Et proxylag kan være ret nyttigt til at øge tilgængeligheden af dit databaselag. Det kan reducere mængden af kode på applikationssiden for at håndtere databasefejl og ændringer i replikeringstopologi. I dette blogindlæg vil vi diskutere, hvordan man opsætter en HAProxy til at fungere oven på PostgreSQL.
Første ting først - HAProxy arbejder med databaser som en proxy på netværkslag. Der er ingen forståelse af den underliggende, nogle gange komplekse, topologi. Alt hvad HAProxy gør er at sende pakker på round-robin måde til definerede backends. Det inspicerer ikke pakker, og det forstår heller ikke protokol, hvor applikationer taler med PostgreSQL. Som et resultat er der ingen måde for HAProxy at implementere læse/skrive-opdeling på en enkelt port - det ville kræve parsing af forespørgsler. Så længe din applikation kan opdele læsninger fra skrivninger og sende dem til forskellige IP'er eller porte, kan du implementere R/W-opdeling ved hjælp af to backends. Lad os tage et kig på, hvordan det kan gøres.
HAProxy-konfiguration
Nedenfor kan du finde et eksempel på to PostgreSQL-backends konfigureret i HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkSom vi kan se, bruger de porte 3307 til at skrive og 3308 til at læse. I denne opsætning er der tre servere - en aktiv og to standby-replikaer. Hvad der er vigtigt, bruges tcp-check til at spore nodernes sundhed. HAProxy vil oprette forbindelse til port 9201, og den forventer at se en streng returneret. Raske medlemmer af backend vil returnere forventet indhold, de, der ikke returnerer strengen, vil blive markeret som utilgængelige.
Xinetd-opsætning
Da HAProxy tjekker port 9201, er der noget, der skal lytte på den. Vi kan bruge xinetd til at lytte der og køre nogle scripts for os. Eksempel på konfiguration af en sådan tjeneste kan se sådan ud:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Du skal sørge for at tilføje linjen:
postgreschk 9201/tcptil /etc/services.
Xinetd starter et postgreschk-script, som har indhold som nedenfor:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Scriptets logik går som følger. Der er to forespørgsler, som bruges til at detektere nodens tilstand.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Den første kontrollerer, om PostgreSQL er under gendannelse - den vil være 'falsk' for den aktive server og 'sand' for standby-servere. Den anden kontrollerer, om PostgreSQL er i skrivebeskyttet tilstand. Den aktive server vender tilbage 'fra', mens standby-servere vender tilbage 'til'. Baseret på resultaterne kalder scriptet return_ok()-funktionen med en rigtig parameter ('master' eller 'slave', afhængig af hvad der blev opdaget). Hvis forespørgslerne mislykkedes, vil en 'return_fail'-funktion blive udført.
Return_ok-funktionen returnerer en streng baseret på argumentet, som blev sendt til den. Hvis værten er en aktiv server, vil scriptet returnere "PostgreSQL master kører". Hvis det er en standby, vil den returnerede streng være:"PostgreSQL slave kører". Hvis tilstanden ikke er klar, vender den tilbage:"PostgreSQL kører". Det er her løkken slutter. HAProxy kontrollerer tilstanden ved at oprette forbindelse til xinetd. Sidstnævnte starter et script, som derefter returnerer en streng, som HAProxy parser.
Som du måske husker, forventer HAProxy følgende strenge:
tcp-check expect string master\ is\ runningfor skrive-backend og
tcp-check expect string is\ running.for den skrivebeskyttede backend. Dette gør den aktive server til den eneste tilgængelige vært i skrive-backend, mens både aktive og standby-servere kan bruges på læse-backend.
PostgreSQL og HAProxy i ClusterControl
Opsætningen ovenfor er ikke kompleks, men det tager noget tid at sætte den op. ClusterControl kan bruges til at indstille alt dette for dig.
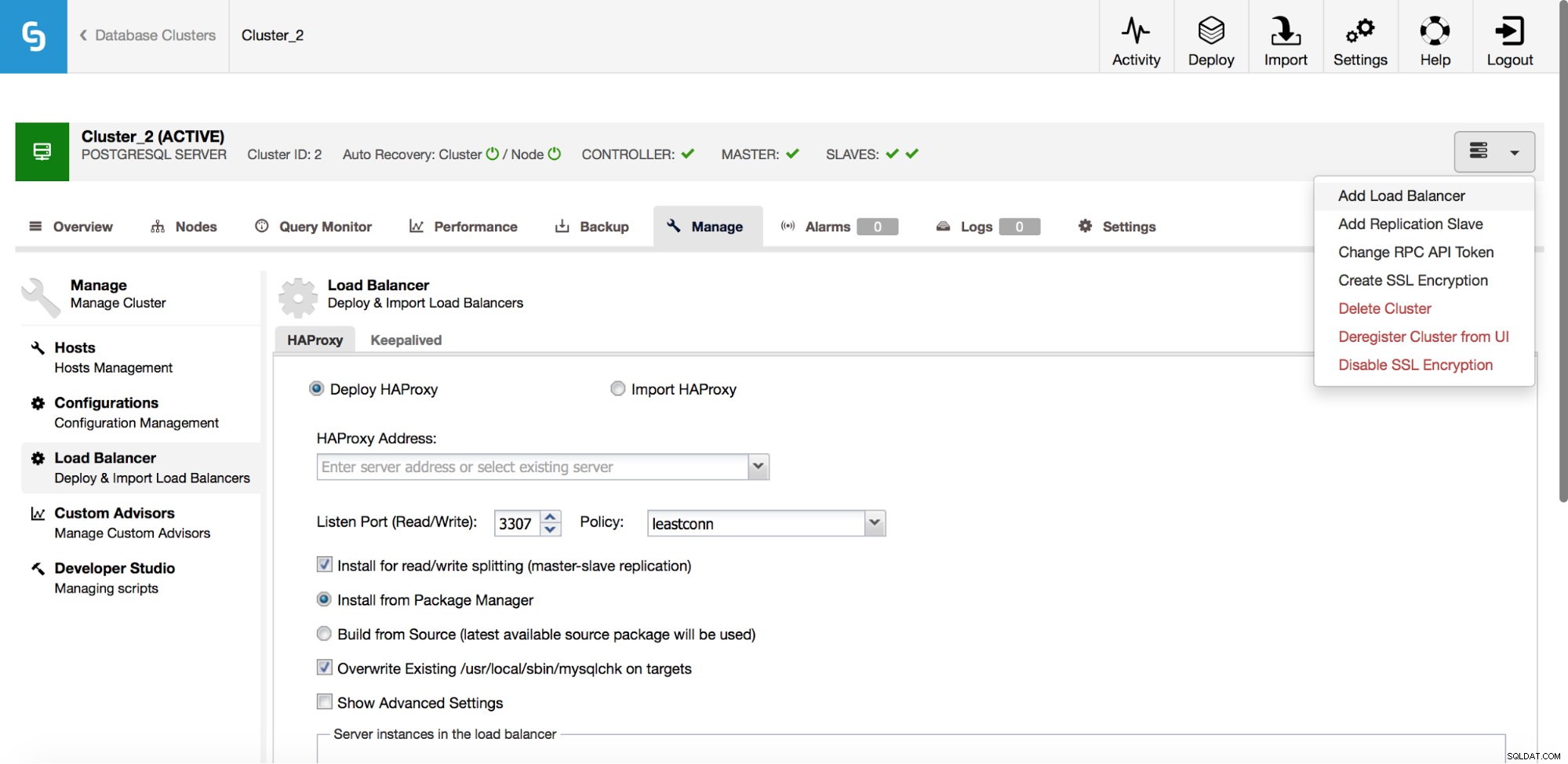
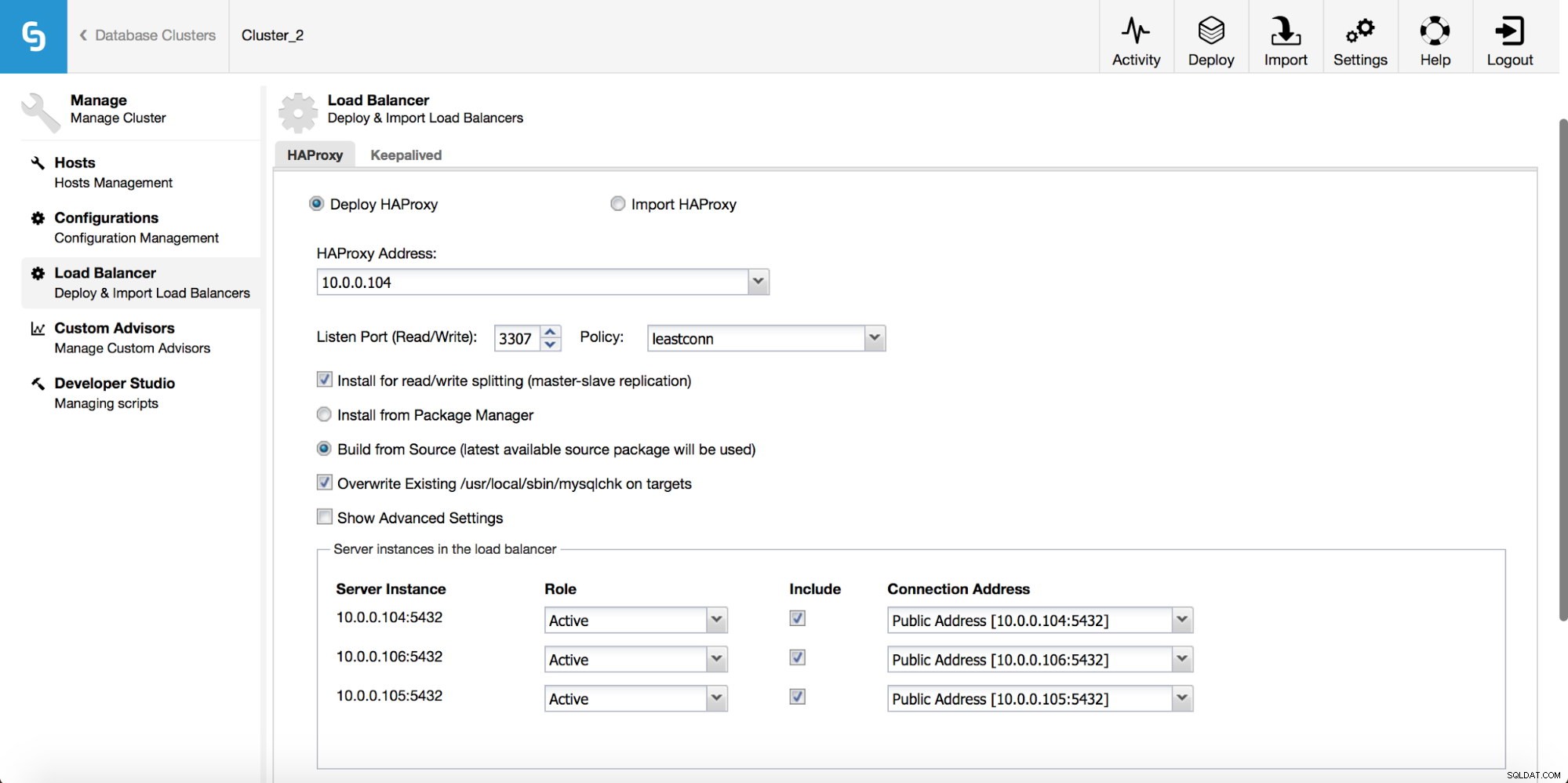
I rullemenuen for klyngejob har du mulighed for at tilføje en belastningsbalancer. Så dukker en mulighed for at implementere HAProxy op. Du skal udfylde, hvor du vil installere det, og tage nogle beslutninger:fra de lagre, som du har konfigureret på værten eller den seneste version, kompileret fra kildekoden. Du skal også konfigurere, hvilke noder i klyngen du vil føje til HAProxy.
Når HAProxy-forekomsten er implementeret, kan du få adgang til nogle statistikker på fanen "Noder":
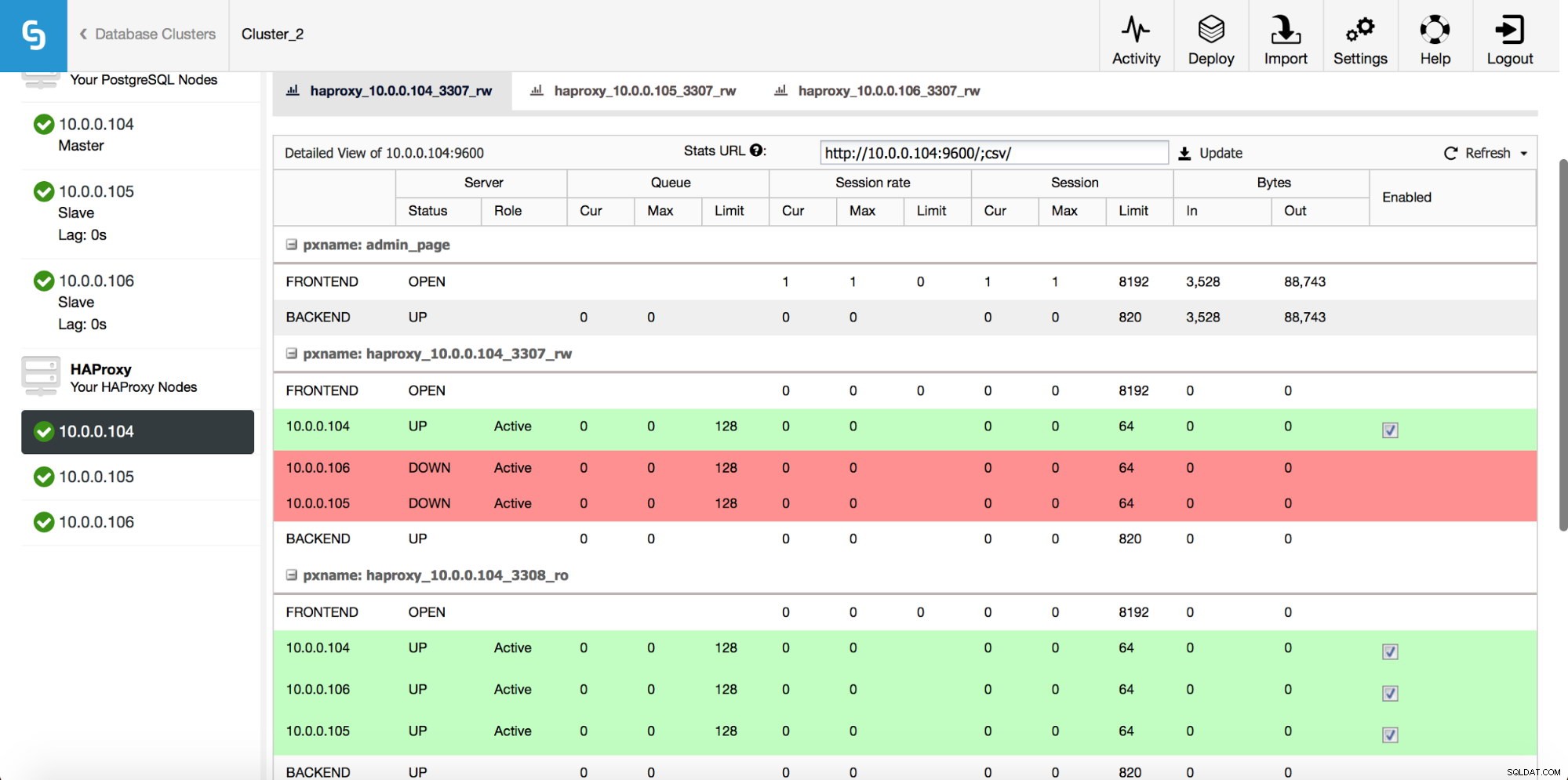
Som vi kan se, for R/W-backend, er kun én vært (aktiv server) markeret som op. For den skrivebeskyttede backend er alle noder oppe.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperBevares
HAProxy vil sidde mellem dine applikationer og databaseinstanser, så det vil spille en central rolle. Det kan desværre også blive et enkelt fejlpunkt, skulle det fejle, er der ingen vej til databaserne. For at undgå en sådan situation kan du implementere flere HAProxy-forekomster. Men så er spørgsmålet - hvordan man beslutter sig for, hvilken proxy-vært der skal oprettes forbindelse til. Hvis du implementerede HAProxy fra ClusterControl, er det så simpelt som at køre endnu et "Add Load Balancer"-job, denne gang med at implementere Keepalved.
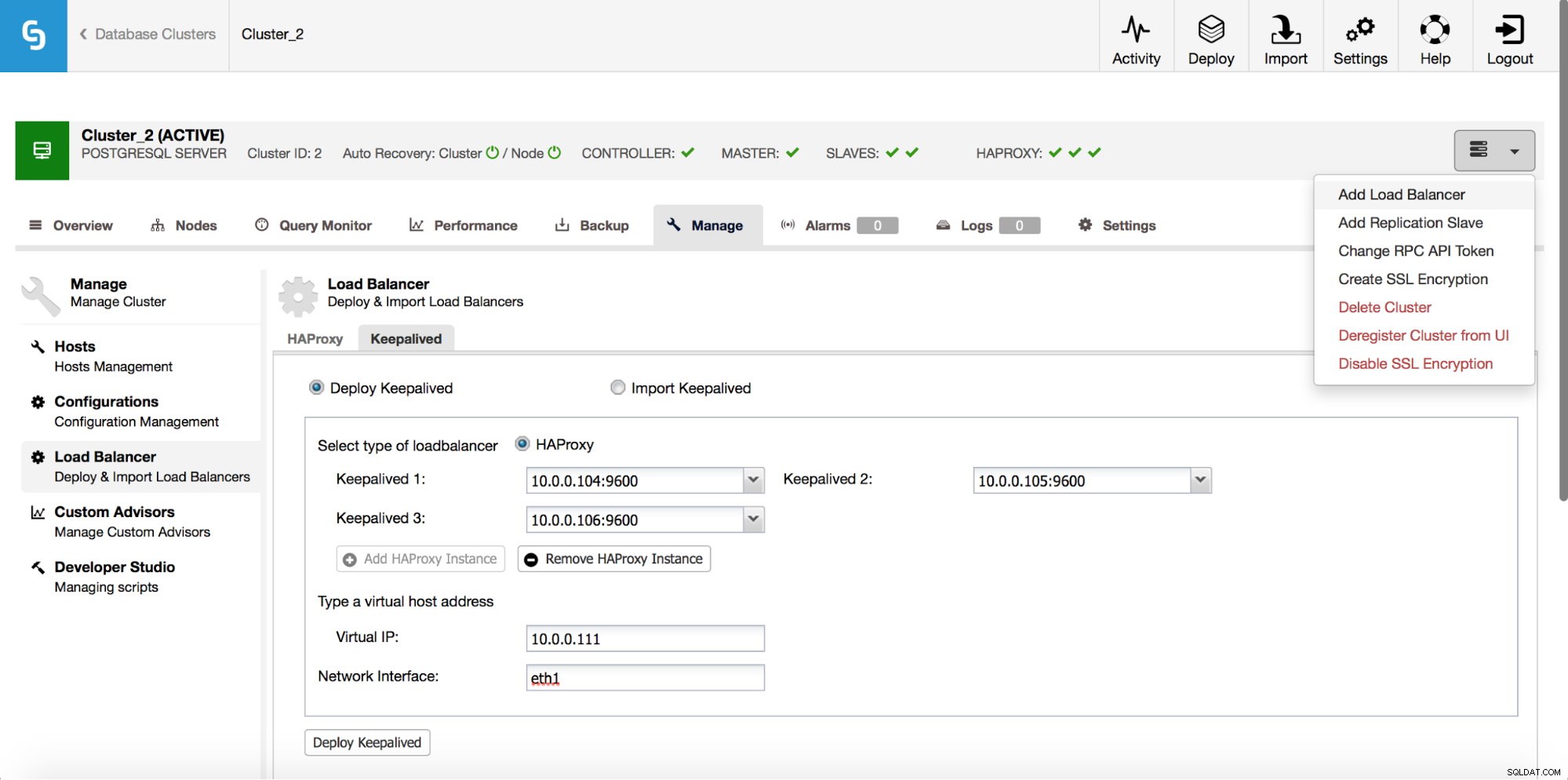
Som vi kan se på skærmbilledet ovenfor, kan du hente op til tre HAProxy-værter, og Keepalived vil blive installeret oven på dem og overvåge deres tilstand. En virtuel IP (VIP) vil blive tildelt en af dem. Din applikation skal bruge denne VIP til at oprette forbindelse til databasen. Hvis den "aktive" HAProxy bliver utilgængelig, vil VIP blive flyttet til en anden vært.
Som vi har set, er det ret nemt at implementere en fuld høj tilgængelig stak til PostgreSQL. Prøv det, og lad os vide, hvis du har feedback.