Introduktion
I dag er høj tilgængelighed et krav for mange systemer, uanset hvilken teknologi du bruger. Dette er især vigtigt for databaser, da de gemmer data, som kritiske applikationer og systemer er afhængige af. Den mest almindelige strategi for at opnå høj tilgængelighed er replikering. Der er forskellige måder at replikere data på tværs af flere servere og failover-trafik, når f.eks. en primær server holder op med at reagere.
Høj tilgængelighedsarkitektur til PostgreSQL
Der er adskillige arkitekturer til implementering af høj tilgængelighed i PostgreSQL, men de grundlæggende er Primær-Standby og Primær-Primær arkitekturer.
Primære-standby-arkitekturer
Primær-Standby kan være den mest grundlæggende HA-arkitektur, du kan sætte op, og ofte den nemmeste at implementere og vedligeholde. Den er baseret på en primær database med en eller flere standby-servere. Disse Standby-databaser forbliver synkroniserede (eller næsten synkroniserede) med den primære node, afhængigt af om replikeringen er synkron eller asynkron. Hvis den primære server fejler, indeholder Standby-serveren næsten alle den primære servers data og kan hurtigt omdannes til den nye primære databaseserver.
Du kan implementere to typer standby-databaser, baseret på arten af replikeringen:
- Logiske standbys – Replikeringen mellem Primær og Standby foretages via SQL-sætninger.
- Fysiske Standbys – Replikeringen mellem Primær og Standby foretages via de interne datastrukturændringer.
I tilfælde af PostgreSQL bruges en strøm af WAL-poster (Write-ahead Log) til at holde Standby-databaserne synkroniserede. Dette kan være synkront eller asynkront, og hele databaseserveren er replikeret.
Fra og med version 10 inkluderer PostgreSQL en indbygget mulighed for at opsætte logisk replikering, som konstruerer en strøm af logiske datamodifikationer ud fra informationen i fremskrivningsloggen. Denne replikeringsmetode gør det muligt at replikere dataændringerne fra individuelle tabeller uden at skulle udpege en primær server. Det tillader også data at flyde i flere retninger.
Desværre er en primær standby-opsætning ikke nok til effektivt at sikre høj tilgængelighed, da du også skal håndtere fejl. For at håndtere fejl skal du være i stand til at opdage dem. Når du ved, at der er en fejl, f.eks. fejl på den primære knude eller knudepunktet, der ikke reagerer, kan du vælge en standby-knude for at erstatte den fejlbehæftede knude med den mindst mulige forsinkelse. Denne proces skal være så effektiv som muligt for at genoprette fuld funktionalitet til applikationerne. PostgreSQL selv inkluderer ikke en automatisk failover-mekanisme, så dette vil kræve nogle brugerdefinerede scripts eller tredjepartsværktøjer til denne automatisering.
Når der er sket en failover, skal din applikation underrettes i overensstemmelse hermed for at begynde at bruge den nye primære. Du skal også evaluere tilstanden af din arkitektur efter failover, fordi du kan løbe ind i en situation, hvor kun den nye primære kører (f.eks. havde du en primær node og kun én standby før problemet). I så fald skal du tilføje en standby-knude for at genskabe den primære standby-opsætning, du oprindeligt havde for høj tilgængelighed.
Primær-Primær arkitektur
Primær-Primær arkitektur giver en måde at minimere indvirkningen af en fejl på en af knudepunkterne, da den eller de andre knudepunkter kan tage sig af al trafikken og kun potentielt påvirke ydeevnen en smule men aldrig at miste funktionalitet. Primær-Primær arkitektur bruges ofte med det dobbelte formål at skabe et miljø med høj tilgængelighed og skalere horisontalt (sammenlignet med konceptet med vertikal skalerbarhed, hvor du tilføjer flere ressourcer til en server).
PostgreSQL understøtter endnu ikke denne arkitektur "native", så du bliver nødt til at henvise til tredjepartsværktøjer og -implementeringer. Når du vælger en løsning, skal du huske på, at der er mange projekter/værktøjer, men nogle af dem understøttes ikke længere, mens andre er nye og måske ikke kamptestes i produktionen.
Belastningsbalancering
Load balancers er værktøjer, der kan bruges til at styre trafikken fra din applikation for at få mest muligt ud af din databasearkitektur.
Ikke kun er disse værktøjer nyttige til at balancere belastningen af dine databaser, men de hjælper også applikationer med at blive omdirigeret til de tilgængelige/sunde noder og endda specificere porte med forskellige roller.
HAProxy er en belastningsbalancer, der distribuerer trafik fra én oprindelse til en eller flere destinationer og kan definere specifikke regler og/eller protokoller for denne opgave. Hvis nogen af destinationerne holder op med at svare, markeres de som offline, og trafikken sendes til resten af de tilgængelige destinationer.
Keeplived er en tjeneste, der giver dig mulighed for at konfigurere en virtuel IP-adresse inden for en aktiv/passiv gruppe af servere. Denne virtuelle IP-adresse er tildelt en aktiv server. Hvis denne server fejler, migreres IP-adressen automatisk til den "Sekundære" passive server, så den kan fortsætte med at arbejde med den samme IP-adresse på en gennemsigtig måde for systemerne.
Lad os nu se, hvordan man implementerer en Primary-Standby PostgreSQL-klynge med load balancer-servere og keepalive konfigureret mellem dem. Vi vil demonstrere dette ved hjælp af ClusterControls brugervenlige grænseflade.
For dette eksempel vil vi oprette:
- 3 PostgreSQL-servere (en primær og to standbys).
- 2 HAProxy Load Balancers.
- Opretholdt konfigureret mellem load balancer-serverne.
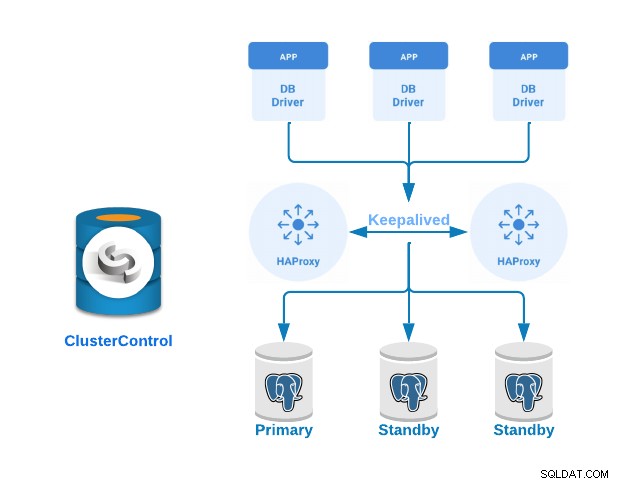
Databaseimplementering
For at implementere en database ved hjælp af ClusterControl skal du blot vælge muligheden "Deploy" og følge instruktionerne, der vises.
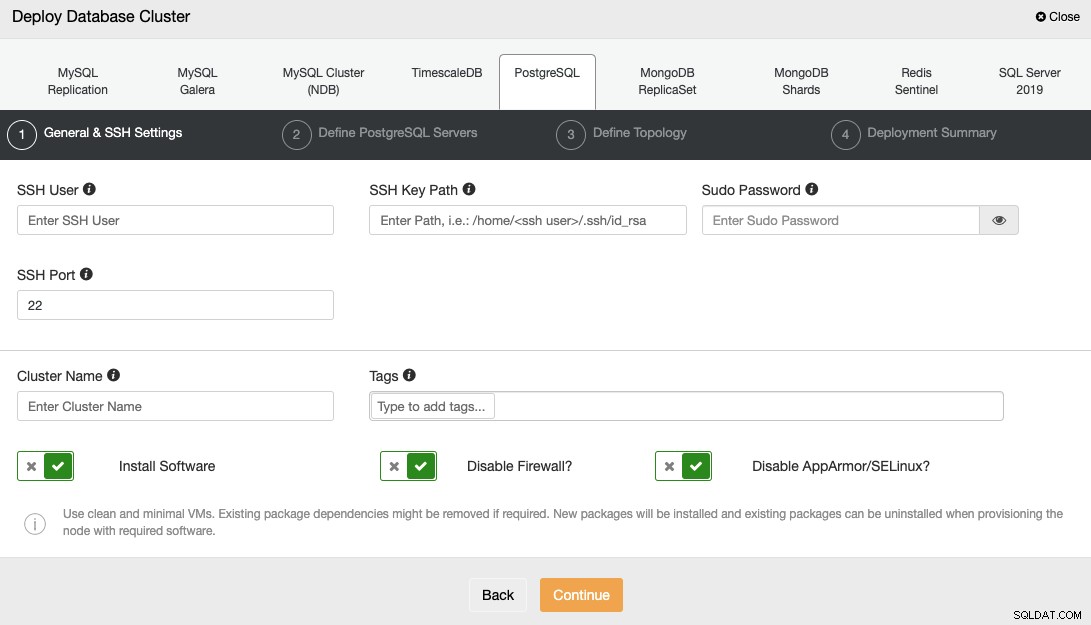
Når du vælger PostgreSQL, skal du angive brugeren, nøglen eller adgangskoden og Port for at forbinde med SSH til dine servere. Du skal også bruge navnet på din nye klynge og vælge, om du vil have ClusterControl til at installere den tilsvarende software og konfigurationer for dig.
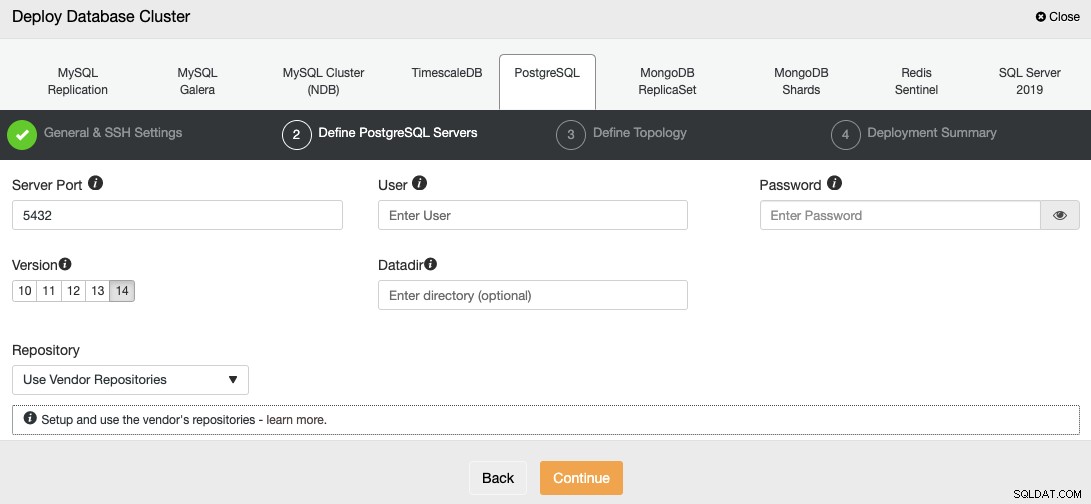
Efter opsætning af SSH-adgangsoplysningerne skal du definere databasebrugeren, version og datadir (valgfrit). Du kan også angive, hvilket lager der skal bruges; det officielle leverandørlager vil blive brugt som standard.
I næste trin skal du tilføje dine servere til den klynge, du vil oprette.
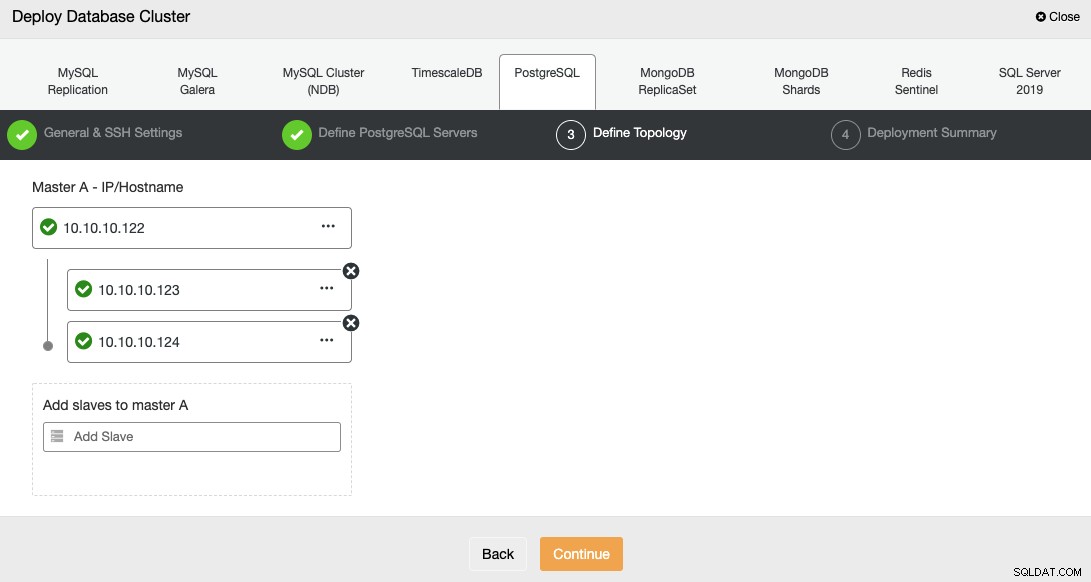
Når du tilføjer dine servere, kan du indtaste IP eller værtsnavn.
I det sidste trin kan du vælge, om din replikering skal være Synkron eller Asynkron.
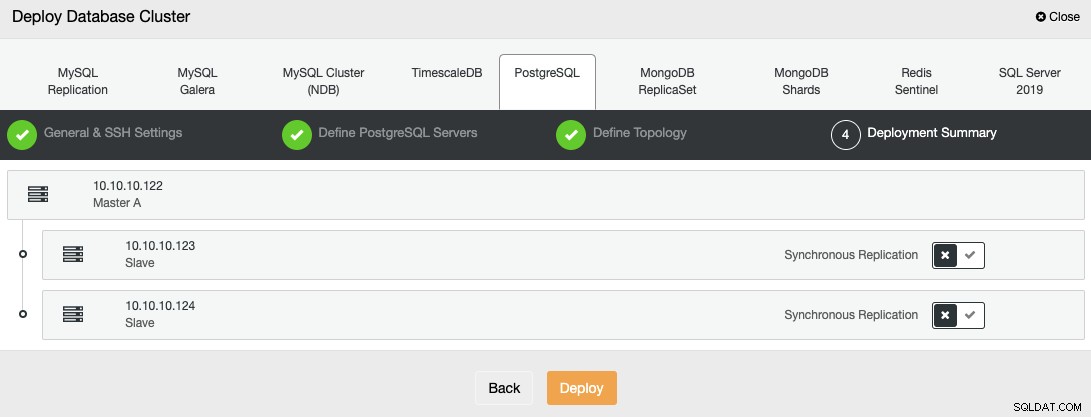
Du kan overvåge status for oprettelsen af din nye klynge fra ClusterControl aktivitetsmonitor.
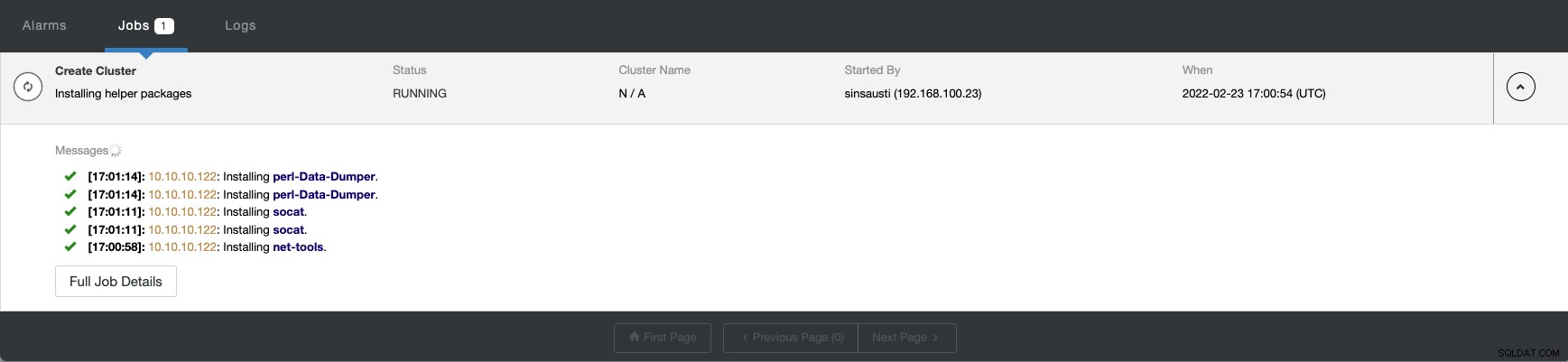
Når opgaven er færdig, kan du se din klynge i hoved ClusterControl skærm.
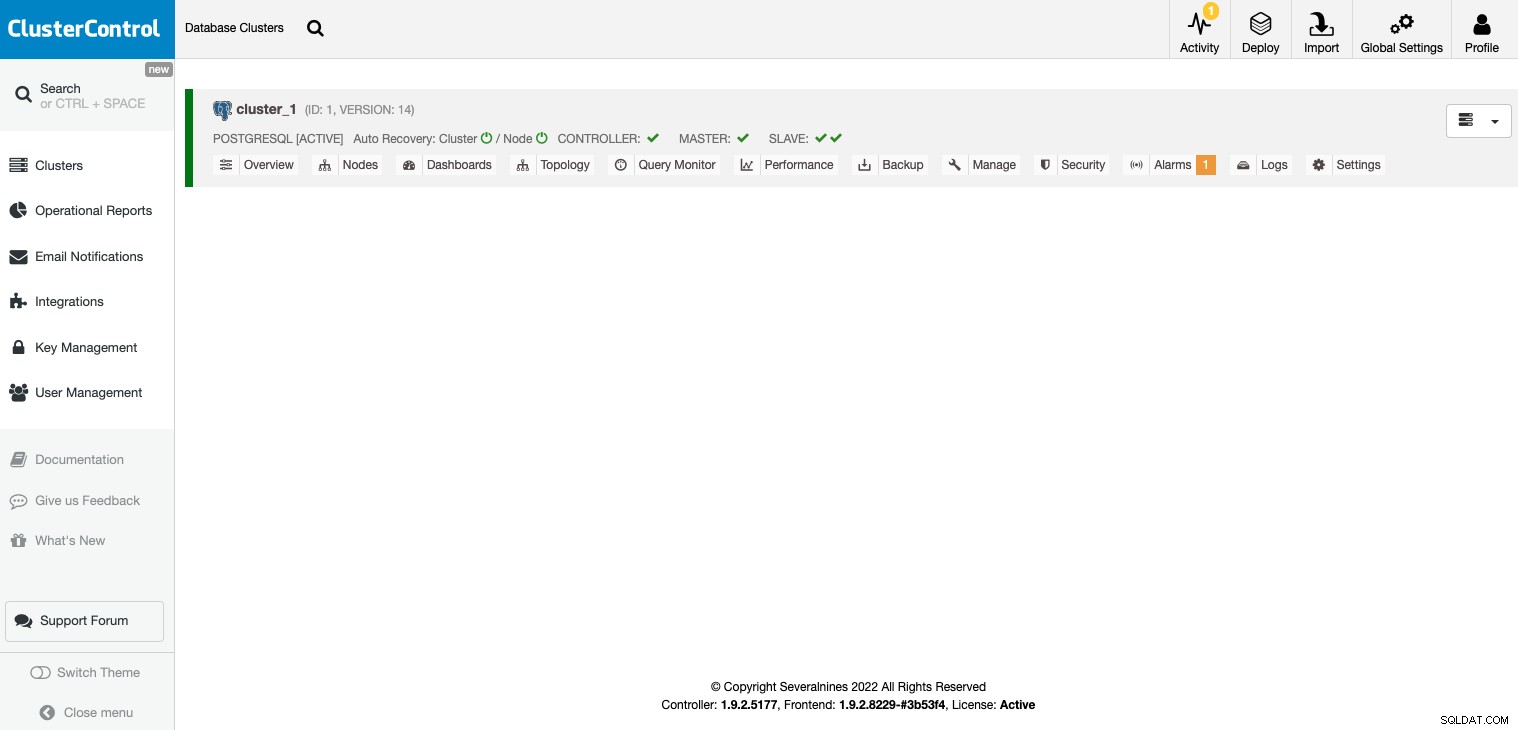
Når din klynge er oprettet, kan du udføre flere opgaver, såsom at tilføje en load balancer (HAProxy) eller en ny replika.
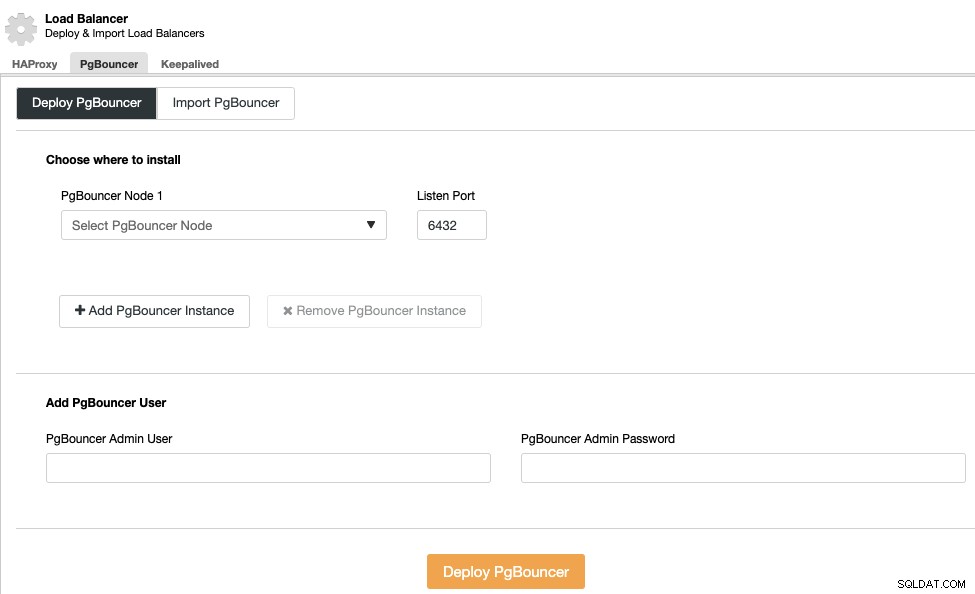
Load Balancer-implementering
For at udføre en load balancer-implementering skal du vælge "Tilføj load balancer"-indstillingen i klyngehandlingerne og udfylde de anmodede oplysninger.
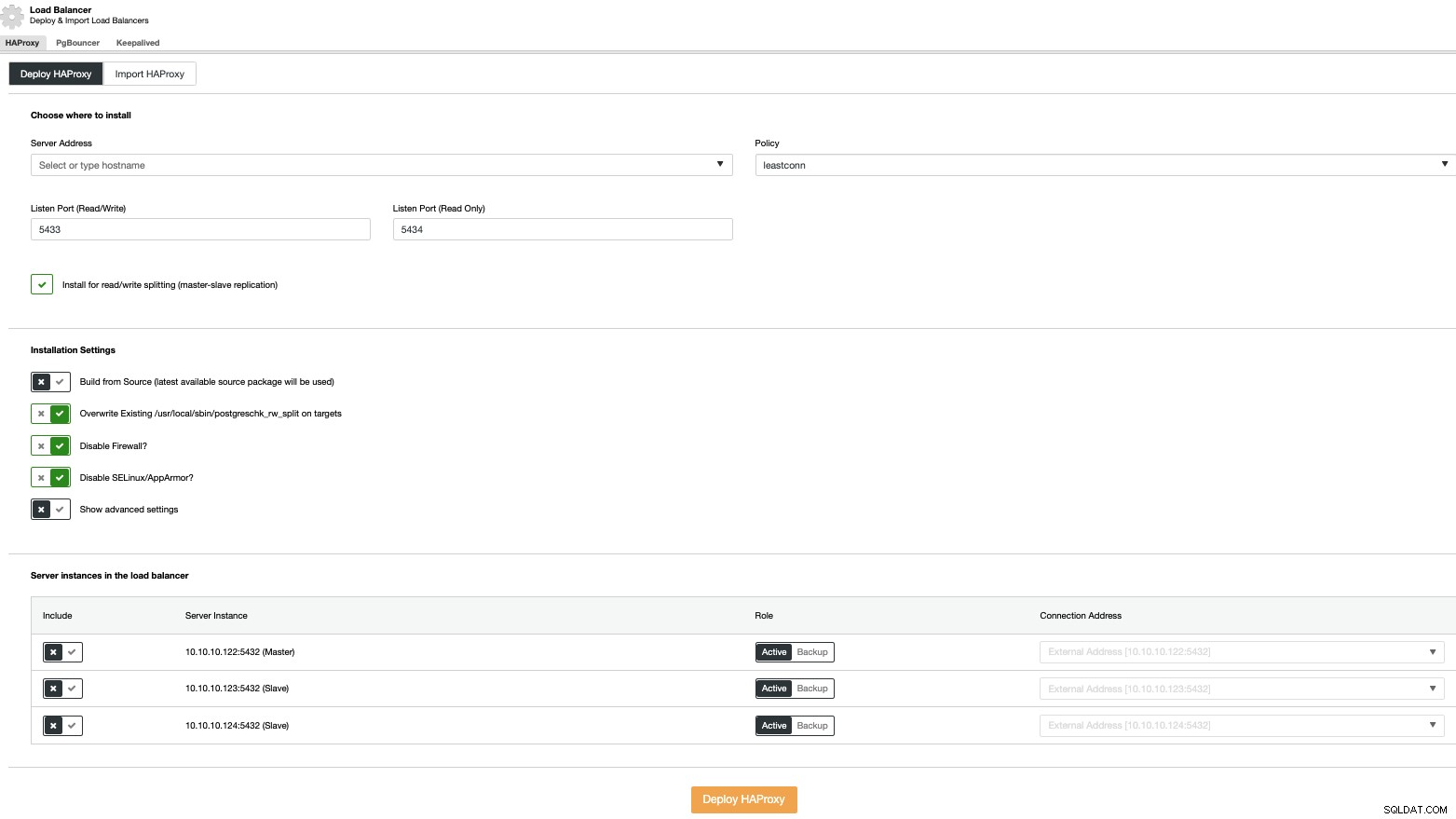
Du behøver kun at tilføje IP-adressen eller værtsnavnet, porten, politik, og de noder, du vil konfigurere i dine belastningsbalancere.
Keelived implementering
For at udføre en Keepalive-implementering skal du vælge klyngen, gå til menuen "Administrer" og sektionen "Load Balancer" og derefter vælge muligheden "Keelived".
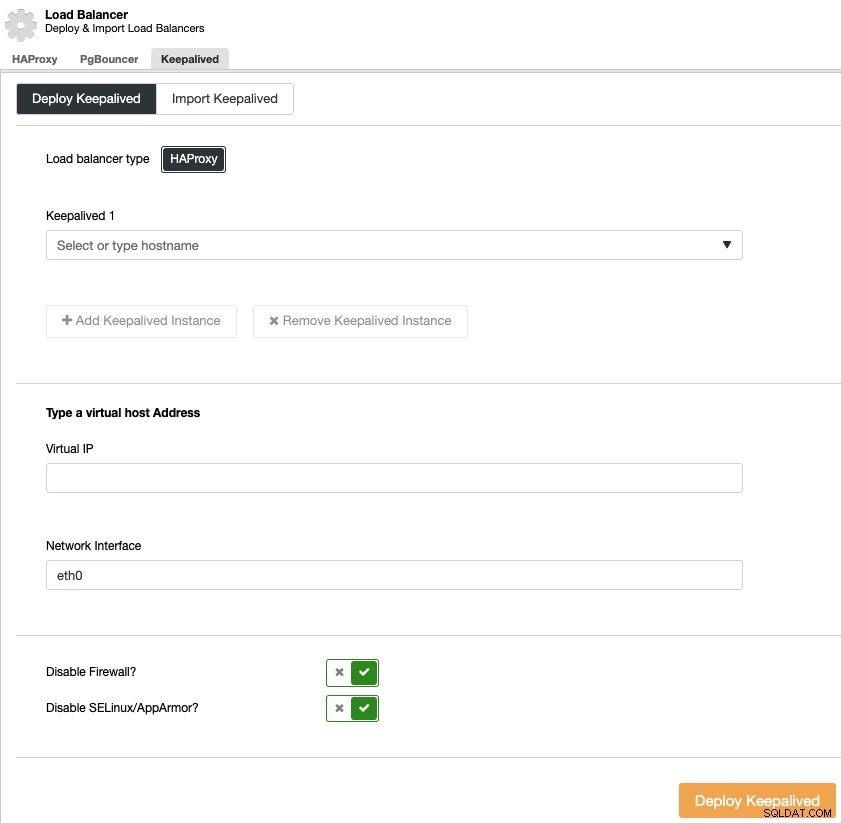
Du skal vælge load balancer-servere og den virtuelle IP-adresse til din høje tilgængelighedsmiljø.
Keelived bruger den virtuelle IP-adresse og migrerer den fra én load balancer til en anden i tilfælde af fejl, så dine systemer kan fortsætte med at fungere normalt.
Hvis du fulgte de foregående trin, skulle du have følgende topologi:
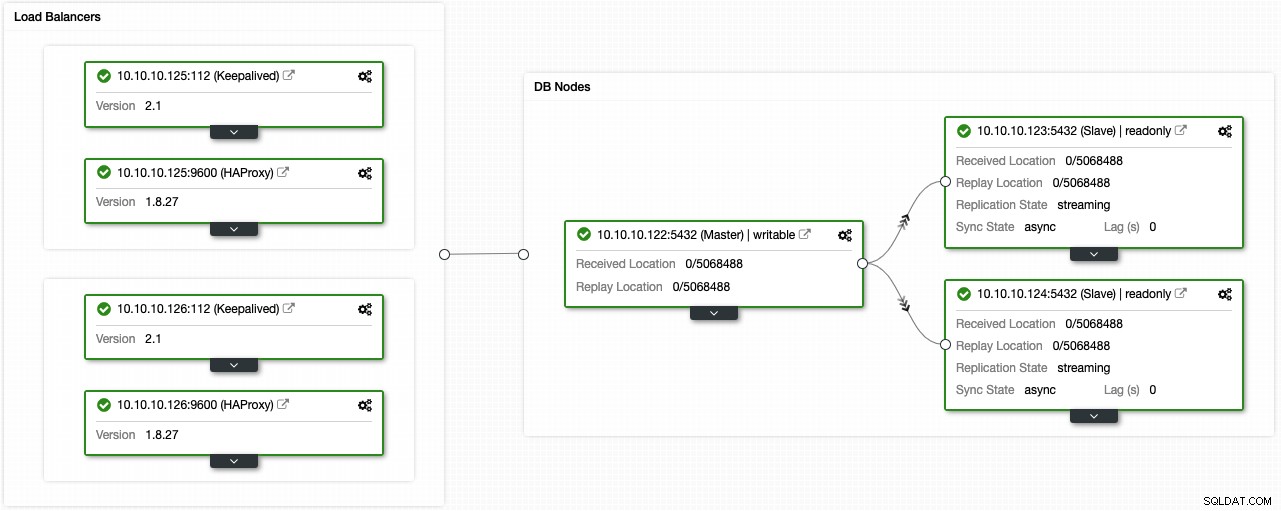
Du kan forbedre dette miljø med høj tilgængelighed ved at tilføje en forbindelsespooler som PgBouncer. Det er ikke et must, men det kan være nyttigt at forbedre ydeevnen og håndtere aktive forbindelser i tilfælde af fejl, og det bedste er, at du også kan implementere det ved at bruge ClusterControl.
ClusterControl Failover
Antag, at "Autorecovery"-indstillingen er TIL i din ClusterControl-server. I tilfælde af en primær fejl, vil ClusterControl promovere den mest avancerede Standby (hvis den ikke er på sortlisten) til Primær, samt give dig besked om problemet. Det vil også failover resten af standby-knuderne for at replikere fra den nye primære.
HAProxy er som standard konfigureret med to forskellige porte; læse-skrive- og skrivebeskyttede porte.
I din læse-skrive-port har du din primære server som online og resten af dine noder som offline, og i den skrivebeskyttede port har du både primær og standby online.
Når HAProxy registrerer, at en af dine noder, enten Primær eller Standby, ikke er tilgængelig, markerer den den automatisk som offline. Det tager det ikke i betragtning for at sende trafik til det. Detektion udføres af sundhedstjekscripts, som ClusterControl konfigurerer på tidspunktet for implementeringen. Disse kontrollerer, om forekomsterne er oppe, om de er under gendannelse eller er skrivebeskyttede.
Når ClusterControl fremmer en Standby til Primary, markerer din HAProxy den gamle Primary som offline for begge porte og sætter den promoverede node online i læse-skriveporten.
Hvis din aktive HAProxy, som har tildelt den virtuelle IP-adresse, som dine systemer opretter forbindelse til, fejler, migrerer Keepalved denne IP-adresse til din passive HAProxy automatisk. Det betyder, at dine systemer så kan fortsætte med at fungere normalt.
På denne måde fortsætter dine systemer med at fungere som forventet og uden din manuelle indgriben.
Overvejelser
Hvis det lykkes dig at gendanne din gamle mislykkede Primære node, vil den IKKE automatisk blive genindført i klyngen som standard. Du skal gøre det manuelt. En grund til dette er, at hvis din replika blev forsinket på tidspunktet for fejlen, og ClusterControl føjer den gamle Primary til klyngen, ville det betyde tab af information eller datainkonsistens på tværs af noderne. Du vil måske også analysere problemet i detaljer. Hvis ClusterControl lige genindførte den mislykkede node i klyngen, ville du muligvis miste diagnostisk information.
Hvis failover mislykkes, gøres der heller ikke flere forsøg. Manuel indgriben er påkrævet for at analysere problemet og udføre de tilsvarende handlinger. Dette er for at undgå den situation, hvor ClusterControl, som den høje tilgængelighedsmanager, forsøger at fremme den næste Standby og den næste. Der kan være et problem, og du bliver nødt til at tjekke dette.
Sikkerhed
En vigtig ting, du ikke må glemme, før du går i produktion med dit høje tilgængelighedsmiljø, er at sikre dets sikkerhed.
Adskillige sikkerhedsaspekter, der skal overvejes, omfatter kryptering, rollestyring og adgangsbegrænsning ved hjælp af IP-adresse, som vi har dækket indgående i en tidligere blog.
I din PostgreSQL-database har du filen pg_hba.conf, som håndterer klientgodkendelsen. Du kan begrænse typen af forbindelse, kilde-IP-adresse eller netværk, hvilken database du kan oprette forbindelse til, og med hvilke brugere. Derfor er denne fil en vigtig brik for PostgreSQL-sikkerhed.
Du kan konfigurere din PostgreSQL-database fra postgresql.conf-filen, så den kun lytter på en specifik netværksgrænseflade og en anden port end standardporten (5432), og dermed undgår grundlæggende forbindelsesforsøg fra uønskede kilder .
Korrekt brugeradministration, enten ved hjælp af sikre adgangskoder eller begrænsning af adgang og privilegier, er en anden vigtig del af dine sikkerhedsindstillinger. Det anbefales, at du tildeler det mindst mulige antal privilegier til alle brugere og angiver, hvis det er muligt, kilden til forbindelsen.
Du kan også aktivere datakryptering, enten under transport eller i hvile, for at undgå adgang til oplysninger for uautoriserede personer.
En revisionslog er nyttig til at forstå, hvad der sker eller er sket i din database. PostgreSQL giver dig mulighed for at konfigurere flere parametre til logning eller endda bruge pgAudit-udvidelsen til denne opgave.
Sidst, men ikke mindst, anbefales det at holde din database og servere opdateret med de nyeste patches for at undgå sikkerhedsrisici. Til dette giver ClusterControl dig mulighed for at generere driftsrapporter for at verificere, om du har tilgængelige opdateringer og endda hjælpe dig med at opdatere dine databaseservere.
Konklusion
Implementeringer med høj tilgængelighed kan synes vanskelige at opnå, især når det kommer til at forstå de forskellige arkitekturer og nødvendige komponenter for at konfigurere dem korrekt.
Hvis du administrerer HA manuelt, så sørg for at tjekke Udfør replikeringstopologiændringer for PostgreSQL. Mange vil lede efter værktøjer som ClusterControl til at hjælpe med at administrere udrulning, belastningsbalancere, failover, sikkerhed og mere til et komplet miljø med høj tilgængelighed. Du kan downloade ClusterControl gratis i 30 dage for at se, hvordan det kan lette byrden ved at administrere en databaseinfrastruktur med høj tilgængelighed.
Uanset hvordan du vælger at administrere dine PostgreSQL-databaser med høj tilgængelighed, skal du sørge for at følge os på Twitter eller LinkedIn, eller abonnere på vores nyhedsbrev for at få de seneste opdateringer og bedste praksis til at administrere dine databaseopsætninger.