Hvad er unikke nøglebegrænsninger?
En unik begrænsning er en regel, der begrænser kolonneindtastninger til unikke. Med andre ord forhindrer denne type begrænsninger at indsætte dubletter i en kolonne. En unik begrænsning er et af instrumenterne til at håndhæve dataintegritet i en SQL Server-database. Da en tabel kun kan have én primær nøgle, kan du bruge en unik begrænsning til at gennemtvinge en kolonnes unikke karakter eller en kombination af kolonner, der ikke udgør en primær nøgle.
Oprettelse af en unik begrænsning på en kolonne opretter automatisk et unikt indeks. På denne måde implementerer SQL Server integritetskravet til den unikke begrænsning. Derfor, når du forsøger at indsætte en dubletværdi i en kolonne, hvorpå der er defineret en unik begrænsning, vil databasemotoren registrere den unikke begrænsningsovertrædelse og udstede en tilsvarende fejl. Som følge heraf vil rækken med de duplikerede værdier ikke blive tilføjet til en tabel.
Oprettelse af en unik begrænsning
Følgende eksempelforespørgsel opretter Studenter tabel og en unik begrænsning på Login kolonne, så der ikke er elever med samme login.
CREATE TABLE Students ( Login CHAR NOT NULL ,CONSTRAINT AK_Student_Login UNIQUE (Login) ); GO
Hvis Studerende tabel allerede eksisterer, så kan du bruge følgende eksempelforespørgsel til at oprette den unikke begrænsning.
ALTER TABLE Students ADD CONSTRAINT AK_Student_Login UNIQUE (Login); GO
Bemærk, at når du tilføjer en unik begrænsning til en eksisterende tabel, verificerer databasemotoren, om kolonnen, som begrænsningen er tilføjet, indeholder duplikerede værdier. Hvis der er sådanne værdier, vil begrænsningen ikke blive tilføjet og returnere en fejl.
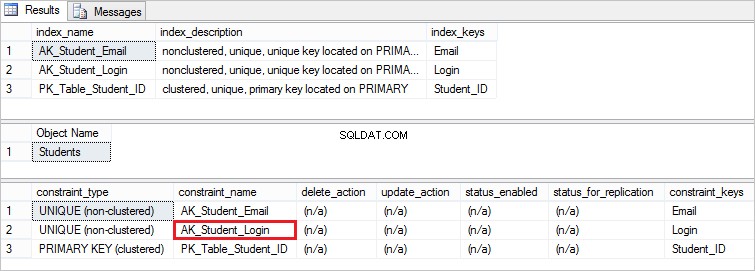
For nu at bekræfte, at den unikke begrænsning faktisk er blevet tilføjet, skal du udføre følgende sætninger:
EXEC sp_helpindex Students EXEC sp_helpconstraint Students
Her er den begrænsning, vi har oprettet:
Oprettelse af en unik begrænsning i SQL Server Management Studio
Lad os sige, at vi skal definere en unik begrænsning på Login kolonne den Studenter tabel.
1. I Object Explorer , højreklik på Studenter tabel og klik på Design .
2. Højreklik på Tabeldesigneren og vælg Indekser/nøgler...
3. I Indekser/nøgler vindue, skal du klikke på Tilføj .
4. Under Generelt skal du klikke på Kolonner og klik derefter på ellipseknappen. I Indekskolonner vindue, skal du vælge den eller de kolonner, som du vil inkludere i den unikke begrænsning.
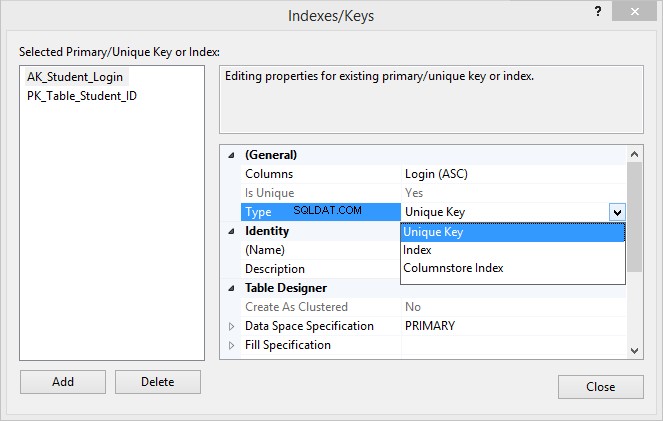
5. Under Generelt skal du klikke på Skriv og vælg Unik nøgle fra rullelisten.
6. Under Identitet sektion, angiv navnet på begrænsningen (i vores tilfælde AK_Student_Login ), og klik på Luk for at gemme den nyoprettede begrænsning.
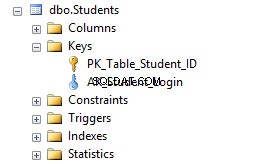
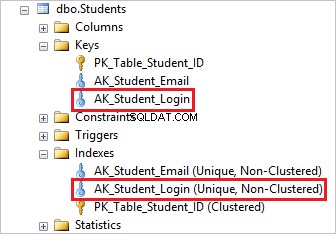
Nu, hvis du går til Studenter tabel i Object Explorer og klik på Indekser mappe, vil du se, at tabellen indeholder en primær nøgle og en unik begrænsning AK_Student_Login .
Hvordan er unikke begrænsninger forskellige fra primære nøgler?
I lighed med en unik begrænsning bruges en primær nøgle også til at håndhæve dataintegritet i en tabel. Men det primære formål med en primær nøgle er entydigt at identificere hver post i en tabel og implementere korrekte relationer mellem tabeller i en database. En primær nøgle er påkrævet i 99 % af tabellerne for at tillade korrekt adgang til tabelrækker. Der kan kun være én primær nøgle pr. tabel defineret på én eller flere kolonner.
Unikke begrænsninger bruges specifikt til at forhindre duplikerede værdier i at blive indsat i en kolonne. Der kan være flere kolonner med unikke begrænsninger, eller der er muligvis ingen unikke begrænsninger defineret på en tabel overhovedet. De er ikke obligatoriske for en tabel i modsætning til primærnøgler.
Lad os sige, at vi har Eleverne tabel med personlige oplysninger om hver enkelt studerende på et universitet. Tabellen inkluderer StudentID kolonne, som er en primær nøgle og gemmer et unikt ID for hver specifik elev. Denne primære nøglekolonne bruges til entydigt at identificere hver studerende på et universitet.
Samtidig er Studerende tabel har sådanne kolonner som E-mail , cpr-nummer og Login og hver af disse kolonner skal gemme unikke værdier. Da der allerede er én primær nøgle i tabellen, vil vi bruge unikke begrænsninger i stedet for at pålægge disse kolonner entydighed. En tabel kan således have mange unikke begrænsninger og kun én primær nøgle.
En anden ting, der adskiller en unik begrænsning fra en primær nøgle, er, at den primære nøgle ikke tillader nogen NULL værdier i en kolonne, hvorimod en kolonne med en unik begrænsning kan indeholde en NULL værdi, men kun én, da SQL Server fortolker to NULL-værdier som de samme værdier.
Antag, at der oprettes en unik begrænsning på E-mail kolonne i Studenter bord. Lad os prøve at indsætte to rækker begge med NULL s i E-mail felter:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (1, 'John White', 19, NULL, 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (2, 'James Marvin', 21, NULL, 987-65-4321, 'Marvin_J17') GO
Vi får følgende fejlmeddelelse:

Nå, dette er en forudsigelig adfærd, fordi duplikerede værdier, selvom de er NULL'er, ikke er tilladt af den unikke begrænsning.
Unik begrænsning vs Unikt indeks
Selvom både den unikke begrænsning og det unikke indeks er to helt forskellige urelaterede databaseenheder, har de det samme mål og den samme indflydelse på SQL Server-ydeevnen. De sikrer begge dataentydighed i en kolonne.
I modsætning til det unikke indeks kan du dog ikke angive IGNORE_DUP_KEY, DROP_EXISTING, PAD_INDEX og STATISTICS_NORECOMPUTE mulighederne for den unikke begrænsning i ALTER TABLE-sætningerne.
Når du opretter en unik begrænsning på en kolonne, opretter SQL Server automatisk et unikt indeks på kolonnen, det er bare sådan, denne funktion er implementeret i SQL Server.
For at slette det unikke indeks skal du først slippe den tilsvarende unikke begrænsning, og dette vil automatisk slette det underliggende unikke indeks.
Følgende erklæring vil slette AK_Student_Login begrænsning:
ALTER TABLE Students DROP CONSTRAINT AK_Student_Login; GO
Du kan se, at du slipper AK_Student_Login unik begrænsning sletter dets tilsvarende indeks.
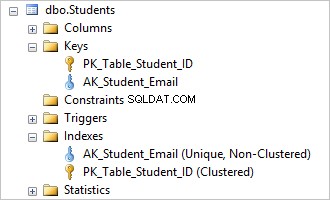
Det var nemt, nu kan du indsætte identiske værdier i Login kolonne.
Deaktivering af unik begrænsning
Der er en mulighed, der deaktiverer en unik begrænsning. Følgende forespørgsel skal deaktivere alle tabelbegrænsningerne:
ALTER TABLE Students NOCHECK CONSTRAINT ALL GO
Efter at have udført forespørgslen, lad os nu prøve at indsætte en duplikerende post:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, NULL, 123-45-6789, 'John555') GO
Det, vi får, er den unikke meddelelse om overtrædelse af begrænsninger:

Det ser således ud til, at ALTER TABLE