Håndtering af trafik til databasen kan blive sværere og sværere, efterhånden som den stiger i mængde, og databasen faktisk er fordelt på flere servere. PostgreSQL-klienter taler normalt til et enkelt slutpunkt. Når en primær node fejler, vil databaseklienterne blive ved med at prøve den samme IP-adresse igen. Hvis du har fejlet over til en sekundær node, skal applikationen opdateres med det nye slutpunkt. Det er her, du ønsker at sætte en belastningsbalancer mellem applikationerne og databaseforekomsterne. Det kan dirigere applikationer til tilgængelige/sunde databasenoder og failover, når det kræves. En anden fordel ville være at øge læseydelsen ved at bruge replikaer effektivt. Det er muligt at oprette en skrivebeskyttet port, der afbalancerer læsninger på tværs af replikaer. I denne blog vil vi dække HAProxy. Vi vil se, hvad der er, hvordan det virker, og hvordan det implementeres til PostgreSQL.
Hvad er HAProxy?
HAProxy er en open source-proxy, der kan bruges til at implementere høj tilgængelighed, belastningsbalancering og proxy for TCP- og HTTP-baserede applikationer.
Som load balancer distribuerer HAProxy trafik fra én oprindelse til én eller flere destinationer og kan definere specifikke regler og/eller protokoller for denne opgave. Hvis en af destinationerne holder op med at svare, markeres den som offline, og trafikken sendes til resten af de tilgængelige destinationer.
Sådan installeres og konfigureres HAProxy manuelt
For at installere HAProxy på Linux kan du bruge følgende kommandoer:
På Ubuntu/Debian OS:
$ apt-get install haproxy -yPå CentOS/RedHat OS:
$ yum install haproxy -yOg så skal vi redigere følgende konfigurationsfil for at administrere vores HAProxy-konfiguration:
$ /etc/haproxy/haproxy.cfgKonfiguration af vores HAProxy er ikke kompliceret, men vi skal vide, hvad vi gør. Vi har flere parametre at konfigurere, alt efter hvordan vi ønsker at HAProxy skal fungere. For mere information kan vi følge dokumentationen om HAProxy-konfigurationen.
Lad os se på et grundlæggende konfigurationseksempel. Antag, at du har følgende databasetopologi:
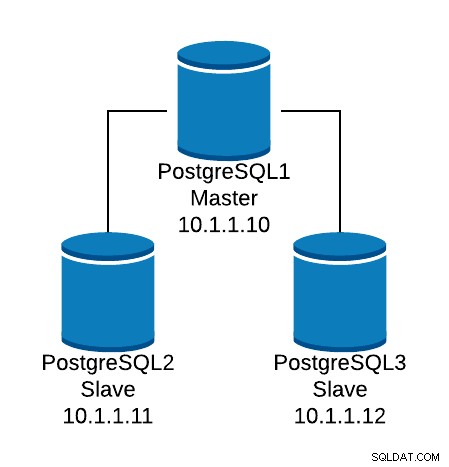 Eksempel på databasetopologi
Eksempel på databasetopologi Vi ønsker at skabe en HAProxy-lytter for at balancere læsetrafikken mellem de tre noder.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkSom vi nævnte før, er der flere parametre at konfigurere her, og denne konfiguration afhænger af, hvad vi vil gøre. For eksempel:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkSådan virker HAProxy på ClusterControl
For PostgreSQL er HAProxy konfigureret af ClusterControl med to forskellige porte som standard, en læse-skrive og en skrivebeskyttet.
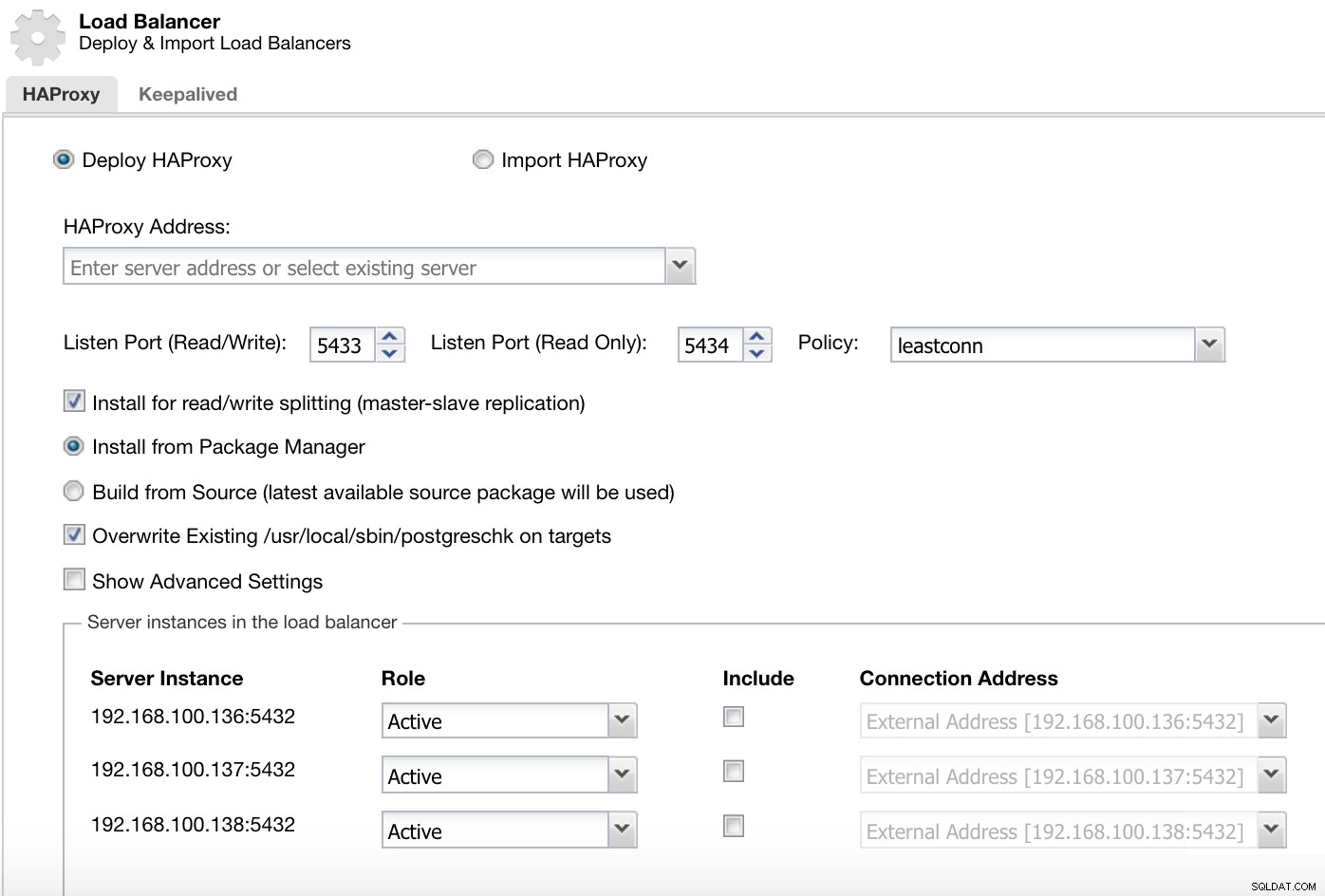 ClusterControl Load Balancer Deploy Information 1
ClusterControl Load Balancer Deploy Information 1 I vores read-write-port har vi vores masterserver som online og resten af vores noder som offline, og i read-only-porten har vi både masteren og slaverne online.
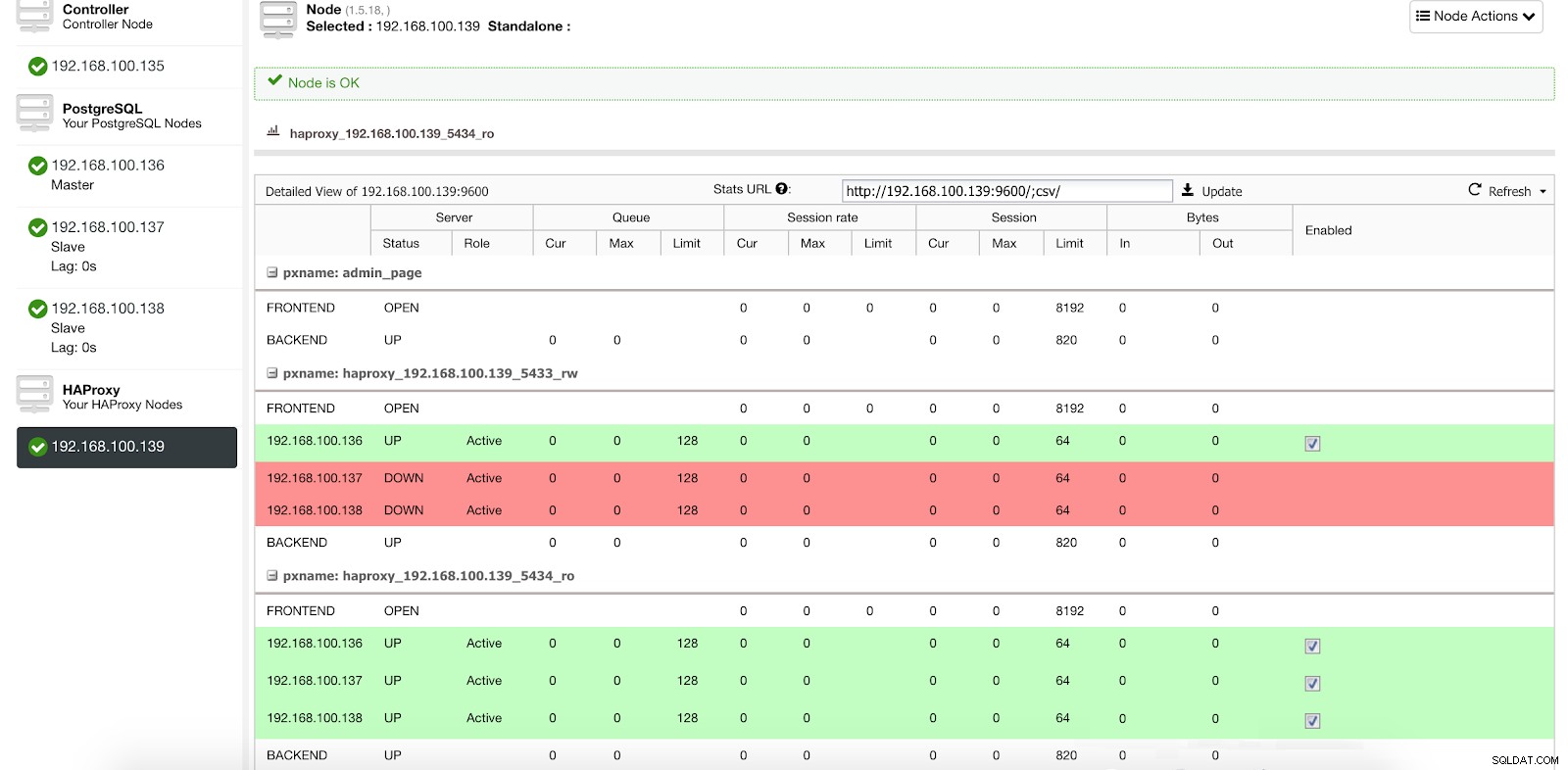 ClusterControl Load Balancer Stats 1
ClusterControl Load Balancer Stats 1 Når HAProxy registrerer, at en af vores noder, enten master eller slave, ikke er tilgængelig, markerer den den automatisk som offline og tager den ikke i betragtning, når den sender trafik. Registrering udføres af sundhedstjek-scripts, der er konfigureret af ClusterControl på tidspunktet for implementeringen. Disse kontrollerer, om forekomsterne er oppe, om de er under gendannelse eller er skrivebeskyttede.
Når ClusterControl fremmer en slave til master, markerer vores HAProxy den gamle master som offline (for begge porte) og sætter den promoverede node online (i læse-skrive-porten).
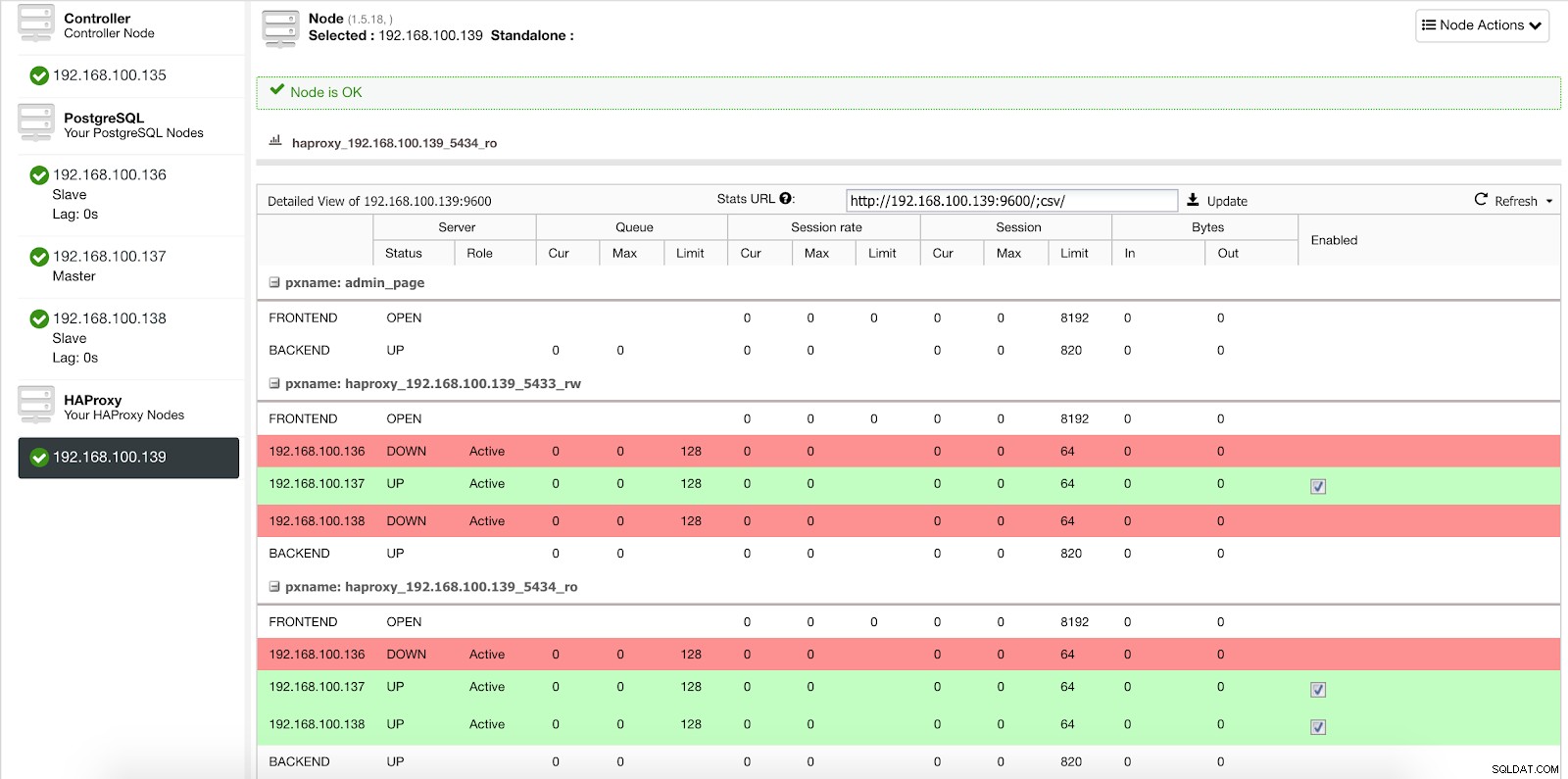 ClusterControl Load Balancer Stats 2
ClusterControl Load Balancer Stats 2 På denne måde fortsætter vores systemer med at fungere normalt og uden vores indgriben.
Sådan implementerer du HAProxy med ClusterControl
I vores eksempel oprettede vi et miljø med 1 master og 2 slaver - se et skærmbillede af Topology View i ClusterControl. Vi tilføjer nu vores HAProxy load balancer.
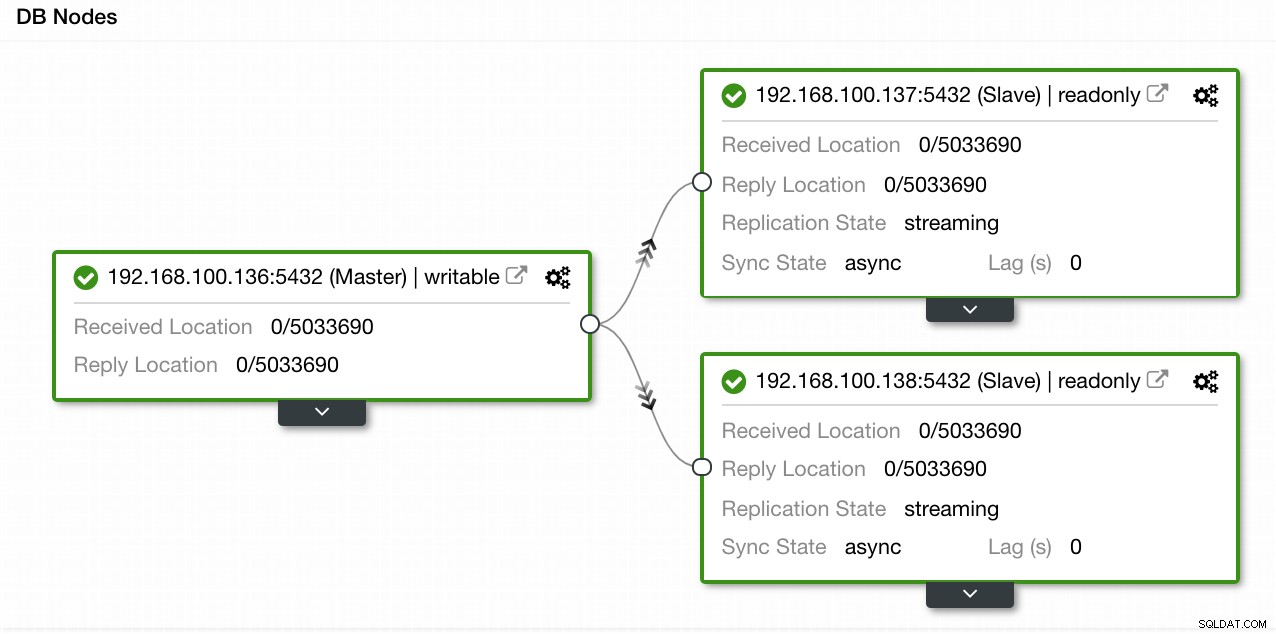 ClusterControl Topology View 1
ClusterControl Topology View 1 Til denne opgave skal vi gå til ClusterControl -> PostgreSQL Cluster Actions -> Tilføj Load Balancer
 ClusterControl Cluster Actions Menu
ClusterControl Cluster Actions Menu Her skal vi tilføje de oplysninger, som ClusterControl vil bruge til at installere og konfigurere vores HAProxy load balancer.
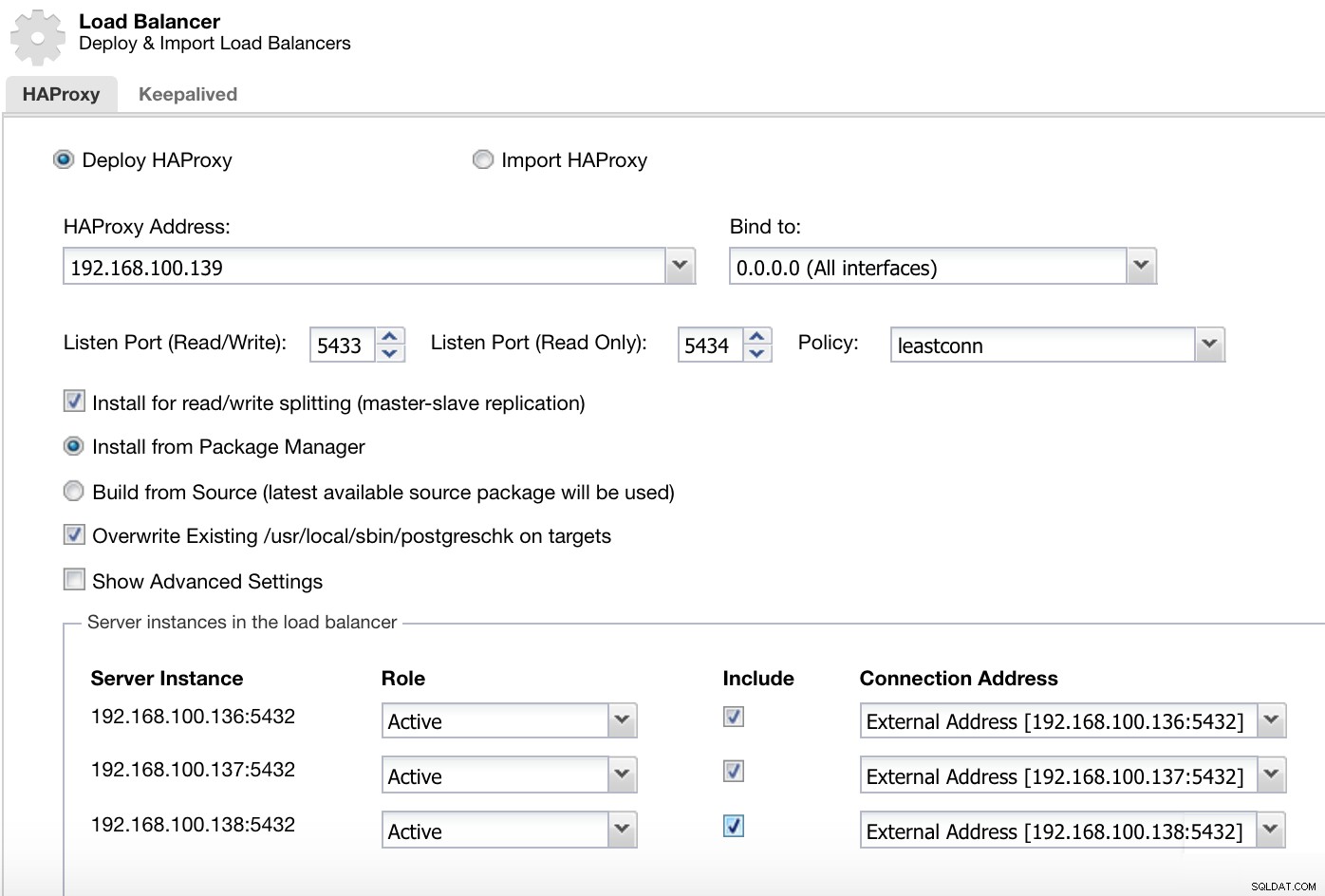 ClusterControl Load Balancer Deploy Information 2
ClusterControl Load Balancer Deploy Information 2 De oplysninger, vi skal introducere, er:
Handling:Implementer eller importer.
HAProxy-adresse:IP-adresse til vores HAProxy-server.
Bind til:Interface eller IP-adresse, hvor HAProxy vil lytte.
Lytteport (læse/skrive):Port til læse-/skrivetilstand.
Listen Port (Read Only):Port til skrivebeskyttet tilstand.
Politik:Det kan være:
- leastconn:Serveren med det laveste antal forbindelser modtager forbindelsen.
- roundrobin:Hver server bruges på skift, i henhold til deres vægt.
- kilde:Kilde-IP-adressen hashes og divideres med den samlede vægt af de kørende servere for at angive, hvilken server der skal modtage anmodningen.
Installer til læse-/skriveopdeling:Til master-slave-replikering.
Kilde:Vi kan vælge Installer fra en pakkehåndtering eller byg fra kilde.
Overskriv eksisterende postgreschk på mål.
Og vi skal vælge, hvilke servere du vil tilføje til HAProxy-konfigurationen og nogle yderligere oplysninger som:
Rolle:Det kan være Aktivt eller Backup.
Inkluder:Ja eller Nej.
Oplysninger om forbindelsesadresse.
Vi kan også konfigurere avancerede indstillinger som Admin User, Backend Name, Timeouts og mere.
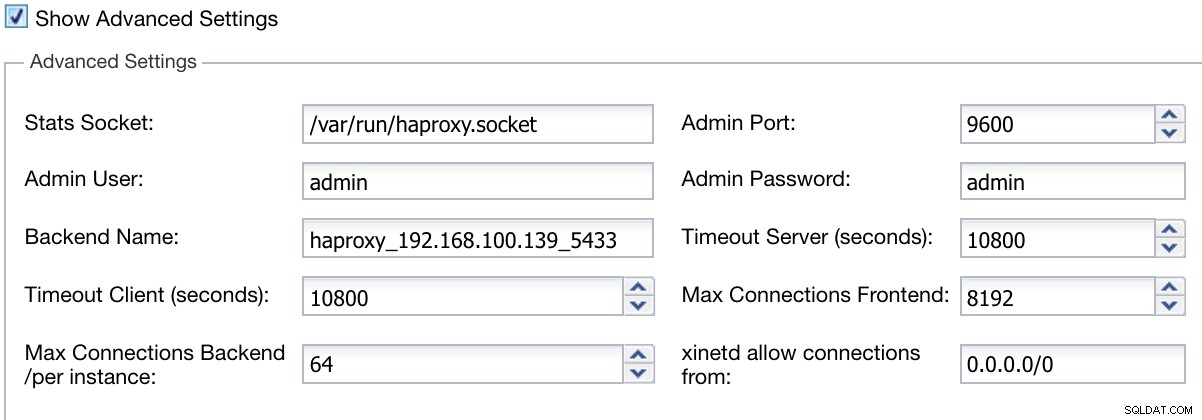 ClusterControl Load Balancer Deploy Information Advanced
ClusterControl Load Balancer Deploy Information Advanced Når du er færdig med konfigurationen og bekræfter implementeringen, kan vi følge fremskridtene i aktivitetssektionen på ClusterControl UI.
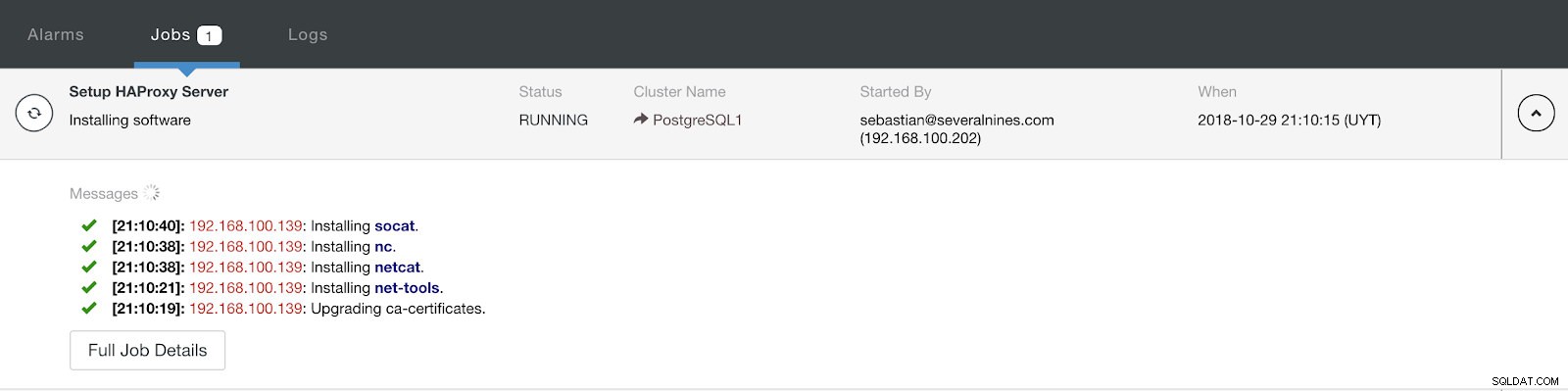 ClusterControl Activity Section
ClusterControl Activity Section Når det er færdigt, bør vi have følgende topologi:
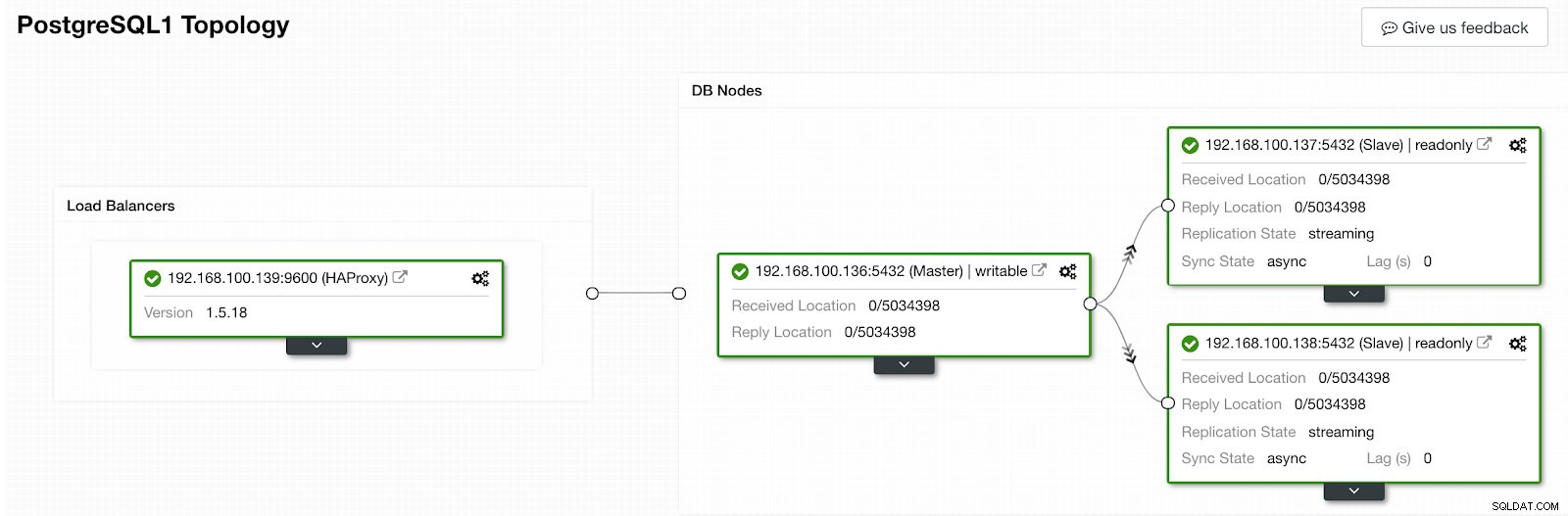 ClusterControl Topology View 2
ClusterControl Topology View 2 Vi kan forbedre vores HA-design ved at tilføje en ny HAProxy-node og konfigurere Keepalved-tjenesten mellem dem. Alt dette kan udføres af ClusterControl. For mere information kan du tjekke vores tidligere blog om PostgreSQL og HA.
Brug af ClusterControl CLI til at tilføje en HAProxy Load Balancer
Også kendt som s9s-værktøjer, blev denne valgfri pakke introduceret i ClusterControl version 1.4.1, som indeholder en binær kaldet s9s. Det er et kommandolinjeværktøj til at interagere, kontrollere og administrere din databaseinfrastruktur ved hjælp af ClusterControl. s9s kommandolinjeprojekt er open source og kan findes på GitHub.
Fra version 1.4.1 vil installationsscriptet automatisk installere pakken (s9s-tools) på ClusterControl-noden.
ClusterControl CLI åbner en ny dør til klyngeautomatisering, hvor du nemt kan integrere den med eksisterende implementeringsautomatiseringsværktøjer som Ansible, Puppet, Chef eller Salt.
Lad os se på et eksempel på, hvordan man opretter en HAProxy load balancer med IP-adresse 192.168.100.142 på klynge ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.Og så kan vi tjekke alle vores noder fra kommandolinjen:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5For mere information om s9s og hvordan man bruger det, kan du tjekke den officielle dokumentation eller denne blog om dette emne.
Konklusion
I denne blog har vi gennemgået, hvordan HAProxy kan hjælpe os med at styre trafikken, der kommer fra applikationen til vores PostgreSQL-database. Vi tjekkede, hvordan det kan implementeres og konfigureres manuelt, og så, hvordan det kan automatiseres med ClusterControl. For at undgå at HAProxy bliver et enkelt fejlpunkt (SPOF), skal du sørge for at implementere mindst to HAProxy-instanser og implementere noget som Keepalved og Virtual IP oven i dem.