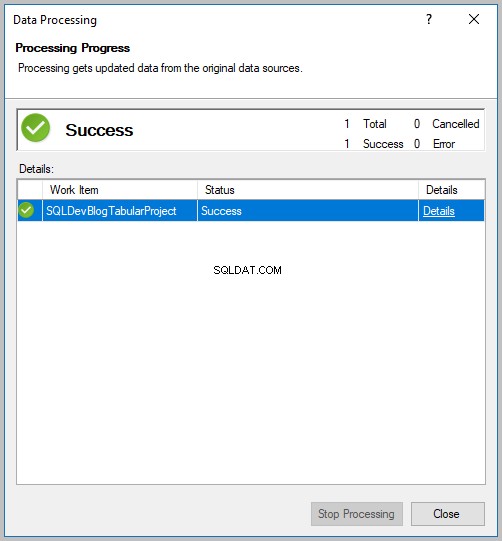
Analysis Services-databasen blev behandlet med succes:
Script til databasebehandlingen
Dernæst skal vi hente det script, der bruges til at behandle Analysis Services-databasen.
En af måderne til at automatisere behandlingen af en Analysis Services-database er at scripte den opgave, der udfører behandlingen, og køre den som et SQL-job (trin) i SQL Server.
Klik på Process Database igen, men tryk ikke på OK denne gang.
I Script rullemenu øverst til venstre i vinduet, klik på Scripthandling til nyt forespørgselsvindue som vist nedenfor:
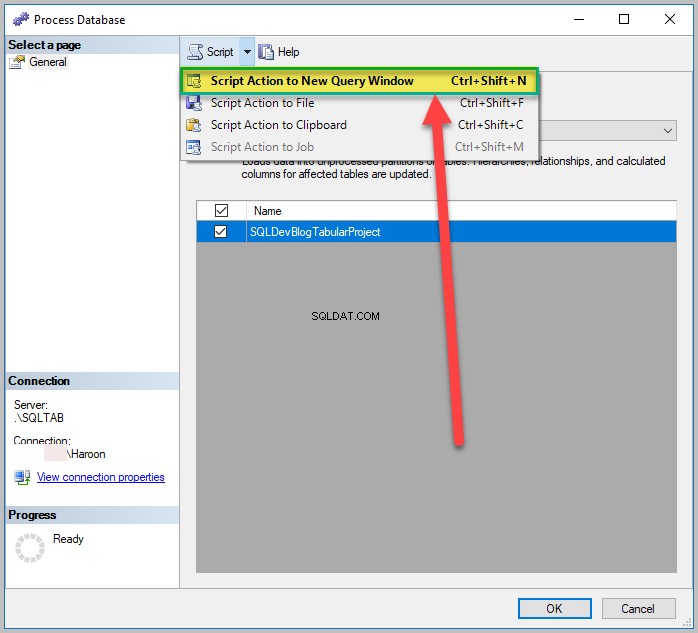
Behandlingsscriptet vil blive åbnet i et nyt vindue kaldet XMLA-forespørgselsvindue :
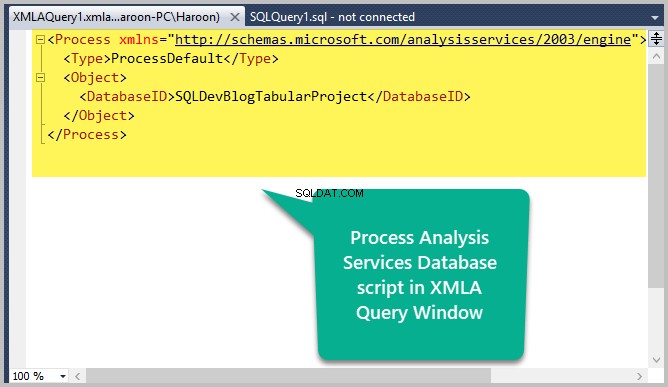
Kør Process Database-scriptet
Tryk på F5 for at køre XMLA-scriptet, som begynder at behandle Analysis Services-databasen:
SQL Server Agent Check
Tilslut nu til SQL-serverens databasemotor, og sørg for, at SQL Server-agenten kører.

Konfigurer SQL Server Agent Access
En anden vigtig ting er at sikre, at den konto, der kører SQL Server Agent, har adgang til Analysis Services-databasen.
I vores tilfælde kører NT Service\SQLAgent-kontoen SQL Server-agent – det betyder, at denne konto skal have tilladelser til at behandle Analysis Services-databasen.
Opret forbindelse til den tabelformede instans for Analysis Services og gå til den ønskede Analysis Services-database. Opret derefter en ny rolle Database Runner ved at tilføje NT Service\SQLAgent konto og give den Procesdatabasen tilladelse:
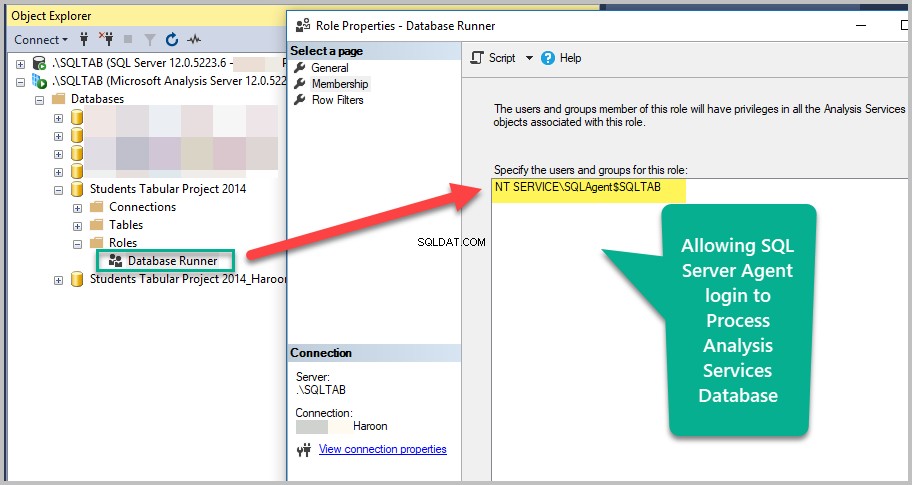
Bemærk venligst, at en af standardmåderne at opnå dette på er at oprette en proxy og kortlægge legitimationsoplysningerne til denne proxy. Detaljerne i denne proces er dog uden for rammerne af denne artikel.
Kopiér XMLA-script for at behandle databasen
Kopier XMLA-scriptet fra SQL Analysis Services XMLA Query Window, som vi brugte til at behandle Analysis Services-databasen.
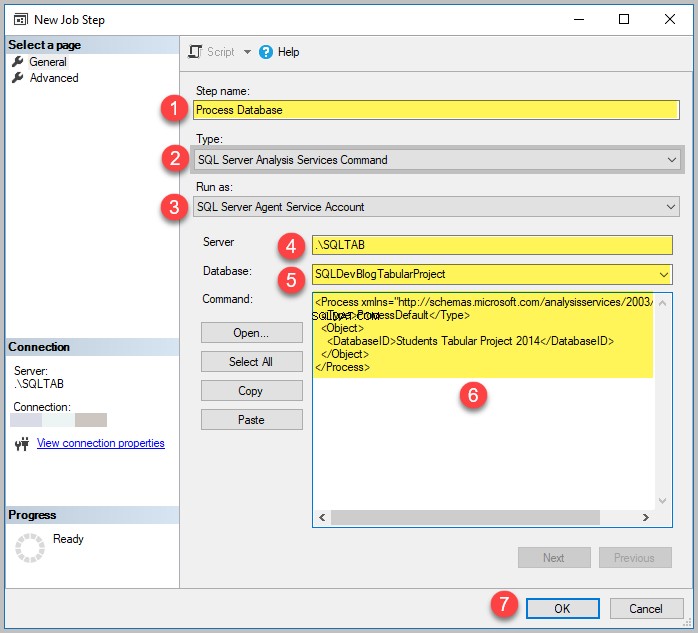
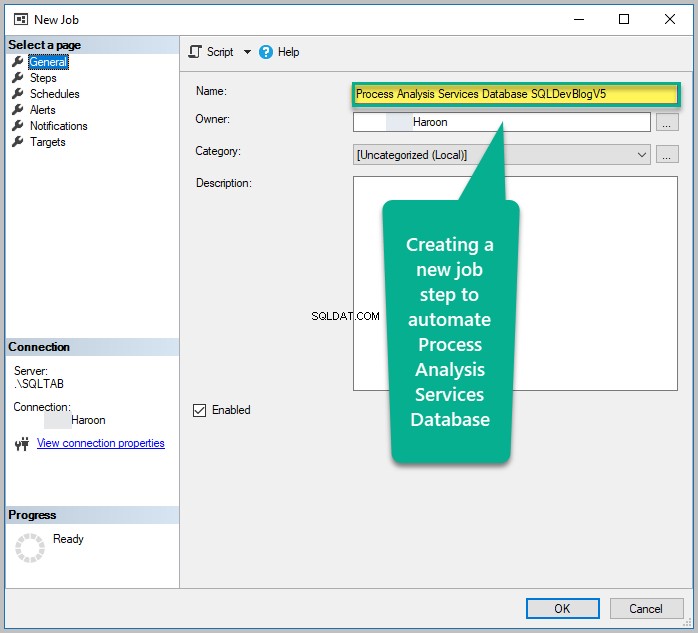
Opret et jobtrin
Gå tilbage til SQL Server Agent og opret et nyt jobtrin som Process Analysis Services Database SQLDevBlogV5.
Opret et nyt trin ved at angive følgende oplysninger og klik på OK :
Husk, at du skal indtaste navnet på din server og database og derefter indsætte scriptet, som du kopierede fra XMLA Query Editor.
Start jobbet
Højreklik på jobbet, og klik på Start job ved trin...
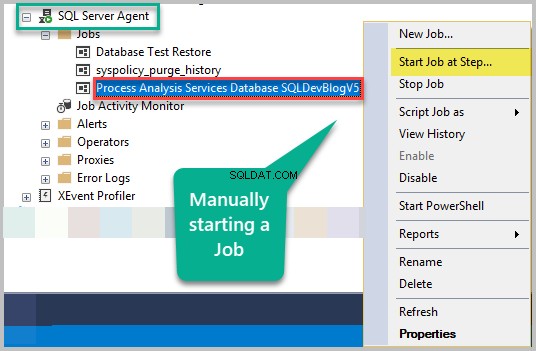
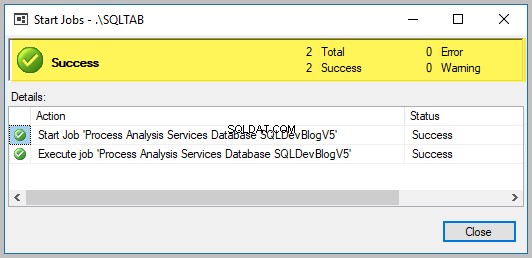
Jobtrinnet kører med succes som vist nedenfor:
Planlæg jobbet til at automatisere behandling
Planlæg derefter jobbet for at automatisere behandlingen af din Analysis Services-database.
Tillykke! Du har med succes automatiseret Analysis Services-databasebehandlingen, hvilket sparer tid og kræfter brugt af en DBA eller en DevOps-ingeniør på at behandle databasen, hver gang data skal opdateres fra kilden.
Ting at gøre
Nu hvor du kan automatisere behandlingen af en Analysis Services-database, prøv venligst følgende ting for at forbedre dine færdigheder yderligere:
- Planlæg Analysis Services-databasebehandlingsjobbet nævnt i denne artikel til at køre dagligt og tilføje flere data til prøven med tiden
- Implementer den komplette løsning ved at gøre følgende:
- Opsæt en eksempeldatabase
- Opret en tabelformet datamodel
- Importer en eksempeldatabase til tabeldatamodellen
- Implementer tabeldatamodellen for at oprette en Analysis Services-database
- Automatiser behandlingen af Analysis Services-databasen ved hjælp af SQL Agent
- Opret forbindelse til Analysis Services-databasen via Excel for at se dataene, efter at Analysis Services-databasen er opdateret automatisk ved hjælp af SQL-jobbet