I informationsteknologiens verden er automatisering ikke noget nyt for de fleste af os. Faktisk bruger de fleste organisationer det til forskellige formål afhængigt af deres arbejdstype og mål. For eksempel bruger dataanalytikere automatisering til at generere rapporter, systemadministratorer bruger automatisering til deres gentagne opgaver som at rense diskplads, og udviklere bruger automatisering til at automatisere deres udviklingsproces.
I dag er der en masse automatiseringsværktøjer til IT tilgængelige og kan vælges takket være DevOps-æraen. Hvilket værktøj er det bedste? Svaret er et forudsigeligt 'det afhænger', da det afhænger af, hvad vi forsøger at opnå, samt vores miljøopsætning. Nogle af automatiseringsværktøjerne er Terraform, Bolt, Chef, SaltStack og et meget trendy er Ansible. Ansible er en open source agentløs it-motor, der kan automatisere applikationsimplementering, konfigurationsstyring og it-orkestrering. Ansible blev grundlagt i 2012 og er skrevet på det mest populære sprog, Python. Den bruger en playbook til at implementere al automatiseringen, hvor alle konfigurationer er skrevet på et sprog, der kan læses af mennesker, YAML.
I dagens indlæg skal vi lære, hvordan man bruger Ansible til at udføre Postgresql-databaseimplementering.
Hvad gør Ansible speciel?
Grunden til, at ansible bruges hovedsageligt på grund af dets funktioner. Disse funktioner er:
-
Alt kan automatiseres ved at bruge et simpelt menneskelæsbart sprog YAML
-
Ingen agent vil blive installeret på fjernmaskinen (agentløs arkitektur)
-
Konfigurationen vil blive pushet fra din lokale maskine til serveren fra din lokale maskine (push-model)
-
Udviklet ved hjælp af Python (et af de populære sprog, der bruges i øjeblikket), og mange biblioteker kan vælges fra
-
Samling af Ansible-moduler omhyggeligt udvalgt af Red Had Engineering Team
Sådan fungerer Ansible
Før Ansible kan køre operationelle opgaver til fjernværterne, skal vi installere det i én vært, som bliver controllerknudepunktet. I denne controller-knude vil vi orkestrere alle opgaver, som vi gerne vil udføre i fjernværterne, også kendt som administrerede noder.
Controllernoden skal have opgørelsen af de administrerede noder og Ansible-softwaren for at administrere den. De påkrævede data, der skal bruges af Ansible, f.eks. administreret nodes værtsnavn eller IP-adresse, vil blive placeret i denne beholdning. Uden en ordentlig opgørelse kunne Ansible ikke udføre automatiseringen korrekt. Se her for at lære mere om inventar.
Ansible er agentløs og bruger SSH til at skubbe ændringerne, hvilket betyder, at vi ikke behøver at installere Ansible i alle noder, men alle de administrerede noder skal have python og eventuelle nødvendige pythonbiblioteker installeret. Både controller-noden og administrerede noder skal indstilles som adgangskodeløse. Det er værd at nævne, at forbindelsen mellem alle controller-knudepunkter og administrerede noder er god og testet korrekt.
Til denne demo har jeg klargjort 4 Centos 8 VM'er ved at bruge vagrant. Den ene vil fungere som en controller-node, og de andre 2 VM'er vil fungere som databasenoder, der skal implementeres. Vi går ikke i detaljer om, hvordan man installerer Ansible i dette blogindlæg, men hvis du gerne vil se guiden, er du velkommen til at besøge dette link. Bemærk, at vi bruger 3 noder til at opsætte en streaming-replikeringstopologi med en primær og 2 standby-knudepunkter. I dag er mange produktionsdatabaser i en opsætning med høj tilgængelighed, og en opsætning med 3 noder er almindelig.
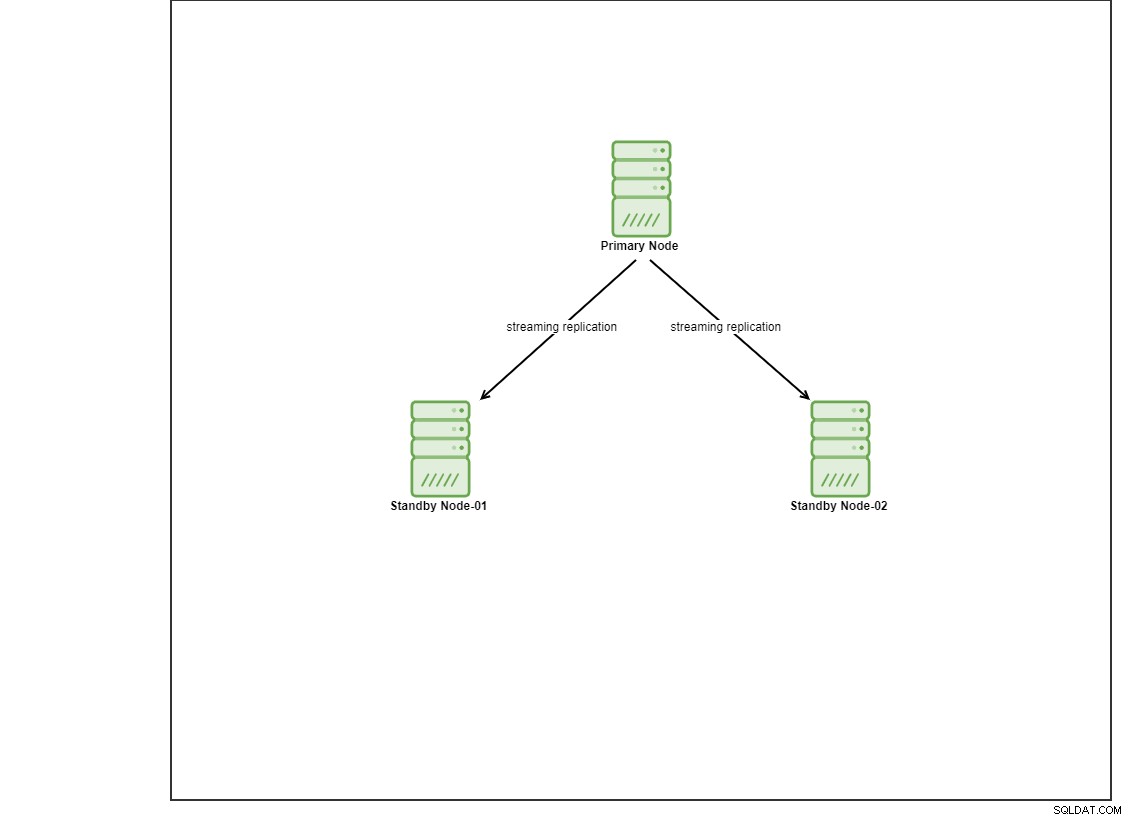
Installation af PostgreSQL
Der er flere måder at installere PostgreSQL på ved at bruge Ansible. I dag vil jeg bruge Ansible-roller til at opnå dette formål. Ansible roller i en nøddeskal er et sæt opgaver til at konfigurere en vært til at tjene et bestemt formål som at konfigurere en tjeneste. Ansible-roller defineres ved hjælp af YAML-filer med en foruddefineret mappestruktur, der kan downloades fra Ansible Galaxy-portalen.
Ansible Galaxy på den anden side er et opbevaringssted for Ansible-roller, der er tilgængelige for at falde direkte ind i dine Playbooks for at strømline dine automatiseringsprojekter.
Til denne demo har jeg valgt de roller, der er blevet vedligeholdt af dudefellah. For at vi kan bruge denne rolle, skal vi downloade og installere den til controller-noden. Opgaven er ret ligetil og kan udføres ved at køre følgende kommando, forudsat at Ansible er blevet installeret på din controller node:
$ ansible-galaxy install dudefellah.postgresql Du bør se følgende resultat, når rollen er installeret med succes i din controller-node:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
For at vi kan installere PostgreSQL ved hjælp af denne rolle, er der et par trin, der skal udføres. Her kommer Ansible Playbook. Ansible Playbook er, hvor vi kan skrive Ansible-kode eller en samling af de scripts, som vi gerne vil køre på de administrerede noder. Ansible Playbook bruger YAML og består af et eller flere afspilninger, der køres i en bestemt rækkefølge. Du kan definere værter såvel som et sæt opgaver, som du gerne vil køre på de tildelte værter eller administrerede noder.
Alle opgaver vil blive udført som den mulige bruger, der loggede ind. For at vi kan udføre opgaverne med en anden bruger inklusive 'root', kan vi gøre brug af blive. Lad os tage et kig på pg-play.yml nedenfor:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13 Som du kan se, har jeg defineret værterne som pgcluster og gør brug af bliver, så Ansible kører opgaverne med sudo-privilegiet. Brugervagrant er allerede i sudoer-gruppen. Jeg har også defineret den rolle, som jeg installerede dudefellah.postgresql. pgcluster er blevet defineret i hosts-filen, som jeg oprettede. Hvis du undrer dig over, hvordan det ser ud, kan du se nedenfor:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansible Ud over det har jeg oprettet en anden brugerdefineret fil (custom_var.yml), hvori jeg inkluderede al den konfiguration og indstilling for PostgreSQL, som jeg gerne vil implementere. Detaljerne for den brugerdefinerede fil er som nedenfor:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" } For at køre installationen er det eneste, vi skal gøre, at udføre følgende kommando. Du vil ikke kunne køre ansible-playbook-kommandoen uden den oprettede playbook-fil (i mit tilfælde er det pg-play.yml).
$ ansible-playbook pg-play.yml -i pghost Efter jeg har udført denne kommando, vil den køre et par opgaver defineret af rollen og vil vise denne meddelelse, hvis kommandoen kørte med succes:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12 Når ansible fuldførte opgaverne, loggede jeg på slaven (n2), stoppede PostgreSQL-tjenesten, fjernede indholdet af databiblioteket (/var/lib/pgsql/13/data/) og kør følgende kommando for at starte sikkerhedskopieringsopgaven:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size | Vi kan også kontrollere status for replikeringen på standby ved hjælp af følgende kommando, efter at vi startede PostgreSQL-tjenesten tilbage:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any Som du kan se, er der meget arbejde, der skal gøres, for at vi kan konfigurere replikeringen til PostgreSQL, selvom vi har automatiseret nogle af opgaverne. Lad os se, hvordan dette kan opnås med ClusterControl.
PostgreSQL-implementering ved hjælp af ClusterControl GUI
Nu hvor vi ved, hvordan vi implementerer PostgreSQL ved hjælp af Ansible, lad os se, hvordan vi kan implementere ved at bruge ClusterControl. ClusterControl er en administrations- og automatiseringssoftware til databaseklynger, herunder MySQL, MariaDB, MongoDB samt TimescaleDB. Det hjælper med at implementere, overvåge, administrere og skalere din databaseklynge. Der er to måder at implementere databasen på. I dette blogindlæg viser vi dig, hvordan du implementerer den ved hjælp af den grafiske brugergrænseflade (GUI), forudsat at du allerede har ClusterControl installeret på dit miljø.
Det første trin er at logge ind på din ClusterControl og klikke på Implementer:
Du vil blive præsenteret for skærmbilledet nedenfor for det næste trin i implementeringen , vælg fanen PostgreSQL for at fortsætte:
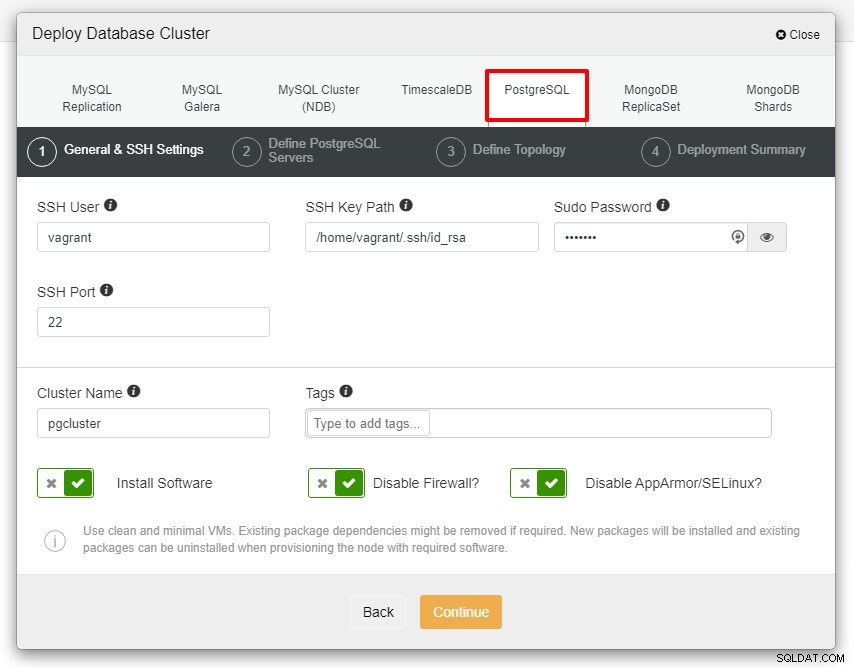
Før vi går videre, vil jeg gerne minde dig om, at forbindelsen mellem ClusterControl-noden og databasenoderne skal være uden adgangskode. Inden implementeringen skal vi kun generere ssh-keygen fra ClusterControl-noden og derefter kopiere den til alle noderne. Udfyld input for SSH-bruger, Sudo-adgangskode samt klyngenavn i henhold til dit krav, og klik på Fortsæt.
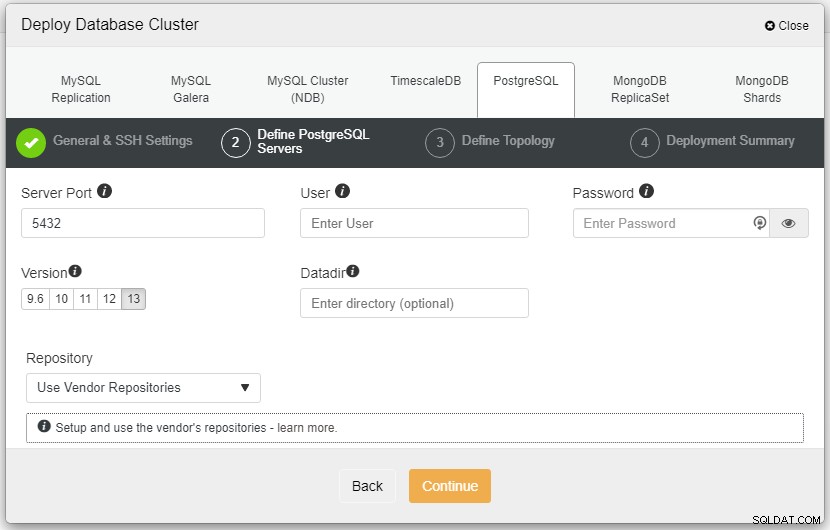
I skærmbilledet ovenfor skal du definere serverporten (i tilfælde af at du gerne vil bruge andre), den bruger du gerne vil have, samt adgangskoden og den version, du ønsker at installere.
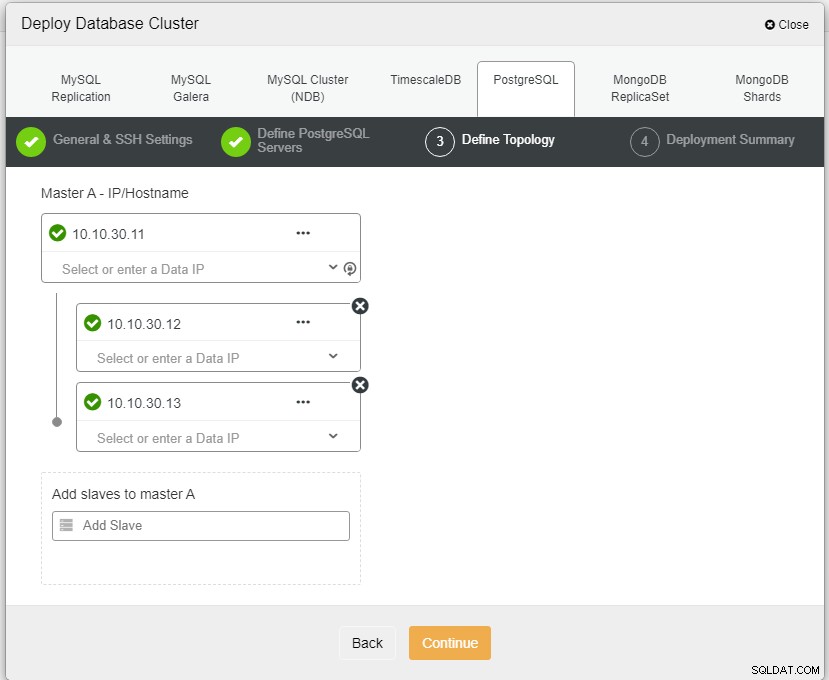
Her skal vi definere serverne enten ved at bruge værtsnavnet eller IP-adressen, som i dette tilfælde 1 master og 2 slaver. Det sidste trin er at vælge replikeringstilstanden for vores klynge.
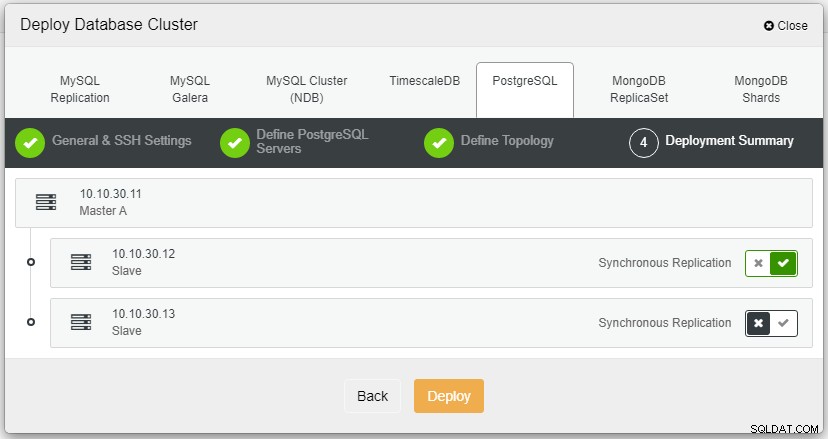
Når du har klikket på Implementer, starter implementeringsprocessen, og vi kan overvåge fremskridtene på fanen Aktivitet.
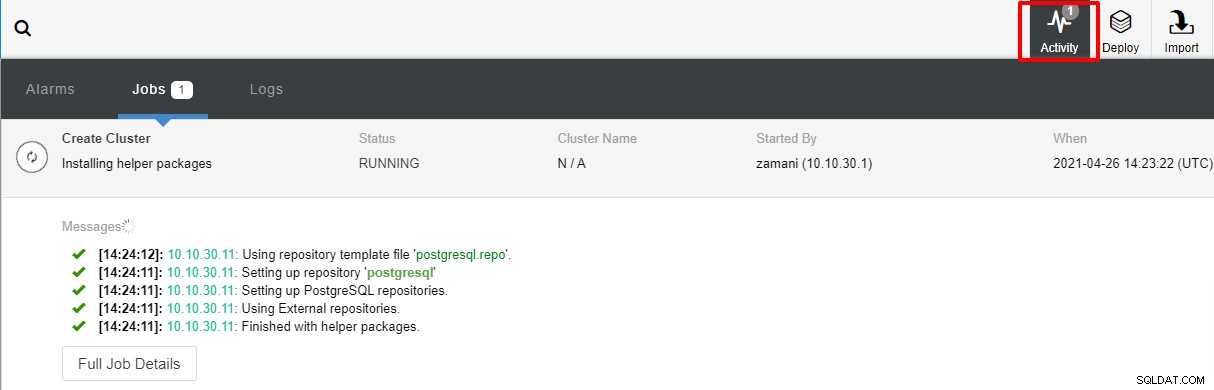
Implementeringen vil normalt tage et par minutter, ydeevne afhænger for det meste af netværket og serverens specifikationer.

Nu hvor vi har PostgreSQL installeret ved hjælp af ClusterControl.
PostgreSQL-implementering ved hjælp af ClusterControl CLI
Den anden alternative måde at implementere PostgreSQL på er ved at bruge CLI. forudsat at vi allerede har konfigureret den adgangskodeløse forbindelse, kan vi bare udføre følgende kommando og lade den afslutte.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --log Du bør se meddelelsen nedenfor, når processen er fuldført, og du kan logge ind på ClusterControl-webstedet for at bekræfte:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token. Konklusion
Som du kan se, er der et par måder at implementere PostgreSQL på. I dette blogindlæg har vi lært, hvordan man implementerer det ved at bruge Ansible og samt bruge vores ClusterControl. Begge måder er nemme at følge og kan opnås med en minimal indlæringskurve. Med ClusterControl kan streaming-replikeringsopsætningen suppleres med HAProxy, VIP og PGBouncer for at tilføje forbindelsesfejl, virtuel IP og forbindelsespooling til opsætningen.
Bemærk, at implementering kun er ét aspekt af et produktionsdatabasemiljø. At holde det oppe og køre, automatisere failovers, gendanne ødelagte noder og andre aspekter som overvågning, alarmering, sikkerhedskopier er afgørende.
Forhåbentlig vil dette blogindlæg gavne nogle af jer og give en idé om, hvordan man automatiserer PostgreSQL-implementeringer.