Du har måske hørt om udtrykket "splittet hjerne". Hvad er det? Hvordan påvirker det dine klynger? I dette blogindlæg vil vi diskutere, hvad det præcist er, hvilken fare det kan udgøre for din database, hvordan vi kan forhindre det, og hvis alt går galt, hvordan man kommer sig fra det.
Længe forbi er dagene med enkelte forekomster, i dag kører næsten alle databaser i replikeringsgrupper eller klynger. Dette er fantastisk til høj tilgængelighed og skalerbarhed, men en distribueret database introducerer nye farer og begrænsninger. Et tilfælde, der kan være dødbringende, er en netværksdeling. Forestil dig en klynge af flere noder, som på grund af netværksproblemer blev opdelt i to dele. Af indlysende årsager (datakonsistens) bør begge dele ikke håndtere trafik på samme tid, da de er isoleret fra hinanden, og data ikke kan overføres mellem dem. Det er også forkert ud fra et applikationssynspunkt - også selvom der i sidste ende ville være en måde at synkronisere dataene på (selvom afstemning af 2 datasæt ikke er trivielt). I et stykke tid ville en del af applikationen være uvidende om ændringerne foretaget af andre applikationsværter, som får adgang til den anden del af databaseklyngen. Dette kan føre til alvorlige problemer.
Tilstanden, hvor klyngen er blevet delt i to eller flere dele, der er villige til at acceptere skrivninger, kaldes "splittet hjerne".
Det største problem med delt hjerne er datadrift, da skriverier sker på begge dele af klyngen. Ingen af MySQL-varianter giver automatiserede metoder til at flette datasæt, der har divergeret. Du finder ikke en sådan funktion i MySQL-replikering, gruppereplikering eller Galera. Når først dataene er divergeret, er den eneste mulighed enten at bruge en af delene af klyngen som kilden til sandheden og kassere ændringer udført på den anden del - medmindre vi kan følge en manuel proces for at flette dataene.
Dette er grunden til, at vi starter med, hvordan man forhindrer splittelse af hjernen. Dette er så meget nemmere end at skulle rette eventuelle datauoverensstemmelser.
Sådan forhindrer du split hjerne
Den nøjagtige løsning afhænger af databasens type og miljøets opsætning. Vi vil tage et kig på nogle af de mest almindelige tilfælde for Galera Cluster og MySQL-replikering.
Galera-klynge
Galera har en indbygget "kredsløbsafbryder" til at håndtere split hjerne:den er afhængig af en kvorummekanisme. Hvis et flertal (50 % + 1) af noderne er tilgængelige i klyngen, vil Galera fungere normalt. Hvis der ikke er flertal, vil Galera stoppe med at betjene trafik og skifte til såkaldt "ikke-primær" tilstand. Dette er stort set alt, hvad du behøver for at håndtere en split-hjerne-situation, mens du bruger Galera. Selvfølgelig er der manuelle metoder til at tvinge Galera til "Primær" tilstand, selvom der ikke er flertal. Sagen er, medmindre du gør det, bør du være sikker.
Måden, hvorpå kvorum beregnes, har vigtige konsekvenser - på et enkelt datacenterniveau vil du gerne have et ulige antal noder. Tre noder giver dig en tolerance for svigt af en node (2 noder matcher kravet om, at mere end 50 % af noderne i klyngen er tilgængelige). Fem noder vil give dig en tolerance for svigt af to noder (5 - 2 =3, hvilket er mere end 50 % fra 5 noder). På den anden side vil brug af fire noder ikke forbedre din tolerance over tre node-klynge. Det ville stadig kun håndtere en fejl på én node (4 - 1 =3, mere end 50 % fra 4), mens fejl på to noder vil gøre klyngen ubrugelig (4 - 2 =2, kun 50 %, ikke mere).
Mens du installerer Galera-klyngen i et enkelt datacenter, skal du huske på, at du ideelt set gerne vil distribuere noder på tværs af flere tilgængelighedszoner (separat strømkilde, netværk osv.) - så længe de findes i dit datacenter, dvs. . En simpel opsætning kan se ud som nedenfor:
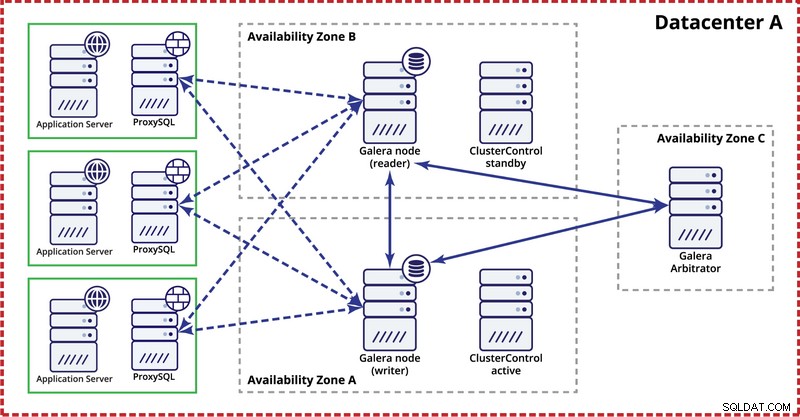
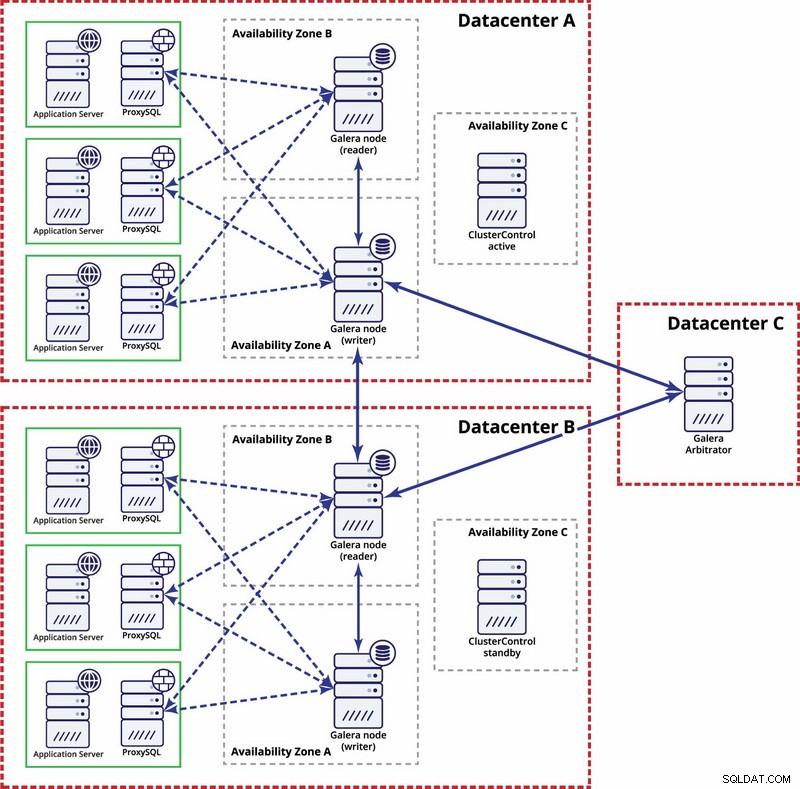
På multidatacenterniveau er disse overvejelser også gældende. Hvis du ønsker, at Galera-klyngen automatisk skal håndtere datacenterfejl, skal du bruge et ulige antal datacentre. For at reducere omkostningerne kan du bruge en Galera-arbitrator i en af dem i stedet for en databasenode. Galera arbitrator (garbd) er en proces, der deltager i kvorumberegningen, men den indeholder ingen data. Dette gør det muligt at bruge det selv på meget små instanser, da det ikke er ressourcekrævende - selvom netværksforbindelsen skal være god, da den 'ser' al replikeringstrafikken. Eksempel på opsætning kan se ud som på et diagram nedenfor:
MySQL-replikering
Med MySQL-replikering er det største problem, at der ikke er nogen quorum-mekanisme indbygget, som det er i Galera-klyngen. Derfor kræves der flere trin for at sikre, at din opsætning ikke bliver påvirket af en split hjerne.
En metode er at undgå automatiserede failovers på tværs af datacentre. Du kan konfigurere din failover-løsning (det kan være gennem ClusterControl, eller MHA eller Orchestrator) til kun at være failover inden for et enkelt datacenter. Hvis der var et fuldstændigt datacenterudfald, ville det være op til administratoren at beslutte, hvordan der skal failover, og hvordan man sikrer, at serverne i det fejlslagne datacenter ikke bliver brugt.
Der er muligheder for at gøre det mere automatiseret. Du kan bruge Consul til at gemme data om noderne i replikeringsopsætningen, og hvilken af dem der er master. Så vil det være op til administratoren (eller via noget scripting) at opdatere denne post og flytte skrivninger til det andet datacenter. Du kan drage fordel af en Orchestrator/Raft-opsætning, hvor Orchestrator-knudepunkter kan fordeles på tværs af flere datacentre og registrere split hjerne. Baseret på dette kan du tage forskellige handlinger som, som vi nævnte tidligere, opdatere poster i vores konsul eller etcd. Pointen er, at dette er et meget mere komplekst miljø at konfigurere og automatisere end Galera cluster. Nedenfor kan du finde et eksempel på opsætning af multi-datacenter til MySQL-replikering.
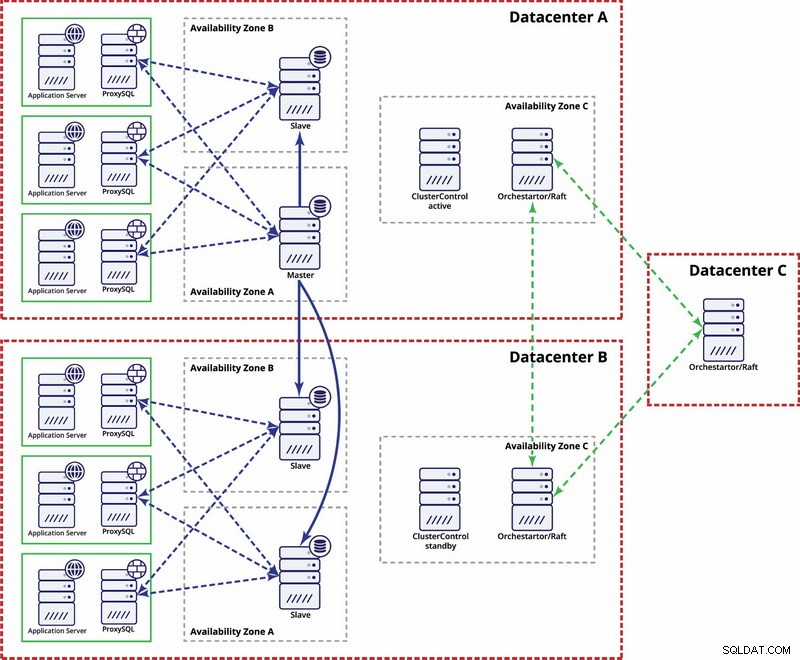
Husk, at du stadig skal oprette scripts for at få det til at fungere, dvs. overvåge Orchestrator-noder for en split hjerne og tage de nødvendige handlinger for at implementere STONITH og sikre, at masteren i datacenter A ikke vil blive brugt, når netværket konvergerer, og forbindelsen vil gendannes.
Split Brain Happened - Hvad skal man gøre nu?
Det værste tilfælde skete, og vi har datadrift. Vi vil prøve at give dig nogle tip, hvad der kan gøres her. Desværre vil de nøjagtige trin mest afhænge af dit skemadesign, så det vil ikke være muligt at skrive en præcis vejledning.
Hvad du skal huske på er, at det ultimative mål vil være at kopiere data fra den ene master til den anden og genskabe alle relationer mellem tabeller.
Først og fremmest skal du identificere, hvilken node der fortsætter med at tjene data som master. Dette er et datasæt, hvortil du vil flette data gemt på den anden "master"-instans. Når det er gjort, skal du identificere data fra den gamle master, som mangler på den nuværende master. Dette vil være manuelt arbejde. Hvis du har tidsstempler i dine tabeller, kan du bruge dem til at lokalisere de manglende data. I sidste ende vil binære logfiler indeholde alle dataændringer, så du kan stole på dem. Du skal muligvis også stole på din viden om datastrukturen og relationerne mellem tabeller. Hvis dine data er normaliseret, kan én post i én tabel være relateret til poster i andre tabeller. For eksempel kan din applikation indsætte data i "bruger"-tabel, som er relateret til "adresse"-tabel ved hjælp af bruger_id. Du bliver nødt til at finde alle relaterede rækker og udtrække dem.
Næste trin vil være at indlæse disse data i den nye master. Her kommer den vanskelige del - hvis du forberedte dine opsætninger på forhånd, kunne dette blot være et spørgsmål om at køre et par indsatser. Hvis ikke, kan dette være ret komplekst. Det handler om primær nøgle og unikke indeksværdier. Hvis dine primærnøgleværdier genereres som unikke på hver server ved hjælp af en slags UUID-generator eller ved at bruge auto_increment_increment og auto_increment_offset-indstillinger i MySQL, kan du være sikker på, at dataene fra den gamle master, du skal indsætte, ikke vil forårsage primærnøgle eller unikke nøglekonflikter med data på den nye master. Ellers skal du muligvis manuelt ændre data fra den gamle master for at sikre, at de kan indsættes korrekt. Det lyder komplekst, så lad os tage et kig på et eksempel.
Lad os forestille os, at vi indsætter rækker ved hjælp af auto_increment på node A, som er en master. For nemheds skyld fokuserer vi kun på en enkelt række. Der er kolonner 'id' og 'værdi'.
Hvis vi indsætter det uden nogen særlig opsætning, vil vi se poster som nedenfor:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Disse vil replikere til slaven (B). Hvis den splittede hjerne sker og skrivninger vil blive udført på både gammel og ny master, vil vi ende med følgende situation:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Som du kan se, er der ingen måde at blot dumpe poster med id på 1004, 1005 og 1006 fra node A og gemme dem på node B, fordi vi ender med duplikerede primærnøgleposter. Det, der skal gøres, er at ændre værdierne af id-kolonnen i rækkerne, der indsættes til en værdi, der er større end den maksimale værdi af id-kolonnen fra tabellen. Dette er alt, hvad der er nødvendigt for enkelte rækker. For mere komplekse relationer, hvor flere tabeller er involveret, skal du muligvis foretage ændringerne flere steder.
På den anden side, hvis vi havde forudset dette potentielle problem og konfigureret vores noder til at gemme ulige id'er på node A og lige id'er på node B, ville problemet have været så meget lettere at løse.
Node A blev konfigureret med auto_increment_offset =1 og auto_increment_increment =2
Node B blev konfigureret med auto_increment_offset =2 og auto_increment_increment =2
Sådan ville dataene se ud på node A før den splittede hjerne:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Når en delt hjerne skete, vil det se ud som nedenfor.
Node A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Node B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Nu kan vi nemt kopiere manglende data fra node A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Og indlæs det til node B, der ender med følgende datasæt:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Selvfølgelig er rækkerne ikke i den oprindelige rækkefølge, men det burde være ok. I værste fald bliver du nødt til at sortere efter 'værdi'-kolonnen i forespørgsler og måske tilføje et indeks for at gøre sorteringen hurtig.
Forestil dig nu hundreder eller tusinder af rækker og en meget normaliseret tabelstruktur - for at gendanne en række kan det betyde, at du bliver nødt til at gendanne flere af dem i yderligere tabeller. Med et behov for at ændre id'er (fordi du ikke havde beskyttende indstillinger på plads) på tværs af alle relaterede rækker, og alt dette er manuelt arbejde, kan du forestille dig, at dette ikke er den bedste situation at være i. Det tager tid at komme sig og det er en fejlbehæftet proces. Heldigvis, som vi diskuterede i begyndelsen, er der midler til at minimere chancerne for, at splittet hjerne vil påvirke dit system eller til at reducere det arbejde, der skal gøres for at synkronisere tilbage dine noder. Sørg for at bruge dem og forbliv forberedt.