Jeg havde fornøjelsen af at deltage i PGDay UK i sidste uge – en meget flot begivenhed, forhåbentlig får jeg chancen for at komme tilbage næste år. Der var masser af interessante foredrag, men den, der især fangede min opmærksomhed, var Performace for forespørgsler med gruppering af Alexey Bashtanov.
Jeg har holdt en del lignende præstationsorienterede foredrag tidligere, så jeg ved, hvor svært det er at præsentere benchmark-resultater på en forståelig og interessant måde, og Alexey gjorde et ret godt stykke arbejde, synes jeg. Så hvis du beskæftiger dig med dataaggregering (dvs. BI, analytics eller lignende arbejdsbelastninger), anbefaler jeg, at du går gennem slides, og hvis du får mulighed for at deltage i foredraget på en anden konference, anbefaler jeg stærkt at gøre det.
Men der er et punkt, hvor jeg er uenig i snakken. En række steder foreslog talen, at du generelt burde foretrække HashAggregate, fordi sortering er langsomme.
Jeg betragter dette som en smule misvisende, fordi et alternativ til HashAggregate er GroupAggregate, ikke Sort. Så anbefalingen antager, at hver GroupAggregate har en indlejret sortering, men det er ikke helt sandt. GroupAggregate kræver sorteret input, og en eksplicit sortering er ikke den eneste måde at gøre det på – vi har også IndexScan og IndexOnlyScan noder, der eliminerer sorteringsomkostningerne og bevarer de andre fordele forbundet med sorterede stier (især IndexOnlyScan).
Lad mig demonstrere, hvordan (IndexOnlyScan+GroupAggregate) klarer sig sammenlignet med både HashAggregate og (Sort+GroupAggregate) – scriptet, jeg har brugt til målingerne, er her. Den bygger fire simple tabeller, hver med 100 millioner rækker og forskellige antal grupper i kolonnen "branch_id" (bestemmer størrelsen af hash-tabellen). Den mindste har 10.000 grupper
-- tabel med 10k grupperopret tabel t_10000 (branch_id bigint, mængde numerisk); indsæt i t_10000 vælg mod(i, 10000), random() fra gener_series(1,100000000) s(i);
og tre ekstra borde har 100k, 1M og 5M grupper. Lad os køre denne enkle forespørgsel, der samler dataene:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
og overbevis derefter databasen om at bruge tre forskellige planer:
1) HashAggregate
SET enable_sort =off;SET enable_hashagg =on;EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1; FORESPØRGSPLAN -------------------------------------------- ---------------------------- HashAggregate (pris=2136943.00..2137067.99 rows=9999 width=40) Gruppenøgle:branch_id -> Seq Scan på t_10000 (pris=0,00..1636943,00 rows=100000000 width=19)(3 rækker)
2) GroupAggregate (med en sortering)
SET enable_sort =on;SET enable_hashagg =off;EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1; FORESPØRGSPLAN -------------------------------------------- ------------------------------- GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40) Group Key:branch_id -> Sorter (pris=16975438.38..17225438.38 rows=100000000 width=19) Sorteringsnøgle:branch_id -> Seq Scan på t_10000 (cost=0.00..1636943.000 rows) ...pre3) GroupAggregate (med en IndexOnlyScan)
SET enable_sort =on;SET enable_hashagg =off;CREATE INDEX ON t_10000 (branch_id, amount);EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1; FORESPØRGSPLAN -------------------------------------------- -------------------------- GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40) Group Key:branch_id -> Index Only Scan bruger t_10000_branch_id_amount_idx på t_10000 (cost=0.57..3483004.57 rows=100000000 width=19)(3 rows)Resultater
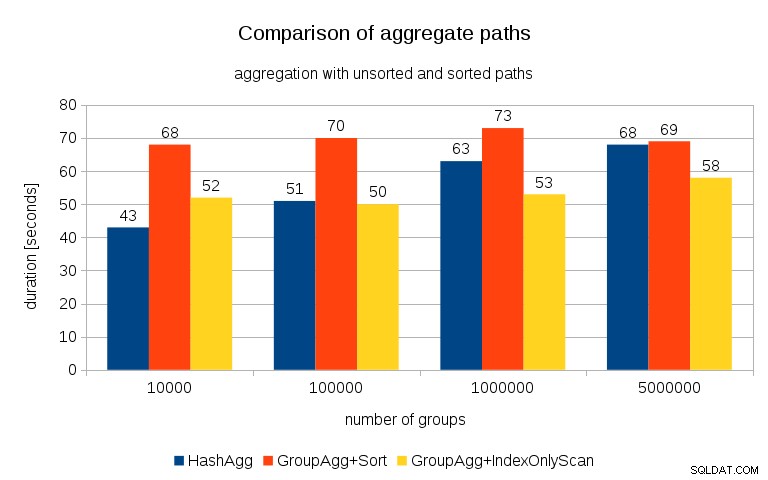
Efter at have målt timings for hver plan på alle tabellerne, ser resultaterne således ud:
For små hashtabeller (passer ind i L3-cache, som er 16MB i dette tilfælde), er HashAggregate-stien klart hurtigere end begge sorterede stier. Men ret hurtigt bliver GroupAgg+IndexOnlyScan lige så hurtigt eller endda hurtigere – dette skyldes cacheeffektivitet, den største fordel ved GroupAggregate. Mens HashAggregate skal beholde hele hash-tabellen i hukommelsen på én gang, behøver GroupAggregate kun at beholde den sidste gruppe. Og jo mindre hukommelse du bruger, jo mere sandsynligt er det, at det passer ind i L3-cachen, hvilket er nogenlunde en størrelsesorden hurtigere sammenlignet med almindelig RAM (for L1/L2-cachene er forskellen endnu større).
Så selvom der er en betydelig overhead forbundet med IndexOnlyScan (for 10k tilfældet er det omkring 20 % langsommere end HashAggregate-stien), da hashtabellen vokser, falder L3-cache-hitforholdet hurtigt, og forskellen gør til sidst GroupAggregate hurtigere. Og til sidst bliver selv GroupAggregate+Sort på niveau med HashAggregate-stien.
Du kan hævde, at dine data generelt har et ret lavt antal grupper, og derfor vil hash-tabellen altid passe ind i L3-cachen. Men overvej, at L3-cachen deles af alle processer, der kører på CPU'en, og også af alle dele af forespørgselsplanen. Så selvom vi i øjeblikket har ~20 MB L3-cache pr. socket, vil din forespørgsel kun få en del af det, og den bit vil blive delt af alle noder i din (muligvis ret komplekse) forespørgsel.
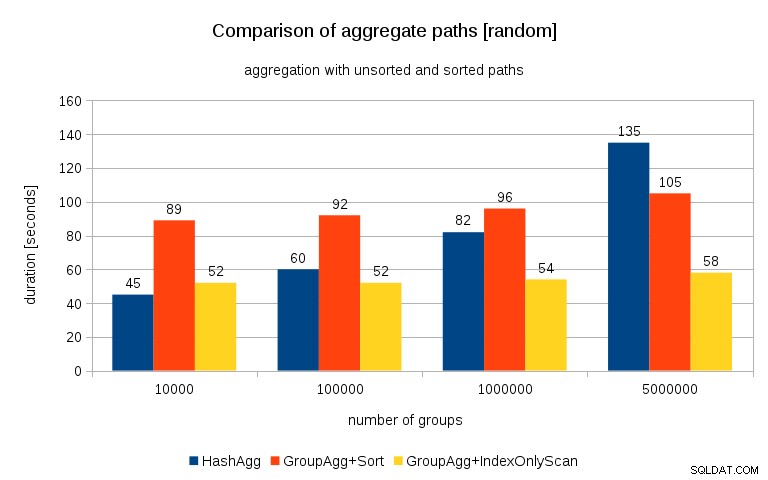
Opdatering 2016/07/26 :Som påpeget i kommentarerne af Peter Geoghegan, resulterer den måde, dataene blev genereret på, sandsynligvis i korrelation - ikke værdierne (eller rettere hash af værdierne), men hukommelsesallokeringer. Jeg har gentaget forespørgslerne med korrekt randomiserede data, dvs. gør
insert into t_10000 select (10000*random())::bigint, random() fra gener_series(1,100000000) s(i);i stedet for
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);og resultaterne ser således ud:
Sammenligner jeg dette med det forrige diagram, synes jeg, det er ret klart, at resultaterne er endnu mere til fordel for sorterede stier, især for datasættet med 5M-grupper. 5M datasættet viser også, at GroupAgg med en eksplicit sortering kan være hurtigere end HashAgg.
Oversigt
Mens HashAggregate sandsynligvis er hurtigere end GroupAggregate med en eksplicit sortering (jeg tøver dog med at sige, at det altid er tilfældet), kan det nemt gøres meget hurtigere at bruge GroupAggregate med IndexOnlyScan hurtigere end HashAggregate.
Selvfølgelig kan du ikke vælge den nøjagtige plan direkte - planlæggeren skal gøre det for dig. Men du påvirker udvælgelsesprocessen ved at (a) oprette indekser og (b) indstille
work_mem. Det er derfor nogle gange laverework_mem(ogmaintenance_work_mem) værdier resulterer i bedre ydeevne.Yderligere indekser er dog ikke gratis – de koster både CPU-tid (når der indsættes nye data) og diskplads. For IndexOnlyScans kan diskpladskravene være ret betydelige, fordi indekset skal inkludere alle de kolonner, der henvises til af forespørgslen, og almindelig IndexScan vil ikke give dig den samme ydeevne, da den genererer en masse tilfældige I/O mod tabellen (der eliminerer alle de potentielle gevinster).
En anden fin funktion er stabiliteten af ydeevnen – læg mærke til, hvordan HashAggregate-timings-chancen afhænger af antallet af grupper, mens GroupAggregate-stierne stort set udfører det samme.