Denne blog er en kort præsentation om Jenkins og viser dig, hvordan du bruger dette værktøj til at hjælpe med nogle af dine daglige PostgreSQL-administrations- og administrationsopgaver.
Om Jenkins
Jenkins er en open source software til automatisering. Det er udviklet i java og er et af de mest populære værktøjer til kontinuerlig integration (CI) og kontinuerlig levering (CD).
I 2010, efter Oracles opkøb af Sun Microsystems, var "Hudson"-softwaren i en tvist med dets open source-fællesskab. Denne tvist blev grundlaget for lanceringen af Jenkins-projektet.
I dag er "Hudson" (offentlig Eclipse-licens) og "Jenkins" (MIT-licens) to aktive og uafhængige projekter med et meget lignende formål.
Jenkins har tusindvis af plugins, du kan bruge for at fremskynde udviklingsfasen gennem automatisering i hele udviklingslivscyklussen; byg, dokumenter, test, pakke, fase og implementering.
Hvad laver Jenkins?
Selvom hovedanvendelsen af Jenkins kunne være kontinuerlig integration (CI) og kontinuerlig levering (CD), har denne open source et sæt funktionaliteter, og den kan bruges uden nogen forpligtelse eller afhængighed fra CI eller CD, således præsenterer Jenkins nogle interessante funktioner til udforske:
- Planlægning af periodejob (i stedet for at bruge den traditionelle crontab )
- Overvågning af job, dets logfiler og aktiviteter med en ren visning (da de har mulighed for gruppering)
- Vedligeholdelse af opgaver kunne udføres nemt; forudsat at Jenkins har et sæt muligheder for det
- Opsætning og planlægning af softwareinstallation (ved at bruge Puppet) på den samme vært eller i en anden.
- Udgivelse af rapporter og afsendelse af e-mailmeddelelser
Køre PostgreSQL-opgaver i Jenkins
Der er tre almindelige opgaver, som en PostgreSQL-udvikler eller databaseadministrator skal udføre på daglig basis:
- Planlægning og udførelse af PostgreSQL-scripts
- Udførelse af en PostgreSQL-proces sammensat af tre eller flere scripts
- Kontinuerlig integration (CI) til PL/pgSQL-udviklinger
For udførelsen af disse eksempler antages det, at Jenkins- og PostgreSQL-servere (mindst version 9.5) er installeret og fungerer korrekt.
Planlægning og udførelse af et PostgreSQL-script
I de fleste tilfælde implementering af daglige (eller periodiske) PostgreSQL-scripts til udførelse af en sædvanlig opgave såsom...
- Generering af sikkerhedskopier
- Test gendannelsen af en sikkerhedskopi
- Udførelse af en forespørgsel til rapporteringsformål
- Ryd op og arkiver logfiler
- Kald en PL/pgSQL-procedure for at rense tabeller
t er defineret på crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shSom crontab er ikke det bedste brugervenlige værktøj til at administrere denne form for planlægning, det kan gøres på Jenkins med følgende fordele...
- Meget venlig grænseflade til at overvåge deres fremskridt og nuværende status
- Loggene er tilgængelige med det samme og behøver ikke nogen særlig bevilling for at få adgang til dem
- Opgaven kunne udføres manuelt på Jenkins i stedet for at have en planlægning
- For nogle slags job er det ikke nødvendigt at definere brugere og adgangskoder i almindelige tekstfiler, da Jenkins gør det på en sikker måde
- Jobbene kunne defineres som en API-udførelse
Så det kunne være en god løsning at migrere job relateret til PostgreSQL-opgaver til Jenkins i stedet for crontab.
På den anden side har de fleste databaseadministratorer og udviklere stærke færdigheder i scriptsprog, og det ville være nemt for dem at udvikle små grænseflader til at håndtere disse scripts for at implementere de automatiserede processer med det mål at forbedre deres opgaver. Men husk, at Jenkins højst sandsynligt allerede har et sæt funktioner til at gøre det, og disse funktioner kan gøre livet nemt for udviklere, der vælger at bruge dem.
For at definere udførelsen af scriptet er det derfor nødvendigt at oprette et nyt job ved at vælge "Nyt element".
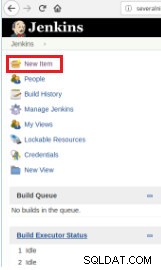 Figur 1 – "Nyt element" for at definere et job til at udføre et PostgreSQL-script
Figur 1 – "Nyt element" for at definere et job til at udføre et PostgreSQL-script Efter at have navngivet det, skal du vælge typen "FreeStyle-projekter" og klikke på OK.
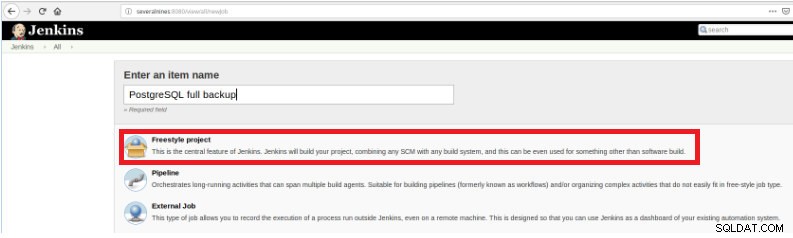 Figur 2 – Valg af jobtype (vare)
Figur 2 – Valg af jobtype (vare) For at afslutte oprettelsen af dette nye job skal du i sektionen "Byg" vælge muligheden "Udfør script" og i kommandolinjefeltet stien og parametreringen af det script, der vil blive udført:
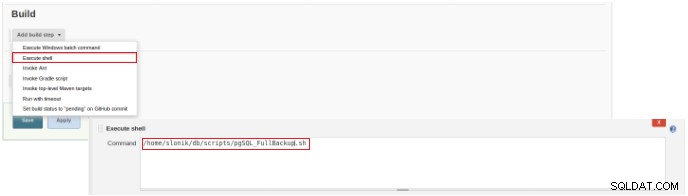 Figur 3 – Specifikation af kommandoen, der skal udføres
Figur 3 – Specifikation af kommandoen, der skal udføres Til denne type job er det tilrådeligt at verificere scripttilladelser, fordi i det mindste udførelse for den gruppe, filen tilhører, og for alle skal indstilles.
I dette eksempel er scriptet query.sh har læse- og eksekveringstilladelser for alle, læse- og eksekveringstilladelser for gruppen og læse skrive og udføre for brugeren:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Dette script har et meget simpelt sæt sætninger, som stort set kun kalder til værktøjet psql for at udføre forespørgsler:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datUdførelse af en PostgreSQL-proces sammensat af tre eller flere scripts
I dette eksempel vil jeg beskrive, hvad du skal bruge for at udføre tre forskellige scripts for at skjule følsomme data, og for det vil vi følge nedenstående trin...
- Importer data fra filer
- Forbered data til at blive maskeret
- Sikkerhedskopiering af database med maskeret data
Så for at definere dette nye job er det nødvendigt at vælge indstillingen "Ny vare" på Jenkins hovedside og derefter, efter at have tildelt et navn, skal indstillingen "Rørledning" vælges:
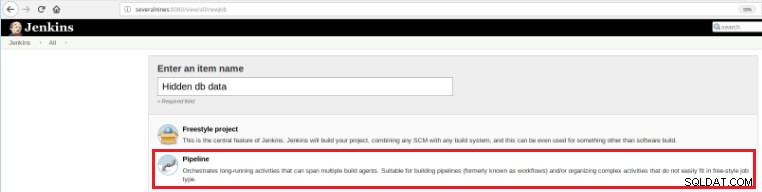 Figur 5 - Pipeline-element i Jenkins
Figur 5 - Pipeline-element i Jenkins Når jobbet er gemt i afsnittet "Pipeline", på fanen "Avancerede projektindstillinger", skal feltet "Definition" sættes til "Pipeline script", som vist nedenfor:
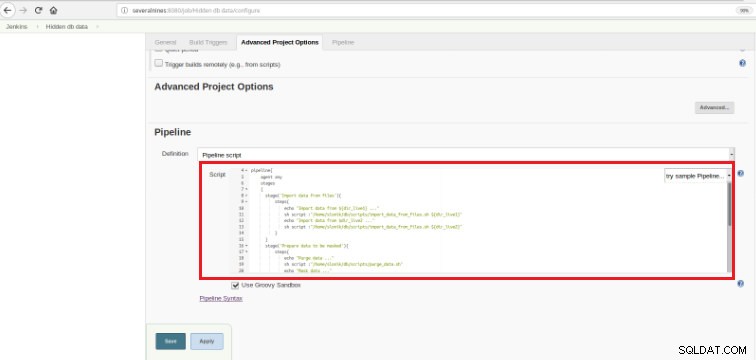 Figur 6 - Groovy script i pipeline sektion
Figur 6 - Groovy script i pipeline sektion Som jeg nævnte i begyndelsen af kapitlet, er det brugte Groovy script sammensat af tre trin, det betyder tre adskilte dele (stadier), som præsenteret i følgende script:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy er et Java-syntaks-kompatibelt objektorienteret programmeringssprog til Java-platformen. Det er både et statisk og dynamisk sprog med funktioner, der ligner dem i Python, Ruby, Perl og Smalltalk.
Det er let at forstå, da denne type script er baseret på nogle få udsagn...
Stage
Betyder de 3 processer, der vil blive udført:"Importer data fra filer", "Forbered data til at blive maskeret"
og "Backup af database med maskeret data".
Trin
Et "trin" (ofte kaldet et "byggetrin") er en enkelt opgave, der er en del af en sekvens. Hver fase kan bestå af flere trin. I dette eksempel har den første fase to trin.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Dataene importeres fra to forskellige kilder.
I det foregående eksempel er det vigtigt at bemærke, at der er to variable defineret i begyndelsen og med et globalt omfang:
dir_live1
dir_live2De scripts, der bruges i disse tre trin, kalder psql , pg_restore og pg_dump hjælpeprogrammer.
Når jobbet er defineret, er det tid til at udføre det, og for det er det kun nødvendigt at klikke på indstillingen "Byg nu":
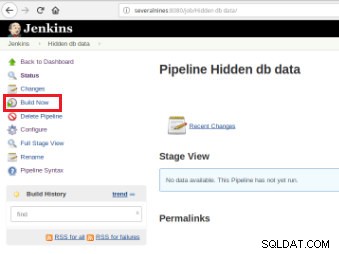 Figur 7 – Udførelsesjob
Figur 7 – Udførelsesjob Når buildet er startet, er det muligt at verificere dets fremskridt.
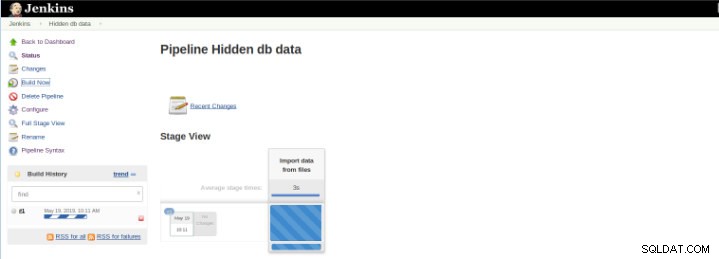 Figur 8 – Start af “Build”
Figur 8 – Start af “Build” Pipeline Stage View-pluginnet inkluderer en udvidet visualisering af Pipeline-byggehistorik på indekssiden for et flowprojekt under Stage View. Denne visning bygges, så snart opgaverne er afsluttet, og hver opgave er repræsenteret med kolonne fra venstre mod højre, og det er muligt at se og sammenligne den forløbne tid for serval-henrettelserne (kendt som en Build in Jenkins).
Når udførelsen (også kaldet en Build) er færdig, er det muligt at få yderligere detaljer ved at klikke på den færdige tråd (rød boks).
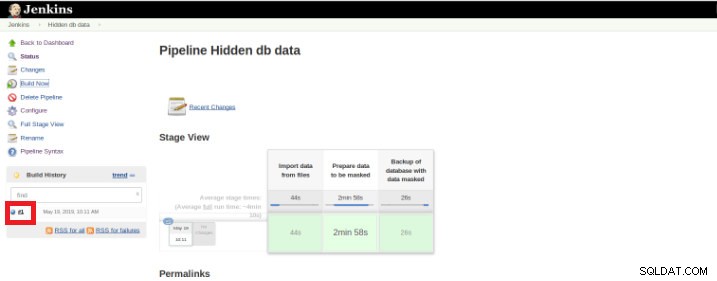 Figur 9 – Start af “Build”
Figur 9 – Start af “Build” og derefter i "Konsoloutput".
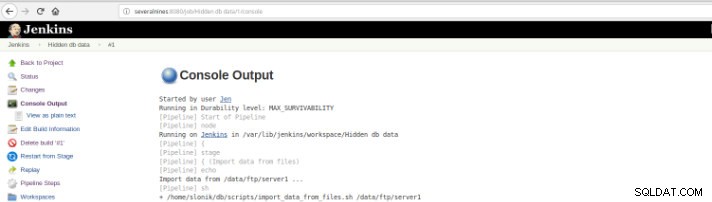 Figur 10 – Konsoloutput
Figur 10 – Konsoloutput De tidligere visninger er ekstremt nyttige, da de gør det muligt at få en opfattelse af den kørselstid, der kræves af hvert trin.
Pipelines, også kendt som workflow, det er et plugin, der tillader definitionen af applikationens livscyklus, og det er en funktionalitet, der bruges i Jenkins til kontinuerlig levering (CD). i tankerne.
Dette eksempel er for at skjule følsomme data, men der er helt sikkert mange andre eksempler på daglig basis af PostgreSQL-databaseadministrator, som kan udføres på et pipelinejob.
Pipeline har været tilgængelig på Jenkins siden version 2.0, og det er en utrolig løsning!

Kontinuerlig integration (CI) til PL/pgSQL-udviklinger
Den kontinuerlige integration til databaseudviklingen er ikke så let som i andre programmeringssprog på grund af de data, der kan gå tabt, så det er ikke nemt at holde databasen i kildekontrol og implementere den på en dedikeret server, især når der er scripts der indeholder DDL (Data Definition Language) og DML (Data Manipulation Language) sætninger. Dette skyldes, at denne slags udsagn ændrer databasens aktuelle tilstand, og i modsætning til andre programmeringssprog er der ingen kildekode at kompilere.
På den anden side er der et sæt databaseudsagn, for hvilke det er muligt kontinuerlig integration som for andre programmeringssprog.
Dette eksempel er kun baseret på udvikling af procedurer, og det vil illustrere udløsningen af et sæt tests (skrevet i Python) af Jenkins, når PostgreSQL-scripts, hvorpå koden for følgende funktioner er gemt, er begået i et kodelager.
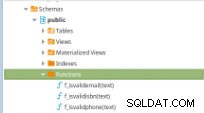 Figur 11 – PLpg/SQL-funktioner
Figur 11 – PLpg/SQL-funktioner Disse funktioner er enkle, og indholdet har kun nogle få logik eller en forespørgsel i PLpg/SQL eller plperlu sprog som funktionen f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Alle de funktioner, der præsenteres her, er ikke afhængige af hinanden, og så er der ingen forrang hverken i dets udvikling eller i dets udrulning. Da det vil blive verificeret forud, er der ingen afhængighed af deres valideringer.
Så for at udføre et sæt valideringsscripts, når først en commit er udført i et kodelager, er det nødvendigt at oprette et byggejob (nyt element) i Jenkins:
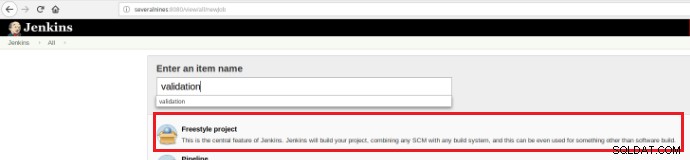 Figur 12 – "Freestyle"-projekt for kontinuerlig integration
Figur 12 – "Freestyle"-projekt for kontinuerlig integration Dette nye byggejob skal oprettes som et "Freestyle"-projekt, og i afsnittet "Kildekodelager" skal URL-adressen til depotet og dets legitimationsoplysninger (orange boks) defineres:
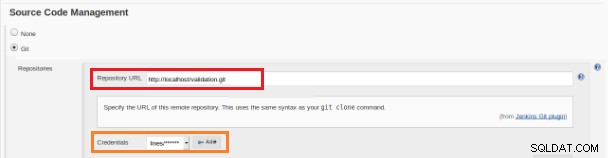 Figur 13 – Kildekodelager
Figur 13 – Kildekodelager I sektionen "Build Triggers" skal muligheden "GitHub hook trigger for GITScm polling" være markeret:
 Figur 14 – afsnittet "Byg udløsere"
Figur 14 – afsnittet "Byg udløsere" Til sidst, i "Byg" sektionen, skal indstillingen "Execute Shell" vælges, og i kommandoboksen skal de scripts, der udfører valideringen af de udviklede funktioner:
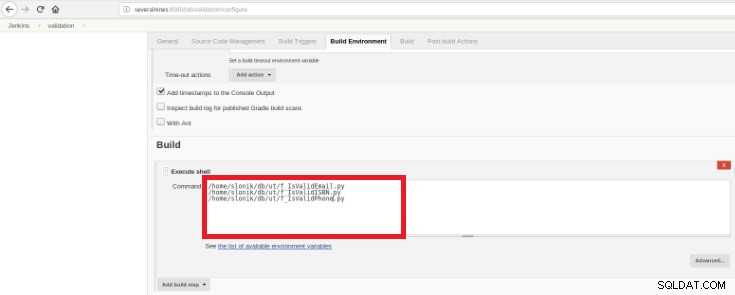 Figur 15 – afsnittet "Byg miljø"
Figur 15 – afsnittet "Byg miljø" Formålet er at have ét valideringsscript for hver udviklet funktion.
Dette Python-script har et simpelt sæt sætninger, der kalder disse procedurer fra en database med nogle foruddefinerede forventede resultater:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Dette script vil teste den præsenterede PLpg/SQL eller plperlu funktioner, og det vil blive udført efter hver commit i kodelageret for at undgå regression på udviklingen.
Når denne jobbuild er udført, kan logudførelserne verificeres.
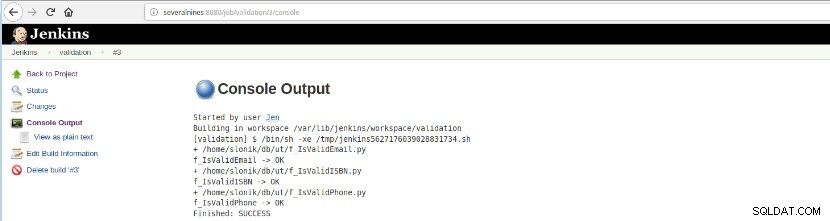 Figur 16 – "Konsoloutput"
Figur 16 – "Konsoloutput" Denne mulighed præsenterer den endelige status:SUCCES eller FEJL, arbejdsområdet, de udførte filer/script, de oprettede midlertidige filer og fejlmeddelelserne (for de fejlede)!
Konklusion
Sammenfattende er Jenkins kendt som et fantastisk værktøj til kontinuerlig integration (CI) og kontinuerlig levering (CD), men det kan bruges til forskellige funktioner som,
- Planlægning af opgaver
- Udførelse af scripts
- Overvågning af processer
Til alle disse formål på hver udførelse (Byg på Jenkins ordforråd) kan det analyseres logfilerne og den forløbne tid.
På grund af et stort antal tilgængelige plugins kunne det undgå nogle udviklinger med et specifikt formål, sandsynligvis er der et plugin der gør præcis det du leder efter, det er bare et spørgsmål om at søge i opdateringscenteret eller Administrer Jenkins>>Administrer plugins inde webapplikationen.