Denne artikel giver en trin for trin guide til at bruge maskinlæringsfunktioner med 2UDA. I artiklen vil vi bruge et eksempel på dyr til at forudsige, om de er pattedyr, fugle, fisk eller insekter.
Softwareversioner
Vi kommer til at bruge 2UDA version 11.6-1 til at implementere Machine Learning-modellen. 2UDA version 11.6-1 kombinerer:
- PostgreSQL 11.6
- Orange 3.23.0
Du kan finde den seneste version af 2UDA her.
Trin 1:Indlæs træningsdatasæt i PostgreSQL
Eksempeldatasættet, der bruges til at træne vores model, er tilgængeligt på det officielle Orange GitHub-lager her.
Følg disse trin for at indlæse træningsdataene i PostgreSQL-tabeller:
- Opret forbindelse til PostgreSQL via psql, OmniDB eller ethvert andet værktøj, som du er bekendt med.
- Opret en tabel til at gemme vores træningsdata . Her hedder det træningsdata.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Indsæt træningsdata i tabellen via COPY-forespørgsel. Før du udfører COPY-forespørgsel, skal du sikre dig, at PostgreSQL har krævet læsetilladelser på datafilen, ellers vil COPY-handlingen mislykkes.
BEMÆRK: Sørg for at indtaste en fane mellemrum mellem enkelte anførselstegn efter afgrænsningstegnet søgeord.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Find venligst skærmbilledet af træningsdatasættet nedenfor
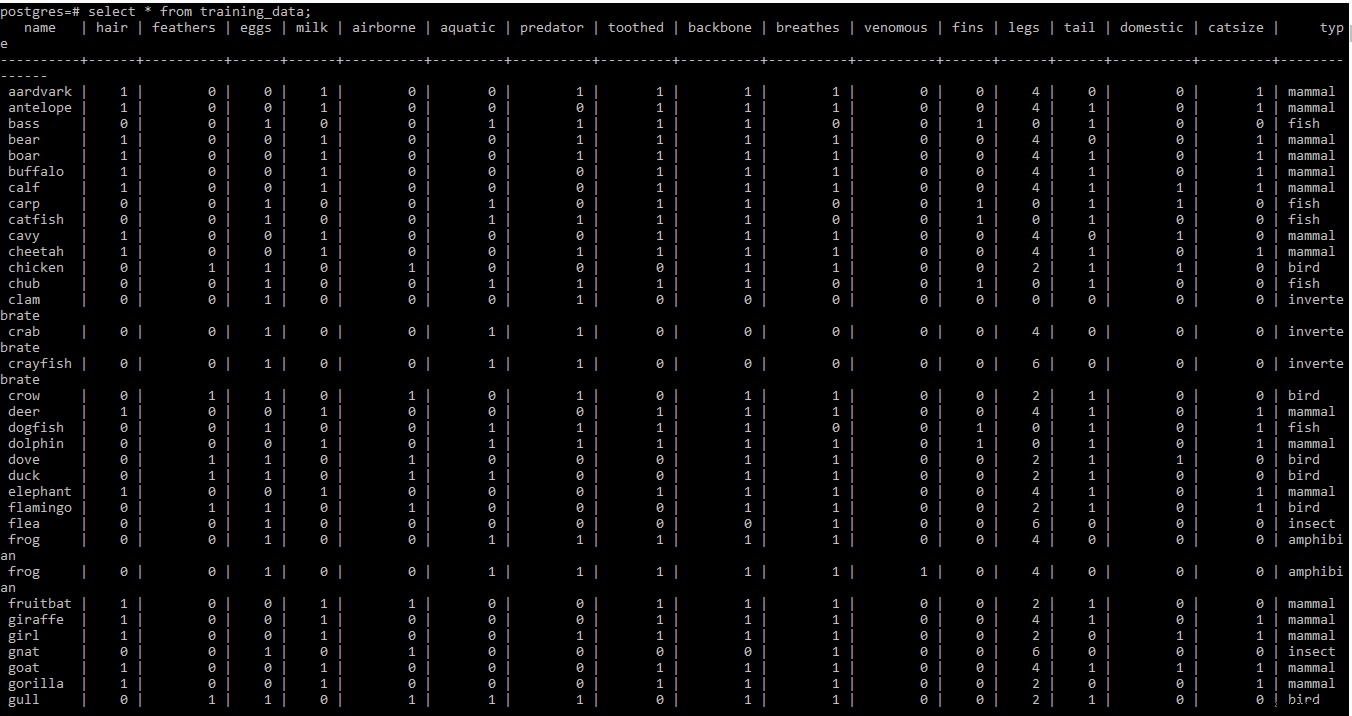
BEMÆRK: Række to og tre i træningsdatasættet på .fanen filen indeholder nogle metaoplysninger. Da det ikke er nødvendigt på dette tidspunkt, er det blevet fjernet fra filen.
Trin 2:Opret arbejdsgang med Orange
- Gå til skrivebordet, og dobbeltklik på det orange ikon.
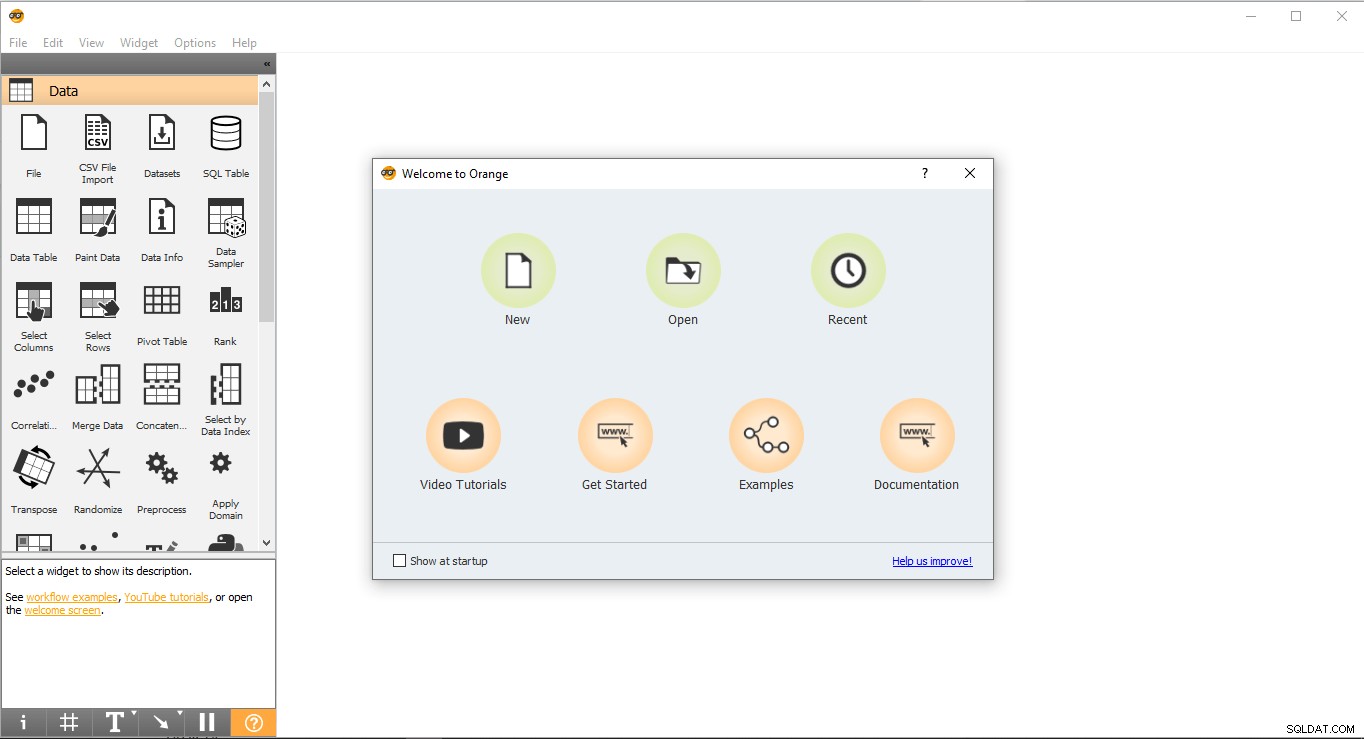
- Sådan ser opstartssiden ud. Vælg Ny mulighed, og det vil oprette et tomt projekt.

Nu er du klar til at anvende Machine Learning-modellen på datasættet.
Trin 3:Vælg Machine Learning-model for at træne dataene
Til denne artikel, k-nearest naboer (KNN) Machine Learning model bruges til at træne dataene. Når datatræningsprocessen er afsluttet, videregives testdata i næste trin til Forudsigelse widget til at kontrollere nøjagtigheden af forudsigelser.
Trin 4:Importer træningsdata fra PostgreSQL til Orange
Dette træningsdatasæt vil blive brugt til at træne Machine Learning-modellen.
- Træk og slip SQL-tabel widget fra Data menu.
- Omdøb widget (valgfrit)
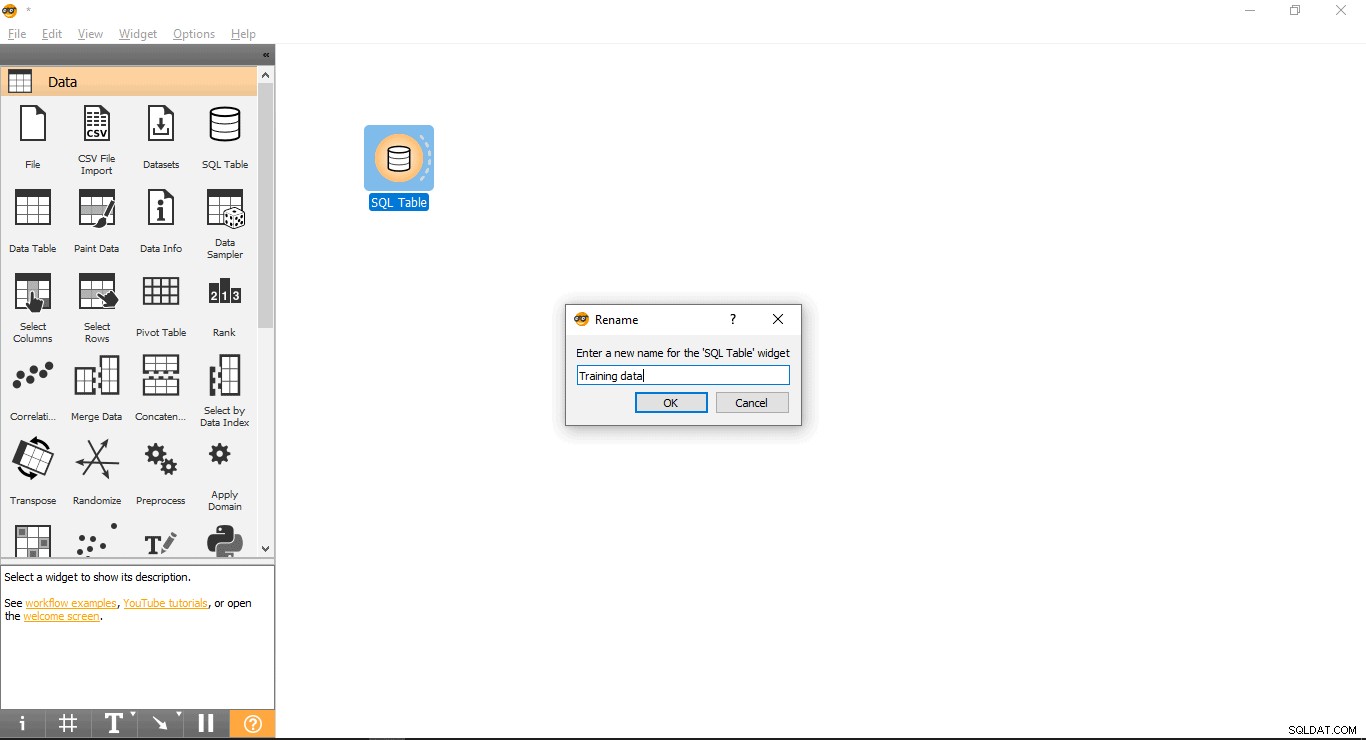
- Højreklik på SQL-tabellen widget.
- Vælg Omdøb .
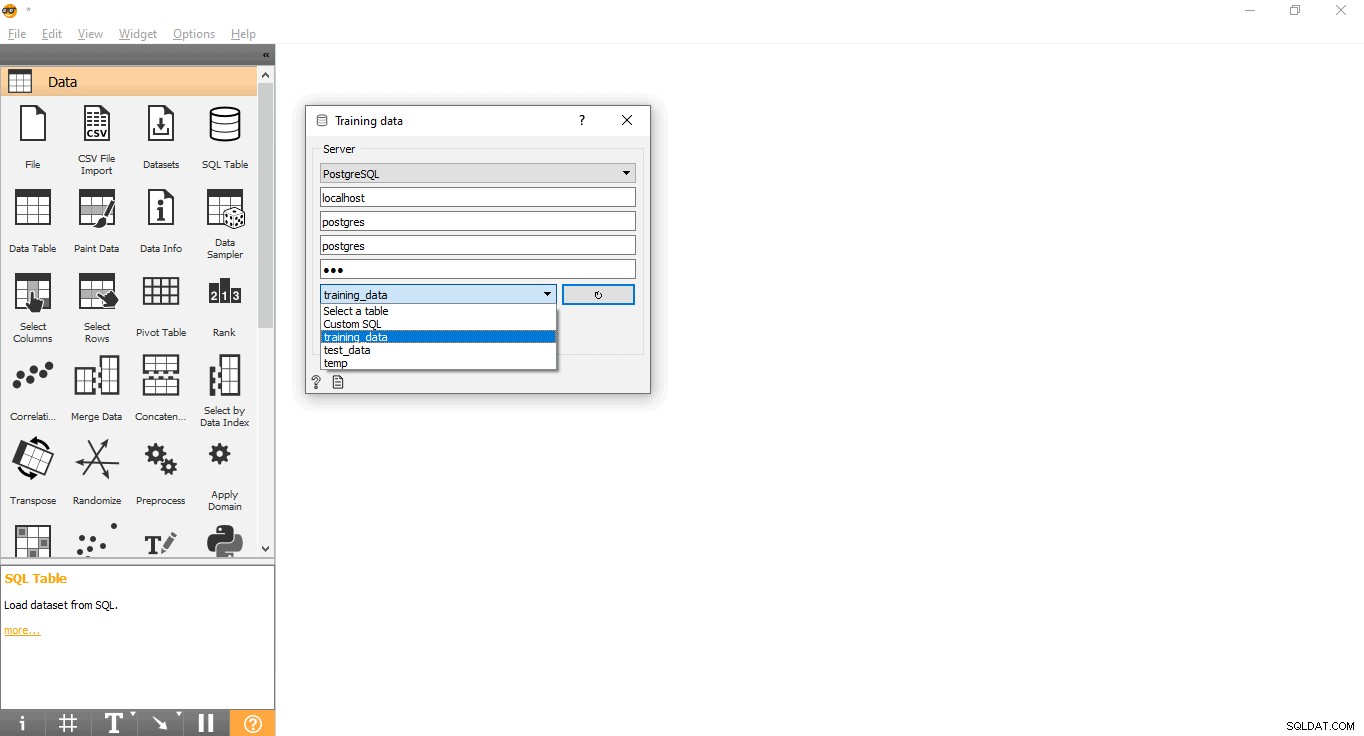
- Opret forbindelse til PostgreSQL for at indlæse træningsdatasættet:
- Dobbeltklik på Uddannelsesdata widget.
- Indtast legitimationsoplysninger for at oprette forbindelse til PostgreSQL-databasen.
- Tryk på genindlæs-knappen for at indlæse alle tilgængelige tabeller fra den givne database.
- Vælg træningsdata-tabel fra rullemenuen, og luk pop op-vinduet.
Trin 5:Tilføj målkolonne
Dette trin er vigtigt, fordi Machine Learning-modellen vil forsøge at forudsige dataene for denne målvariabel/-kolonne:
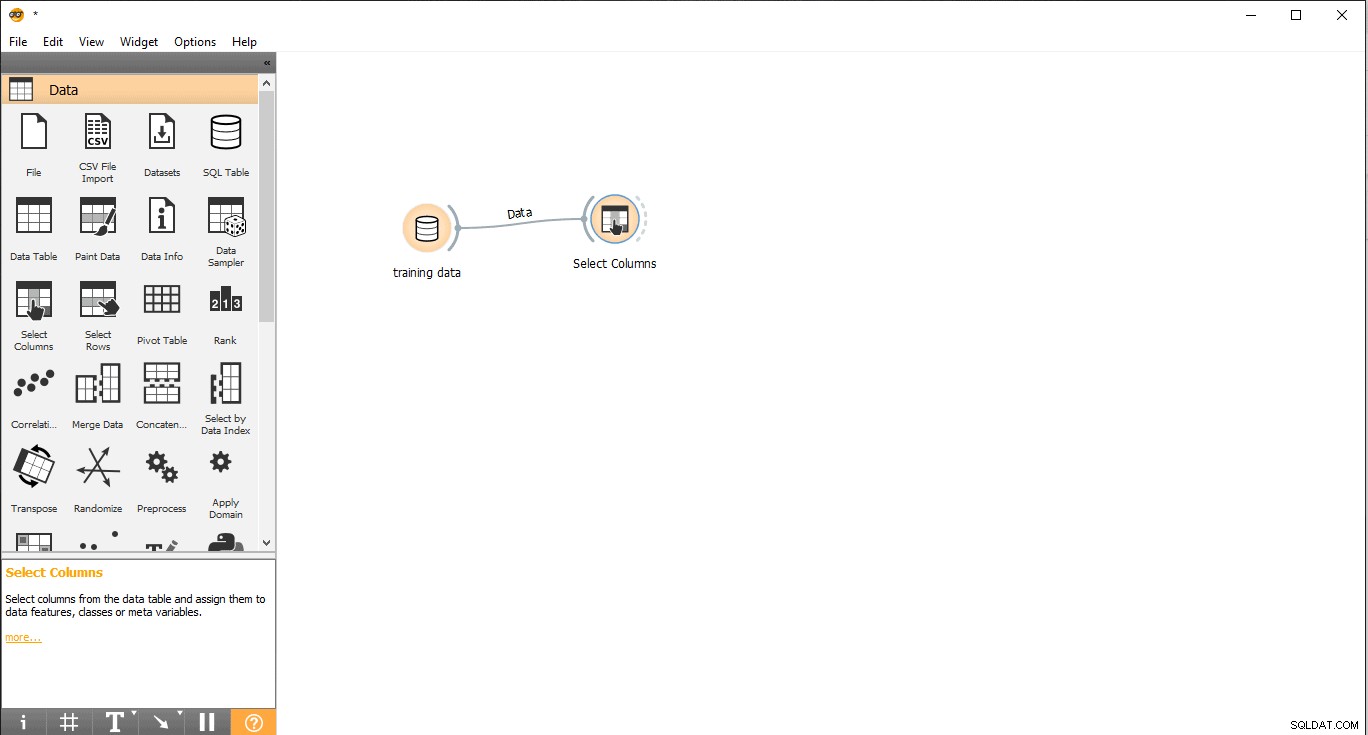
- Træk og slip Vælg kolonner widget fra data menu.
- Dobbeltklik på Vælg kolonner widget.
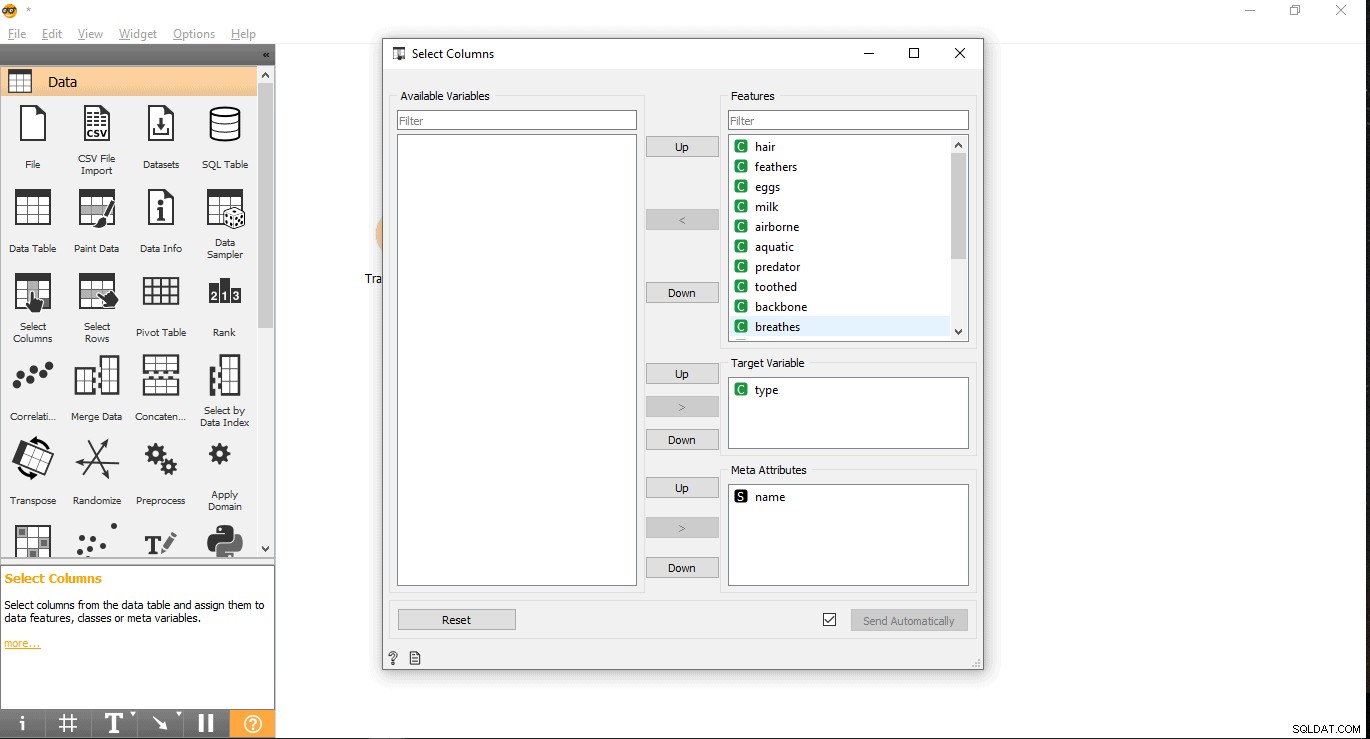
- Søg i din målkolonne under etiketten Funktioner. Her bruges type som målvariabel, fordi vi skal se, hvilken type et givent dyr er.
- Træk og slip det under Target Variable og luk pop op-vinduet.
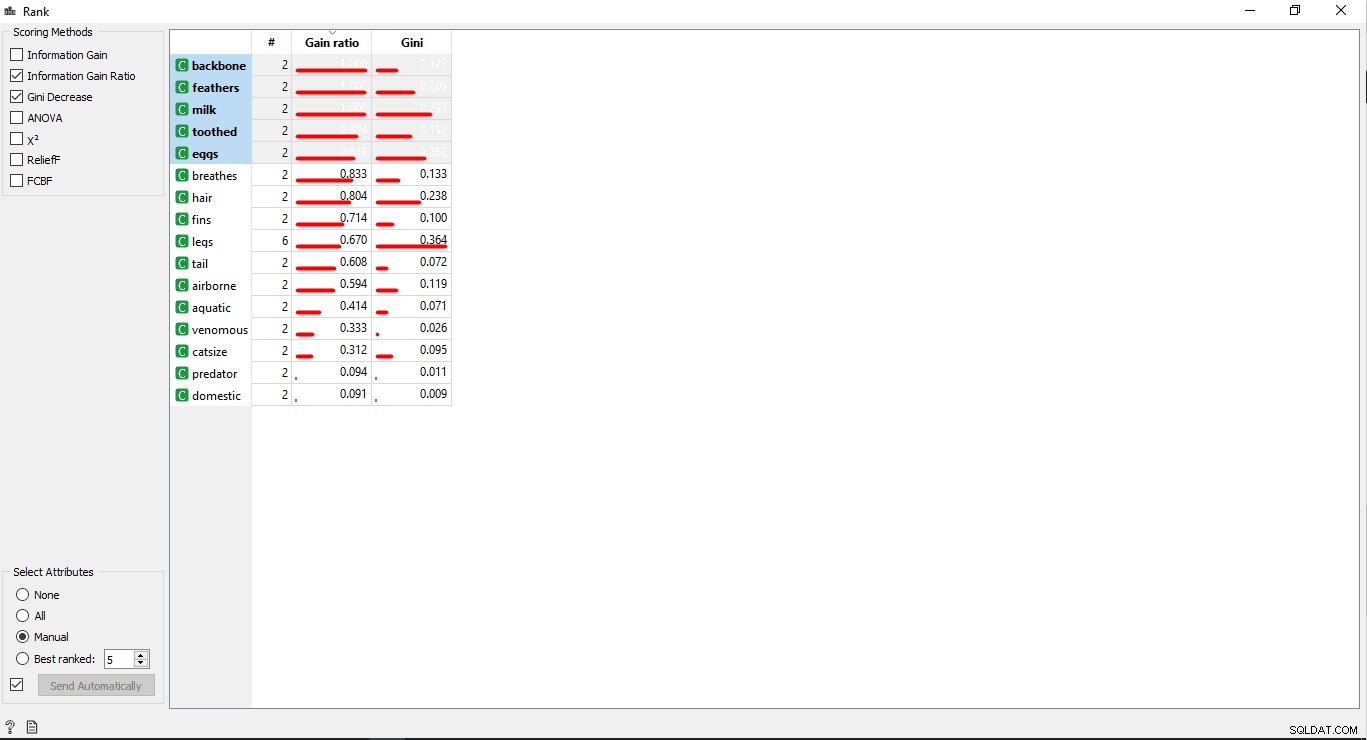
Trin 6:Kolonnerangering
Du kan rangere eller score træningsvariablen/-kolonnerne i henhold til deres korrelation med målkolonnen.
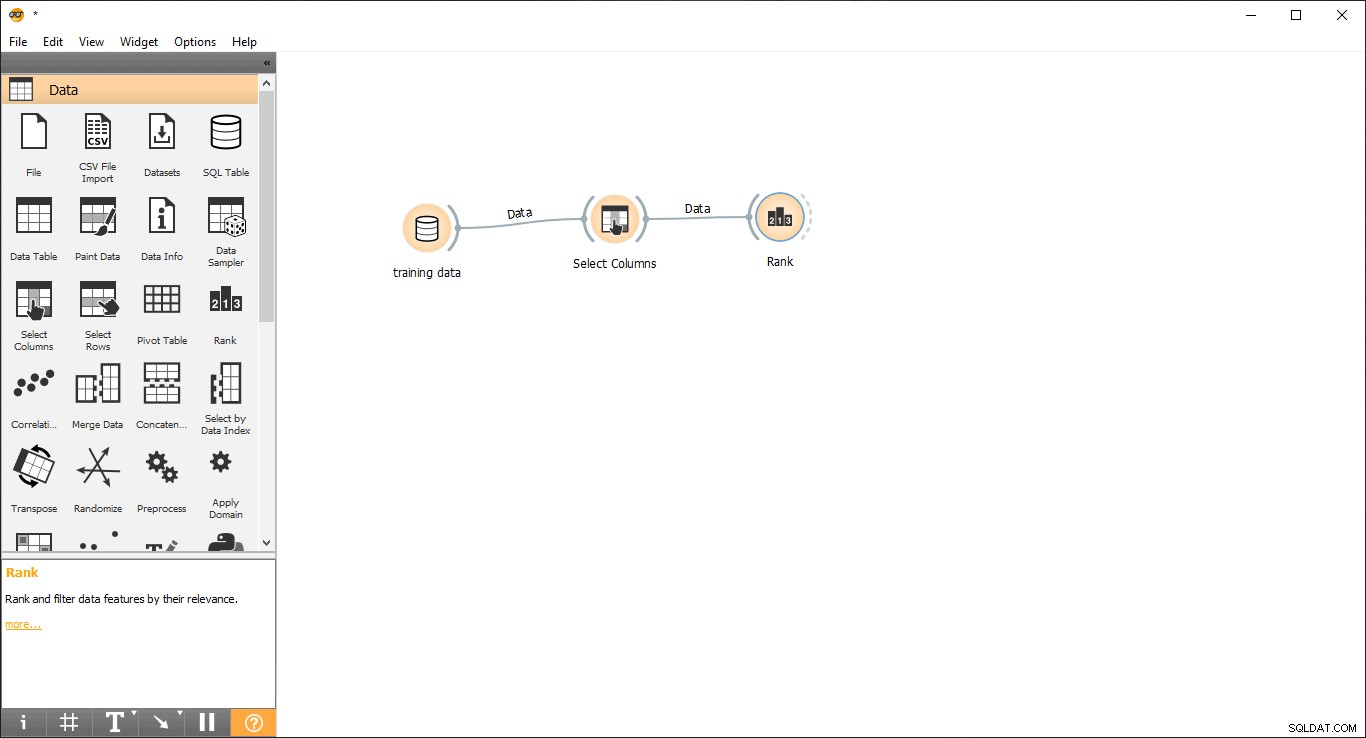
- Træk og slip Ranger widget fra data menu.
- Tegn en linklinje fra Vælg kolonner widget til Ranger widget .
- Dobbeltklik på Rank widget for at se de mest relaterede kolonner i træningsdatatabellen. Det vil som standard vælge de øverste 5 kolonner.
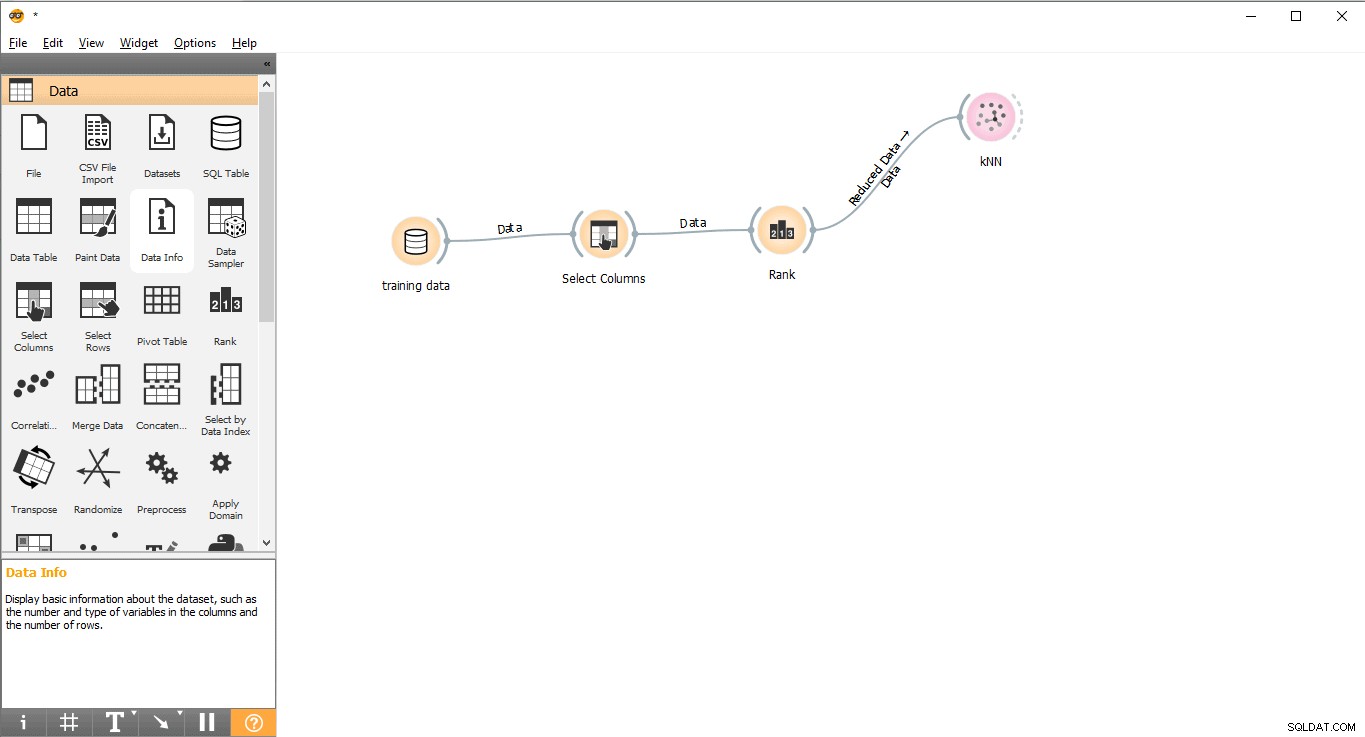
Trin 7:Datatræning
I dette trin vil Machine Learning Model (KNN) blive trænet med træningsdatasættet. Følg venligst følgende trin:
- Træk og slip KNN widget fra modellen menu.
- Tegn en linklinje fra Rank widget til KNN widget.
Trin 8:Indlæs testdatasæt i PostgreSQL
Et separat testdatasæt oprettes til at udføre forudsigelser. Følg venligst trinene for at indlæse testdatasæt i PostgreSQL-tabellen.
- Opret en tabel til at gemme vores testdata . Her er det navngivet som test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Indsæt testdata i testtabellen via COPY forespørgsel. Før du udfører COPY forespørgsel skal du sørge for, at PostgreSQL har krævet læsetilladelser på datafilen, ellers vil COPY-handlingen mislykkes.
BEMÆRK: Sørg for at indtaste en fane mellemrum mellem enkelte anførselstegn efter afgrænsningstegnet søgeord. Et spørgsmålstegn er bevidst placeret i typen kolonne i testdatasættet, fordi vi skal finde ud af typen af et givet dyr med vores Machine Learning-model.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Find venligst skærmbilledet af testdatasættet nedenfor

Trin 9:Importer testdataene fra PostgreSQL til Orange
Følg venligst følgende trin for at anvende forudsigelserne.
- Træk og slip SQL-tabel widget fra data menu.
- Omdøb widget (valgfrit)
- Højreklik på SQL-tabellen widget.
- Vælg Omdøb .
- Opret forbindelse til PostgreSQL for at indlæse testdata.
- Dobbeltklik på Test data widget.
- Forbind den med Testdata tabel fra PostgreSQL.
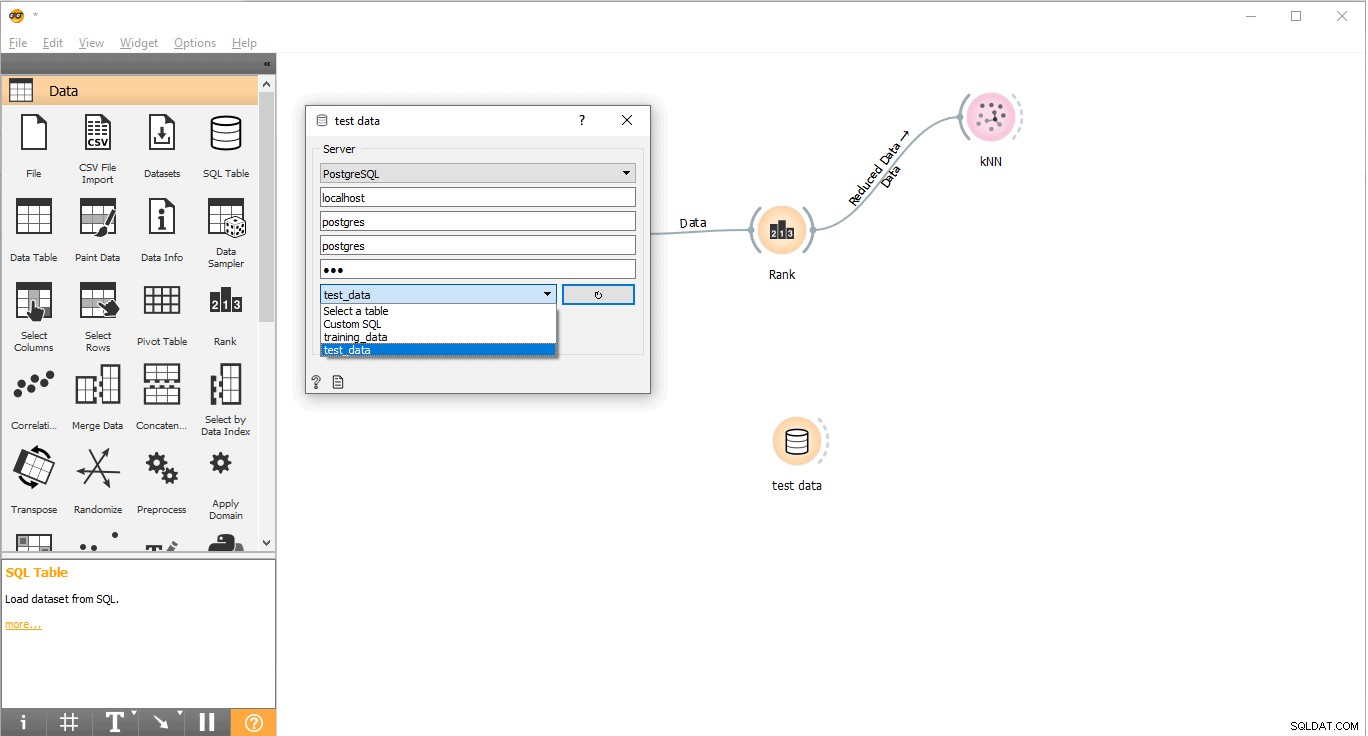
Nu er vi klar til at udføre forudsigelser.
Trin 10:Forudsigelser
Forudsigelse widget vil forsøge at forudsige testdata baseret på træningsdata fra KNN .
- Træk og slip Forudsigelse widget fra Evaluer menu.
- Tegn en linklinjeformular Testdata widget til Forudsigelse widget.
- Tegn en linklinje fra KNN widget til Forudsigelse widget.
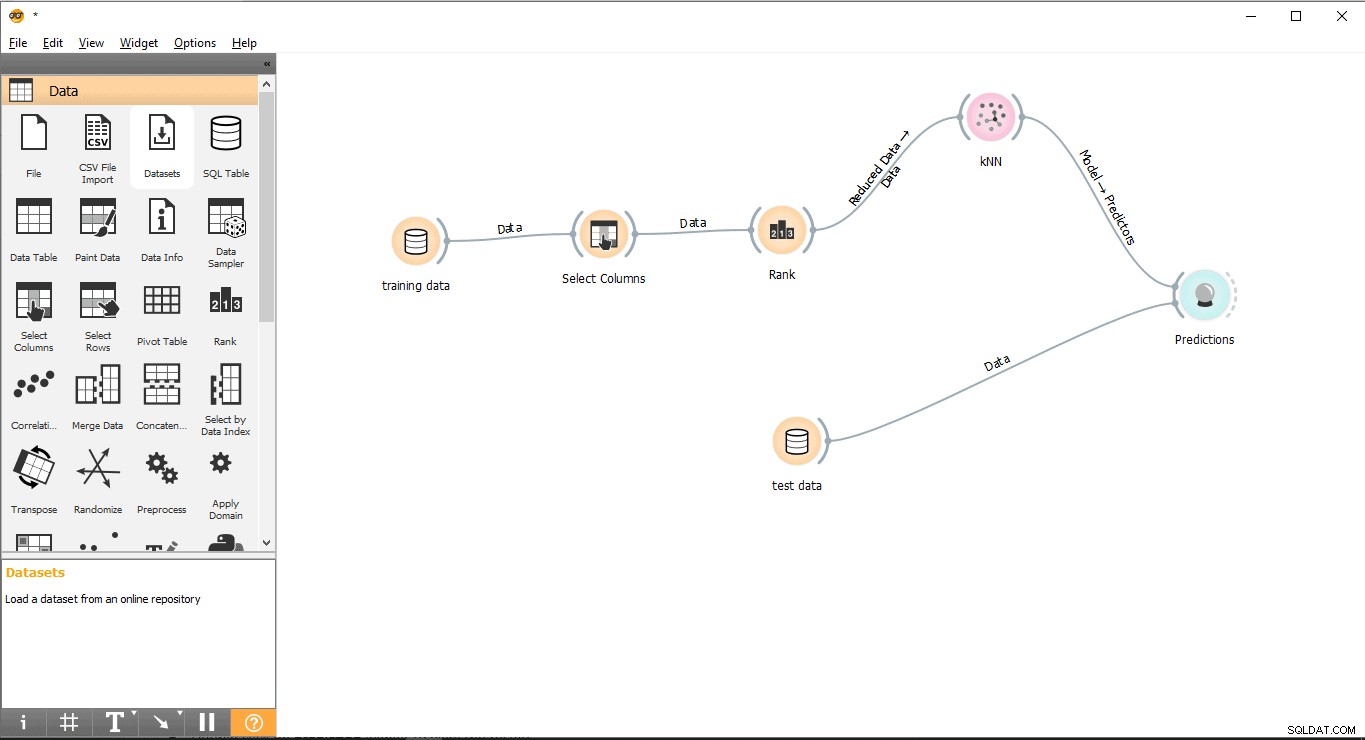
Trin 11:Resultater
Dobbeltklik på Forudsigelse widget for at se resultaterne.
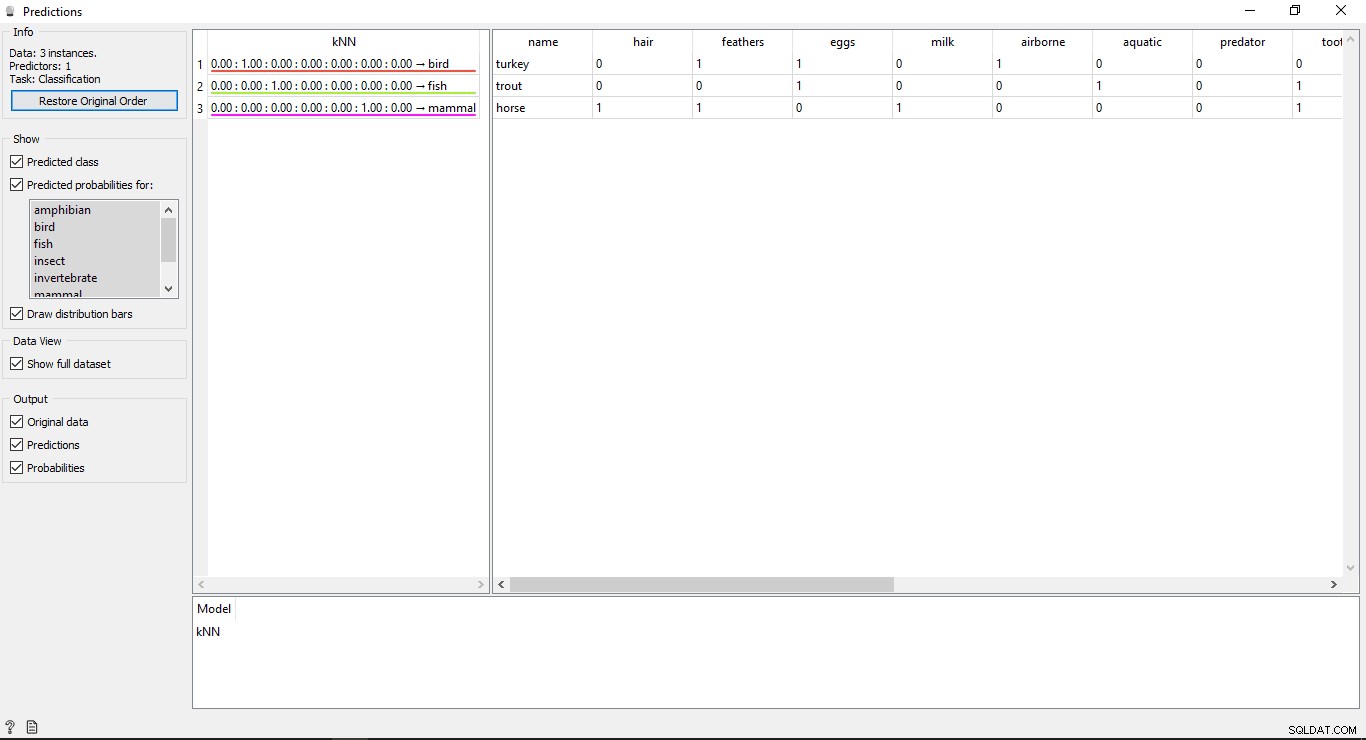
Forstå resultaterne
Du vil se 2 hovedtabeller i forudsigelsesvinduet. Tabellen til venstre viser de forudsagte resultater, mens tabellen til højre viser de originale testdata, som blev leveret til forudsigelser.
Siden KNN model blev brugt til at træne data, så du vil se en kolonne med navnet KNN der viser resultaterne.
Som vi ved:
- Hest er et pattedyr
- Ørred er en fisk
- Tyrkiet er en fugl
Så KNN er i stand til at bestemme alle typerne korrekt.
Forudsigelsers nøjagtighed
Hvis du ser tabellen til venstre i forudsigelseswidgettens output, har den nogle tal før den forudsagte type, dvs. 1,00. 0,00 Disse tal viser nøjagtigheden af den forudsagte type.
Vi har brugt 7 typer dyr i træningsdatasættet, så det viser et samlet antal på 7 kolonner med nøjagtighedsværdier, hver kolonne vil repræsentere 1 type dyr. Du kan kontrollere, hvilken kolonne der repræsenterer hvilken type dyr, ved at se på den tilgængelige liste i venstre side af din skærm under Forudsagte sandsynligheder for etiket. Hvis du ser på den første række, hvor der står Tyrkiet er en fugl . Vi kan se, at dens nøjagtighed er 1,00 (100 % fra 2. kolonne). Det samme gælder andre eksempler på ørred er en fisk og dens nøjagtighed er 1,00 (100 % fra 3. kolonne).
I denne artikel har vi brugt k-nearest neighbours’ algoritme (KNN) til at implementere Machine Learning-modellen. I den næste blog vil vi bruge Support Vector Machine (SVM) model.
For spørgsmål eller kommentarer, kontakt venligst kontaktformularen her.