Læsning fra hukommelsen vil altid være mere effektiv end at gå til disk, så for alle databaseteknologier vil du gerne bruge så meget hukommelse som muligt. Hvis du ikke er sikker på konfigurationen, eller hvis du har en fejl, kan dette generere høj hukommelsesudnyttelse eller endda et problem med manglende hukommelse.
I denne blog vil vi se på, hvordan du tjekker din PostgreSQL-hukommelsesudnyttelse, og hvilken parameter du skal tage i betragtning for at justere den. Lad os starte med at se en oversigt over PostgreSQL's arkitektur.
PostgreSQL-arkitektur
PostgreSQL's arkitektur er baseret på tre grundlæggende dele:Processer, Hukommelse og Disk.
Hukommelsen kan klassificeres i to kategorier:
- Lokal hukommelse :Den indlæses af hver backend-proces til eget brug til forespørgselsbehandling. Det er opdelt i underområder:
- Work mem:Work mem bruges til at sortere tupler efter ORDER BY og DISTINCT operationer og til at sammensætte tabeller.
- Vedligeholdelsesarbejde mem:Nogle former for vedligeholdelsesoperationer bruger dette område. For eksempel VACUUM, hvis du ikke angiver autovacuum_work_mem.
- Temperaturbuffere:Det bruges til at lagre midlertidige tabeller.
- Delt hukommelse :Den tildeles af PostgreSQL-serveren, når den startes, og den bruges af alle processerne. Det er opdelt i underområder:
- Delt bufferpulje:Hvor PostgreSQL indlæser sider med tabeller og indekser fra disken for at arbejde direkte fra hukommelsen, hvilket reducerer diskadgangen.
- WAL-buffer:WAL-dataene er transaktionsloggen i PostgreSQL og indeholder ændringerne i databasen. WAL-buffer er det område, hvor WAL-dataene gemmes midlertidigt, før de skrives til disken i WAL-filerne. Dette gøres hvert et foruddefineret tidspunkt kaldet checkpoint. Dette er meget vigtigt for at undgå tab af information i tilfælde af en serverfejl.
- Forpligtelseslog:Den gemmer status for alle transaktioner til kontrol af samtidighed.
Sådan ved du, hvad der sker
Hvis du har høj hukommelsesudnyttelse, skal du først bekræfte, hvilken proces der genererer forbruget.
Brug af "Top" Linux-kommando
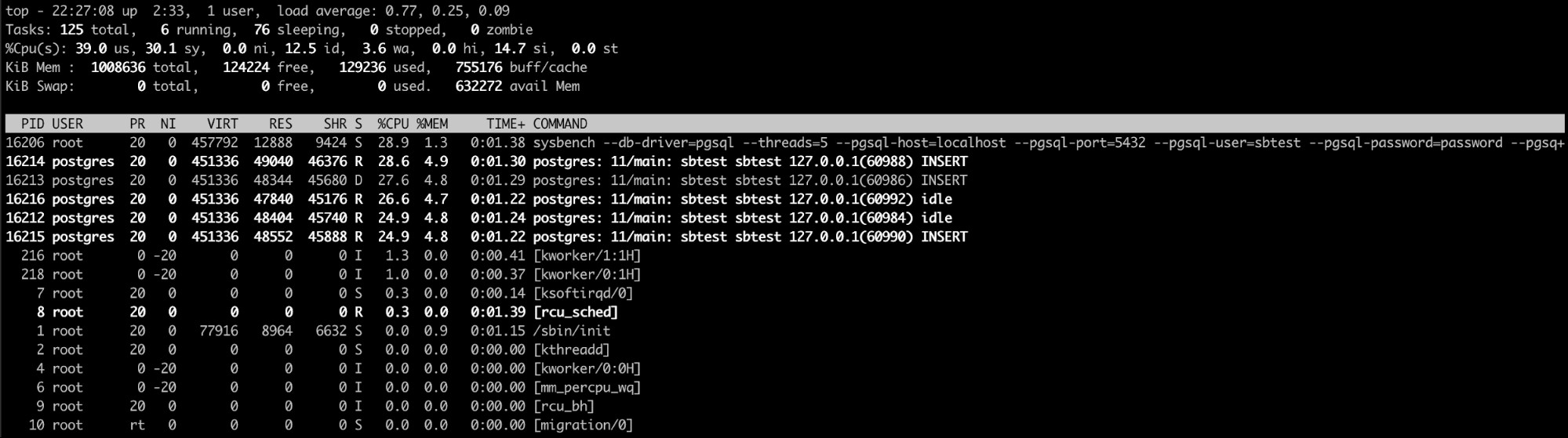
Den øverste linux-kommando er sandsynligvis den bedste mulighed her (eller endda en lignende en som htop). Med denne kommando kan du se processen/processerne, der bruger for meget hukommelse.
Når du bekræfter, at PostgreSQL er ansvarlig for dette problem, er næste trin at tjekke hvorfor.
Brug af PostgreSQL-loggen
At tjekke både PostgreSQL- og systemloggene er bestemt en god måde at få mere information om, hvad der sker i din database/dit system. Du kunne se beskeder som:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childHvis du ikke har nok ledig hukommelse.
Eller endda flere databasemeddelelsesfejl som:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedNår du har en uventet adfærd på databasesiden. Så logfilerne er nyttige til at opdage den slags problemer og endnu mere. Du kan automatisere denne overvågning ved at parse logfilerne på udkig efter værker som "FATAL", "FEJL" eller "Kill", så du vil modtage en advarsel, når det sker.
Brug af Pg_top
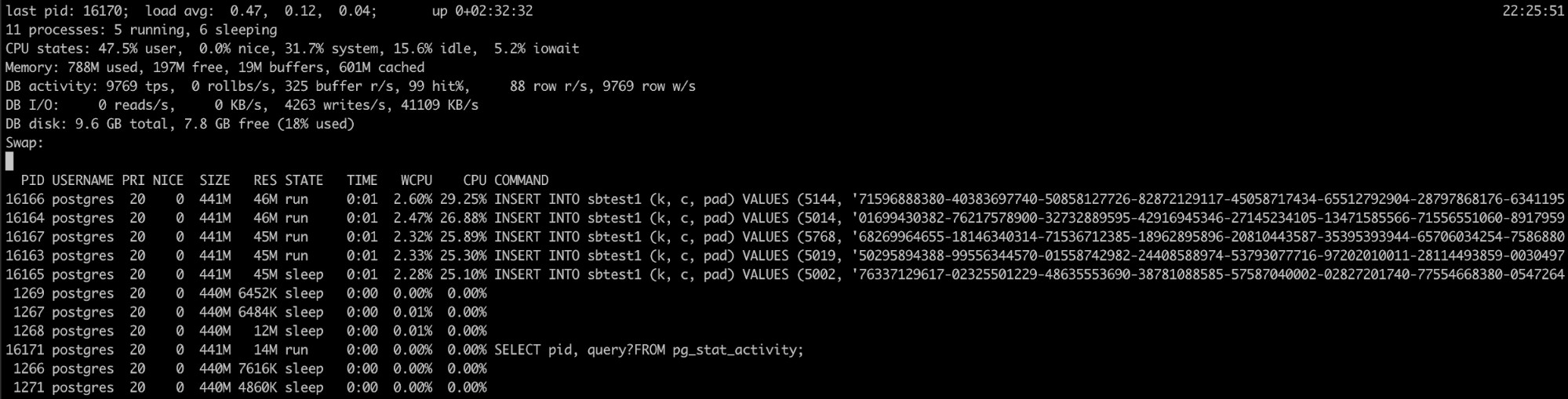
Hvis du ved, at PostgreSQL-processen har en høj hukommelsesudnyttelse, men logfilerne hjalp ikke, du har et andet værktøj, der kan være nyttigt her, pg_top.
Dette værktøj ligner det øverste linux-værktøj, men det er specifikt til PostgreSQL. Så ved at bruge det, vil du have mere detaljeret information om, hvad der kører din database, og du kan endda dræbe forespørgsler eller køre et forklaringsjob, hvis du opdager noget forkert. Du kan finde mere information om dette værktøj her.
Men hvad sker der, hvis du ikke kan opdage nogen fejl, og databasen stadig bruger meget RAM. Så du bliver sandsynligvis nødt til at kontrollere databasekonfigurationen.
Hvilke konfigurationsparametre skal tages i betragtning
Hvis alt ser fint ud, men du stadig har problemet med høj udnyttelse, bør du tjekke konfigurationen for at bekræfte, om den er korrekt. Så følgende er parametre, som du bør tage højde for i dette tilfælde.
delte_buffere
Dette er mængden af hukommelse, som databaseserveren bruger til delte hukommelsesbuffere. Hvis denne værdi er for lav, vil databasen bruge mere disk, hvilket ville forårsage mere langsommelighed, men hvis den er for høj, kan det generere høj hukommelsesudnyttelse. Ifølge dokumentationen, hvis du har en dedikeret databaseserver med 1 GB eller mere RAM, er en rimelig startværdi for shared_buffers 25 % af hukommelsen i dit system.
work_mem
Det specificerer mængden af hukommelse, der vil blive brugt af ORDER BY, DISTINCT og JOIN før skrivning til de midlertidige filer på disken. Som med shared_buffers, hvis vi konfigurerer denne parameter for lavt, kan vi have flere operationer ind i disken, men for høj er farlig for hukommelsesforbruget. Standardværdien er 4 MB.
max_connections
Work_mem går også hånd i hånd med max_connections værdien, da hver forbindelse vil udføre disse operationer på samme tid, og hver operation får lov til at bruge så meget hukommelse som angivet af denne værdi før den begynder at skrive data i midlertidige filer. Denne parameter bestemmer det maksimale antal samtidige forbindelser til vores database, hvis vi konfigurerer et højt antal forbindelser og ikke tager højde for dette, kan du begynde at have ressourceproblemer. Standardværdien er 100.
temp_buffere
De midlertidige buffere bruges til at gemme de midlertidige tabeller, der bruges i hver session. Denne parameter indstiller den maksimale mængde hukommelse til denne opgave. Standardværdien er 8 MB.
maintenance_work_mem
Dette er den maksimale hukommelse, som en operation som støvsugning, tilføjelse af indekser eller fremmednøgler kan forbruge. Det gode er, at kun én operation af denne type kan køres i en session, og det er ikke den mest almindelige ting at køre flere af disse på samme tid i systemet. Standardværdien er 64 MB.
autovacuum_work_mem
Støvsugeren bruger som standard maintenance_work_mem, men vi kan adskille det ved hjælp af denne parameter. Vi kan specificere den maksimale mængde hukommelse, der skal bruges af hver autovakuumarbejder her.
wal_buffere
Mængden af delt hukommelse, der bruges til WAL-data, som endnu ikke er skrevet til disken. Standardindstillingen er 3 % af shared_buffers, men ikke mindre end 64 kB eller mere end størrelsen af et WAL-segment, typisk 16 MB.
Konklusion
Der er forskellige grunde til at have en høj hukommelsesudnyttelse, og at opdage rodproblemet kan være en tidskrævende opgave. I denne blog nævnte vi forskellige måder at kontrollere din PostgreSQL-hukommelsesudnyttelse på, og hvilken parameter du skal tage i betragtning for at justere den for at undgå overdreven hukommelsesbrug.