Artiklen introducerer det grundlæggende i dynamisk datamaskering (DDM) i SQL Server sammen med dens oversigt understøttet af et simpelt eksempel på implementering af datamaskering. Derudover vil læserne blive fortrolige med fordelene ved dynamisk datamaskering. Dette papir fremhæver også vigtigheden af datamaskering i daglige databaseudviklingsopgaver, når nogle felter skal maskeres på grund af deres følsomme natur for at overholde standardpraksis.
Om datamaskering
Lad os gennemgå de grundlæggende begreber for datamaskering og tilgængeligheden af denne funktion i SQL Server.
Simpel definition
Datamaskering er en metode til at skjule data helt eller delvist og derved gøre det svært at genkende eller forstå dataene, efter at maskeringen er blevet anvendt.
Microsoft Definition
Ifølge Microsofts dokumentation begrænser Dynamic data Masking (DDM) eksponering af følsomme data ved at maskere dem til ikke-privilegerede brugere.
Hvad er følsomme data
Med følsomme data mener vi alle data, der indeholder private, personligt identificerbare, økonomiske eller sikkerhedsmæssige oplysninger, som, hvis de afsløres, kan misbruges eller skade en organisations omdømme.
Eksempel på følsomme data
Et godt eksempel på følsomme data er et betalingskortnummer gemt i en database, som skal beskyttes mod enhver uautoriseret brug. Et andet godt eksempel på følsomme data er den personlige e-mailadresse, som nemt kan identificere en person.
Ikke-privilegerede brugere
Enhver databasebruger, der ikke har tilladelse til at se de følsomme data, anses for at være en ikke-privilegeret bruger.
Dynamic Data Masking (DDM)
Datamaskeringsfunktionen, der understøttes af SQL Server, er kendt som dynamisk datamaskering, også omtalt som DDM i Microsoft-dokumentation. Med andre ord henviser Microsoft til datamaskering som dynamisk datamaskering i SQL Server.
Kompatibilitet
Ifølge Microsofts dokumentation understøttes den dynamiske datamaskeringsfunktion af følgende versioner af SQL Server:
1. SQL Server 2016 og nyere versioner
2. Azure SQL-database
3. Azure SQL Data Warehouse
Så hvis du ikke er begyndt at bruge Azure SQL-database(r) endnu, skal du som minimum bruge SQL Server 2016 for at bruge dynamisk datamaskeringsfunktion.
Konfiguration af dynamisk datamaskering
Dynamisk datamaskering kan konfigureres ved blot at bruge T-SQL-kommandoer.
Den dynamiske datamaskeringsimplementering udføres gennem T-SQL-scripting for at forhindre uautoriserede brugere i at se følsomme data.
Fordele ved dynamisk datamaskering
Lad os endelig gennemgå nogle vigtige fordele ved dynamisk datamaskering, men før det vil jeg gerne spørge SQL-begyndere og ikke SQL-professionelle, hvad er fordelene ved integritetsbegrænsninger?
Lad os overveje et eksempel på en unik nøglebegrænsning, der sikrer, at kolonnen, som den anvendes på, har forskellige (ingen duplikerede) værdier. Hvis jeg kan håndhæve særskilte kolonneværdier på tidspunktet for dataindtastning i min front-end-applikation, hvorfor skulle jeg bryde mig om at håndhæve det gennem en database ved at anvende en unik nøglebegrænsning?
Svaret er at sikre reglerne (integritetsbegrænsninger) ) forbliver konsekvente og styres centralt. Jeg er nødt til at gøre det på databaseniveau, ellers bliver jeg måske nødt til at skrive koden for at håndhæve unikke værdier i alle de nuværende og eventuelle kommende applikationer, der får adgang til databasen.
Det samme gælder for dynamisk datamaskering, da den definerer maske på en kolonne på databaseniveau, så der ikke er behov for at udføre yderligere maskering (kode) af de programmer, der får adgang til databasen.
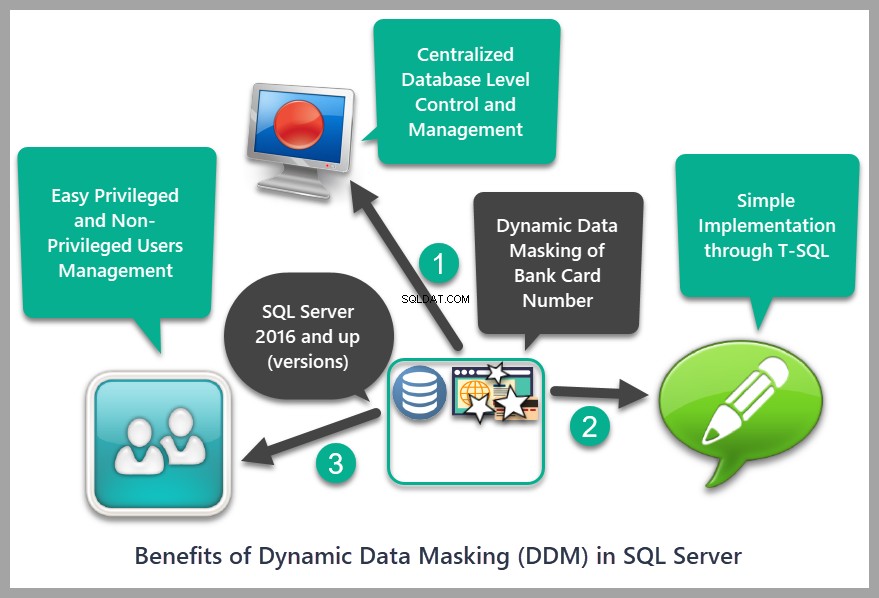
Dynamisk datamaskering har følgende fordele i forhold til traditionelle tilgange:
1. Dynamisk datamaskering implementerer den centraliserede politik med at skjule eller ændre de følsomme data i en database, som er nedarvet af enhver applikation, der ønsker at få adgang til dataene.
2. Dynamisk datamaskering i SQL Server kan hjælpe med at administrere brugere med rettigheder til at se de følsomme data og de brugere, der ikke er autoriseret til at se dem.
3. Det har en simpel implementering i form af T-SQL script.
Implementering af dynamisk datamaskering
Før vi implementerer dynamisk datamaskering, skal vi forstå de typer af dynamisk datamaskering, der kan anvendes på en kolonne i en tabel i en SQL- eller Azure SQL-database.
Typer af datamasker
Der er fire typer datamasker, som vi kan anvende på en kolonne:
1. Standarddatamasker
2. Delvis datamaske
3. Tilfældige datamasker
4. Brugerdefinerede datamasker
I denne artikel vil vi fokusere på standarddatamaskeringstypen.
Anvendelse af dynamiske datamasker
Dynamiske datamasker kan anvendes på en kolonne i en tabel på følgende måder:
1. Når du opretter en ny tabel
2. Ændring af en allerede oprettet tabel for at anvende datamaskering på dens kolonne(r)
Opsæt prøvedatabase
Lad os oprette en prøvedatabase med navnet SQLDevBlogV5 ved at køre følgende T-SQL-script:
-- Create sample database (SQLDevBlogV5) CREATE DATABASE SQLDevBlogV5; GO USE SQLDevBlogV5; -- (1) Create Article table in the sample database CREATE TABLE Article ( ArticleId INT PRIMARY KEY IDENTITY (1, 1) ,Category VARCHAR(50) ,Author VARCHAR(50) ,Title VARCHAR(150) ,Published DATETIME2 ,Notes VARCHAR(400) ) GO -- (2) Populating Article table SET IDENTITY_INSERT [dbo].[Article] ON INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (1, N'Development', N'Atif', N'Introduction to T-SQL Programming ', N'2017-01-01 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (2, N'Testing', N'Peter', N'Database Unit Testing Fundamentals', N'2017-01-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (3, N'DLM', N'Sadaf', N'Database Lifecycle Management for beginners', N'2017-01-20 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (4, N'Development', N'Peter', N'Common Table Expressions (CTE)', N'2017-02-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (5, N'Testing', N'Sadaf', N'Manual Testing vs. Automated Testing', N'2017-03-20 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (6, N'Testing', N'Atif', N'Beyond Database Unit Testing', N'2017-11-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (7, N'Testing', N'Sadaf', N'Cross Database Unit Testing', N'2017-12-20 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (8, N'Development', N'Peter', N'SQLCMD - A Handy Utitliy for Developers', N'2018-01-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (9, N'Testing', N'Sadaf', N'Scripting and Testing Database for beginners ', N'2018-02-15 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (10, N'Development', N'Atif', N'Advanced Database Development Methods', N'2018-07-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (11, N'Testing', N'Sadaf', N'How to Write Unit Tests for your Database', N'2018-11-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (12, N'Development', N'Peter', N'Database Development using Modern Tools', N'2018-12-10 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (13, N'DLM', N'Atif', N'Designing, Developing and Deploying Database ', N'2019-01-01 00:00:00', NULL) INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (14, N'DLM', N'Peter', N'How to Apply Database Lifecycle Management ', N'2019-02-10 00:00:00', NULL) SET IDENTITY_INSERT [dbo].[Article] OFF
Brug følgende forespørgsel til at se artiklerne:
-- View articles SELECT [a].[ArticleId] ,[a].[Category] ,[a].[Author] ,[a].[Title] ,[a].[Published] ,[a].[Notes] FROM dbo.Article A
Forretningskrav til maskering af forfatternavne
Antag nu, at du modtager et forretningskrav, som siger, at forfatternavne skal maskeres på grund af følsomheden af disse oplysninger. Den bedste måde at opfylde dette forretningskrav på er at maskere kolonnen Navn ved hjælp af DDM.
Maskning af forfatternavne
Vi vil ændre tabellen for at tilføje datamaskeringsfunktion som følger:
-- Masking Author column ALTER TABLE Article ALTER COLUMN [Author] varchar(50) MASKED WITH (FUNCTION = 'default()');
Tjekker maskeringsstatus
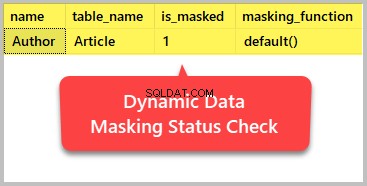
Du kan til enhver tid kontrollere status for dynamisk datamaskering ved at bruge følgende T-SQL-script, der er givet i Microsoft-dokumentationen:
-- Checking dynamic data masking status
SELECT c.name, tbl.name as table_name, c.is_masked, c.masking_function
FROM sys.masked_columns AS c
JOIN sys.tables AS tbl
ON c.[object_id] = tbl.[object_id]
WHERE is_masked = 1; Outputtet viser os, hvilke kolonner der er blevet maskeret med succes:
Datatjek
Tjek nu dataene ved at forespørge på de 5 øverste poster i tabellen, hvor vi har anvendt maskeringen:
-- View top 5 artices records SELECT TOP 5 [a].[ArticleId] ,[a].[Category] ,[a].[Author] ,[a].[Title] ,[a].[Published] ,[a].[Notes] FROM dbo.Article A ORDER BY a.ArticleId
Outputtet ser ikke ud til at vise os det forventede resultat:

Som du kan se på trods af, at vi har maskeret Forfatter-kolonnen, viser den stadig de faktiske værdier. Årsagen bag denne adfærd er, at den konto, vi har brugt til at anvende dynamisk datamaskering, har fået forhøjede privilegier, og det er derfor, de maskerede data er synlige i sin oprindelige form, når vi forespørger i tabellen ved hjælp af den aktuelle konto.
Løsningen er for at oprette en ny bruger med Vælg-tilladelse.
Oprettelse af en bruger med Select-tilladelse på bordet
Lad os nu oprette en ny databasebruger uden login med kun Vælg tilladelse på artikeltabellen som følger:
-- Create ArticleUser to have Select access to Article table CREATE USER ArticleUser WITHOUT LOGIN; GRANT SELECT ON Article TO ArticleUser;
Se Top 5-artikler som ArticleUser
Udfør derefter Select-erklæringen for at få top 5 artikler ved hjælp af den nyoprettede bruger ArticleUser med kun valgt tilladelse:
-- Execute SELECT Article as ArtilceUser EXECUTE AS USER = 'ArticleUser'; -- View artices SELECT TOP 5 [a].[ArticleId] ,[a].[Category] ,[a].[Author] ,[a].[Title] ,[a].[Published] FROM dbo.Article A ORDER BY a.ArticleId -- Revert the User back to what user it was before REVERT;

Tillykke! Du har maskeret forfatterkolonnen i henhold til kravet.
Slip maskeret kolonne
Du kan slippe den dynamiske datamaskering på den kolonne, du har anvendt den før, ved blot at udstede følgende T-SQL-kommando:
-- Removing dynamic data masking on Author column ALTER TABLE Article ALTER COLUMN Author DROP MASKED;
Hold venligst kontakten, da en mere avanceret brug af dynamisk datamaskering er på vej i næste artikel.
Ting at gøre
Nu hvor du kan maskere kolonner i en tabel i en database, prøv venligst følgende ting for at forbedre dine færdigheder yderligere:
1. Prøv at maskere kolonnen Kategori i eksempeldatabasen.
2. Prøv at oprette forfattertabel med AuthorId, Name og Email kolonner og send derefter AuthorId som en fremmednøgle i artikeltabellen og anvend derefter dynamisk datamaskering på Name og Email kolonnerne i forfattertabellen ved at oprette en testbruger
3. Prøv at oprette og slippe dynamisk datamaskering for at sikre, at du med succes kan tilføje og fjerne dynamisk datamaskering på en SQL-tabel