Her er vi. Næsten to årtier inde i det 21. århundrede, og behovet for mere computerkraft er stadig et problem. Teknologivirksomheder banker på fortovet for at tackle dette massive problem direkte. Hardwareingeniører har fundet en løsning ved at ændre den måde, de designer og fremstiller en computers centralenhed (CPU). De indeholder nu flere kerner, hvilket giver mulighed for samtidighed. Til gengæld har softwareudviklere tilpasset den måde, de skriver programmer på, for at tilpasse sig denne ændring i hardware.
PostgreSQL-fællesskabet har udnyttet disse multi-core CPU'er fuldt ud til at forbedre forespørgselsydeevnen. Ved blot at opdatere til version 9.6 eller højere, kan du bruge en funktion kaldet forespørgselsparallelisme til at udføre forskellige operationer. Det opdeler opgaver i mindre dele og spreder hver opgave på tværs af flere CPU-kerner. Hver kerne kan behandle opgaverne på samme tid. På grund af hardwarebegrænsninger er dette den eneste måde at forbedre computerens ydeevne på, når vi bevæger os ind i fremtiden.
Før du bruger parallelitetsfunktionen i PostgreSQL-databasen, er det vigtigt at genkende, hvordan det gør en forespørgsel parallel. Du vil være i stand til at fejlsøge og løse eventuelle problemer, der opstår.
Hvordan virker forespørgselsparallelisme?
For at få en bedre forståelse af, hvordan parallelisme udføres, er det en god idé at starte på klientniveau. For at få adgang til PostgreSQL skal en klient sende en forbindelsesanmodning til databaseserveren kaldet postmaster. Postmasteren vil fuldføre godkendelse og derefter forgrene sig for at oprette en ny serverproces for hver forbindelse. Den er også ansvarlig for at skabe et område med delt hukommelse, som indeholder en bufferpulje. Bufferpuljen overvåger overførslen af data mellem den delte hukommelse og lageret. Derfor, i det øjeblik en forbindelse er etableret, vil bufferpuljen overføre data og tillade, at forespørgselsparallelisme kan finde sted.
Det er ikke nødvendigt, at alle forespørgsler er parallelle. Der er tilfælde, hvor kun en lille mængde data er nødvendig, og den kan hurtigt behandles af kun én kerne. Denne funktion bruges kun, når en forespørgsel vil tage lang tid at fuldføre. Databaseoptimeringsværktøjet bestemmer, om parallelisme skal udføres. Hvis det er nødvendigt, vil databasen bruge en ekstra del af hukommelsen kaldet dynamisk delt hukommelse (DSM). Dette gør det muligt for lederprocessen og de parallelle bevidste arbejdsprocesser at opdele forespørgslen mellem flere kerner og indsamle relevante data.
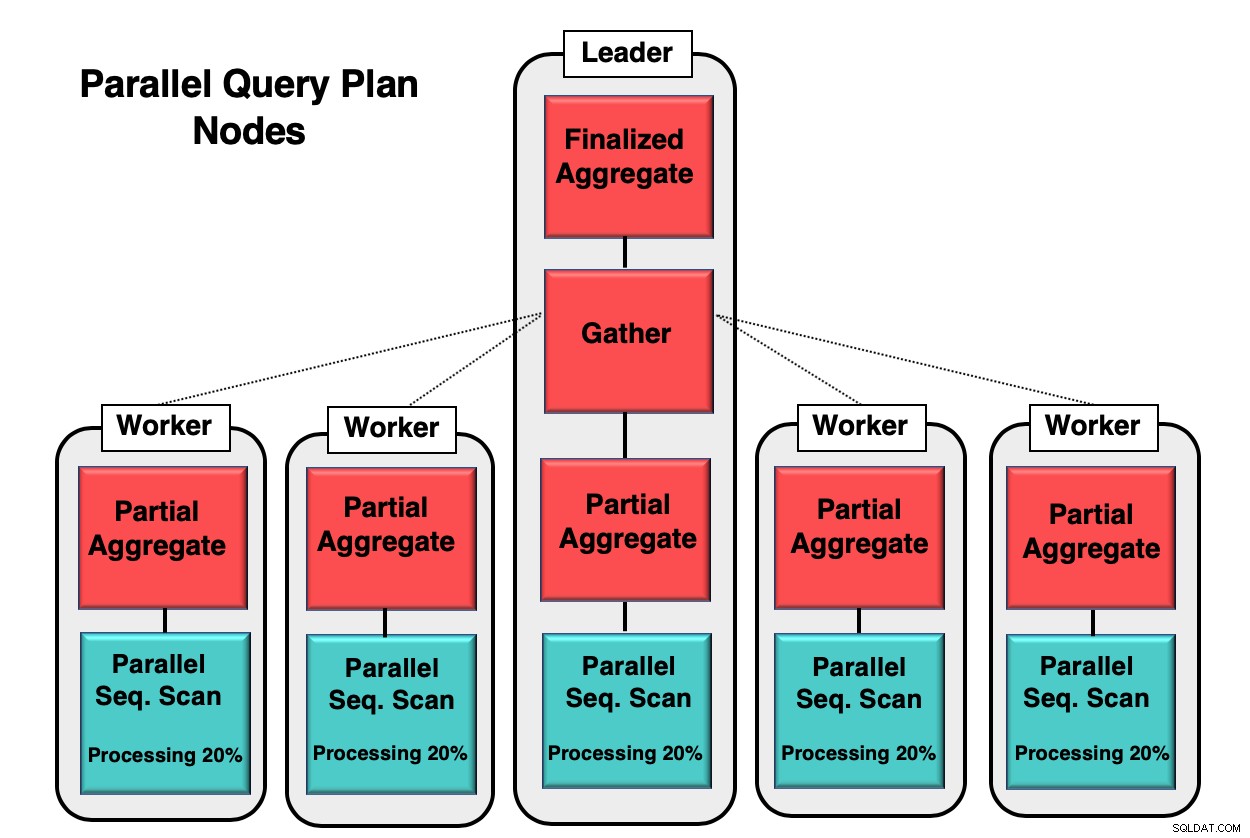
Figur 1 giver dig et eksempel på, hvordan parallelisme finder sted inde i databasen. Lederprocessen kører den indledende forespørgsel, mens de enkelte arbejdsprocesser starter en kopi af den samme proces. Den partielle aggregerede node eller CPU-kerne er ansvarlig for implementering af den parallelle sekventielle scanning af databasetabellen.
I dette tilfælde behandler hver sekventiel scanningsknude 20 % af data i 8 kb blokke. Disse samme noder kan koordinere deres aktivitet ved at bruge en teknik kaldet parallel aware. Hver node har fuld viden om, hvilke data der allerede er blevet behandlet, og hvilke data der skal scannes i tabellen for at fuldføre forespørgslen. Når tuplerne er samlet fuldt ud, sendes de til samlingsknuden for at blive kompileret og afsluttet.
Parallelle operationer
Forskellige typer forespørgsler kan bruges til at hente data fra en database for at producere resultatsæt. Her er specifikke operationer, der giver dig mulighed for at udnytte brugen af flere kerner effektivt.
Sekventiel scanning
Denne operation læser data i en tabel fra begyndelsen til slutningen for at indsamle data. Den fordeler arbejdsbyrden jævnt mellem flere kerner for at øge forespørgselsbehandlingshastigheden. Den er opmærksom på hver kerneaktivitet, hvilket gør det nemmere at afgøre, om hele forespørgslen er gennemført. Indsamlingsknuden modtager derefter de udtrukne data baseret på forespørgslen.
Aggregation
En standardoperation, som tager en stor mængde data og kondenserer dem til et mindre antal rækker. Dette sker under den parallelle behandling ved kun at udtrække de relevante oplysninger fra en tabel eller indekser baseret på forespørgslen. At udføre et gennemsnit af specifikke data er et glimrende eksempel på aggregering.
Hash Join
En teknik, der bruges til at forbinde data mellem to tabeller. Det er den hurtigste join-algoritme, som typisk udføres med en lille tabel og en stor. Du opretter først en hash-tabel og indlæser alle data fra én tabel derind. Derefter kan du scanne alle data fra hash- og anden tabel ved hjælp af parallel sekventiel scanning. Hver tuple, der er udtrukket fra scanningen, sammenlignes med hash-tabellen for at se, om der er et match. Hvis et match identificeres, bliver dataene slået sammen. Med udgivelsen af PostgreSQL 11 tager det omkring en tredjedel af dens tidligere behandlingstid at bruge parallelisme til at fuldføre en hash-join.
Flet tilmelding
Hvis optimeringsværktøjet bestemmer, at en hash-join kommer til at overskride hukommelseskapaciteten, vil den i stedet udføre en merge-join. Processen involverer scanning gennem to sorterede lister på samme tid og samler de samme elementer. Hvis elementerne ikke er ens, bliver dataene ikke slået sammen.
Nested Loop Join
Denne operation bruges, når du skulle forbinde to tabeller indeholdende forskellige programmeringssprog, såsom Quick Basic, Python osv. Hver tabel scannes og behandles ved at bruge flere kerner. Hvis dataene matcher, sendes de til samlingsknuden for at blive tilsluttet. Indekserne scannes også, hvorfor denne proces indeholder flere loops til at hente dataene. I gennemsnit vil det kun tage en tredjedel af tiden at fuldføre sammenføjningen ved at bruge den parallelle proces.
B-tree Index Scan
Denne handling scanner gennem et træ af sorterede data for at finde specifik information. Denne proces tager længere tid end den typiske sekventielle scanning, fordi der er meget ventetid, mens du leder efter poster. Arbejdet med at scanne efter de relevante data er dog delt mellem flere processorer.
Bitmap Heap Scan
Du kan flette flere indekser ved at bruge denne operation. Du vil først oprette det tilsvarende antal bitmaps, da du har indekser. For eksempel, hvis du har tre indekser, skal du først oprette tre bitmaps. Hver bitmap henter og kompilerer tuples baseret på forespørgslen.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperPartitionsparallelisme
Der er en anden form for parallelisme, der kan finde sted i PostgreSQL-databasen. Det kommer dog ikke fra scanning af tabeller og opdeling af opgaverne. Du kan partitionere eller opdele dataene efter specifikke værdier. For eksempel kan du tage værdikøberne og få en enkelt kerne til at behandle dataene inden for den værdi. På den måde ved du præcist, hvad hver kerne behandler på et givet tidspunkt.
Hash-partitionering
Denne operation bruges til at sprede tabelrækker i undertabeller. Igen, skellet bestemmes generelt af en særskilt værdi eller værdiliste fra en tabel. Dette er en fremragende metode at bruge, hvis du ikke har en effektiv lagerstyringsteknik på tværs af alle dine enheder. Du ønsker at bruge partitionering til at distribuere data tilfældigt for at forhindre I/O-flaskehalse.
Deltag i partition
En teknik, der bruges til at opdele tabeller efter partitioner og forbinde dem ved at matche lignende partitioner. For eksempel kan du have en stor tabel med købere fra hele USA. Du kan først opdele tabellen efter forskellige byer og derefter slå nogle byer sammen baseret på regionen i hver stat. Partitionsmæssig joinforbindelse forenkler dine data og giver mulighed for at manipulere tabeller.
Parallel usikker
PostgreSQL 11 udfører automatisk forespørgselsparallelisme, hvis optimeringsværktøjet bestemmer, at dette er den hurtigste måde at fuldføre forespørgslen på. Jo højere PostgreSQL-version du bruger, jo mere parallel kapacitet vil din database have. Desværre bør ikke alle forespørgsler udføres parallelt, selvom det har muligheden. Den type forespørgsel, du udfører, kan have specifikke begrænsninger, og det vil kræve, at kun én kerne fuldfører hele behandlingen. Dette vil bremse dit systems ydeevne, men det vil garantere, at de modtagne data er hele.
For at sikre, at dine forespørgsler aldrig bringes i fare, har udviklere lavet en funktion kaldet parallel unsafe. Du kan manuelt tilsidesætte databaseoptimeringsværktøjet og anmode om, at forespørgslen aldrig bliver parallel. Processen med parallelitet vil ikke blive udført.
Parallelisme i PostgreSQL-databasen er en funktion, der kun bliver bedre med hver databaseversion. Selvom teknologiens fremtid er usikker, ser det ud til, at brugen af denne funktion er kommet for at blive.
For mere information kan du tjekke følgende...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table