Problemer med replikeringsforsinkelse i PostgreSQL er ikke et udbredt problem for de fleste opsætninger. Selvom det kan forekomme, og når det sker, kan det påvirke dine produktionsopsætninger. PostgreSQL er designet til at håndtere flere tråde, såsom forespørgselsparallelisme eller implementering af arbejdstråde til at håndtere specifikke opgaver baseret på de tildelte værdier i konfigurationen. PostgreSQL er designet til at håndtere tunge og stressende belastninger, men nogle gange (på grund af en dårlig konfiguration) kan din server stadig gå sydpå.
At identificere replikeringsforsinkelsen i PostgreSQL er ikke en kompliceret opgave at udføre, men der er et par forskellige tilgange til at undersøge problemet. I denne blog tager vi et kig på, hvad du skal se på, når din PostgreSQL-replikering halter.
Typer af replikering i PostgreSQL
Før vi dykker ned i emnet, lad os først se, hvordan replikering i PostgreSQL udvikler sig, da der er forskellige sæt af tilgange og løsninger, når vi beskæftiger os med replikering.
Varm standby for PostgreSQL blev implementeret i version 8.2 (tilbage i 2006) og var baseret på logforsendelsesmetoden. Dette betyder, at WAL-posterne flyttes direkte fra en databaseserver til en anden for at blive anvendt, eller blot en analog tilgang til PITR, eller meget ligesom det, du laver med rsync.
Denne tilgang, selv gammel, bruges stadig i dag, og nogle institutioner foretrækker faktisk denne ældre tilgang. Denne tilgang implementerer en filbaseret logforsendelse ved at overføre WAL-poster én fil (WAL-segment) ad gangen. Selvom det har en ulempe; En større fejl på de primære servere, transaktioner, der endnu ikke er afsendt, vil gå tabt. Der er et vindue til tab af data (du kan justere dette ved at bruge parameteren archive_timeout, som kan indstilles til så lavt som et par sekunder, men en så lav indstilling vil øge den nødvendige båndbredde til filforsendelse betydeligt).
I PostgreSQL version 9.0 blev Streaming Replication introduceret. Denne funktion gjorde det muligt for os at holde os mere opdaterede sammenlignet med filbaseret logforsendelse. Dens tilgang er ved at overføre WAL-poster (en WAL-fil er sammensat af WAL-poster) på farten (blot en rekordbaseret logforsendelse), mellem en masterserver og en eller flere standby-servere. Denne protokol behøver ikke at vente på, at WAL-filen bliver udfyldt, i modsætning til filbaseret logforsendelse. I praksis vil en proces kaldet WAL-modtager, der kører på standby-serveren, oprette forbindelse til den primære server ved hjælp af en TCP/IP-forbindelse. På den primære server findes en anden proces ved navn WAL-afsender. Dets rolle er ansvarlig for at sende WAL-registre til standby-servere, efterhånden som de sker.
Asynkron replikeringsopsætning i streamingreplikering kan medføre problemer såsom datatab eller slaveforsinkelse, så version 9.1 introducerer synkron replikering. I synkron replikering vil hver commit af en skrivetransaktion vente, indtil der modtages bekræftelse på, at commit er blevet skrevet til skrive-ahead-log på disken på både den primære server og standby-serveren. Denne metode minimerer muligheden for tab af data, da det skal ske, at både master og standby svigter på samme tid.
Den åbenlyse ulempe ved denne konfiguration er, at responstiden for hver skrivetransaktion øges, da vi skal vente, indtil alle parter har svaret. I modsætning til MySQL er der ingen understøttelse, f.eks. i et semi-synkront miljø af MySQL, vil det failback til asynkron, hvis timeout er opstået. Så i Med PostgreSQL er tiden for en commit (minimum) rundrejsen mellem den primære og standbyen. Skrivebeskyttede transaktioner vil ikke blive påvirket af det.
Efterhånden som det udvikler sig, forbedres PostgreSQL løbende, og alligevel er dets replikering forskelligartet. For eksempel kan du bruge fysisk streaming asynkron replikering eller bruge logisk streaming replikering. Begge overvåges forskelligt, selvom du bruger den samme tilgang, når du sender data over replikering, hvilket stadig er streaming replikering. For flere detaljer se manualen for forskellige typer løsninger i PostgreSQL, når du har med replikering at gøre.
Årsager til PostgreSQL-replikeringsforsinkelse
Som defineret i vores tidligere blog er en replikeringsforsinkelse omkostningerne ved forsinkelse for transaktion(er) eller operation(er) beregnet ud fra dens tidsforskel i udførelsen mellem primær/master mod standby/slave node.
Da PostgreSQL bruger streaming-replikering, er den designet til at være hurtig, da ændringer registreres som et sæt af sekvens af logposter (byte-for-byte), som opfanges af WAL-modtageren og derefter skriver disse logposter til WAL-filen. Derefter afspiller opstartsprocessen af PostgreSQL dataene fra det pågældende WAL-segment, og streaming-replikering begynder. I PostgreSQL kan en replikationsforsinkelse forekomme af disse faktorer:
- Netværksproblemer
- Kan ikke finde WAL-segmentet fra det primære. Normalt skyldes dette checkpoint-adfærden, hvor WAL-segmenter roteres eller genbruges
- Optaget noder (primære og standby(r)). Kan være forårsaget af eksterne processer eller nogle dårlige forespørgsler forårsaget af at være en ressourcekrævende
- Dårlig hardware- eller hardwareproblemer, der gør, at det tager lidt forsinkelse
- Dårlig konfiguration i PostgreSQL, såsom et lille antal max_wal_sendere, der indstilles under behandling af tonsvis af transaktionsanmodninger (eller store mængder ændringer).
Hvad skal man kigge efter med PostgreSQL-replikeringsforsinkelse
PostgreSQL-replikering er endnu forskelligartet, men overvågning af replikeringstilstanden er subtil, men ikke kompliceret. I denne tilgang vil vi fremvise er baseret på en primær standby-opsætning med asynkron streaming-replikering. Den logiske replikering kan ikke gavne de fleste af de tilfælde, vi diskuterer her, men visningen pg_stat_subscription kan hjælpe dig med at indsamle oplysninger. Det vil vi dog ikke fokusere på i denne blog.
Brug af pg_stat_replication View
Den mest almindelige fremgangsmåde er at køre en forespørgsel, der refererer til denne visning i den primære node. Husk, at du kun kan høste information fra den primære node ved hjælp af denne visning. Denne visning indeholder følgende tabeldefinition baseret på PostgreSQL 11 som vist nedenfor:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Hvor felterne er defineret som (omfatter PG <10 version),
- pid :Proces-id for walsender-processen
- usesysid :OID for bruger, som bruges til streaming-replikering.
- brugernavn :Navn på bruger, der bruges til Streaming-replikering
- applikationsnavn :Applikationsnavn forbundet til master
- client_addr :Adresse på standby/streaming replikering
- client_hostname :Værtsnavn på standby.
- client_port :TCP-portnummer, hvorpå standby kommunikerer med WAL-afsender
- backend_start :Starttidspunkt, når SR er tilsluttet Master.
- backend_xmin :standbys xmin-horisont rapporteret af hot_standby_feedback.
- stat :Aktuel WAL-afsendertilstand, dvs. streaming
- sent_lsn /sent_placering :Sidste transaktionsplacering sendt til standby.
- write_lsn /write_location :Sidste transaktion skrevet på disk i standby
- flush_lsn /flush_location :Sidste transaktion flush på disk ved standby.
- replay_lsn /replay_location :Sidste transaktion flush på disk ved standby.
- write_lag :Forløbet tid under begåede WAL'er fra primær til standby (men endnu ikke begået i standby)
- flush_lag :Forløbet tid under forpligtede WAL'er fra primær til standby (WAL'er er allerede blevet skyllet, men endnu ikke anvendt)
- replay_lag :Forløbet tid under forpligtede WAL'er fra primær til standby (fuldt indsat i standby node)
- sync_priority :Prioritet for standby-serveren, der vælges som synkron standby
- sync_state :Synkroniser standbytilstand (er den asynkron eller synkron).
En eksempelforespørgsel ville se ud som følger i PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncDette fortæller dig grundlæggende, hvilke lokationsblokke i WAL-segmenterne, der er blevet skrevet, tømt eller anvendt. Det giver dig et detaljeret overblik over replikeringsstatussen.
Forespørgsler til brug i standby-knuden
I standby-knudepunktet er der understøttede funktioner, som du kan reducere dette til en forespørgsel og give dig overblikket over din standby-replikering. For at gøre dette kan du køre følgende forespørgsel nedenfor (forespørgslen er baseret på PG-version> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00I ældre versioner kan du bruge følgende forespørgsel:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Hvad fortæller forespørgslen? Funktioner er defineret i overensstemmelse hermed,
- pg_is_in_recovery ():(boolesk) Sandt, hvis gendannelse stadig er i gang.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Fremskrivningslogplaceringen modtaget og synkroniseret til disk ved streamingreplikering.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Den sidste fremskrivningslogplacering, der blev afspillet igen under gendannelse. Hvis genopretning stadig er i gang, vil dette stige monotont.
- pg_last_xact_replay_timestamp (): (tidsstempel med tidszone) Få tidsstempel for sidste transaktion afspillet under gendannelse.
Ved at bruge noget grundlæggende matematik kan du kombinere disse funktioner. Den mest almindeligt anvendte funktion, der bruges af DBA'er er,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
eller i versioner PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Selvom denne forespørgsel har været i praksis og bruges af DBA'er. Alligevel giver det dig ikke et præcist billede af forsinkelsen. Hvorfor? Lad os diskutere dette i næste afsnit.
Identifikation af forsinkelse forårsaget af WAL-segmentets fravær
PostgreSQL standby noder, som er i gendannelsestilstand, rapporterer ikke til dig den nøjagtige tilstand af, hvad der sker i din replikering. Ikke medmindre du ser PG-loggen, kan du samle information om, hvad der foregår. Der er ingen forespørgsel, du kan køre for at fastslå dette. I de fleste tilfælde kommer organisationer og endda små institutioner med tredjepartssoftware til at lade dem blive advaret, når en alarm udløses.
En af disse er ClusterControl, som giver dig observerbarhed, sender advarsler, når alarmer udløses, eller genopretter din node i tilfælde af en katastrofe eller en katastrofe. Lad os tage dette scenarie, min primære standby asynkron streaming replikeringsklynge har fejlet. Hvordan ville du vide, om noget er galt? Lad os kombinere følgende:
Trin 1:Bestem, om der er en forsinkelse
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Trin 2:Bestem de WAL-segmenter, der modtages fra den primære, og sammenlign med standby-knuden
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70For ældre versioner af PG <10, brug pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Det ser dårligt ud.
Trin 3:Bestem, hvor slemt det kunne være
Lad os nu blande formlen fra trin #1 og i trin #2 og få forskellen. Hvordan man gør dette, PostgreSQL har en funktion kaldet pg_wal_lsn_diff, som er defineret som,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (location pg_lsn, location pg_lsn): (numerisk) Beregn forskellen mellem to fremskrivningslogplaceringer
Nu, lad os bruge det til at bestemme forsinkelsen. Du kan køre det i en hvilken som helst PG-knude, da det er, vi kun giver de statiske værdier:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Lad os anslå, hvor meget der er 1800913104, det ser ud til at være omkring 1,6 GiB, der måske har været fraværende i standby-knuden,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Sidst kan du fortsætte eller endda før forespørgslen se på loggene som at bruge tail -5f til at følge og kontrollere, hvad der foregår. Gør dette for begge primære/standby noder. I dette eksempel vil vi se, at den har et problem,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Når du støder på dette problem, er det bedre at genopbygge dine standby-noder. I ClusterControl er det så nemt som et enkelt klik. Bare gå til sektionen Noder/Topologi, og genopbyg noden ligesom nedenfor:
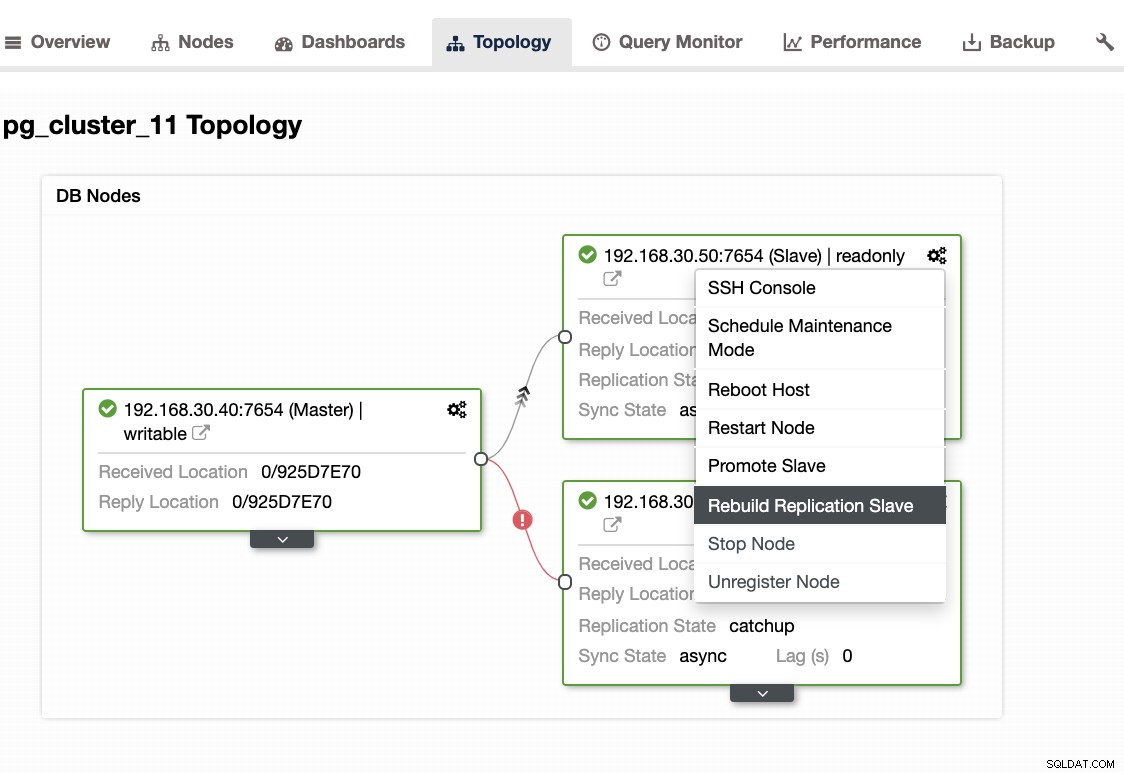
Andre ting at tjekke
Du kan bruge den samme tilgang i vores tidligere blog (i MySQL), ved at bruge systemværktøjer såsom ps, top, iostat, netstat-kombination. For eksempel kan du også få det aktuelle gendannede WAL-segment fra standby-knuden,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Hvordan kan ClusterControl hjælpe?
ClusterControl tilbyder en effektiv måde at overvåge dine databasenoder fra primære til slaveknudepunkter. Når du går til fanen Oversigt, har du allerede visningen af din replikeringstilstand:
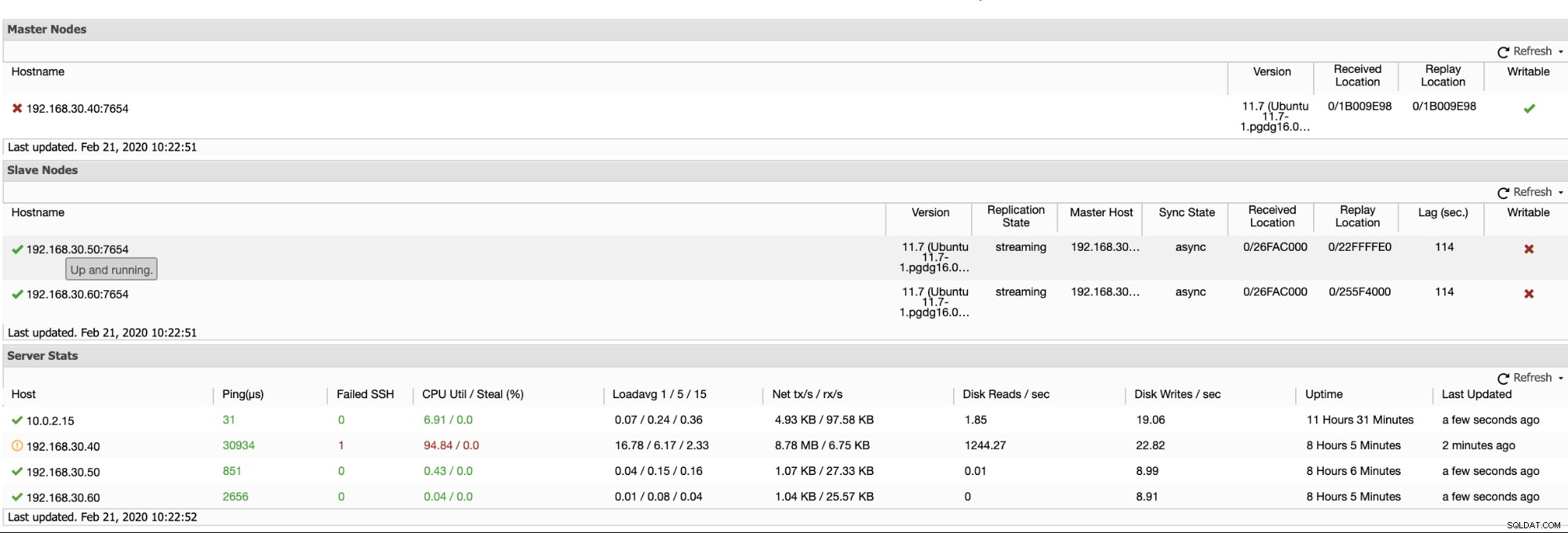
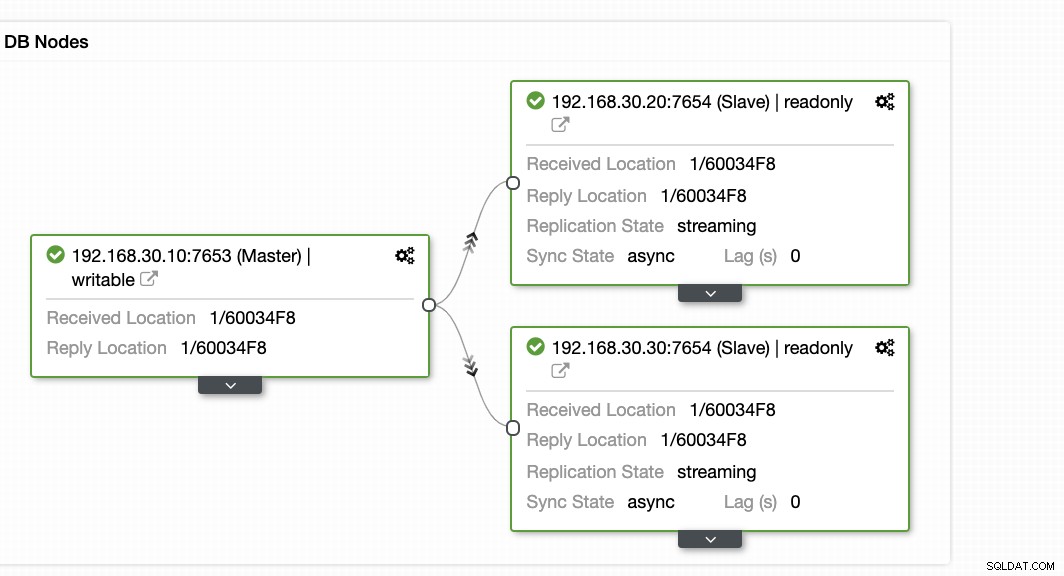
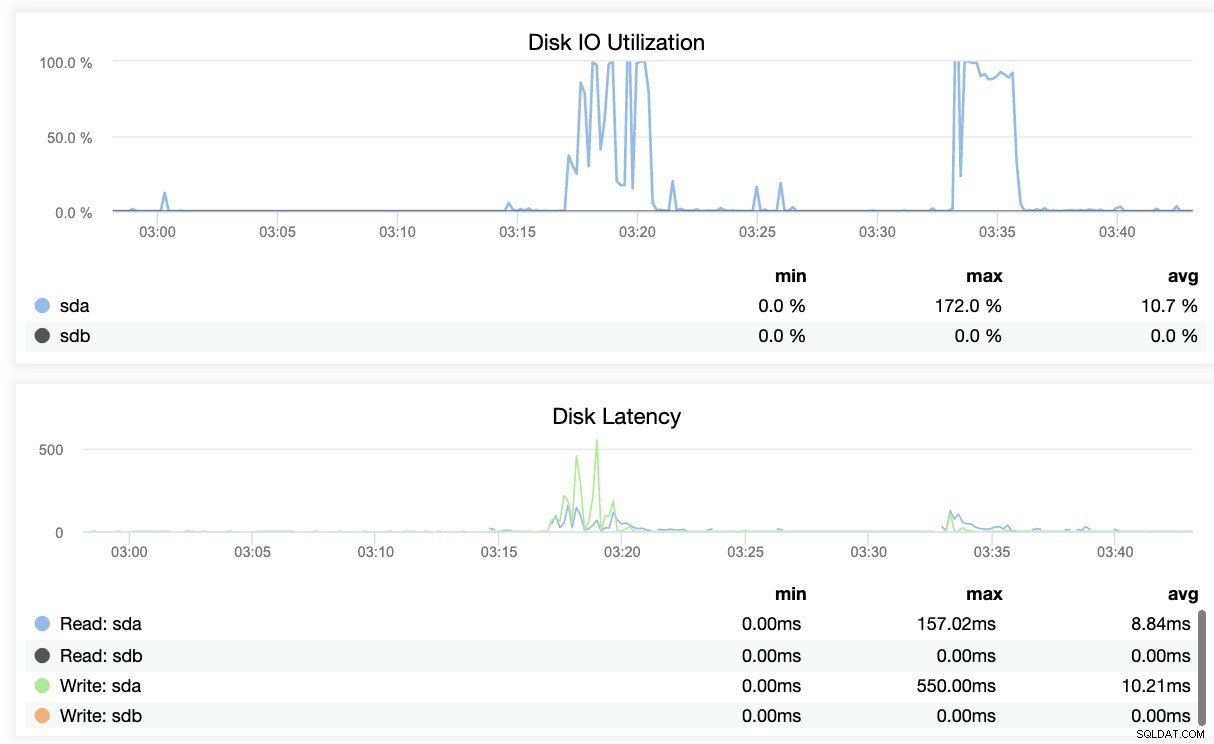
Grundlæggende viser de to skærmbilleder ovenfor, hvordan replikeringstilstanden er, og hvad der er den aktuelle WAL segmenter. Det er slet ikke. ClusterControl viser også den aktuelle aktivitet af, hvad der sker med din Cluster.
Konklusion
Overvågning af replikationssundheden i PostgreSQL kan ende med en anden tilgang, så længe du er i stand til at opfylde dine behov. Brug af tredjepartsværktøjer med observerbarhed, der kan give dig besked i tilfælde af en katastrofe, er din perfekte rute, uanset om det er en open source eller virksomhed. Det vigtigste er, at du har planlagt din katastrofegenopretningsplan og forretningskontinuitet forud for sådanne problemer.