For et par uger siden lavede jeg en ret stor aftale om SQL Server 2016 Service Pack 1. Mange funktioner, der tidligere var reserveret til Enterprise Edition, blev sluppet løs til lavere udgaver, og jeg var ekstatisk over at lære om disse ændringer.
Ikke desto mindre ser jeg nogle få mennesker, der er, lad os sige, en smule mindre begejstrede end jeg er.
Det er vigtigt at huske på, at ændringerne her ikke var beregnet til at give fuldstændig funktionsparitet på tværs af alle udgaver; de havde det specifikke formål at skabe et mere konsistent programmeringsoverfladeareal. Nu kan kunder bruge funktioner som In-Memory OLTP, Columnstore og komprimering uden at bekymre sig om den eller de målrettede udgaver – kun om hvor godt de vil skalere. Adskillige sikkerhedsfunktioner, der ikke rigtigt så ud til at have noget at gøre med edition, er også åbnet. Den, jeg forstod mindst, var Always Encrypted; Jeg kunne ikke forstå, hvorfor kun Enterprise-kunder skulle beskytte ting som kreditkortdata. Transparent datakryptering er stadig kun for Enterprise, på versioner tidligere end SQL Server 2019, fordi dette ikke rigtig er en programmerbarhedsfunktion (enten er den slået til, eller også er den ikke).
Så hvad er der egentlig i det for Standard Edition-kunder?
Jeg tror, at det største problem, de fleste har, er, at den maksimale hukommelse i Standard Edition stadig er begrænset til 128 GB. De ser på det og siger:"Tak, tak for alle funktionerne, men hukommelsesgrænsen betyder, at jeg ikke rigtig kan bruge dem."
Ændringerne i overfladearealet medfører imidlertid muligheder for forbedring af ydeevnen, selvom det ikke var deres oprindelige hensigt (eller selvom det var det – jeg var ikke med til nogen af disse møder). Lad os se nærmere på et lille udsnit af det med småt (fra de officielle dokumenter):
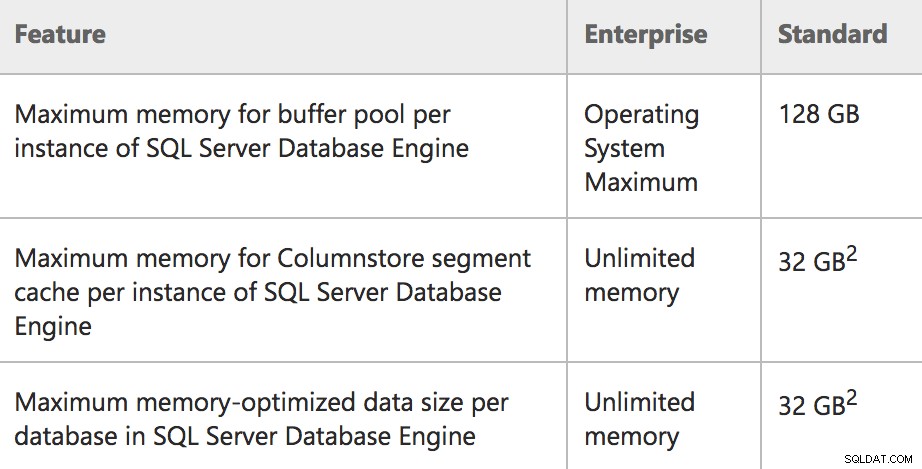 Hukommelsesgrænser for Enterprise/Standard i SQL Server 2016 SP1
Hukommelsesgrænser for Enterprise/Standard i SQL Server 2016 SP1
Den kloge læser vil bemærke, at formuleringen af bufferpuljens grænse er ændret fra:
Hukommelse:Maksimal hukommelse brugt pr. instansTil:
Hukommelse:Maksimal bufferpuljestørrelse pr. tilfældeDette er en bedre beskrivelse af, hvad der virkelig sker i Standard Edition:en grænse på 128 GB kun for bufferpuljen, og andre hukommelsesreservationer kan være ud over det (tænk, at pools som plan-cachen). Så i virkeligheden kunne en Standard Edition-server bruge 128 GB bufferpulje, så kunne den maksimale serverhukommelse være højere og understøtte mere hukommelse, der bruges til andre reservationer. Tilsvarende er Express Edition nu korrekt dokumenteret til at bruge 1,4 GB til bufferpuljen.
Du vil muligvis også bemærke nogle meget specifikke ordlyd i den kolonne længst til venstre (f.eks. "pr. forekomst" og "pr. database") for de funktioner, der bliver eksponeret i Standard Edition for første gang. For at være mere specifik:
- Forekomsten er begrænset til 128 GB hukommelse til bufferpuljen .
- Forekomsten kan have en ekstra 32 GB allokeret til Columnstore-objekter ud over bufferpuljens grænse.
- Hver brugerdatabase på instansen kan have en ekstra 32 GB allokeret til hukommelsesoptimerede tabeller ud over bufferpuljens grænse.
Og for at være krystalklar:Disse hukommelsesgrænser for ColumnStore og In-Memory OLTP trækkes IKKE fra bufferpuljens grænse , så længe serveren har mere end 128 GB ledig hukommelse. Hvis serveren har mindre end 128 GB, vil du se, at disse teknologier konkurrerer med bufferpuljens hukommelse og faktisk er begrænset til % af max serverhukommelse. Flere detaljer er tilgængelige i dette indlæg fra Microsofts Parikshit Savjani.
Jeg har ikke hardware praktisk til at teste omfanget af dette, men hvis du havde en maskine med 256 GB eller 512 GB hukommelse, kunne du teoretisk bruge det hele med en enkelt Standard Edition-instans, hvis du for eksempel kunne sprede dit In -Hukommelsesdata på tværs af databaser i <=32 GB bidder, i alt 128 GB + (32 GB * (antal databaser)). Hvis du ville bruge ColumnStore i stedet for In-Memory, kunne du sprede dine data på tværs af flere forekomster, hvilket giver dig (128 GB + 32 GB) * (antal forekomster). Og du kan kombinere disse strategier for ((128GB + 32GB ColumnStore) * (# forekomster)) + (32GB In-Memory * (# af databaser * # af forekomster)).
Hvorvidt det er praktisk for din applikation at opdele dine data på denne måde, er jeg ikke sikker på; Jeg foreslår kun, at det er muligt. Nogle af jer gør måske allerede nogle af disse ting for at få bedre brug af Standard Edition på servere med mere end 128 GB hukommelse.
Specifikt med ColumnStore, udover at have lov til at bruge 32GB ud over bufferpuljen, skal du huske på, at den komprimering, du kan få her, betyder, at du ofte kan passe meget mere ind i den 32GB-grænse, end du kunne med de samme data i traditionelle række-butik. Og hvis du af en eller anden grund ikke kan bruge ColumnStore (eller det stadig ikke passer ind i 32 GB), kan du nu implementere traditionel side- eller rækkekomprimering – det giver dig måske ikke mulighed for at passe hele din database ind i 128 GB bufferpuljen, men det kan gøre det muligt for flere af dine data at være i hukommelsen på ethvert givet tidspunkt.
Lignende ting er mulige i Express (i en lavere skala), hvor du kan have 1,4 GB til bufferpulje, men yderligere ~352 MB pr. forekomst til ColumnStore og ~352 MB pr. database til In-Memory OLTP.
Men Enterprise Edition har stadig mange fordele
Der er mange andre differentiatorer til at holde interessen for Enterprise Edition, bortset fra ubegrænsede hukommelsesgrænser rundt omkring – fra online-genopbygninger og karuseller-scanninger til fuld-on tilgængelighedsgrupper og alle de virtualiseringsrettigheder, du kan ryste på. Selv ColumnStore-indekser har veldefinerede ydeevneforbedringer forbeholdt Enterprise Edition.
Så bare fordi der er nogle teknikker, der giver dig mulighed for at få mere ud af Standard Edition, betyder det ikke, at den på magisk vis vil skaleres for at opfylde dine præstationsbehov. Ligesom mine andre indlæg om "at gøre det på et budget" (f.eks. partitionering og læsbare sekundære), kan du helt sikkert bruge tid og kræfter på at samle en løsning, men det vil kun komme dig så langt. Pointen med dette indlæg var simpelthen at demonstrere, at du kan komme længere med Standard Edition i 2016 SP1, end du nogensinde kunne før.