Diskplads er en krævende ressource i dag. Du vil normalt gemme data så længe som muligt, men dette kan være et problem, hvis du ikke tager de nødvendige handlinger for at forhindre et potentielt problem med "uden for diskplads".
I denne blog vil vi se, hvordan vi kan opdage dette problem for PostgreSQL, forhindre det, og hvis det er for sent, nogle muligheder, der sandsynligvis vil hjælpe dig med at løse det.
Sådan identificeres PostgreSQL-diskpladsproblemer
Hvis du desværre er i denne situation uden diskplads, vil du kunne se nogle fejl i PostgreSQL-databaselogfilerne:
2020-02-20 19:18:18.131 UTC [4400] LOG: could not close temporary statistics file "pg_stat_tmp/global.tmp": No space left on deviceeller endda i din systemlog:
Feb 20 19:29:26 blog-pg1 rsyslogd: imjournal: fclose() failed for path: '/var/lib/rsyslog/imjournal.state.tmp': No space left on device [v8.24.0-41.el7_7.2 try https://www.rsyslog.com/e/2027 ]PostgreSQL kan fortsætte med at virke i et stykke tid med at køre skrivebeskyttede forespørgsler, men til sidst vil det mislykkes ved at prøve at skrive til disk, så vil du se noget som dette i din klientsession:
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.Så, hvis du ser på diskpladsen, vil du få dette uønskede output...
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/pve-vm--125--disk--0 30G 30G 0 100% /Sådan forhindrer du PostgreSQL-diskpladsproblemer
Den vigtigste måde at forhindre denne type problemer på er ved at overvåge diskpladsforbruget og væksten i database- eller diskforbruget. Til dette bør en graf være en venlig måde at overvåge diskpladstilvæksten:

Og det samme for databasevæksten:
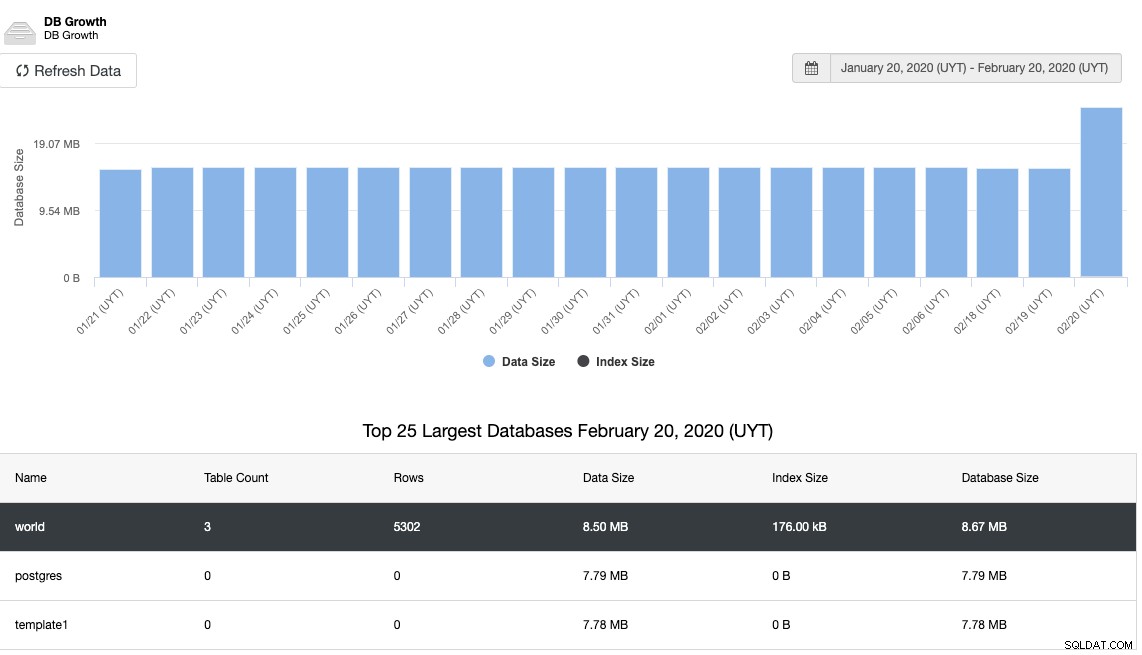
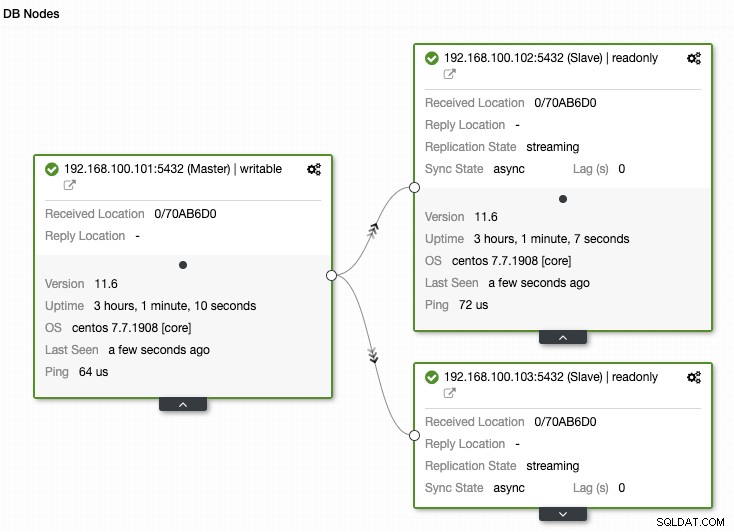
En anden vigtig ting at overvåge er replikeringsstatussen. Hvis du har en replika, og af en eller anden grund holder denne op med at virke, afhængigt af konfigurationen, kan det være muligt, at PostgreSQL gemmer alle WAL-filerne for at gendanne replikaen, når den kommer tilbage.
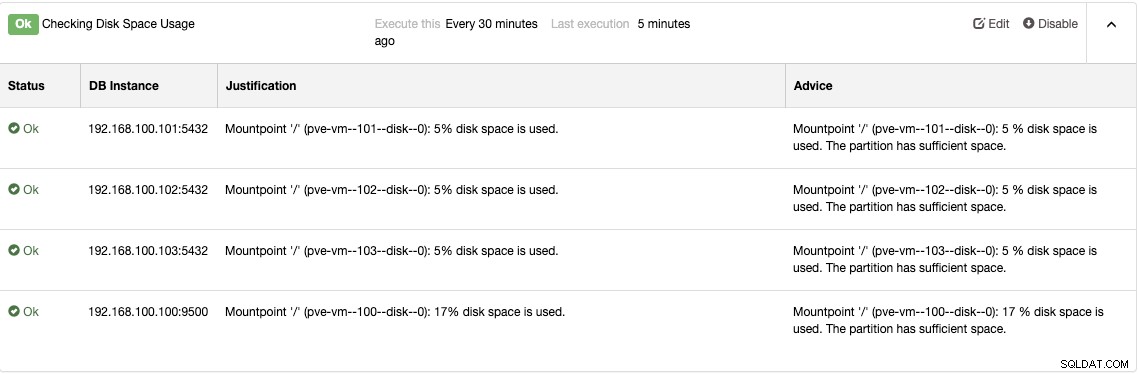
Alt dette overvågningssystem giver ikke mening uden et advarselssystem at vide når du skal tage handlinger:
Sådan løses PostgreSQL-diskpladsproblemer
Tja, hvis du står over for dette problem med manglende diskplads, selv med overvågnings- og alarmeringssystemet implementeret (eller ej), er der mange muligheder for at prøve at løse dette problem uden tab af data (eller mindre som muligt).
Hvad bruger din diskplads?
Det første trin bør være at bestemme, hvor min diskplads er. En bedste praksis er at have separate partitioner, mindst én separat partition til dit databaselager, så du nemt kan bekræfte, om din database eller dit system bruger for meget diskplads. En anden fordel ved dette er at minimere skaden. Hvis din rodpartition er fuld, kan din database stadig skrive i sin egen partition uden problemer.
Anvendelse af databaseplads
Lad os nu se nogle nyttige kommandoer til at kontrollere din databasediskpladsforbrug.
En grundlæggende måde at kontrollere databasens pladsforbrug på er at tjekke databiblioteket i filsystemet:
$ du -sh /var/lib/pgsql/11/data/
819M /var/lib/pgsql/11/data/Eller hvis du har en separat partition til dit databibliotek, kan du bruge df -h direkte.
PostgreSQL-kommandoen "\l+" viser databaserne, der tilføjer størrelsesoplysningerne:
$ postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace
| Description
-----------+----------+-----------+---------+-------+-----------------------+---------+------------
+--------------------------------------------
postgres | postgres | SQL_ASCII | C | C | | 7965 kB | pg_default
| default administrative connection database
template0 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| unmodifiable empty database
| | | | | postgres=CTc/postgres | |
|
template1 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| default template for new databases
| | | | | postgres=CTc/postgres | |
|
world | postgres | SQL_ASCII | C | C | | 8629 kB | pg_default
|
(4 rows)Ved at bruge pg_database_size og databasenavnet kan du se databasestørrelsen:
postgres=# SELECT pg_database_size('world');
pg_database_size
------------------
8835743
(1 row)Og at bruge pg_size_pretty til at se denne værdi på en menneskelig læsbar måde kunne være endnu bedre:
postgres=# SELECT pg_size_pretty(pg_database_size('world'));
pg_size_pretty
----------------
8629 kB
(1 row)Når du ved, hvor pladsen er, kan du foretage den tilsvarende handling for at rette det. Husk, at blot at slette rækker ikke er nok til at genvinde diskpladsen, du skal køre en VACUUM eller VACUUM FULL for at afslutte opgaven.
Logfiler
Den nemmeste måde at gendanne diskplads på er ved at slette logfiler. Du kan tjekke PostgreSQL-logbiblioteket eller endda systemlogfilerne for at kontrollere, om du kan få lidt plads derfra. Hvis du har noget som dette:
$ du -sh /var/lib/pgsql/11/data/log/
18G /var/lib/pgsql/11/data/log/Du bør tjekke mappeindholdet for at se, om der er et problem med logrotation/retention, eller om der sker noget i din database og skriver det til logfilerne.
$ ls -lah /var/lib/pgsql/11/data/log/
total 18G
drwx------ 2 postgres postgres 4.0K Feb 21 00:00 .
drwx------ 21 postgres postgres 4.0K Feb 21 00:00 ..
-rw------- 1 postgres postgres 18G Feb 21 14:46 postgresql-Fri.log
-rw------- 1 postgres postgres 9.3K Feb 20 22:52 postgresql-Thu.log
-rw------- 1 postgres postgres 3.3K Feb 19 22:36 postgresql-Wed.logFør du sletter logfilerne, hvis du har en stor en, er det en god praksis at beholde de sidste 100 linjer eller deromkring og derefter slette dem. Så du kan tjekke, hvad der sker efter at have genereret ledig plads.
$ tail -100 postgresql-Fri.log > /tmp/log_temp.logOg så:
$ cat /dev/null > /var/lib/pgsql/11/data/log/postgresql-Fri.logHvis du bare sletter den med "rm", og logfilen bliver brugt af PostgreSQL-serveren (eller en anden tjeneste), frigives plads ikke, så du bør afkorte denne fil ved hjælp af denne kat / dev/null kommando i stedet.
Denne handling er kun for PostgreSQL og systemlogfiler. Slet ikke pg_wal-indholdet eller en anden PostgreSQL-fil, da det kan generere kritisk skade på din database.
Opblæst
I en normal PostgreSQL-operation fjernes tuples, der er slettet eller forældet af en opdatering, ikke fysisk fra tabellen; de er til stede, indtil der udføres en STØVSUGNING. Så det er nødvendigt at udføre VACUUM periodisk (AUTOVACUUM), især i hyppigt opdaterede tabeller.
Problemet her er, at pladsen ikke returneres til operativsystemet med kun VACUUM, den er kun tilgængelig til brug i samme tabel.
VACUUM FULL omskriver tabellen til en ny diskfil og returnerer den ubrugte plads til operativsystemet. Desværre kræver det en eksklusiv lås på hvert bord, mens det kører.
Du bør tjekke tabellerne for at se, om en VAKUUM (FULD) proces er påkrævet.
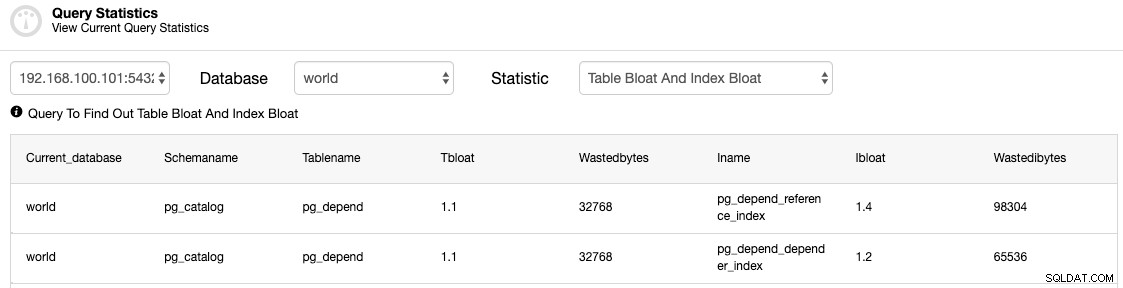
replikeringspladser
Hvis du bruger replikeringspladser, og den af en eller anden grund ikke er aktiv:
postgres=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
-----------+-----------+--------
slot1 | physical | f
(1 row)Det kan være et problem for din diskplads, fordi den vil gemme WAL-filerne, indtil de er modtaget af alle standby-noder.
Måden at rette det på er at gendanne replikaen (hvis det er muligt), eller at slette pladsen:
postgres=# SELECT pg_drop_replication_slot('slot1');
pg_drop_replication_slot
--------------------------
(1 row)Så den plads, der bruges af WAL-filerne, vil blive frigivet.
Konklusion
Som vi nævnte, er overvågnings- og varslingssystemer nøglerne til at undgå denne slags problemer. På denne måde kan ClusterControl hjælpe dig med at få dine systemer oppe at køre, sende dig alarmer, når det er nødvendigt, eller endda tage retableringsforanstaltninger for at holde din databaseklynge i gang. Du kan også implementere/importere forskellige databaseteknologier og skalere dem ud, hvis det er nødvendigt.