PostgreSQL er en af de databaser, der kan implementeres via ClusterControl sammen med MySQL, MariaDB og MongoDB. ClusterControl forenkler ikke kun implementeringen af databaseklyngen, men har en funktion til skalerbarhed, hvis din applikation vokser og kræver den funktionalitet.
Ved at opskalere din database, vil din applikation køre meget jævnere og bedre, hvis applikationsbelastningen eller trafikken stiger. I dette blogindlæg vil vi gennemgå trinene til, hvordan man udfører implementeringen samt opskalering af PostgreSQL v13 med ClusterControl 1.8.2.
Implementering af brugergrænseflade (UI)
Der er to måder at implementere på i ClusterControl, webbrugergrænseflade (UI) samt kommandolinjegrænseflade (CLI). Brugeren har friheden til at vælge enhver af implementeringsmulighederne afhængigt af deres smag og behov. Begge muligheder er nemme at følge og veldokumenterede i vores dokumentation. I dette afsnit vil vi gennemgå implementeringsprocessen ved at bruge den første mulighed - web-UI.
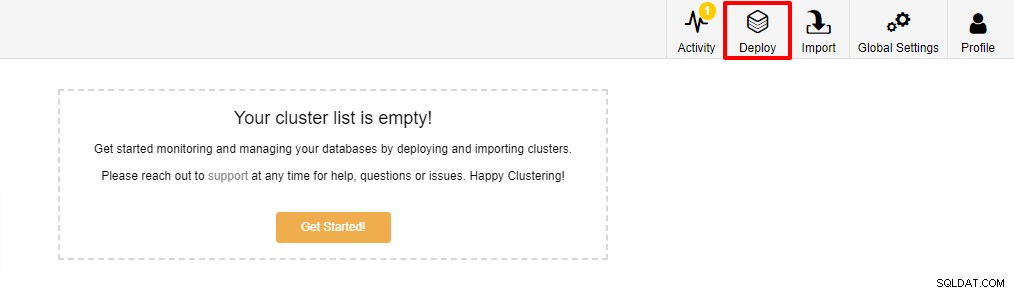
Det første trin er at logge ind på din ClusterControl og klikke på Implementer:
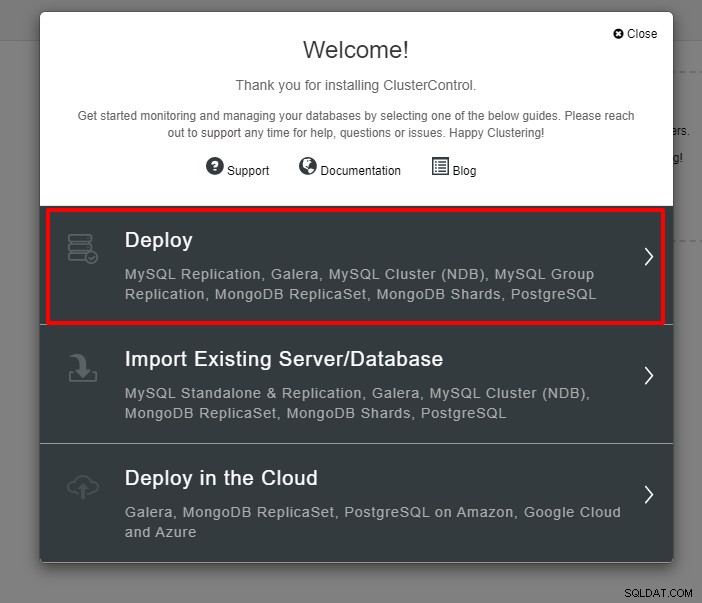
Du vil blive præsenteret for skærmbilledet nedenfor for næste trin i implementeringen , vælg fanen PostgreSQL for at fortsætte:
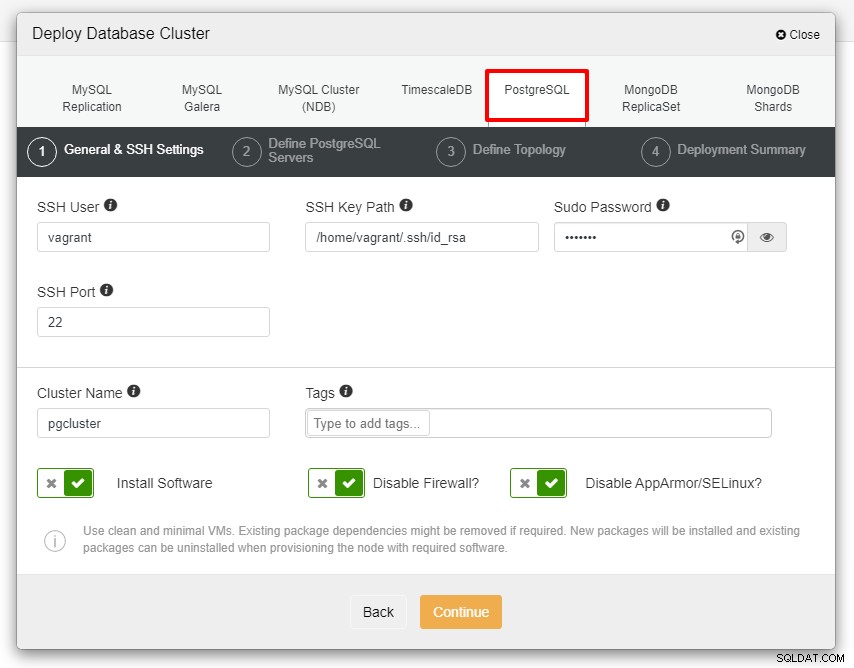
Inden vi går videre, vil jeg gerne minde om, at sammenhængen mellem ClusterControl-noden og databasenoderne skal være uden adgangskode. Inden implementeringen skal vi kun generere ssh-keygen fra ClusterControl-noden og derefter kopiere den til alle noderne. Udfyld input for SSH-bruger, Sudo-adgangskode samt klyngenavn i henhold til dit krav, og klik på Fortsæt.
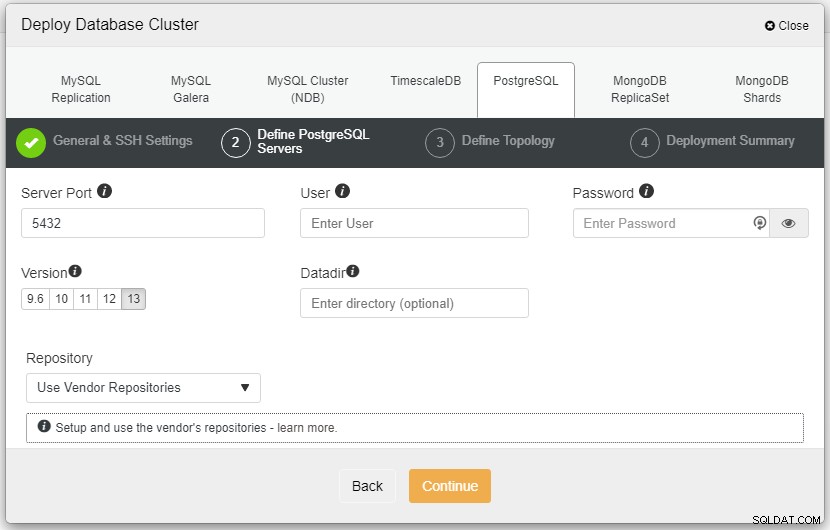
I skærmbilledet ovenfor skal du definere serverporten (i i tilfælde af at du gerne vil bruge andre), den bruger, du gerne vil have, samt adgangskoden og sørg for at vælge Version 13, som du vil installere.
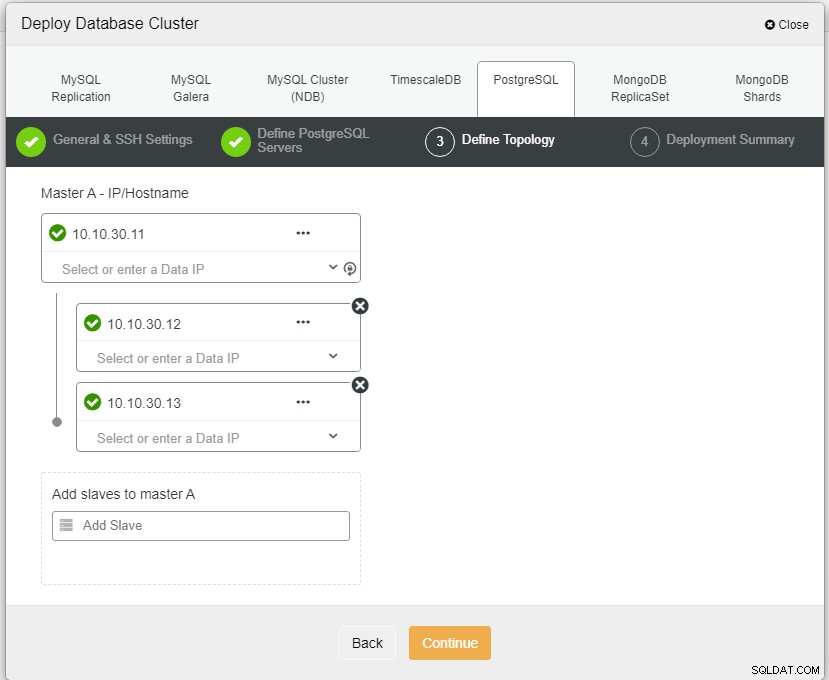 Photo authorPhoto description
Photo authorPhoto descriptionHer skal vi definere serverne enten ved at bruge værtsnavnet eller IP-adressen, som i dette tilfælde 1 master og 2 slaver. Det sidste trin er at vælge replikeringstilstanden for vores klynge.
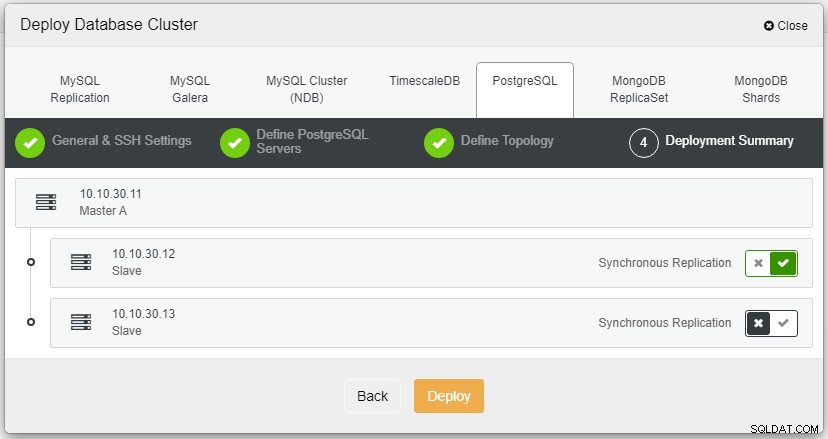
Når du har klikket på Implementer, starter implementeringsprocessen, og vi kan overvåge fremskridt på fanen Aktivitet.
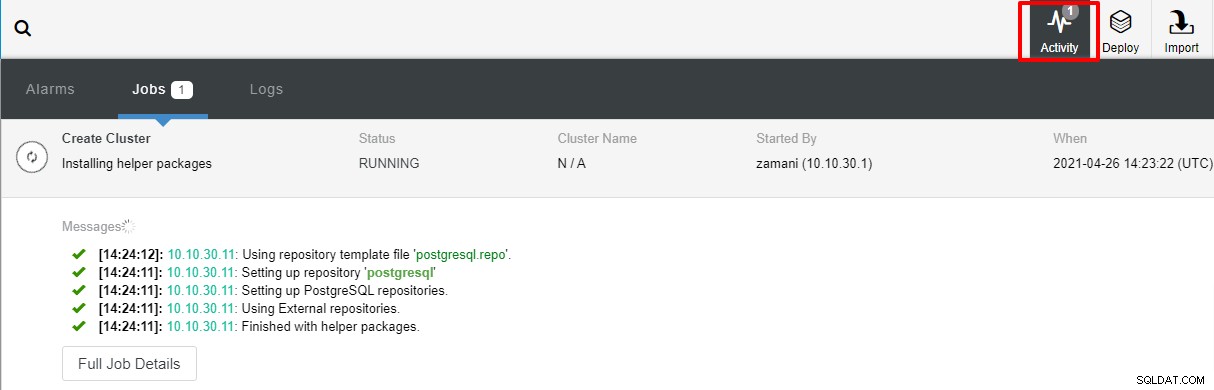
Implementeringen vil normalt tage et par minutter, ydeevne afhænger for det meste af netværk og serverens specifikationer.

Nu hvor vi har PostgreSQL v13 installeret ved hjælp af ClusterControl GUI, hvilket er ret ligetil .
Command Line Interface (CLI) PostgreSQL-implementering
Ud fra ovenstående kan vi se, at implementeringen er ret ligetil ved brug af web-UI. Den vigtige bemærkning er, at alle noder skal have adgangskodeløse SSH-forbindelser før implementeringen. I dette afsnit skal vi se, hvordan du implementerer ved hjælp af ClusterControl CLI- eller "s9s"-værktøjets kommandolinje.
Vi antog, at ClusterControl er blevet installeret før dette, lad os komme i gang med at generere ssh-keygen. Kør følgende kommandoer i ClusterControl-noden:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Når alle kommandoerne ovenfor kørte med succes, kan vi bekræfte den adgangskodeløse forbindelse ved at bruge følgende kommando:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordHvis ovenstående kommando kører med succes, kan klyngeimplementeringen startes fra ClusterControl-serveren ved hjælp af følgende kommandolinje:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logLige efter du har kørt kommandoen ovenfor, vil du se noget som dette, hvilket betyder, at opgaven er begyndt at køre:
Klynge vil blive oprettet på 3 dataknude(r).
Bekræfter jobparametre.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Du kan også bekræfte det ved at logge ind på webkonsollen ved at bruge det brugernavn, du har oprettet. Nu har vi en PostgreSQL-klynge installeret ved hjælp af 3 noder. Hvis du kan lide at lære mere om implementeringskommandoen ovenfor, er her den bedste reference til dig.
Opskalering af PostgreSQL med ClusterControl UI
PostgreSQL er en relationsdatabase, og vi ved, at det ikke er let at udskalere denne type database sammenlignet med en ikke-relationel database. I disse dage har de fleste applikationer brug for skalerbarhed for at give bedre ydeevne og hastighed. Der er mange måder at få dette implementeret på afhængigt af din infrastruktur og miljø.
Skalerbarhed er en af de funktioner, der kan faciliteres af ClusterControl og kan opnås både ved brug af UI og CLI. I dette afsnit skal vi se, hvordan vi kan skalere PostgreSQL ud ved hjælp af ClusterControl UI. Det første trin er at logge ind på din brugergrænseflade og vælge klyngen, når klyngen er valgt, kan du klikke på indstillingen som på skærmbilledet nedenfor:
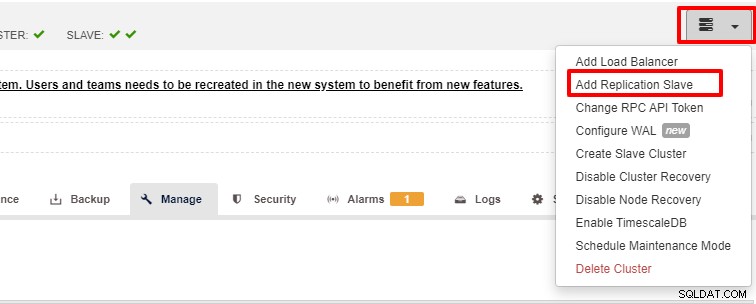
Når der er klikket på "Tilføj replikeringsslave", vil du se følgende side . Du kan enten vælge "Tilføj ny..." eller "Importer..." afhængigt af din situation. I dette eksempel vil vi vælge den første mulighed:
Følgende skærm vil blive vist, når du har klikket på den:
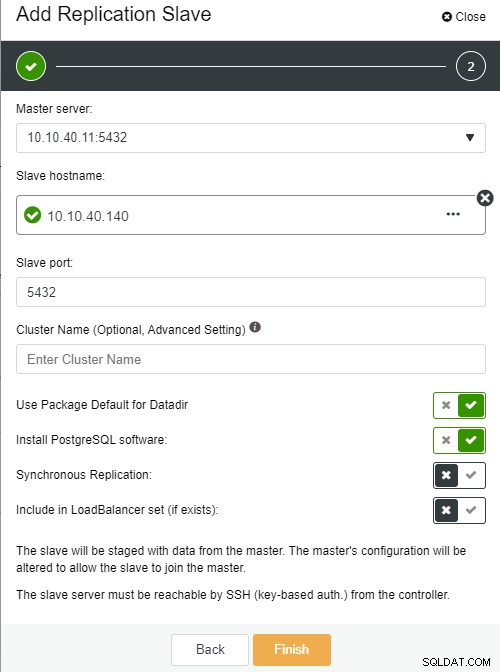 FotoforfatterPhoto description
FotoforfatterPhoto description-
Slaveværtsnavn:værtsnavnet/IP-adressen på den nye slave eller node
-
Slaveport:PostgreSQL-porten for slaven, standard er 5432
-
Klyngenavn:navnet på klyngen, du kan enten tilføje eller lade det stå tomt
-
Brug Package Default for Datadir:du kan få denne indstilling markeret til at fjerne markeringen, hvis du vil have en anden placering til Datadir
-
Installer PostgreSQL-software:du kan lade denne indstilling være markeret
-
Synkron replikering:du kan vælge hvilken type replikering du vil have i denne
-
Inkluder i LoadBalancer-sæt (hvis den findes):denne mulighed skal afkrydses, hvis du har LoadBalancer konfigureret til klyngen
Den vigtigste bemærkning her er, at du skal konfigurere den nye slavevært til at være uden adgangskode, før du kan køre denne opsætning. Når alt er bekræftet, kan vi klikke på knappen "Udfør" for at fuldføre opsætningen. I dette eksempel har jeg tilføjet IP “10.10.40.140”.
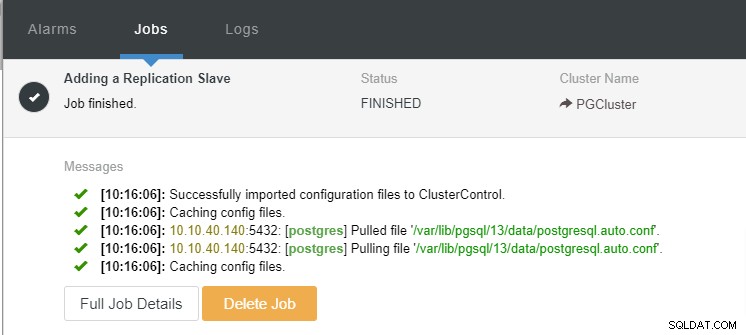
Vi kan nu overvåge jobaktiviteten og lade opsætningen fuldføre. For at bekræfte opsætningen kan vi gå til fanen "Topologi" for at se den nye slave:
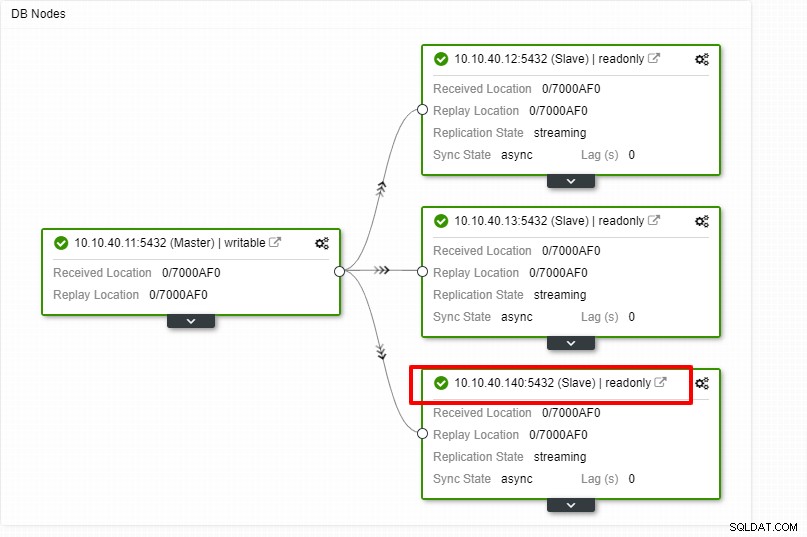
Udskalering af PostgreSQL med ClusterControl CLI
At tilføje de nye noder til den eksisterende klynge er meget enkelt ved at bruge CLI. Fra controller-noden udfører du følgende kommando. Den første kommando er at identificere den klynge, som vi gerne vil tilføje den nye node til:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.I dette eksempel kan vi se, at node-id er "1" for klyngenavnet "PGCluster". Lad os se den første kommandoindstilling om, hvordan du tilføjer en ny node til den eksisterende PostgreSQL-klynge:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logStenografien "--log" i slutningen af linjen vil lade os se, hvad der er den aktuelle opgave, der kører efter kommandoen udført som nedenfor:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…Den næste tilgængelige kommando, som du kan bruge, er som følgende:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitTilføj node til klynge
\ Job 9 RUNNING [▋ ] 5% Installing packagesBemærk, at der er "--vent" stenografi i linjen, og det output, du vil se, vil blive vist som ovenfor. Når processen er fuldført, kan vi bekræfte de nye noder på fanen "Oversigt" i klyngen fra brugergrænsefladen:
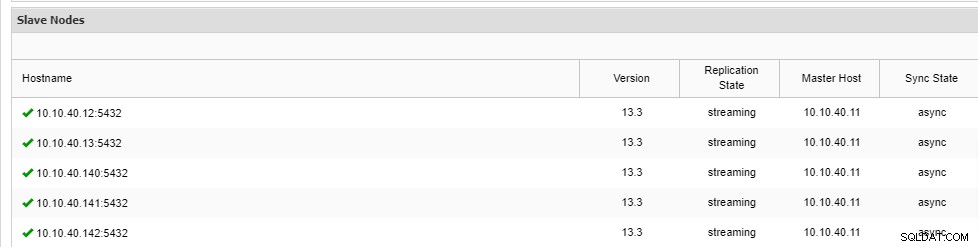
Konklusion
I dette blogindlæg har vi gennemgået to muligheder for at skalere PostgreSQL ud i ClusterControl. Som du måske bemærker, er det nemt at udskalere PostgreSQL med ClusterControl. ClusterControl kan ikke kun udføre skalerbarheden, men du kan også opnå høj tilgængelighed for din databaseklynge. Funktioner som HAProxy, PgBouncer samt Keepalived er tilgængelige og klar til at blive implementeret for din klynge, når du føler behov for disse muligheder. Med ClusterControl er din databaseklynge nem at administrere og overvåge på samme tid.
Vi håber, at dette blogindlæg vil hjælpe dig med at skalere din PostgreSQL-opsætning.