I en tidligere blog havde vi diskuteret, hvordan man migrerer en selvstændig Moodle-opsætning til skalerbar opsætning baseret på en klynget database. Det næste trin, du skal tænke på, er failover-mekanismen - hvad gør du, hvis og når din databasetjeneste går ned.
En fejlbehæftet databaseserver er ikke usædvanlig, hvis du har MySQL-replikering som din backend Moodle-database, og hvis det sker, bliver du nødt til at finde en måde at genoprette din topologi ved for eksempel at promovere en standby-server til blive en ny primær server. At have automatisk failover til din Moodle MySQL-database hjælper med apps oppetid. Vi vil forklare, hvordan failover-mekanismer fungerer, og hvordan du indbygger automatisk failover i din opsætning.
Høj tilgængelighedsarkitektur til MySQL-database
Høj tilgængelighedsarkitektur kan opnås ved at gruppere din MySQL-database på et par forskellige måder. Du kan bruge MySQL-replikering, opsætte flere replikaer, der nøje følger din primære database. Oven i det kan du sætte en databasebelastningsbalancer til at opdele læse/skrive-trafikken og fordele trafikken på tværs af læse-skrive- og skrivebeskyttede noder. Database høj tilgængelighedsarkitektur ved hjælp af MySQL-replikering kan beskrives som nedenfor:
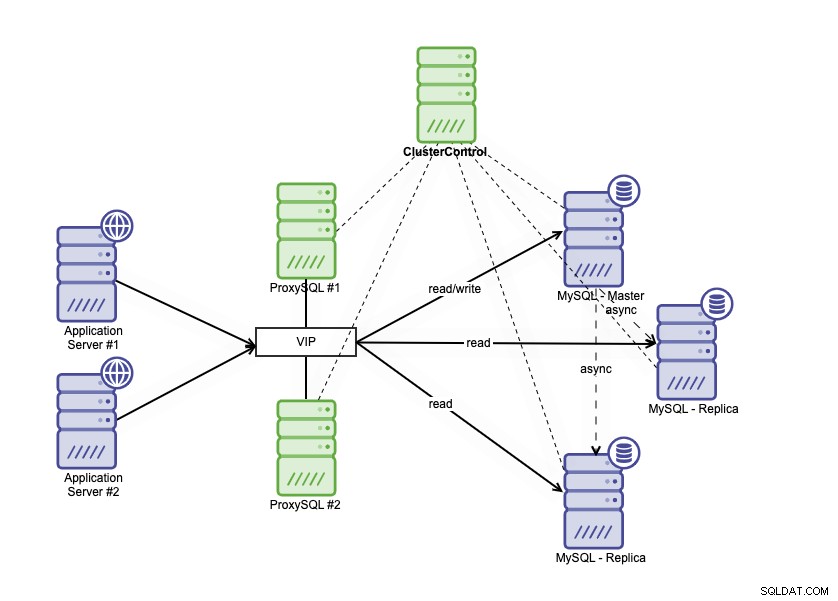
Den består af en primær database, to databasereplikaer og databasebelastningsbalancer (i denne blog bruger vi ProxySQL som databasebelastningsbalancer), og keepalived som en service til at overvåge ProxySQL-processerne. Vi bruger Virtuel IP-adresse som en enkelt forbindelse fra applikationen. Trafikken vil blive distribueret til den aktive load balancer baseret på rolleflaget i keepalved.
ProxySQL er i stand til at analysere trafikken og forstå, om en anmodning er en læsning eller en skrivning. Det vil derefter videresende anmodningen til den/de relevante vært(er).
Failover på MySQL-replikering
MySQL-replikering bruger binær logning til at replikere data fra den primære til replikaerne. Replikaerne forbinder til den primære node, og hver ændring repliceres og skrives til replika nodernes relælogfiler gennem IO_THREAD. Når ændringerne er gemt i relæloggen, fortsætter SQL_THREAD-processen med at anvende data i replikadatabasen.
Standardindstillingen for parameter read_only i en replika er TIL. Det bruges til at beskytte selve replikaen mod enhver direkte skrivning, så ændringerne vil altid komme fra den primære database. Dette er vigtigt, da vi ikke ønsker, at replikaen skal afvige fra den primære server. Failover-scenarie i MySQL-replikering sker, når den primære ikke er tilgængelig. Det kan der være mange årsager til; f.eks. servernedbrud eller netværksproblemer.
Du skal promovere en af replikaerne til primær, deaktiver skrivebeskyttet parameter på den promoverede replika, så den kan skrives. Du skal også ændre den anden replika for at oprette forbindelse til den nye primære. I GTID-tilstand behøver du ikke at notere det binære lognavn og position, hvorfra replikeringen skal genoptages. Men i traditionel binlog-baseret replikering skal du helt sikkert kende det sidste binære lognavn og position, hvorfra du skal fortsætte. Failover i binlog-baseret replikering er en ret kompleks proces, men selv failover i GTID-baseret replikering er heller ikke trivielt, da du skal passe på ting som fejlagtige transaktioner. At opdage en fejl er én ting, og så er det nok ikke muligt at reagere på fejlen inden for en kort forsinkelse uden automatisering.
Hvordan ClusterControl aktiverer automatisk failover
ClusterControl har mulighed for at udføre automatisk failover for din Moodle MySQL-database. Der er en automatisk gendannelse for klynge og node-funktion, som vil udløse failover-processen, når den primære database går ned.
Vi vil simulere, hvordan Automatisk Failover sker i ClusterControl. Vi vil få den primære database til at gå ned og bare se på ClusterControl-dashboardet. Nedenfor er den aktuelle topologi for klyngen:
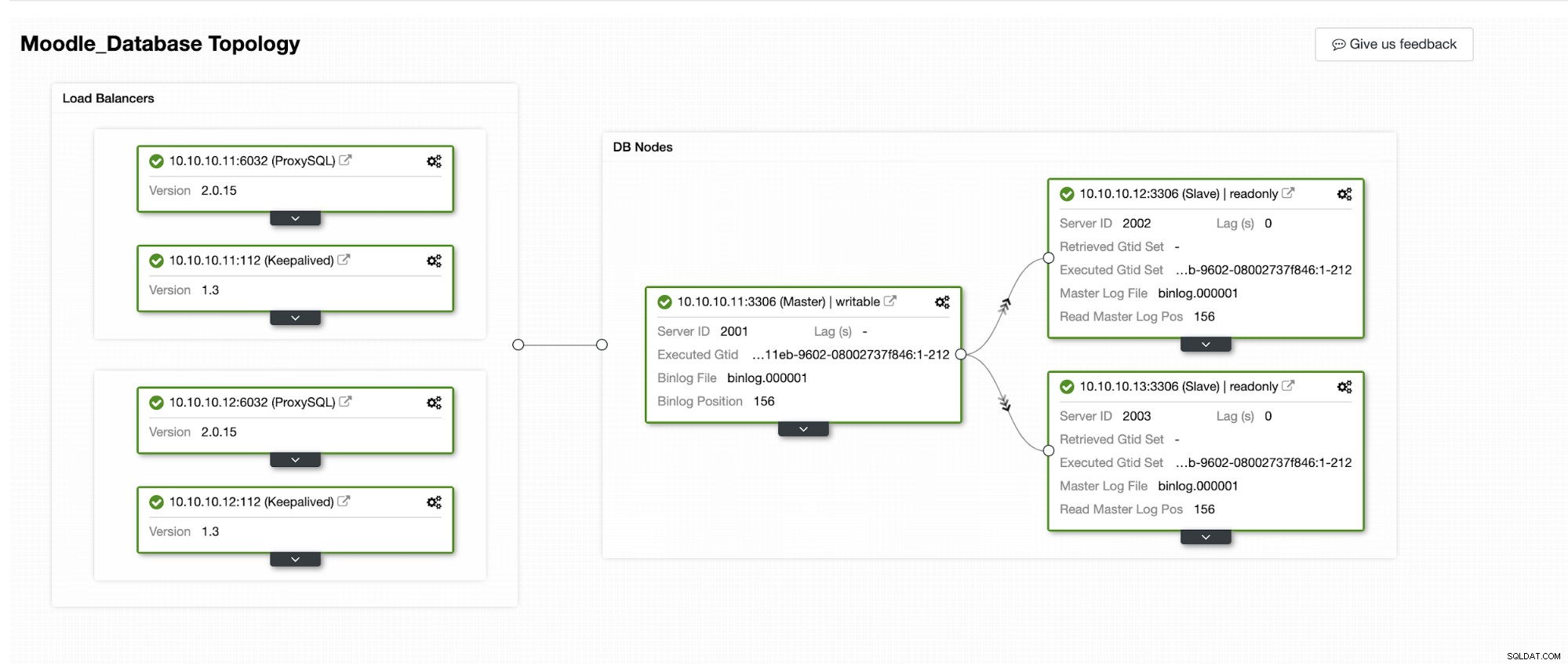
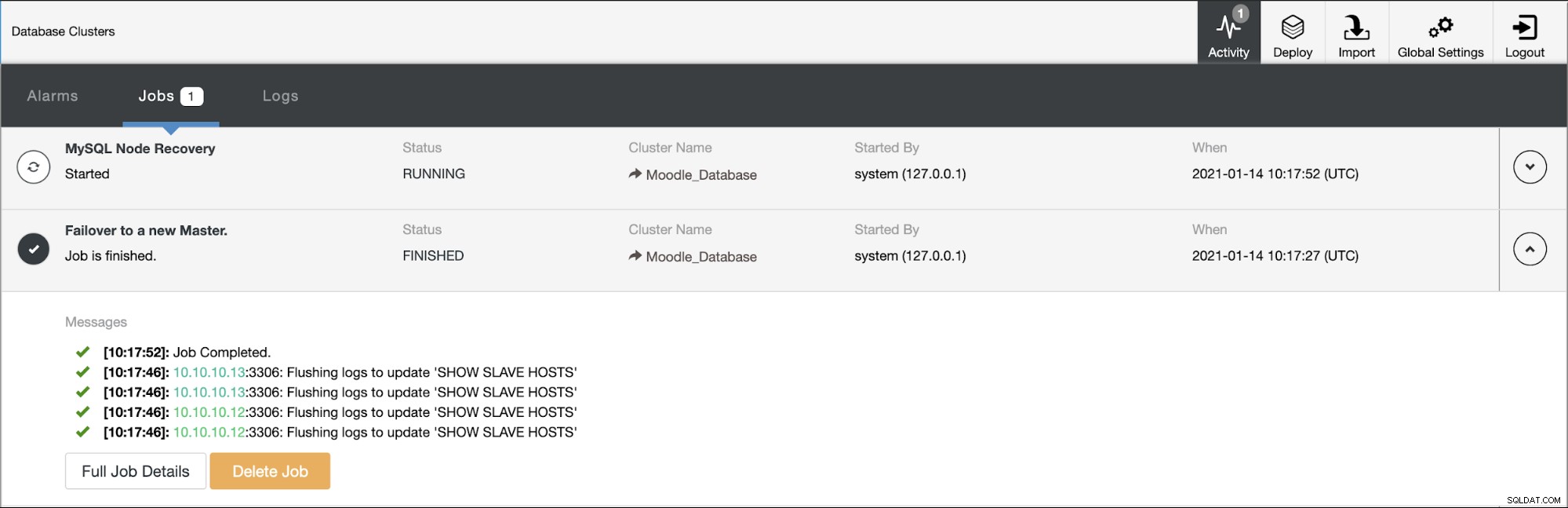
Den primære database bruger IP-adresse 10.10.10.11, og replikaerne er:10.10.10.12 og 10.10.10.13. Når nedbruddet sker på den primære, udløser ClusterControl en alarm, og en failover starter som vist på billedet nedenfor:
En af replikaerne vil blive forfremmet til primær, hvilket resulterer i Topologien som på nedenstående billede:
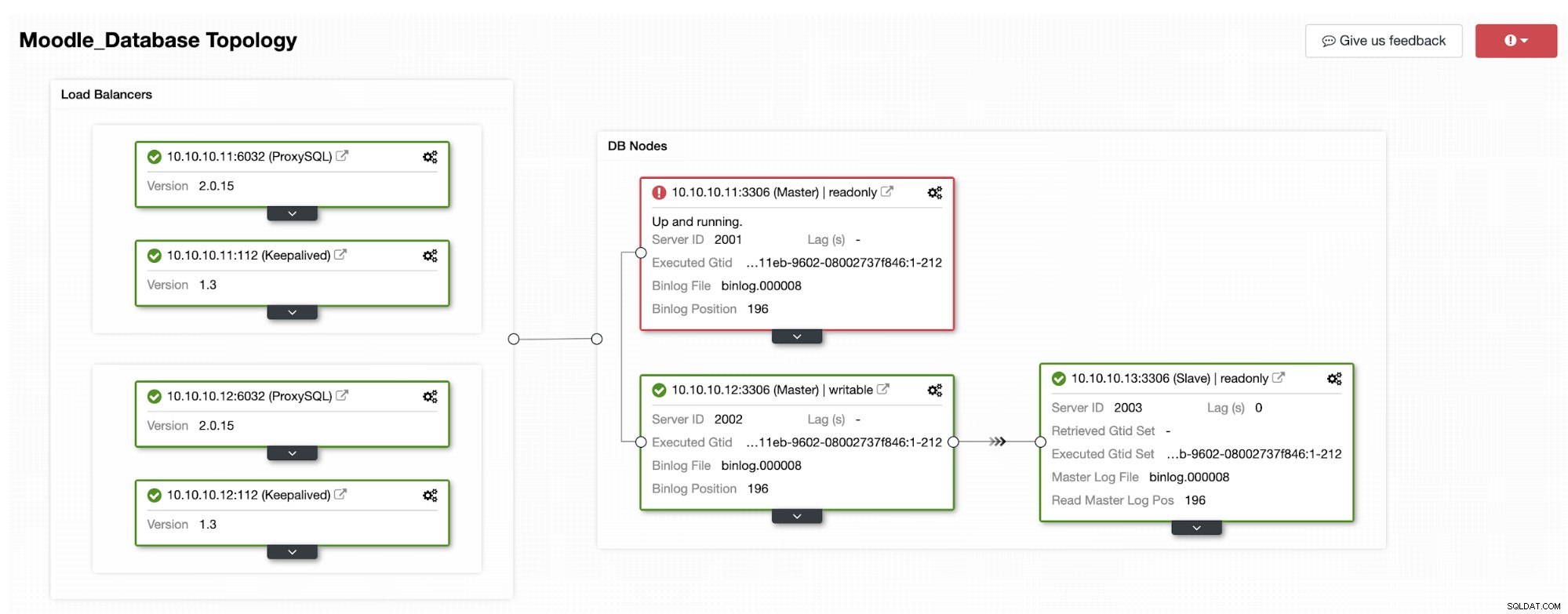
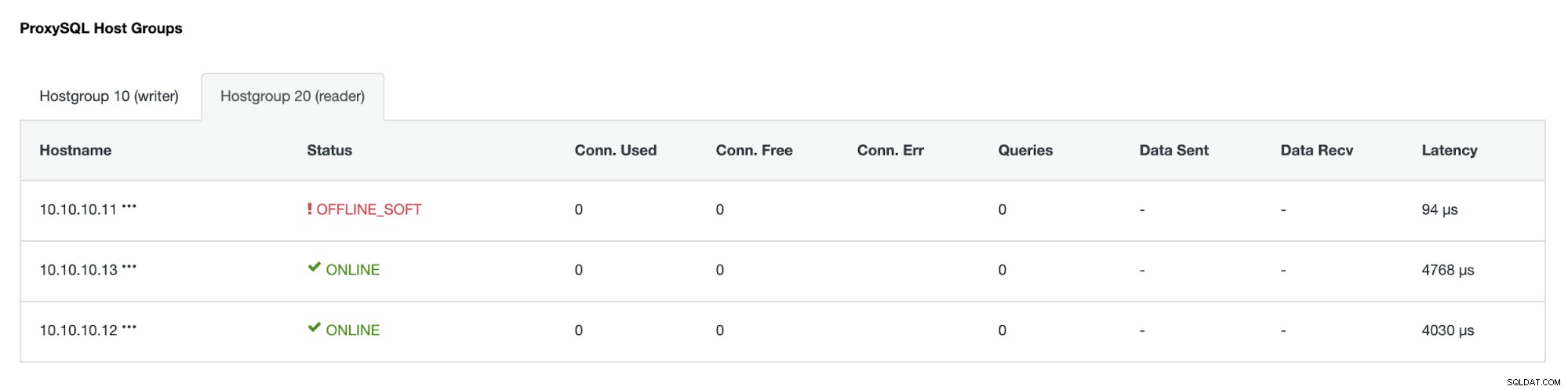
IP-adressen 10.10.10.12 tjener nu skrivetrafikken som primær, og vi står også tilbage med kun én replika, som har IP-adressen 10.10.10.13. På ProxySQL-siden vil proxyen automatisk registrere den nye primære. Hostgroup (HG10) betjener stadig skrivetrafikken, som har medlem 10.10.10.12 som vist nedenfor:

Hostgroup (HG20) kan stadig betjene læst trafik, men som du kan se noden 10.10.10.11 er offline på grund af nedbruddet :
Når den primære fejlbehæftede server kommer online igen, bliver den ikke automatisk gendannet -introduceret i databasetopologien. Dette er for at undgå at miste fejlfindingsoplysninger, da genindførelse af noden som en replika kan kræve overskrivning af nogle logfiler eller andre oplysninger. Men det er muligt at konfigurere auto-rejoin af den mislykkede node.