Replikation spiller en afgørende rolle for at opretholde høj tilgængelighed. Servere kan fejle, operativsystemet eller databasesoftwaren skal muligvis opgraderes. Dette betyder omrokering af serverroller og flytning af replikeringslinks, samtidig med at datakonsistensen bevares på tværs af alle databaser. Topologiændringer vil være nødvendige, og der er forskellige måder at udføre dem på.
Promovering af en standby-server
Det er uden tvivl den mest almindelige operation, du bliver nødt til at udføre. Der er flere årsager - for eksempel databasevedligeholdelse på den primære server, der ville påvirke arbejdsbyrden på en uacceptabel måde. Der kan være planlagt nedetid på grund af nogle hardwareoperationer. Nedbrud af den primære server, som gør den utilgængelig for applikationen. Disse er alle grunde til at udføre en failover, uanset om det er planlagt eller ej. I alle tilfælde bliver du nødt til at forfremme en af standby-serverne til at blive en ny primær server.
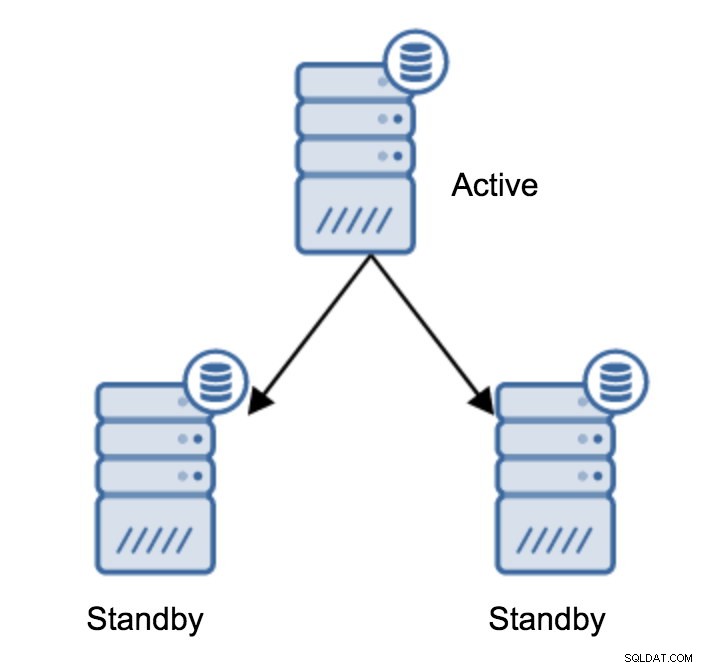
For at fremme en standby-server skal du køre:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
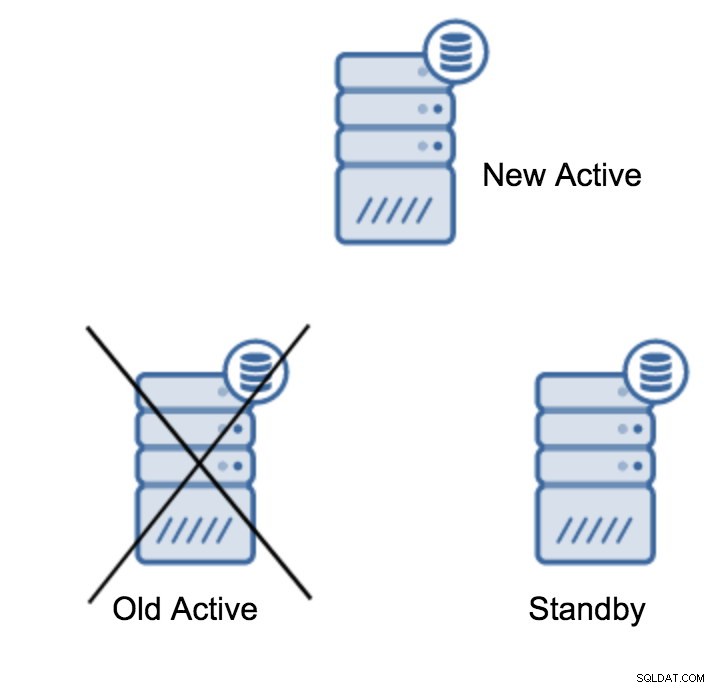
server promotedDet er nemt at køre denne kommando, men sørg først for at undgå tab af data. Hvis vi taler om et "primær server nede" scenarie, har du muligvis ikke for mange muligheder. Hvis det er en planlagt vedligeholdelse, så er det muligt at forberede sig på det. Du skal stoppe trafikken på den primære server og derefter kontrollere, at standbyserveren har modtaget og anvendt alle data. Dette kan gøres på standby-serveren ved at bruge forespørgslen som nedenfor:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Når alt er i orden, kan du stoppe den gamle primære server og fremme standby-serveren.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperReslaving af en standby-server fra en ny primær server
Du kan have mere end én standby-server, der slaver fra din primære server. Standby-servere er trods alt nyttige til at aflaste skrivebeskyttet trafik. Efter at have promoveret en standby-server til en ny primær server, skal du gøre noget ved de resterende standby-servere, som stadig er forbundet (eller som forsøger at oprette forbindelse) til den gamle primære server. Desværre kan du ikke bare ændre recovery.conf og forbinde dem til den nye primære server. For at forbinde dem skal du først genopbygge dem. Der er to metoder, du kan prøve her:standard basis backup eller pg_rewind.
Vi kommer ikke nærmere ind på, hvordan man tager en basissikkerhedskopiering - vi dækkede det i vores tidligere blogindlæg, som fokuserede på at tage sikkerhedskopier og gendanne dem på PostgreSQL. Hvis du tilfældigvis bruger ClusterControl, kan du også bruge det til at oprette en basis backup:
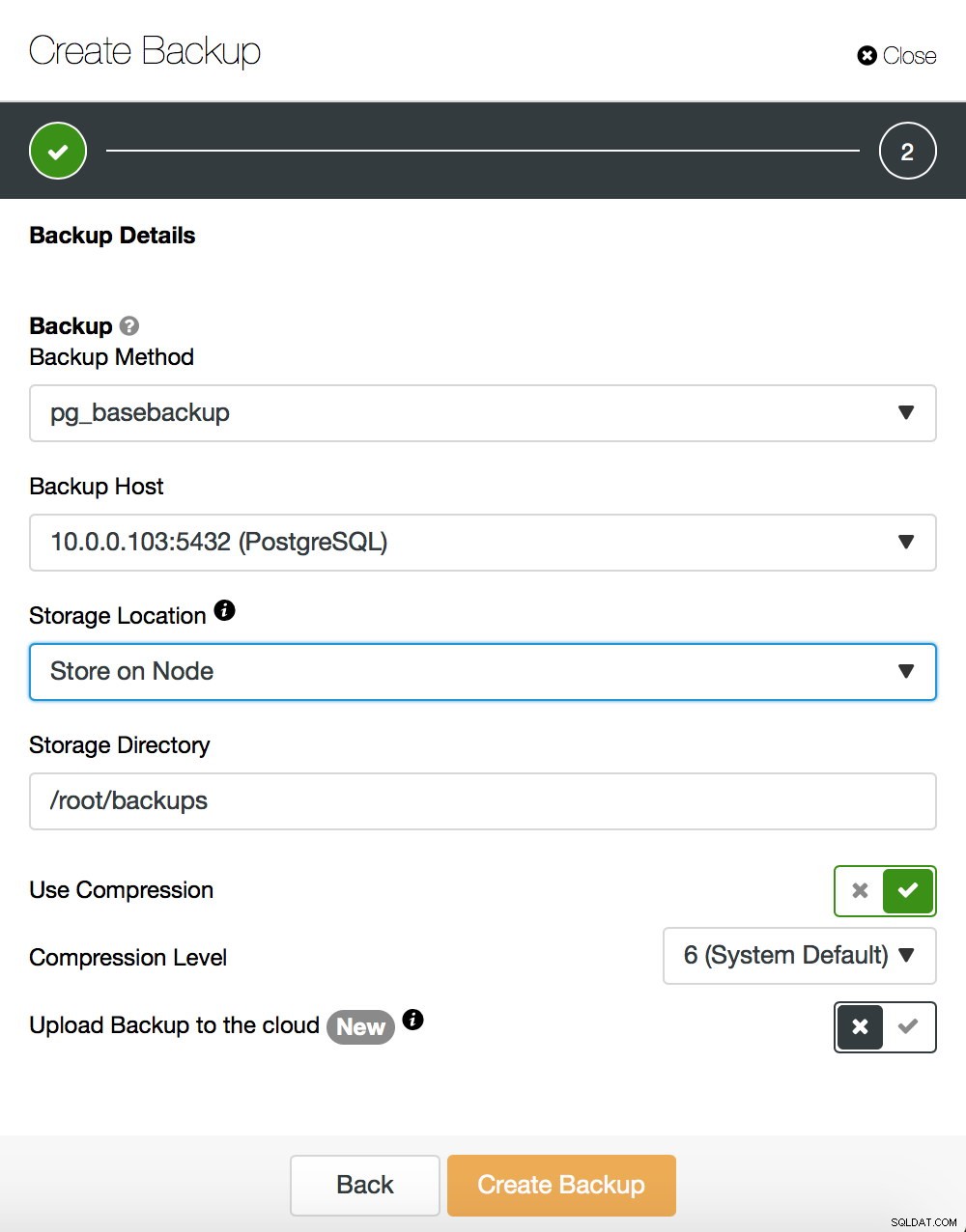
På den anden side, lad os sige et par ord om pg_rewind. Den største forskel mellem begge metoder er, at basis backup opretter en fuld kopi af datasættet. Hvis vi taler om små datasæt, kan det være ok, men for datasæt med hundredvis af gigabyte i størrelse (eller endnu større), kan det hurtigt blive et problem. I sidste ende vil du have dine standby-servere hurtigt op at køre - for at aflaste din aktive server og have endnu en standby at failover til, hvis behovet skulle opstå. Pg_rewind virker anderledes - den kopierer kun de blokke, der er blevet ændret. I stedet for at kopiere alt kopierer den kun ændringer, hvilket fremskynder processen ganske betydeligt. Lad os antage, at din nye master har en IP på 10.0.0.103. Sådan kan du udføre pg_rewind. Bemærk venligst, at du skal have stoppet målserveren - PostgreSQL kan ikke køre der.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
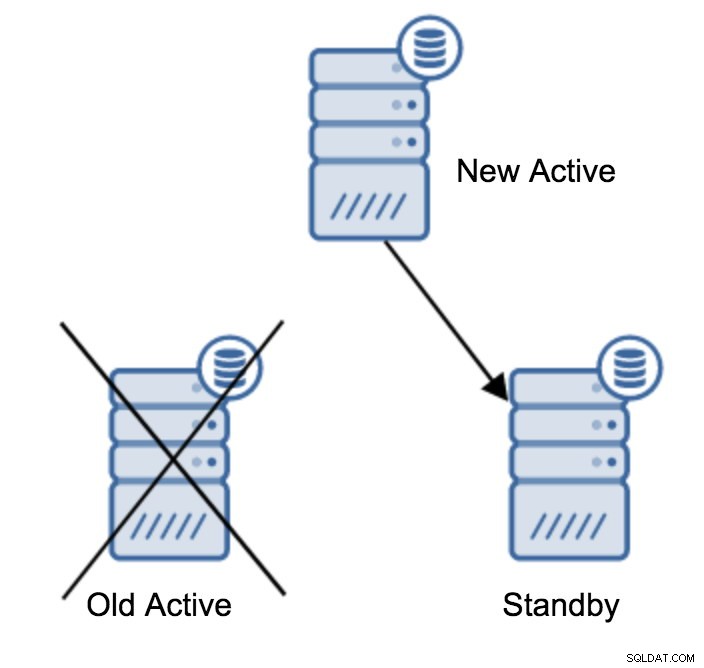
Done!Dette vil gøre et tørløb , tester processen, men laver ingen ændringer. Hvis alt er i orden, er det eneste, du skal gøre, at køre det igen, denne gang uden parameteren '--dry-run'. Når det er gjort, vil det sidste resterende trin være at oprette en recovery.conf-fil, som peger på den nye master. Det kan se sådan ud:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Nu er du klar til at starte din standby-server, og den vil replikere fra den nye aktive server.
Kædet replikering
Der er adskillige grunde til, at du måske ønsker at bygge en kædet replikering, selvom det typisk gøres for at reducere belastningen på den primære server. Servering af WAL til standby-servere tilføjer nogle overhead. Det er ikke meget af et problem, hvis du har en standby eller to, men hvis vi taler om et stort antal standby-servere, kan dette blive et problem. For eksempel kan vi minimere antallet af standby-servere, der replikerer direkte fra den aktive ved at oprette en topologi som nedenfor:
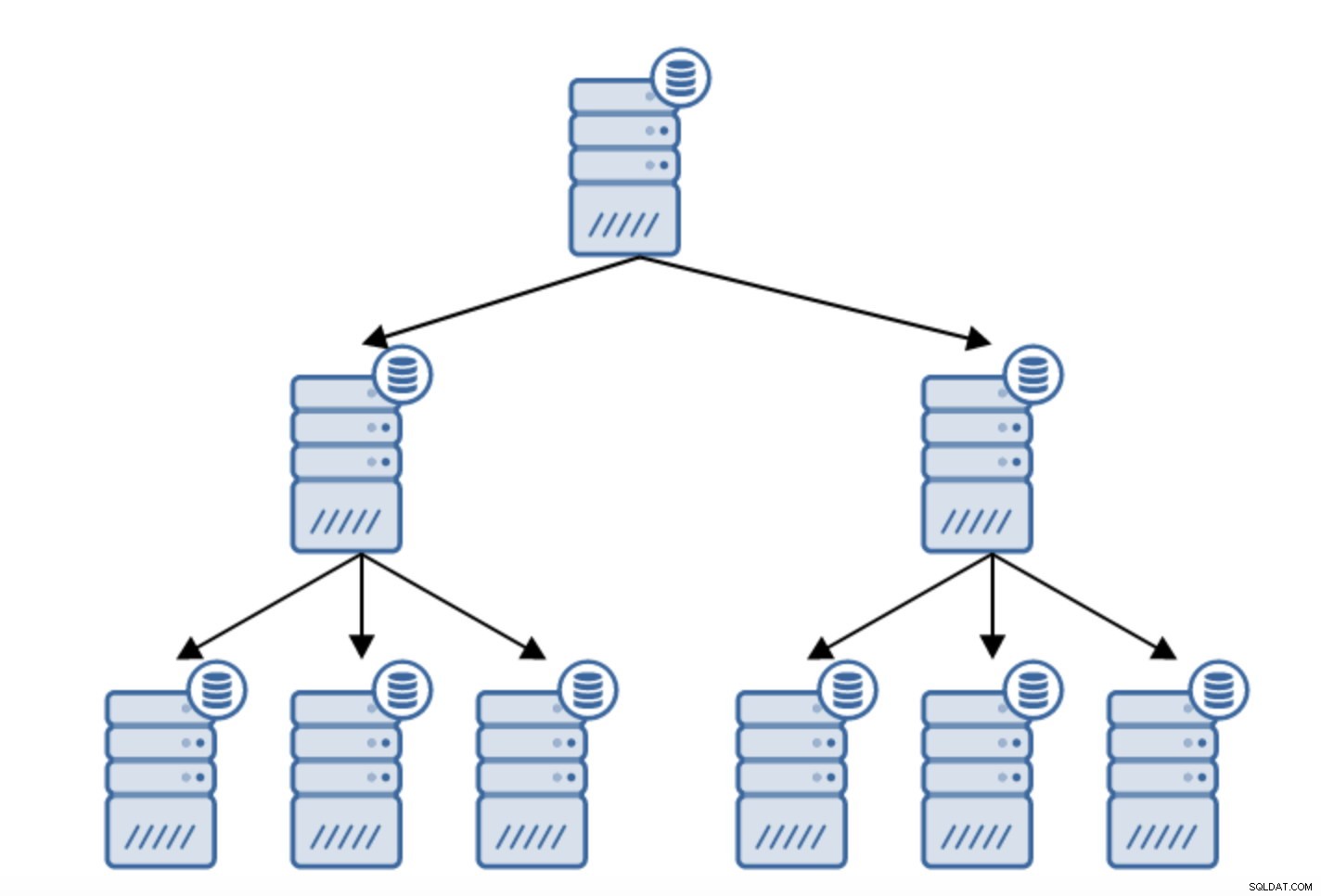
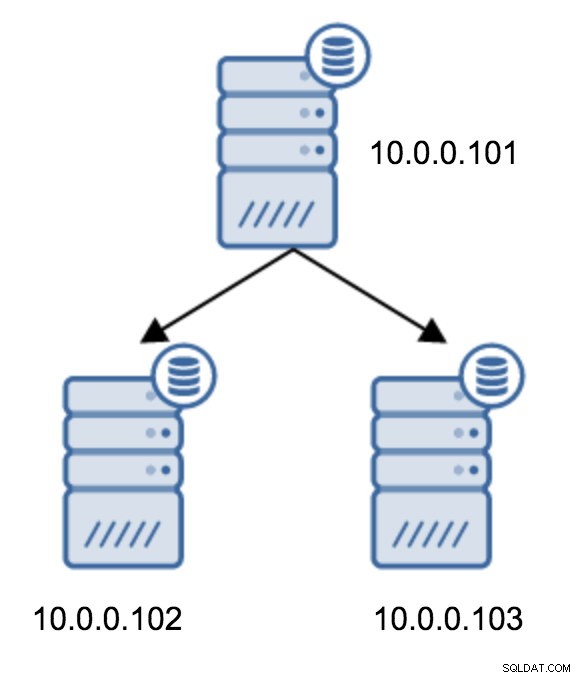
Skiftet fra en topologi med to standby-servere til en kædet replikering er ret ligetil.
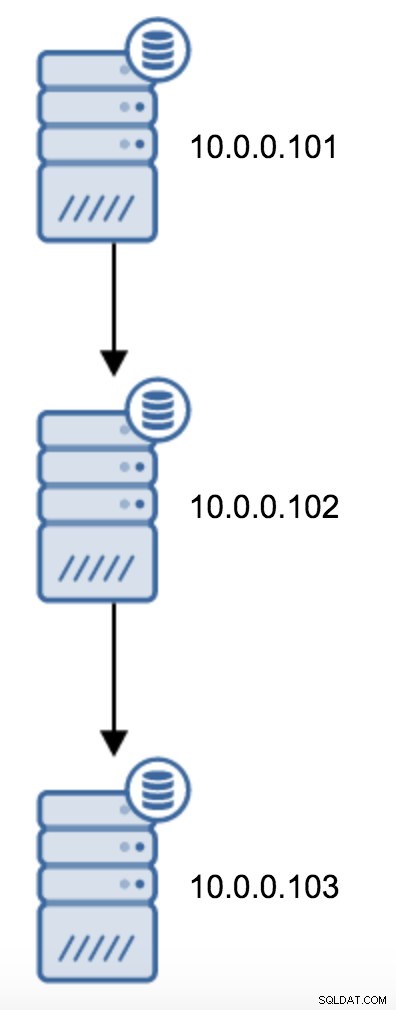
Du skal ændre recovery.conf på 10.0.0.103, pege den mod 10.0.0.102 og derefter genstarte PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Efter genstart bør 10.0.0.103 begynde at anvende WAL-opdateringer.
Dette er nogle almindelige tilfælde af topologiændringer. Et emne, der ikke blev diskuteret, men som stadig er vigtigt, er virkningen af disse ændringer på ansøgningerne. Vi vil dække det i et separat indlæg, samt hvordan man gør disse topologiændringer gennemsigtige for applikationerne.