Dette er den anden del af en todelt serie om 2ndQuadrants repmgr, et open source-værktøj med høj tilgængelighed til PostgreSQL.
I den første del opsatte vi en tre-node PostgreSQL 12-klynge sammen med en "vidne"-knude. Klyngen bestod af en primær knude og to standby-knudepunkter. Klyngen og vidneknudepunktet var hostet i en Amazon Web Service Virtual Private Cloud (VPC). EC2-serverne, der var vært for Postgres-forekomsterne, blev placeret i undernet i forskellige tilgængelighedszoner (AZ), som vist nedenfor:
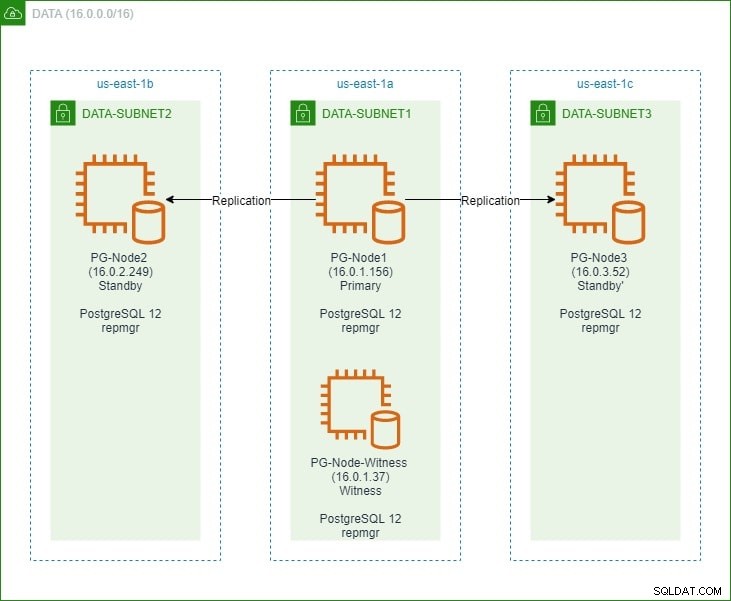
Vi vil lave omfattende referencer til nodenavnene og deres IP-adresser, så her er tabellen igen med nodernes detaljer:
| Nodenavn | IP-adresse | Rolle | Apps kører |
| PG-Node1 | 16.0.1.156 | Primær | PostgreSQL 12 og repmgr |
| PG-Node2 | 16.0.2.249 | Standby 1 | PostgreSQL 12 og repmgr |
| PG-Node3 | 16.0.3.52 | Standby 2 | PostgreSQL 12 og repmgr |
| PG-Node-Witness | 16.0.1.37 | Vidne | PostgreSQL 12 og repmgr |
Vi installerede repmgr i de primære og standby noder og registrerede derefter den primære node med repmgr. Vi klonede derefter begge standby-noder fra den primære og startede dem. Begge standby noder blev også registreret med repmgr. Kommandoen "repmgr cluster show" viste os, at alt kørte som forventet:

Aktuelt problem
Opsætning af streamingreplikering med repmgr er meget enkel. Det, vi skal gøre, er at sikre, at klyngen fungerer, selv når den primære bliver utilgængelig. Dette er, hvad vi vil dække i denne artikel.
I PostgreSQL-replikering kan en primær blive utilgængelig af et par årsager. For eksempel:
- operativsystemet for den primære node kan gå ned eller ikke reagere
- Den primære node kan miste sin netværksforbindelse
- PostgreSQL-tjenesten i den primære node kan gå ned, stoppe eller blive utilgængelig uventet
- PostgreSQL-tjenesten i den primære node kan stoppes med vilje eller ved et uheld
Når en primær bliver utilgængelig, gør en standby det ikke automatisk fremme sig selv til den primære rolle. En standby fortsætter stadig med at betjene skrivebeskyttede forespørgsler – selvom dataene vil være aktuelle op til det sidste LSN modtaget fra den primære. Ethvert forsøg på en skriveoperation vil mislykkes.
Der er to måder at afbøde dette på:
- Standby er manuelt opgraderet til en primær rolle. Dette er normalt tilfældet for en planlagt failover eller "switchover"
- Standby er automatisk forfremmet til en primær rolle. Dette er tilfældet med ikke-native værktøjer, der kontinuerligt overvåger replikering og foretager genoprettelseshandlinger, når den primære er utilgængelig. repmgr er et sådant værktøj.
Vi vil overveje det andet scenarie her. Denne situation har dog nogle ekstra udfordringer:
- Hvis der er mere end én standby, hvordan bestemmer værktøjet (eller standbyerne), hvilken der skal fremmes som primær? Hvordan fungerer kvorummet og forfremmelsesprocessen?
- For flere standbyer, hvis en er gjort til primær, hvordan begynder de andre noder at "følge den" som den nye primære?
- Hvad sker der, hvis den primære fungerer, men af en eller anden grund midlertidigt adskilles fra netværket? Hvis en af standbyerne forfremmes til primær, og den oprindelige primære kommer tilbage online, hvordan kan en "split brain"-situation undgås?
remgrs svar:Witness Node og repmgr-dæmonen
For at besvare disse spørgsmål bruger repmgr noget, der kaldes en vidneknude . Når den primære er utilgængelig - er det vidneknudepunktets opgave at hjælpe standbyerne med at nå et beslutningsdygtigt, hvis en af dem skulle forfremmes til en primær rolle. Standbys når dette kvorum ved at bestemme, om den primære node faktisk er offline eller kun midlertidigt utilgængelig. Vidneknuden bør være placeret i samme datacenter/netværkssegment/undernet som den primære knude, men må ALDRIG køre på den samme fysiske vært som den primære knude.
Husk, at vi i den første del af denne serie udrullede en vidneknude i samme tilgængelighedszone og undernet som den primære knude. Vi kaldte det PG-Node-Witness og installerede en PostgreSQL 12-instans der. I dette indlæg vil vi også installere repmgr der, men mere om det senere.
Den anden komponent i løsningen er repmgr-dæmonen (repmgrd) kører i alle noder i klyngen og vidneknudepunktet. Igen, vi startede ikke denne dæmon i den første del af denne serie, men vi vil gøre det her. Dæmonen kommer som en del af repmgr-pakken - når den er aktiveret, kører den som en almindelig tjeneste og overvåger kontinuerligt klyngens helbred. Det initierer en failover, når et kvorum er nået om, at den primære er offline. Det kan ikke kun automatisk fremme en standby, det kan også genstarte andre standbys i en multi-node klynge for at følge den nye primære .
Kvorumsprocessen
Når en standby indser, at den ikke kan se den primære, rådfører den sig med andre standbys. Alle standbys, der kører i klyngen, når et kvorum for at vælge en ny primær ved hjælp af en række kontroller:
- Hver standby udspørger andre standbyer om det tidspunkt, den sidst "så" den primære. Hvis en standbys sidste replikerede LSN eller tidspunktet for sidste kommunikation med den primære er nyere end den aktuelle nodes sidst replikerede LSN eller tidspunktet for sidste kommunikation, gør noden ikke noget og venter på, at kommunikationen med den primære gendannes
- Hvis ingen af standbyerne kan se den primære, tjekker de, om vidne-knuden er tilgængelig. Hvis vidneknudepunktet heller ikke kan nås, antager standbyerne, at der er et netværksudfald på den primære side og fortsætter ikke med at vælge en ny primær
- Hvis vidnet kan nås, antager standbyerne, at den primære er nede og fortsætter med at vælge en primær
- Den node, der blev konfigureret som den "foretrukne" primære, vil derefter blive forfremmet. Hver standby vil få sin replikering geninitialiseret for at følge den nye primære.
Konfiguration af klyngen til automatisk failover
Vi vil nu konfigurere klyngen og vidne-noden til automatisk failover.
Trin 1:Installer og konfigurer repmgr i Witness
Vi så allerede, hvordan man installerer repmgr-pakken i vores sidste artikel. Det gør vi også i vidne-knuden:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Og så:
# yum install repmgr12 -y
Dernæst tilføjer vi følgende linjer i vidneknudepunktets postgresql.conf-fil:
listen_addresses ='*'shared_preload_libraries ='repmgr'
Vi tilføjer også følgende linjer i filen pg_hba.conf i vidneknudepunktet. Bemærk, hvordan vi bruger CIDR-området for klyngen i stedet for at angive individuelle IP-adresser.
Lokal replikation repmgr trusthost replikation repmgr 127.0.0.1/32 trusthost replikation repmgr 16.0.0.0/16 trustlocal repmgr repmgr trusthost repmgr repmgr 127.0.0.1/32 trusthost repmgr repmgr 16.0.0.0.0/16 Trust
Bemærk
[Trinnene beskrevet her er kun til demonstrationsformål. Vores eksempel her er at bruge eksternt tilgængelige IP'er til noderne. Brug af listen_address ='*' sammen med pg_hbas "tillid"-sikkerhedsmekanisme udgør derfor en sikkerhedsrisiko og bør IKKE bruges i produktionsscenarier. I et produktionssystem vil noderne alle være inde i et eller flere private undernet, som kan nås via private IP'er fra jumphosts.]
Med postgresql.conf og pg_hba.conf ændringer udført, opretter vi repmgr-brugeren og repmgr-databasen i vidnet og ændrer repmgr-brugerens standardsøgesti:
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$ createdb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Til sidst tilføjer vi følgende linjer til filen repmgr.conf, som er placeret under /etc/repmgr/12/
node_id =4node_name ='PG-Node-Witness'forbindelse ='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'data_directory ='/var/lib/pgsql/12/data'
Når konfigurationsparametrene er indstillet, genstarter vi PostgreSQL-tjenesten i vidne-noden:
# systemctl genstart postgresql-12.service
For at teste forbindelsen til at vidne node repmgr, kan vi køre denne kommando fra den primære node:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Dernæst registrerer vi vidne-knuden med repmgr ved at køre kommandoen "repmgr vidneregister" som postgres-bruger. Bemærk, hvordan vi bruger adressen på den primære node, og IKKE vidne-noden i kommandoen nedenfor:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf vidneregister -h 16.0.1.156
Dette skyldes, at kommandoen "repmgr vidneregister" tilføjer vidneknudens metadata til den primære knudes repmgr-database og initialiserer om nødvendigt vidneknuden ved at installere repmgr-udvidelsen og kopiere repmgr-metadataene til vidneknuden.
Outputtet vil se sådan ud:
INFO:opretter forbindelse til vidne-node "PG-Node-Witness" (ID:4)INFO:opretter forbindelse til primær nodeNOTICE:forsøger at installere udvidelsen "repmgr"BEMÆRK:"repmgr"-udvidelsen er installeret korrektINFO:vidneregistrering komplet BEMÆRKNING:vidneknude "PG-node-vidne" (ID:4) lykkedes registreret
Til sidst kontrollerer vi status for den overordnede opsætning fra enhver node:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Outputtet ser sådan ud:

Trin 2:Ændring af sudoers-filen
Med klyngen og vidnet kørende tilføjer vi følgende linjer i sudoers-filen i hver node i klyngen og vidneknuden:
Standarder:postgres !requirettypostgres ALL =NOPASSWD:/usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl genstart postgresql-12.service , /usr/bin/systemctl genindlæs postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Trin 3:Konfiguration af repmgrd-parametre
Vi har allerede tilføjet fire parametre i repmgr.conf-filen i hver node. De tilføjede parametre er de grundlæggende nødvendige for repmgr-drift. For at aktivere repmgr-dæmonen og automatisk failover, skal en række andre parametre aktiveres/tilføjes. I de følgende underafsnit vil vi beskrive hver parameter og den værdi, de indstilles til i hver node.
failover
Failover-parameteren er en af de obligatoriske parametre for repmgr-dæmonen. Denne parameter fortæller dæmonen, om den skal starte en automatisk failover, når en failover-situation detekteres. Den kan have en af to værdier:"manuel" eller "automatisk". Vi indstiller dette til automatisk i hver node:
failover ='automatisk'
promote_command
Dette er en anden obligatorisk parameter for repmgr-dæmonen. Denne parameter fortæller repmgr-dæmonen, hvilken kommando den skal køre for at fremme en standby. Værdien af denne parameter vil typisk være kommandoen "repmgr standby promote" eller stien til et shell-script, der kalder kommandoen. Til vores brug indstiller vi dette til følgende i hver node:
promote_command ='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
følge_kommando
Dette er den tredje obligatoriske parameter for repmgr-dæmonen. Denne parameter fortæller en standby node at følge den nye primære. repmgr-dæmonen erstatter %n-pladsholderen med node-id'et for den nye primære på kørselstidspunktet:
følge_kommando ='/usr/pgsql-12/bin/repmgr standby følg -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
prioritet
Prioritetsparameteren tilføjer vægt til en nodes berettigelse til at blive en primær. Indstilling af denne parameter til en højere værdi giver en node større berettigelse til at blive den primære node. Hvis denne værdi indstilles til nul for en node, vil det også sikre, at noden aldrig promoveres som primær.
I vores brugstilfælde har vi to standbys:PG-Node2 og PG-Node3. Vi ønsker at promovere PG-Node2 som den nye primære, når PG-Node1 går offline, og PG-Node3 for at følge PG-Node2 som dens nye primære. Vi indstiller parameteren til følgende værdier i de to standby noder:
| Nodenavn | Parameterindstilling |
| PG-Node2 | prioritet =60 |
| PG-Node3 | prioritet =40 |
monitor_interval_secs
Denne parameter fortæller repmgr-dæmonen, hvor ofte (i antal sekunder) den skal kontrollere tilgængeligheden af opstrømsknuden. I vores tilfælde er der kun én opstrømsknude:den primære knude. Standardværdien er 2 sekunder, men vi vil udtrykkeligt indstille dette i hver node:
monitor_interval_secs =2
connection_check_type
Connection_check_type-parameteren dikterer den protokol, som repmgr-dæmonen vil bruge til at nå ud til opstrømsknuden. Denne parameter kan have tre værdier:
- ping :repmgr bruger PQPing() metoden
- forbindelse :repmgr forsøger at oprette en ny forbindelse til opstrømsknuden
- forespørgsel :repmgr forsøger at køre en SQL-forespørgsel på opstrømsknuden ved hjælp af den eksisterende forbindelse
Igen vil vi indstille denne parameter til standardværdien for ping i hver node:
connection_check_type ='ping'
reconnect_attempts og reconnect_interval
Når den primære bliver utilgængelig, vil repmgr-dæmonen i standby-knuderne forsøge at genoprette forbindelsen til den primære i reconnect_attempts-tider. Standardværdien for denne parameter er 6. Mellem hvert gentilslutningsforsøg vil den vente i reconnect_interval sekunder, som har en standardværdi på 10. Til demonstrationsformål vil vi bruge et kort interval og færre gentilslutningsforsøg. Vi indstiller denne parameter i hver node:
reconnect_attempts =4gentilslut_interval =8
primær_synlighedskonsensus
Når den primære bliver utilgængelig i en multi-node klynge, kan standbys konsultere hinanden for at opbygge et kvorum om en failover. Dette gøres ved at spørge hver standby om, hvornår den sidst så den primære. Hvis en nodes sidste kommunikation var meget nylig og senere end det tidspunkt, hvor den lokale node så den primære, antager den lokale node, at den primære stadig er tilgængelig, og fortsætter ikke med en failover-beslutning.
For at aktivere denne konsensusmodel skal parameteren primary_visibility_consensus indstilles til "true" i hver node – inklusive vidnet:
primær_synlighed_konsensus =sandt
standby_disconnect_on_failover
Når parameteren standby_disconnect_on_failover er sat til "true" i en standby node, vil repmgr-dæmonen sikre, at dens WAL-modtager er afbrudt fra den primære og ikke modtager nogen WAL-segmenter. Den vil også vente på, at WAL-modtagerne på andre standby-knudepunkter stopper, før den træffer en failover-beslutning. Denne parameter skal indstilles til den samme værdi i hver node. Vi indstiller dette til "sandt".
standby_disconnect_on_failover =sandt
Indstilling af denne parameter til sand betyder, at hver standby-knude er holdt op med at modtage data fra den primære, da failoveren sker. Processen vil have en forsinkelse på 5 sekunder plus den tid, det tager WAL-modtageren at stoppe, før der træffes en failover-beslutning. Som standard vil repmgr-dæmonen vente i 30 sekunder for at bekræfte, at alle søskendenoder er holdt op med at modtage WAL-segmenter, før failoveren sker.
repmgrd_service_start_command og repmgrd_service_stop_command
Disse to parametre specificerer, hvordan du starter og stopper repmgr-dæmonen ved at bruge kommandoerne "repmgr daemon start" og "repmgr daemon stop".
Dybest set er disse to kommandoer indpakninger omkring operativsystemkommandoer til start/stop af tjenesten. De to parameterværdier knytter disse kommandoer til deres OS-specifikke versioner. Vi indstiller disse parametre til følgende værdier i hver node:
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
PostgreSQL Service Start/Stop/Genstart kommandoer
Som en del af dens drift vil repmgr-dæmonen ofte skulle stoppe, starte eller genstarte PostgreSQL-tjenesten. For at sikre, at dette sker problemfrit, er det bedst at angive de tilsvarende operativsystemkommandoer som parameterværdier i filen repmgr.conf. Vi vil indstille fire parametre i hver node til dette formål:
service_start_command ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl genstart postgresql-12.service'service_reload_command ='sudo /usr/bin/systemctl genindlæs postgresql-12.service'
monitoring_historie
Indstilling af parameteren monitoring_history til "yes" sikrer, at repmgr gemmer sine klyngeovervågningsdata. Vi indstiller dette til "ja" i hver node:
monitoring_historie =ja
log_status_interval
Vi indstiller parameteren i hver node for at angive, hvor ofte repmgr-dæmonen vil logge en statusmeddelelse. I dette tilfælde indstiller vi dette til hvert 60. sekund:
log_status_interval =60
Trin 4:Start af repmgr-dæmonen
Med parametrene nu indstillet i klyngen og vidne-knuden, udfører vi en tør kørsel af kommandoen for at starte repmgr-dæmonen. Vi tester dette først i den primære knude og derefter de to standby-knudepunkter, efterfulgt af vidne-knuden. Kommandoen skal udføres som postgres-brugeren:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Outputtet skal se sådan ud:
INFO:forudsætninger for at starte repmgrd opfyldt DETAIL:følgende kommando vil blive udført: sudo /usr/bin/systemctl start repmgr12.service
Dernæst starter vi dæmonen i alle fire noder:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Outputtet i hver node skulle vise, at dæmonen er startet:
BEMÆRKNING:udfører:"sudo /usr/bin/systemctl start repmgr12.service"BEMÆRKNING:repmgrd blev startet med succes
Vi kan også tjekke servicestarthændelsen fra de primære eller standby-knudepunkter:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf klyngehændelse --event=repmgrd_start
Outputtet skulle vise, at dæmonen overvåger forbindelserne:
Endelig kan vi kontrollere dæmon-outputtet fra sysloggen i en hvilken som helst af standbyerne:
# kat /var/log/meddelelser | grep repmgr | mindre
Her er outputtet fra PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [BEMÆRK] ved hjælp af den medfølgende konfigurationsfil "/etc/repmgr/12/repmgr.conf"Feb. 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [BEMÆRK] repmgrd (repmgrd 5.0.0) starter op Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] opretter forbindelse til databasen "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"Feb. 5 11:37:24 PG-Node3 systemd[1]:repmgr12.service:Kan ikke åbne PID-filen /run/repmgr/repmgrd-12.pid (endnu?) efter start:Ingen sådan fil eller mappe. Feb 5 11:37 :24 PG-Node3 repmgrd[2014]:INFO: set_repmgrd_pid():forudsat at pidfilen er /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [BEMÆRK] starter overvågning af node "PG-Node3" (ID:3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] "connection_check_type" sat til "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] overvågningsforbindelse til upstream node "PG-Node1" (ID:1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID:3) monitoring upstream node "PG- Node1" (ID:1) i normal tilstand Feb 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [DETAIL] sidste opdatering af overvågningsstatistik var for 2 sekunder siden Feb 5 11:39:26 PG-Node3 repmgrd[2014]:[2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID:3) monitoring upstream node "PG- Node1" (ID:1) i normal tilstand ... ...
Kontrol af syslog i den primære node viser en anden type output:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [BEMÆRK] ved hjælp af den medfølgende konfigurationsfil "/etc/repmgr/12/repmgr.conf"Feb. 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [BEMÆRK] repmgrd (repmgrd 5.0.0) starter op Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] opretter forbindelse til databasen "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"feb. 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [BEMÆRK] starter overvågning af node "PG-Node1" (ID:1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] "connection_check_type" sat til "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [BEMÆRK] monitoring cluster primære "PG-Node1" (ID:1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] underordnet node "PG-Node-Witness" (ID:4) er endnu ikke vedhæftet. Feb 5 11 :37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] underordnet node "PG-Node3" (ID:3) er vedhæftet Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] underordnet node "PG-Node2" (ID:2) er vedhæftet Feb 5 11:37:32 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:32] [NOTICE] nyt vidne "PG-Node-Witness" (ID:4) har oprettet forbindelse Feb 5 11:38:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:38:14] [INFO] overvågning af primær node "PG-Node1" (ID:1) i normal tilstand Feb 5 11:39:15 PG-Node1 repmgrd[2017]:[2020-02-05 11:39:15] [INFO] overvågning af primær node "PG-Node1" (ID:1) i normal tilstand ... ...
Trin 5:Simulering af en mislykket primærgruppe
Nu vil vi simulere en fejlslagen primær ved at stoppe den primære node (PG-Node1). Fra nodens shell-prompt kører vi følgende kommando:
# systemctl stop postgresql-12.service
Failover-processen
Når processen stopper, venter vi i cirka et minut eller to og tjekker derefter syslog-filen for PG-Node2. Følgende meddelelser vises. For overskuelighed og enkelhed har vi farvekodede grupper af beskeder og tilføjede mellemrum mellem linjer:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [ADVARSEL] kan ikke pinge "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. feb 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] DETAIL] PQping() returnerede "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [INFO] sover 8 sekunder indtil næste forsøg på genforbindelse Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] kontrollerer status for node 1, 2 af 4 forsøg Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [ADVARSEL] kan ikke pinge "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. feb 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] DETAIL] PQping() returnerede "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] sover 8 sekunder indtil næste genforbindelsesforsøg Feb 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] kontrollerer status for node 1, 3 af 4 forsøg Feb 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [ADVARSEL] kan ikke pinge "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. feb 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] DETAIL] PQping() returnerede "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] sover 8 sekunder indtil næste forsøg på genforbindelse Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] kontrollerer tilstanden for node 1, 4 af 4 forsøg Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [ADVARSEL] kan ikke pinge "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] DETAIL] PQping() returnerede "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [ADVARSEL] kunne ikke genoprette forbindelse til node 1 efter 4 forsøg Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] indstiller "wal_retrieve_retry_interval" til 86405000 millisekunder Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [ADVARSEL] wal-modtager kører ikke Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [BEMÆRK] WAL-modtager afbrudt på alle søskendenoder Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] WAL-modtager afbrudt på alle 2 søskendenoder Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] lokale nodes sidste modtagelse lsn:0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] kontrollerer status for søskendenode "PG-Node3" (ID:3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID:3) rapporterer, at dens opstrøms er node 1 , sidst set for 26 sekund(er) siden Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node 3 sidst så primær node for 26 sekunder siden Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] modtog sidst LSN for søskendenode "PG-Node3" (ID:3) er :0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID:3) har samme LSN som den nuværende kandidat "PG-Node2" (ID:2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID:3) har lavere prioritet (40) end nuværende kandidat "PG-Node2" (ID:2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] tjekker status for søskendenode "PG-Node-Witness" (ID:4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID:4) rapporterer, at dens opstrøms er node 1, sidst set for 26 sekund(er) siden Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node 4 sidst så primær node for 26 sekund(er) siden Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] synlige noder:3; samlede knudepunkter:3; ingen noder har set den primære inden for de sidste 4 sekunder ……Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [BEMÆRK] forfremmelseskandidat er "PG-Node2" (ID:2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] indstiller "wal_retrieve_retry_interval" til 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [BEMÆRK] denne node er vinderen, vil nu promovere sig selv og informere andre noder …… Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [BEMÆRK] fremmer standby til primær Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [DETAIL] promoverer serveren "PG-Node2" (ID:2) ved hjælp af pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [BEMÆRK] venter i op til 60 sekunder (parameteren "promote_check_timeout") på, at forfremmelsen er fuldført Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [BEMÆRKNING] STANDBY PROMOTE vellykket Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [DETAIL] serveren "PG-Node2" (ID:2) blev forfremmet til primær Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] 2 følgere at give besked Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] giver node "PG-Node3" (ID:3) besked om at følge node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] giver node "PG-Node-Witness" (ID:4) besked om at følge node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] skifter til primær overvågningstilstand Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [BEMÆRK] overvågningsklynge primære "PG-Node2" (ID:2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [NOTICE] nyt vidne "PG-Node-Witness" (ID:4) har oprettet forbindelse Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [BEMÆRK] ny standby "PG-Node3" (ID:3) er tilsluttet Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [BEMÆRK] ny standby "PG-Node3" (ID:3) har tilsluttet 5. februar 11:55:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:55:02] [INFO] overvågning af primær node "PG-Node2" (ID:2) i normal tilstand Feb 5 11:56:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:56:02] [INFO] overvågning af primær node "PG-Node2" (ID:2) i normal tilstand … …
Der er en masse information her, men lad os nedbryde, hvordan begivenhederne har udspillet sig. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
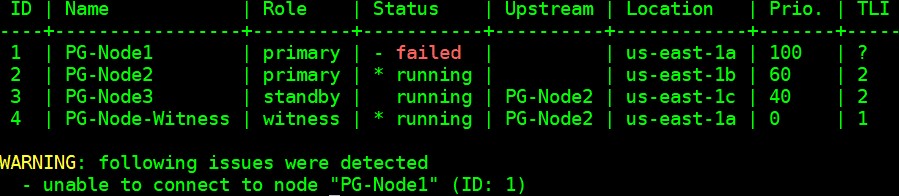
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
Konklusion
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1