Denne blog er anden del af Implementering af en multi-datacenter-opsætning til PostgreSQL. I dette slag vil vi vise, hvordan man implementerer PostgreSQL i denne type miljø, og hvordan man failover i tilfælde af masterfejl ved hjælp af ClusterControls automatiske gendannelsesfunktion.
På dette tidspunkt antager vi, at du har forbindelse mellem datacentrene (som vi så i den første del af denne blog), og at du har de nødvendige servere til denne opgave (som vi også nævnte i forrige del).
Implementer en PostgreSQL-klynge
Vi bruger ClusterControl til denne opgave, så vi antager, at du har den installeret (den kunne være installeret på den samme Load Balancer-server, men hvis du kan bruge en anden endnu bedre).
Gå til din ClusterControl-server, og vælg indstillingen 'Deploy'. Hvis du allerede har en PostgreSQL-instans kørende, skal du i stedet vælge 'Importér eksisterende server/database'.
Når du vælger PostgreSQL, skal du angive bruger, nøgle eller adgangskode og port til opret forbindelse med SSH til vores PostgreSQL-værter. Du skal også bruge navnet på din nye klynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
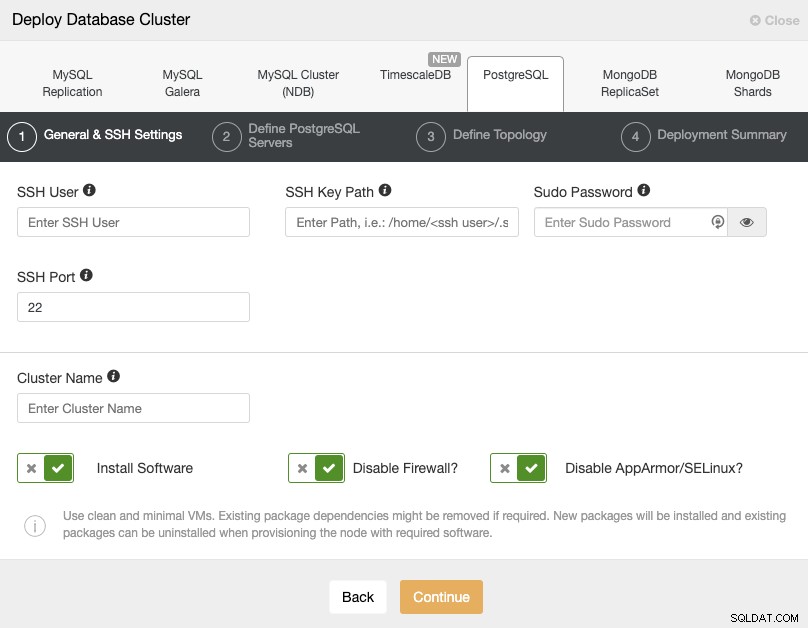
Se venligst ClusterControl-brugerkravene for denne opgave her, men hvis du fulgte den forrige blog, skal du bruge 'fjernbrugeren' her og den korrekte SSH-port (som vi nævnte, anbefales det at bruge en anden, hvis du bruger den offentlige IP-adresse til at få adgang til den i stedet for en VPN).
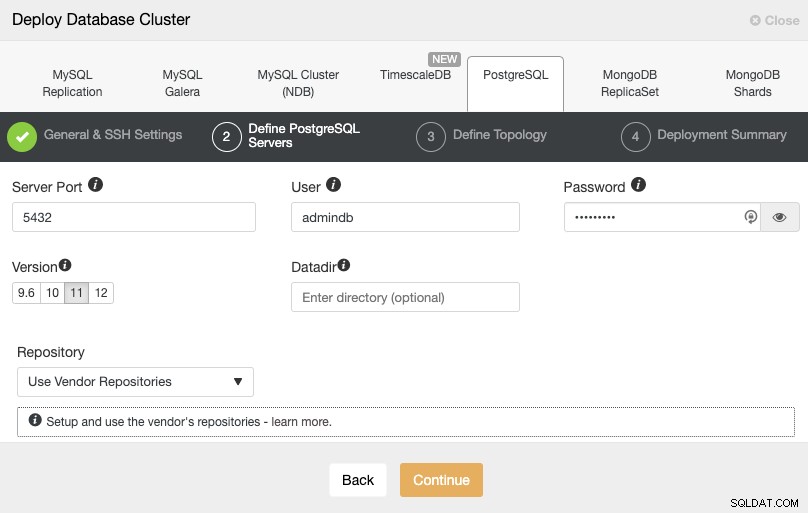
Efter opsætning af SSH-adgangsoplysningerne skal du definere databasebrugeren, version og datadir (valgfrit). Du kan også angive, hvilket lager der skal bruges. I det næste trin skal du tilføje dine servere til den klynge, du vil oprette.
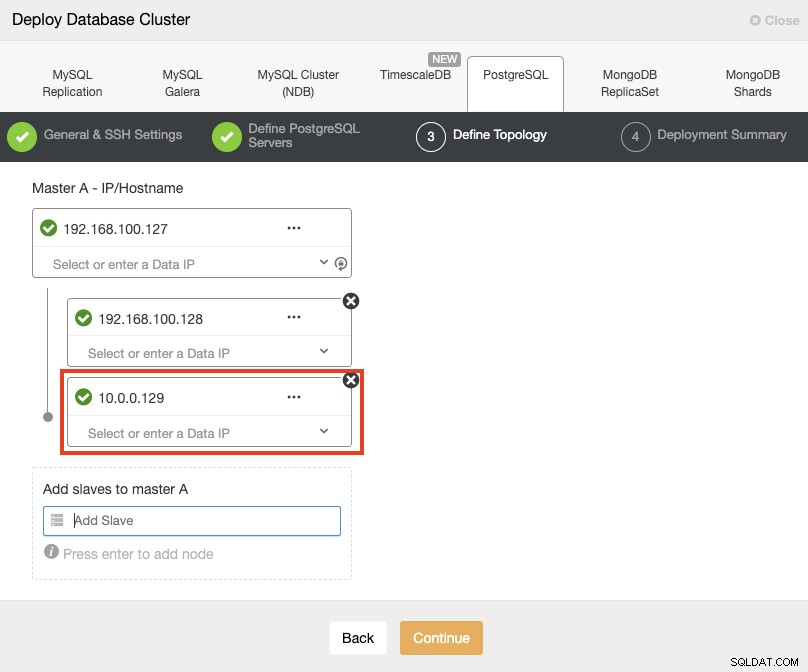
Når du tilføjer dine servere, kan du indtaste IP eller værtsnavn. I denne del vil du bruge de offentlige IP-adresser på dine servere, og som du kan se i det røde felt, bruger jeg et andet netværk til den anden standby-knude. ClusterControl har ingen begrænsninger for det netværk, der skal bruges. Det eneste krav om dette er at have SSH-adgang til noden.
Så efter vores tidligere eksempel skulle disse IP-adresser være:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)I det sidste trin kan du vælge, om din replikering skal være Synkron eller Asynkron.
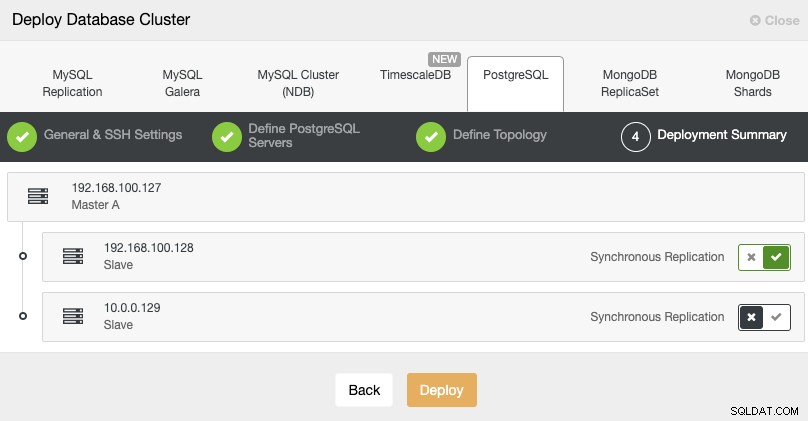
I dette tilfælde er det vigtigt at bruge asynkron replikering til din eksterne node , hvis ikke, kan din klynge blive påvirket af ventetiden eller netværksproblemer.
Du kan overvåge status for oprettelsen af din nye klynge fra ClusterControl-aktivitetsmonitoren.
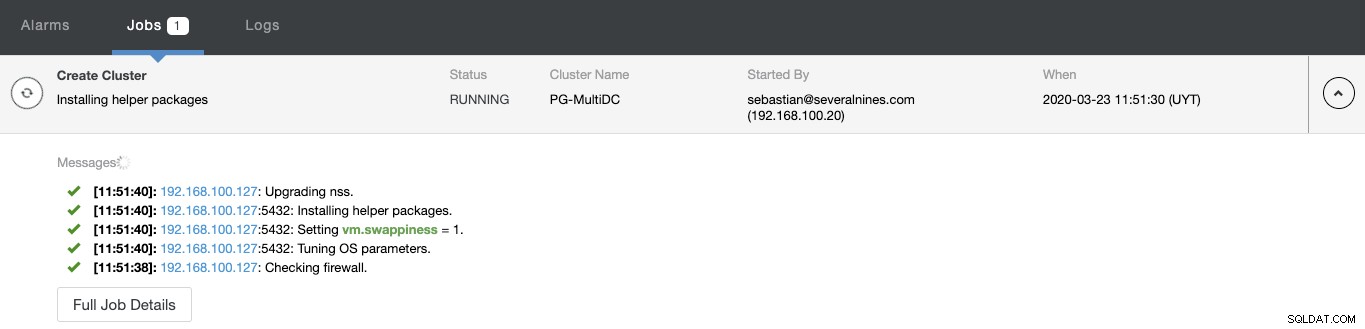
Når opgaven er færdig, kan du se din nye PostgreSQL-klynge i hovedskærmen ClusterControl.

Tilføjelse af en PostgreSQL Load Balancer (HAProxy)
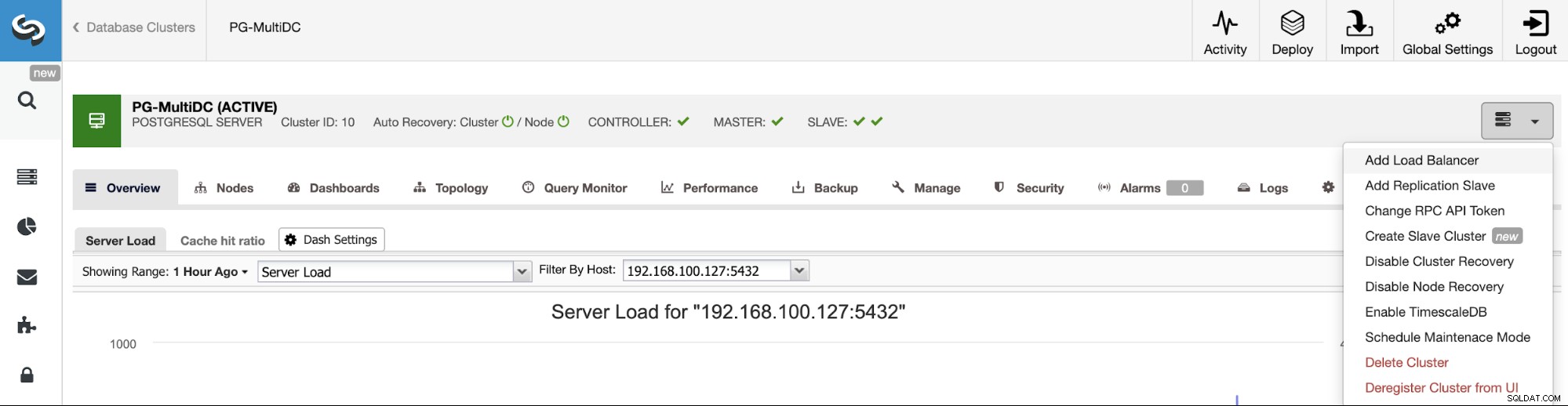
Når du har oprettet din klynge, kan du udføre flere opgaver på den, såsom at tilføje en belastningsbalancer (HAProxy) eller en ny replika.
For at følge vores tidligere eksempel, lad os tilføje en belastningsbalancer, der, som vi nævnte, vil hjælpe dig med at administrere dit HA-miljø. For dette skal du gå til ClusterControl -> Vælg PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer.
Her skal du tilføje de oplysninger, som ClusterControl vil bruge til at installere og konfigurere din HAProxy belastningsbalancer. Denne Load Balancer kan installeres på den samme ClusterControl-server, men hvis du kan bruge en anden, er det endnu bedre.
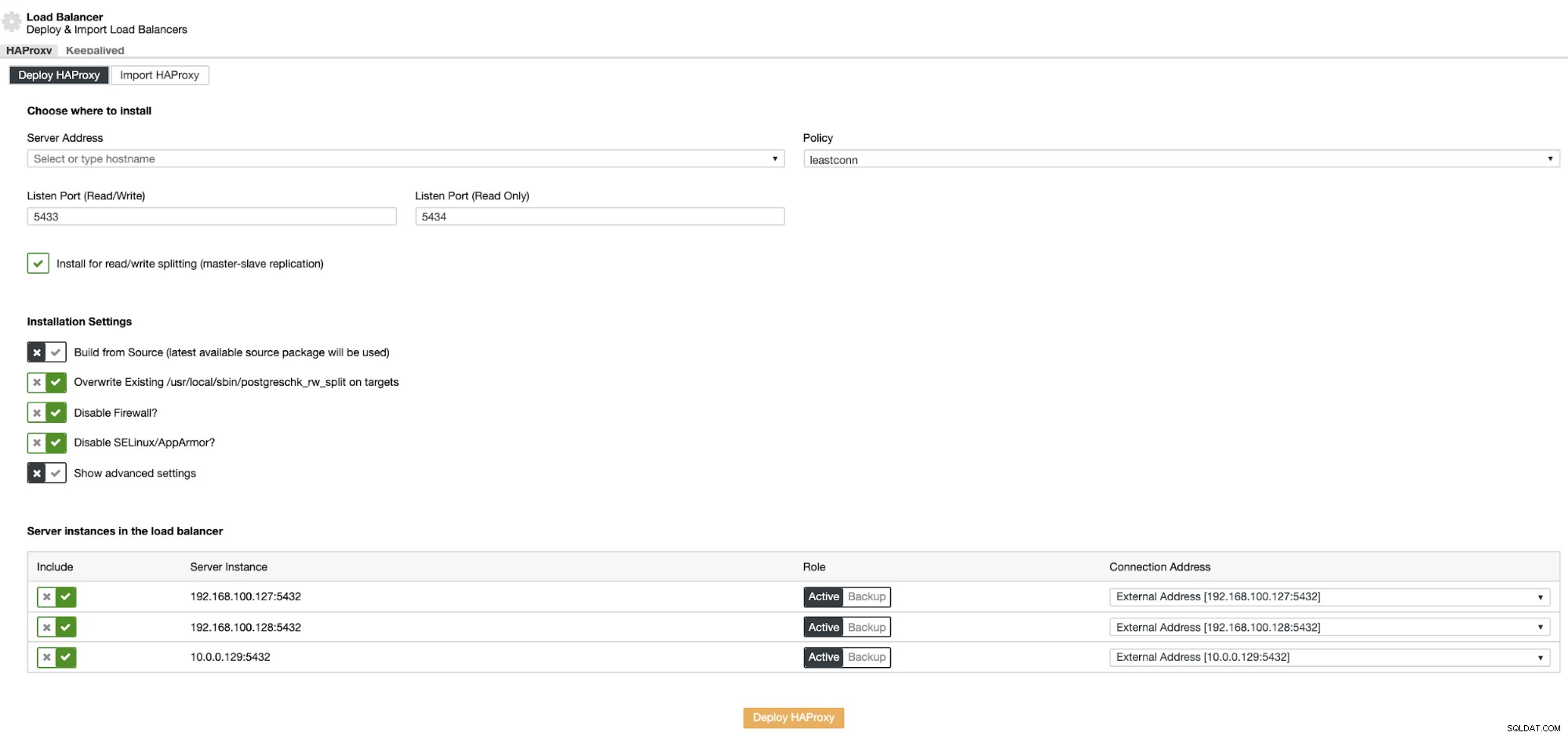
De oplysninger, du skal introducere, er:
Handling:Implementer eller importer.
Serveradresse:IP-adresse til din HAProxy-server (det kan være den samme ClusterControl IP-adresse).
Lytteport (læse/skrive):Port til læse-/skrivetilstand.
Listenport (skrivebeskyttet):Port til skrivebeskyttet tilstand.
Politik:Det kan være:
- leastconn:Serveren med det laveste antal forbindelser modtager forbindelsen.
- roundrobin:Hver server bruges på skift, i henhold til deres vægt.
- kilde:Kilde-IP-adressen hashes og divideres med den samlede vægt af de kørende servere for at angive, hvilken server der skal modtage anmodningen.
Installer til læse-/skriveopdeling:Til master-slave-replikering.
Byg fra kilde:Du kan vælge Installer fra en pakkeadministrator eller byg fra kilde.
Og du skal vælge, hvilke servere du vil tilføje til HAProxy-konfigurationen.
Du kan også konfigurere avancerede indstillinger som Admin User, Backend Name, Timeouts og mere.
Når du er færdig med konfigurationen og bekræfter implementeringen, kan du følge fremskridtene i aktivitetssektionen på ClusterControl UI.
Og når dette er færdigt, kan du gå til ClusterControl -> Noder -> HAProxy node, og kontroller den aktuelle status.
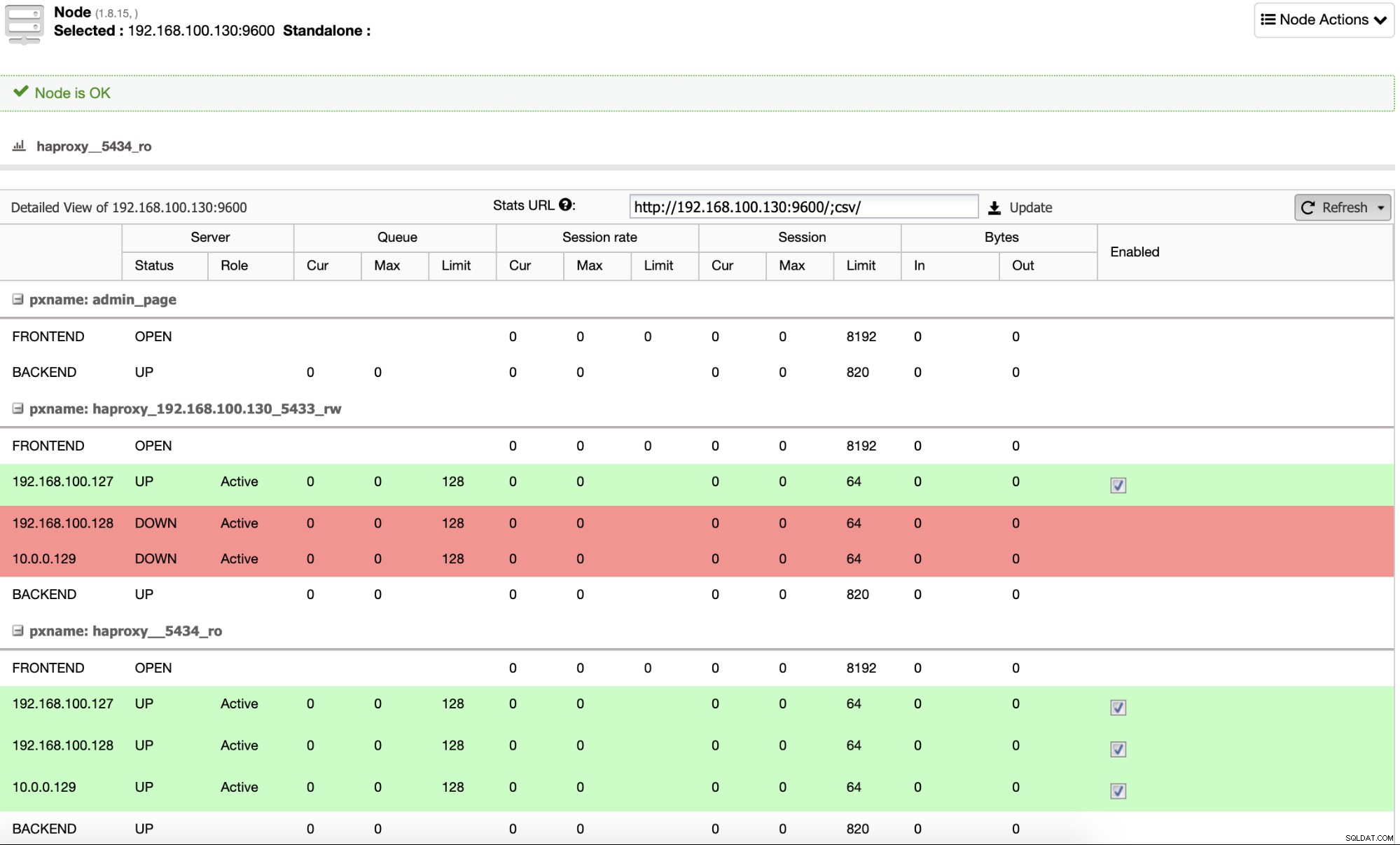
Som standard konfigurerer ClusterControl HAProxy med to forskellige porte, en til læse- Write, der vil blive brugt til applikationen eller brugeren til at skrive (og læse) data, og en anden til Read-Only, som vil blive brugt til at balancere læsetrafikken mellem alle noderne. I Read-Write-porten er kun masternoden aktiveret, og i tilfælde af masterfejl vil ClusterControl fremme den mest avancerede slave til master og omkonfigurere denne port for at deaktivere den gamle master og aktivere den nye. På denne måde kan din applikation stadig fungere i tilfælde af en masterdatabasefejl, da trafikken omdirigeres af Load Balancer til den korrekte node.
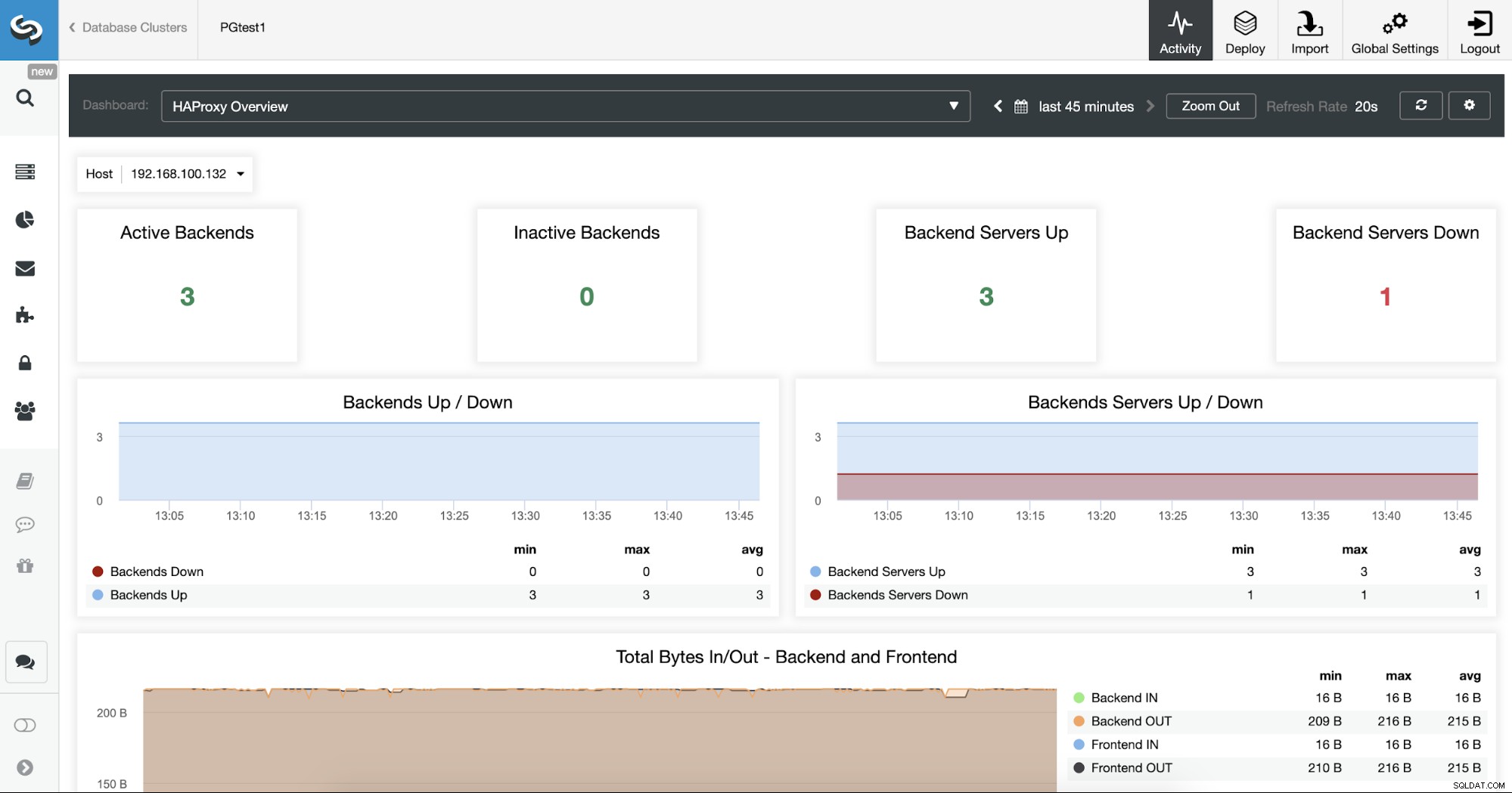
Du kan også overvåge dine HAProxy-servere ved at tjekke Dashboard-sektionen.
Nu kan du forbedre dit HA-design ved at tilføje en ny HAProxy-node i fjerndatacenter og konfigurere Keepalved-tjenesten mellem dem. Keepalved giver dig mulighed for at bruge en virtuel IP-adresse, der er tildelt den aktive Load Balancer-knude. Hvis denne node fejler, vil denne virtuelle IP blive migreret til den sekundære HAProxy-node, så at have denne IP konfigureret i din applikation vil give dig mulighed for at holde alt i gang i tilfælde af et Load Balancer-problem.
Al denne konfiguration kan udføres ved hjælp af ClusterControl.
Konklusion
Ved at følge denne todelte blog kan du implementere en multi-datacenter-opsætning til PostgreSQL med høj tilgængelighed og SSH-forbindelse mellem datacentret for at undgå kompleksiteten af en VPN-konfiguration.
Ved at bruge asynkron replikering til den eksterne node undgår du ethvert problem relateret til latens og netværksydelse, og ved at bruge ClusterControl vil du have automatisk (eller manuel) failover i tilfælde af fejl (blandt andre flere funktioner). Dette kunne være den nemmeste måde at nå denne topologi på, og vi håber, at dette vil være nyttigt for dig.