Når du implementerer en databaseklynge på forskellige servere, vil du have opnået replikeringsfordelen ved at forbedre datatilgængeligheden. Der er dog behov for at holde styr på processer og se, om de kører eller ej. Et af de programmer, der bruges i denne proces, er Heartbeat, som har evnen til at kontrollere og verificere tilstedeværelsen af ressourcer på et eller flere systemer i en given klynge. Udover PostgreSQL og filsystemerne, som PostgreSQL-data er lagret for, er DRBD en af de ressourcer, vi vil diskutere i denne artikel om, hvordan Heartbeat-programmet kan bruges.
HA hjerteslag
Som diskuteret tidligere i DRBD-bloggen opnås en høj tilgængelighed af data ved at køre forskellige forekomster af serveren, men betjene de samme data. Disse kørende serverforekomster kan defineres som en klynge i forhold til et Heartbeat. Dybest set er hver serverinstans fysisk i stand til at levere den samme service som de andre inden for den klynge. Dog kan kun én instans aktivt yde service ad gangen med det formål at sikre høj tilgængelighed af data. Vi kan derfor definere de andre instanser som 'hot-spares', som kan tages i brug i tilfælde af fejl på masteren. Heartbeat-pakken kan downloades fra dette link. Når du har installeret denne pakke, kan du konfigurere den til at fungere med dit system med nedenstående procedure. En simpel struktur af Heartbeat-konfigurationen er:
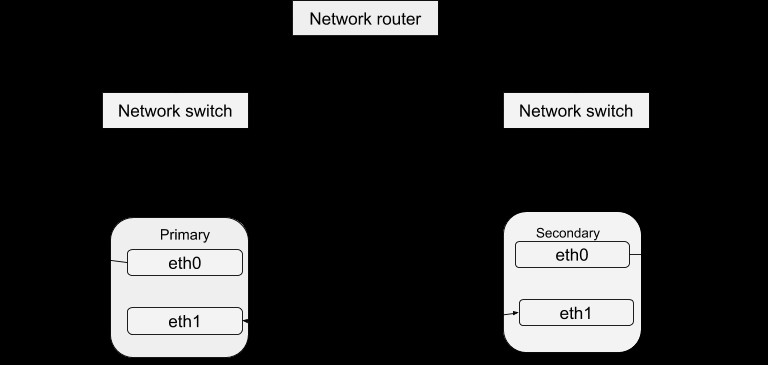
Konfiguration af hjerteslag
Hvis du kigger ind i denne mappe /etc/ha.d, vil du finde nogle filer, som bruges i konfigurationsprocessen. Ha.cf-filen danner den primære hjerteslagskonfiguration. Den inkluderer listen over alle noder og tidspunkter for identifikation af fejl udover at styre hjerteslaget på, hvilken type mediestier der skal bruges, og hvordan de konfigureres. Sikkerhedsoplysninger for klyngen registreres i authkeys-filen. Registrerede oplysninger i disse filer bør være identiske for alle værter i klyngen, og dette kan nemt opnås ved at synkronisere på tværs af alle værterne. Det vil sige, at enhver ændring af information i én vært skal kopieres til alle de andre.
Ha.cf-fil
Den grundlæggende disposition af ha.cf-filen er
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacilitet:denne bruges til at dirigere Heartbeat på, hvilken syslog-logfunktion den skal bruge til at optage beskeder. De mest brugte værdier er auth, authpriv, user, local0, syslog og daemon. Du kan også beslutte ikke at have nogen logs, så du kan indstille værdien til ingen .i.e
logfacility none - Keepalive:dette er tiden mellem hjerteslag, dvs. den frekvens, hvormed hjerteslagssignalet sendes til de andre værter. I eksempelkoden ovenfor er den sat til 3 sekunder.
- Dødtid:det er forsinkelsen i sekunder, hvorefter en node erklæres at have fejlet.
- Warntime:er forsinkelsen i sekunder, hvorefter en advarsel registreres i en log, der indikerer, at en node ikke længere kan kontaktes.
- Initdead:dette er tiden i sekunder, der skal ventes under systemstart, før den anden vært anses for at være nede.
- Mcast:det er en defineret metode til at sende et hjerteslagssignal. For eksempelkoden ovenfor bruges multicast-netværksadressen over en afgrænset netværksenhed. For en multipel klynge skal multicast-adressen være unik for hver klynge. Du kan også vælge en seriel forbindelse frem for multicast, eller hvis du opsætter på en sådan måde, at der er flere netværksgrænseflader, skal du bruge begge til hjerteslagforbindelsen som i eksemplet. Fordelen ved at bruge begge er at overvinde chancerne for forbigående fejl, som følgelig kan forårsage en ugyldig fejlhændelse.
- Auto_failback:dette genforbinder en server, der havde fejlet, tilbage til klyngen, hvis den bliver tilgængelig. Det kan dog skabe forvirring, hvis serveren er tændt og derefter kommer online på et andet tidspunkt. I forhold til DRBD, hvis det ikke er godt konfigureret, kan du ende med mere end ét datasæt på den samme server. Derfor er det tilrådeligt altid at slå det fra.
- Node:skitserer knudepunktet i Heartbeat-klyngegruppen. Du bør mindst have 1 node for hver.
Yderligere konfigurationer
Du kan også indstille yderligere konfigurationsoplysninger som:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:dette er vigtigt for at sikre, at du har forbindelse på den offentlige grænseflade til serverne og forbindelse til en anden vært. Det er vigtigt at overveje IP-adressen i stedet for værtsnavnet for destinationsmaskinen.
- Respawn:dette er kommandoen, der skal køres, når der opstår en fejl.
- Apiauth:er autoriteten for fejlen. Du skal konfigurere bruger- og gruppe-id, som kommandoen skal udføres med. Authkeys-filen indeholder autorisationsoplysningerne for Heartbeat-klyngen, og denne nøgle er meget unik til at verificere maskiner inden for en given Heartbeat-klynge.
- Deadping:definerer timeout, før et manglende svar udløser en fejl.
Integration af hjerteslag med Postgres og DRBD
Som nævnt før, når en masterserver fejler, vil en anden server med en given klynge springe i gang for at levere den samme service. Heartbeat hjælper med konfigurationen af ressourcer, der forbedrer valget af en server i tilfælde af fejl. Det definerer for eksempel, hvilke individuelle servere der skal bringes op eller kasseres i tilfælde af fejl. Ved at tjekke ind på haresources-filen i mappen /etc/ha.d får vi en oversigt over de ressourcer, der kan administreres. Ressourcefilstien er /etc/ha.d/resource.d og ressourcedefinitionen er på én linje, der er:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(bemærk mellemrummene).
- Drbd1:refererer til navnet på den foretrukne vært for at være mere sekant den server, der normalt bruges som standardmaster til at håndtere tjenesten. Som nævnt i DRBD-bloggen har vi brug for ressourcer til vores server, og disse er defineret i linjen som drbddisk, filsystem og postgres. Det sidste felt er en virtuel IP-adresse, der skal bruges til at dele tjenesten, dvs. oprette forbindelse til Postgres-serveren. Som standard vil det blive allokeret til den server, der er aktiv, når Heartbeat starter. Når der opstår en fejl, vil disse ressourcer blive startet på backup-serveren i rækkefølge, når det korresponderende script kaldes. I indstillingen vil scriptet skifte DRBD-disken på den sekundære vært til primær tilstand, hvilket får enheden til at læse/skrive.
- Filsystem:dette vil administrere filsystemressourcerne, og i dette tilfælde er DRBD'en blevet valgt, så den vil blive monteret under opkaldet af ressourcescriptet.
- Postgres:dette vil enten starte eller administrere Postgres-serveren
Nogle gange vil du gerne modtage meddelelser via e-mail. For at gøre det skal du tilføje denne linje til ressourcefilen med din e-mail for at modtage advarselsteksterne:
MailTo:: example@sqldat.com::DRBDFailureFor at starte hjerteslaget kan du køre kommandoen
/etc/ha.d/heartbeat starteller genstart både den primære og sekundære server. Hvis du nu kører kommandoen
$ /usr/lib64/heartbeat/hb_standbyDen aktuelle node vil blive udløst til at afgive sine ressourcer rent til den anden node.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperHåndtering af systemniveaufejl
Nogle gange kan serverkernen være beskadiget, hvilket indikerer et potentielt problem med din server. Du bliver nødt til at konfigurere serveren til at fjerne sig selv fra klyngen i tilfælde af et problem. Dette problem omtales ofte som kernepanik, og det udløser derfor en hård genstart på din maskine. Du kan gennemtvinge en genstart ved at indstille kernel.panic og kernel.panic_on_oop for kernekontrolfilen /etc/sysctl.conf. Dvs.
kernel.panic_on_oops = 1
kernel.panic = 1En anden mulighed er at gøre det fra kommandolinjen ved hjælp af sysctl-kommandoen, dvs.:
$ sysctl -w kernel.panic=1Du kan også redigere filen sysctl.conf og genindlæse konfigurationsoplysningerne ved hjælp af denne kommando.
sysctl -pVærdien angiver det antal sekunder, der skal ventes før genstart. Den anden hjerteslagsknude bør derefter registrere, at serveren er nede og derefter skifte over failover-værten.
Konklusion
Heartbeat er et undersystem, som tillader valg af en sekundær server til primær og et backup-system, når en aktiv server fejler. Det bestemmer også, om alle de andre servere er i live. Det sikrer også overførsel af ressourcer til den nye primære node