Dine ansvarsområder som DBA (eller DBCC CHECKDB . Du kan komme halvvejs dertil ved at oprette en simpel vedligeholdelsesplan med en "Check Database Integrity Task" – men efter min mening er dette blot at markere et afkrydsningsfelt.
Hvis du ser nærmere efter, er der meget lidt, du kan gøre for at kontrollere, hvordan opgaven fungerer. Selv det ret ekspansive panel Egenskaber afslører en hel masse indstillinger for vedligeholdelsesunderplanen, men praktisk talt intet om DBCC kommandoer den vil køre. Personligt synes jeg, du bør tage en meget mere proaktiv og kontrolleret tilgang til, hvordan du udfører din CHECKDB operationer i produktionsmiljøer, ved at oprette dine egne job og manuelt håndlave din DBCC kommandoer. Du kan skræddersy din tidsplan eller selve kommandoerne til forskellige databaser – for eksempel er ASP.NET-medlemskabsdatabasen sandsynligvis ikke så afgørende som din salgsdatabase og kunne tolerere mindre hyppige og/eller mindre grundige kontroller.
Men for dine vigtige databaser tænkte jeg, at jeg ville sammensætte et indlæg for at detaljere nogle af de ting, jeg ville undersøge for at minimere forstyrrelsen DBCC kommandoer kan forårsage – og hvilke myter og marketingshot du skal være på vagt over for. Og jeg vil gerne takke Paul "Mr. DBCC" Randal (@PaulRandal) for at give værdifuldt input – ikke kun til dette specifikke indlæg, men også de endeløse råd, han giver på sin blog, #sqlhelp og i SQLskills Immersion-træning.
Tag venligst alle disse ideer med et gran salt, og gør dit bedste for at udføre passende test i dit miljø – ikke alle disse forslag vil give bedre ydeevne i alle miljøer. Men du skylder dig selv, dine brugere og dine interessenter i det mindste at overveje virkningen af din CHECKDB operationer kan have, og tage skridt til at afbøde disse virkninger, hvor det er muligt – uden at indføre unødvendig risiko ved ikke at kontrollere de rigtige ting.
Reducer støjen og forbrug alle fejl
Uanset hvor du kører CHECKDB , brug altid WITH NO_INFOMSGS mulighed. Dette undertrykker simpelthen alt det irrelevante output, der bare fortæller dig, hvor mange rækker der er i hver tabel; hvis du er interesseret i disse oplysninger, kan du få dem fra simple forespørgsler mod DMV'er og ikke mens DBCC løber. At undertrykke outputtet gør det langt mindre sandsynligt, at du går glip af en kritisk besked, der er begravet i alt det glade output.
På samme måde bør du altid bruge WITH ALL_ERRORMSGS mulighed, men især hvis du kører SQL Server 2008 RTM eller SQL Server 2005 (i disse tilfælde kan du se listen over fejl pr. objekt trunkeret til 200). For enhver CHECKDB andre operationer end hurtige ad-hoc-tjek, bør du overveje at dirigere output til en fil. Management Studio er begrænset til 1000 linjers output fra DBCC CHECKDB , så du kan gå glip af nogle fejl, hvis du overskrider dette tal.
Selvom det ikke udelukkende er et præstationsproblem, vil brug af disse muligheder forhindre dig i at skulle køre processen igen. Dette er især vigtigt, hvis du er midt i en katastrofeoprettelse.
Overfør logiske kontroller, hvor det er muligt
I de fleste tilfælde CHECKDB bruger størstedelen af sin tid på at udføre logiske kontroller af dataene. Hvis du har mulighed for at udføre disse kontroller på en sand kopi af dataene, kan du fokusere din indsats på den fysiske struktur af dine produktionssystemer og bruge den sekundære server til at håndtere alle de logiske kontroller og afhjælpe den belastning fra den primære. Af sekundær server , jeg mener kun følgende:
- Stedet, hvor du tester dine fulde gendannelser – fordi du tester dine gendannelser, ikke?
Andre mennesker (især den gigantiske marketingstyrke, som er Microsoft) kunne have overbevist dig om, at andre former for sekundære servere er egnede til DBCC checks. For eksempel:
- en AlwaysOn Availability Group læsbar sekundær;
- et øjebliksbillede af en spejlet database;
- en log afsendt sekundær;
- SAN-spejling;
- eller andre variationer...
Desværre er dette ikke tilfældet, og ingen af disse sekundære er gyldige, pålidelige steder at udføre dine kontroller som et alternativ til det primære. Kun en en-til-en-sikkerhedskopi kan tjene som en ægte kopi; alt andet, der er afhængigt af ting som anvendelsen af log backups for at komme til en konsistent tilstand, vil ikke pålideligt afspejle integritetsproblemer på den primære.
Så i stedet for at prøve at overføre dine logiske kontroller til en sekundær og aldrig udføre dem på den primære, foreslår jeg her:
- Sørg for, at du ofte tester gendannelserne af dine fulde sikkerhedskopier. Og nej, dette inkluderer ikke
COPY_ONLYsikkerhedskopier fra en AG-sekundær, af samme årsager som ovenfor – det ville kun være gyldigt i det tilfælde, hvor du lige har startet den sekundære med en fuld gendannelse. - Kør
DBCC CHECKDBofte imod de fulde gendan, før du gør noget andet. Igen, genafspilning af logposter på dette tidspunkt vil ugyldiggøre denne database som en sand kopi af kilden. - Kør
DBCC CHECKDBmod dit primære, måske opdelt på måder, som Paul Randal foreslår, og/eller på en mindre hyppig tidsplan og/eller ved at brugePHYSICAL_ONLYoftere end ikke. Dette kan afhænge af, hvor ofte og pålideligt du udfører (2). - Antag aldrig, at checks mod det sekundære er nok. Selv med en nøjagtig replika af din primære database, er der stadig fysiske problemer, der kan opstå på I/O-undersystemet i din primære, som aldrig vil forplante sig til den sekundære.
- Analyser altid
DBCCproduktion. Bare at køre det og ignorere det, for at markere det fra en eller anden liste, er lige så nyttigt som at køre sikkerhedskopier og hævde succes uden nogensinde at teste, at du faktisk kan gendanne den sikkerhedskopi, når det er nødvendigt.
Eksperimenter med sporingsflag 2549, 2562 og 2566
Jeg har lavet nogle grundige test af to sporingsflag (2549 og 2562) og har fundet ud af, at de kan give væsentlige præstationsforbedringer, men Lonny rapporterer, at de ikke længere er nødvendige eller nyttige. Hvis du er på 2016 eller nyere, spring hele denne sektion over . Hvis du er på en ældre version, er disse to sporingsflag beskrevet meget mere detaljeret i KB #2634571, men grundlæggende:
- Sporingsflag 2549
- Dette optimerer checkdb-processen ved at behandle hver enkelt databasefil som værende på en unik underliggende disk. Dette er okay at bruge, hvis din database har en enkelt datafil, eller hvis du ved, at hver databasefil faktisk er på et separat drev. Hvis din database har flere filer, og de deler en enkelt, direkte tilsluttet spindel, skal du være på vagt over for dette sporingsflag, da det kan gøre mere skade end gavn.
VIGTIG :sql.sasquatch rapporterer en regression i denne sporingsflagadfærd i SQL Server 2014.
- Dette optimerer checkdb-processen ved at behandle hver enkelt databasefil som værende på en unik underliggende disk. Dette er okay at bruge, hvis din database har en enkelt datafil, eller hvis du ved, at hver databasefil faktisk er på et separat drev. Hvis din database har flere filer, og de deler en enkelt, direkte tilsluttet spindel, skal du være på vagt over for dette sporingsflag, da det kan gøre mere skade end gavn.
- Sporingsflag 2562
- Dette flag behandler hele checkdb-processen som en enkelt batch, på bekostning af højere tempdb-udnyttelse (op til 5 % af databasestørrelsen).
- Bruger en bedre algoritme til at bestemme, hvordan sider fra databasen skal læses, hvilket reducerer latch-stridigheder (specifikt for
DBCC_MULTIOBJECT_SCANNER). Bemærk, at denne specifikke forbedring er i SQL Server 2012-kodestien, så du vil drage fordel af den selv uden sporingsflaget. Dette kan undgå fejl som f.eks.:
Timeout opstod under afventning af låsning:klasse 'DBCC_MULTIOBJECT_SCANNER'.
- Ovenstående to sporingsflag er tilgængelige i følgende versioner:
- SQL Server 2008 Service Pack 2 kumulativ opdatering 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 kumulativ opdatering 4+
(10.00.5775+)SQL Server 2008 R2 RTM kumulativ opdatering 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 kumulativ opdatering 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, alle versioner
(11.00.2100+) - Sporingsflag 2566
- Hvis du stadig bruger SQL Server 2005, forsøger dette sporingsflag, der blev introduceret i 2005 SP2 CU#9 (9.00.3282) (dog ikke dokumenteret i den kumulative opdaterings Knowledge Base-artikel, KB #953752), at rette op på dårlig ydeevne af
DATA_PURITYkontroller på x64-baserede systemer. På et tidspunkt kunne du se flere detaljer i KB #945770, men det ser ud til, at artiklen blev skrubbet fra både Microsofts supportside og WayBack-maskinen. Dette sporingsflag burde ikke være nødvendigt i mere moderne versioner af SQL Server, da problemet i forespørgselsprocessoren er blevet rettet.
- Hvis du stadig bruger SQL Server 2005, forsøger dette sporingsflag, der blev introduceret i 2005 SP2 CU#9 (9.00.3282) (dog ikke dokumenteret i den kumulative opdaterings Knowledge Base-artikel, KB #953752), at rette op på dårlig ydeevne af
Hvis du skal bruge nogen af disse sporingsflag, anbefaler jeg stærkt, at du indstiller dem på sessionsniveau ved hjælp af DBCC TRACEON snarere end som et startopsporingsflag. Ikke alene gør det dig i stand til at slukke for dem uden at skulle skifte SQL Server, men det giver dig også mulighed for kun at implementere dem, når du udfører visse CHECKDB kommandoer, i modsætning til operationer, der bruger enhver form for reparation.
Reducer I/O-påvirkning:optimer tempdb
DBCC CHECKDB kan gøre stor brug af tempdb, så sørg for at planlægge ressourceudnyttelse der. Dette er normalt en god ting at gøre under alle omstændigheder. For CHECKDB du ønsker at allokere plads korrekt til tempdb; den sidste ting du ønsker er CHECKDB fremskridt (og alle andre samtidige operationer) for at skulle vente på en autogrow. Du kan få en idé til krav ved at bruge WITH ESTIMATEONLY , som Paul forklarer her. Bare vær opmærksom på, at estimatet kan være ret lavt på grund af en fejl i SQL Server 2008 R2. Hvis du bruger Trace flag 2562, skal du også sørge for at imødekomme de ekstra pladskrav.
Og selvfølgelig er alle de typiske råd til optimering af tempdb på stort set ethvert system også passende her:Sørg for, at tempdb er på sit eget sæt hurtig spindler, sørg for, at den er dimensioneret til at rumme al anden samtidig aktivitet uden at skulle vokse, sørg for at du bruger et optimalt antal datafiler osv. Et par andre ressourcer, du kan overveje:
- Optimering af tempdb-ydelse (MSDN)
- Kapacitetsplanlægning for tempdb (MSDN)
- En SQL Server DBA-myte om dagen:(30/12) tempdb bør altid have én datafil pr. processorkerne
Reducer I/O-påvirkning:styr snapshottet
For at køre CHECKDB , vil moderne versioner af SQL Server forsøge at skabe et skjult øjebliksbillede af din database på det samme drev (eller på alle drevene, hvis dine datafiler spænder over flere drev). Du kan ikke kontrollere denne mekanisme, men hvis du vil kontrollere hvor CHECKDB fungerer, opret først dit eget snapshot (Enterprise Edition kræves) på det drev, du kan lide, og kør DBCC kommando mod øjebliksbilledet. I begge tilfælde vil du gerne køre denne operation under en relativ nedetid for at minimere kopier-på-skriv-aktiviteten, der vil gå gennem snapshottet. Og du vil ikke have, at denne tidsplan kommer i konflikt med tunge skriveoperationer, såsom indeksvedligeholdelse eller ETL.
Du har muligvis set forslag til at tvinge CHECKDB at køre i offlinetilstand ved hjælp af WITH TABLOCK mulighed. Jeg fraråder stærkt denne tilgang. Hvis din database bruges aktivt, vil valget af denne mulighed blot gøre brugerne frustrerede. Og hvis databasen ikke bruges aktivt, sparer du ikke diskplads ved at undgå et øjebliksbillede, da der ikke vil være nogen kopi-på-skriv-aktivitet at gemme.
Reducer I/O-påvirkning:undgå 665/1450/1452 fejl
I nogle tilfælde kan du se en af følgende fejl:
Operativsystemet returnerede fejl 1450 (Der findes utilstrækkelige systemressourcer til at fuldføre den anmodede tjeneste.) til SQL Server under en skrivning med offset 0x[...] i filen med håndtag 0x[...]. Dette er normalt en midlertidig tilstand, og SQL Server vil fortsætte med at prøve handlingen igen. Hvis tilstanden fortsætter, skal der straks træffes foranstaltninger for at rette op på den.
Operativsystemet returnerede fejl 665 (den anmodede handling kunne ikke fuldføres på grund af en filsystembegrænsning) til SQL Server under en skrivning med offset 0x[...] i filen '[fil]'
Der er nogle tips her til at reducere risikoen for disse fejl under CHECKDB operationer og reducere deres indvirkning generelt – med flere tilgængelige rettelser, afhængigt af dit operativsystem og SQL Server-version:
- Sparse File Fejl:1450 eller 665 på grund af filfragmentering:Rettelser og løsninger
- SQL Server rapporterer operativsystemfejl 1450 eller 1452 eller 665 (forsøg igen)
Reducer CPU-påvirkning
DBCC CHECKDB er multi-threaded som standard (men kun i Enterprise Edition). Hvis dit system er CPU-bundet, eller du bare vil have CHECKDB for at bruge mindre CPU på bekostning af at køre længere, kan du overveje at reducere parallelitet på et par forskellige måder:
- Brug Resource Governor på 2008 og nyere, så længe du kører Enterprise Edition. For kun at målrette DBCC-kommandoer for en bestemt ressourcepulje eller arbejdsbelastningsgruppe, skal du skrive en klassificeringsfunktion, der kan identificere de sessioner, der skal udføre dette arbejde (f.eks. et specifikt login eller et job_id).
- Brug Trace flag 2528 til at slå parallelisme fra for
DBCC CHECKDB(samtCHECKFILEGROUPogCHECKTABLE). Sporflag 2528 er beskrevet her. Dette er selvfølgelig kun gyldigt i Enterprise Edition, for på trods af hvad Books Online siger i øjeblikket, er sandheden, atCHECKDBgår ikke parallelt i Standard Edition. - Mens
DBCCkommandoen i sig selv understøtter ikkeMAXDOP(i det mindste før SQL Server 2014 SP2), respekterer den den globale indstillingmax degree of parallelism. Sandsynligvis ikke noget, jeg ville gøre i produktionen, medmindre jeg ikke havde andre muligheder, men dette er en overordnet måde at kontrollere visseDBCCkommandoer, hvis du ikke kan målrette dem mere eksplicit.
Vi havde bedt om bedre kontrol over antallet af CPU'er, der DBCC CHECKDB bruger, men de var gentagne gange blevet nægtet indtil SQL Server 2014 SP2. Så du kan nu tilføje WITH MAXDOP = n til kommandoen.
Mine resultater
Jeg ønskede at demonstrere et par af disse teknikker i et miljø, jeg kunne kontrollere. Jeg installerede AdventureWorks2012 og udvidede det derefter ved hjælp af AW-forstørrelsesscriptet skrevet af Jonathan Kehayias (blog | @SQLPoolBoy), som udvidede databasen til omkring 7 GB. Derefter kørte jeg en række CHECKDB kommandoer imod det og timede dem. Jeg brugte en almindelig vanilje DBCC CHECKDB alene, derefter bruges alle andre kommandoer WITH NO_INFOMSGS, ALL_ERRORMSGS . Derefter fire tests med (a) ingen sporingsflag, (b) 2549, (c) 2562 og (d) både 2549 og 2562. Så gentog jeg de fire test, men tilføjede PHYSICAL_ONLY mulighed, som omgår alle de logiske kontroller. Resultaterne (i gennemsnit over 10 testkørsler) siger:
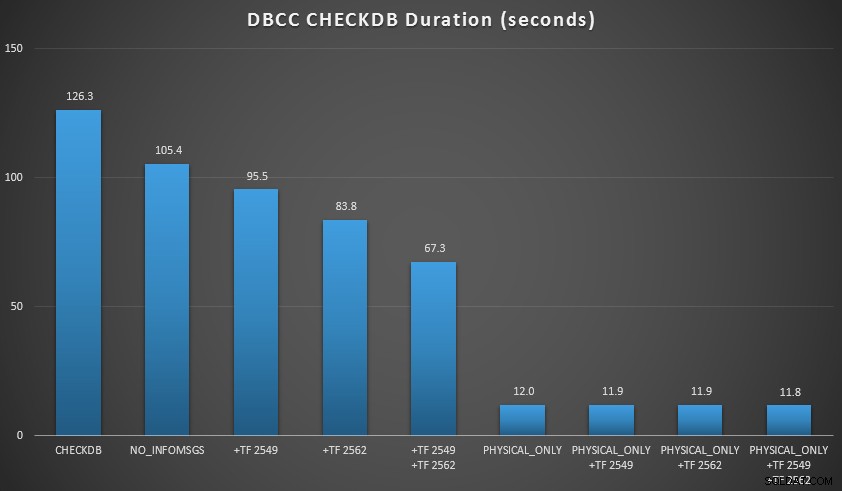
CHECKDB-resultater mod 7 GB database
Så udvidede jeg databasen noget mere, lavede mange kopier af de to forstørrede tabeller, hvilket førte til en databasestørrelse lige nord for 70 GB, og kørte testene igen. Resultaterne, igen i gennemsnit over 10 testkørsler:
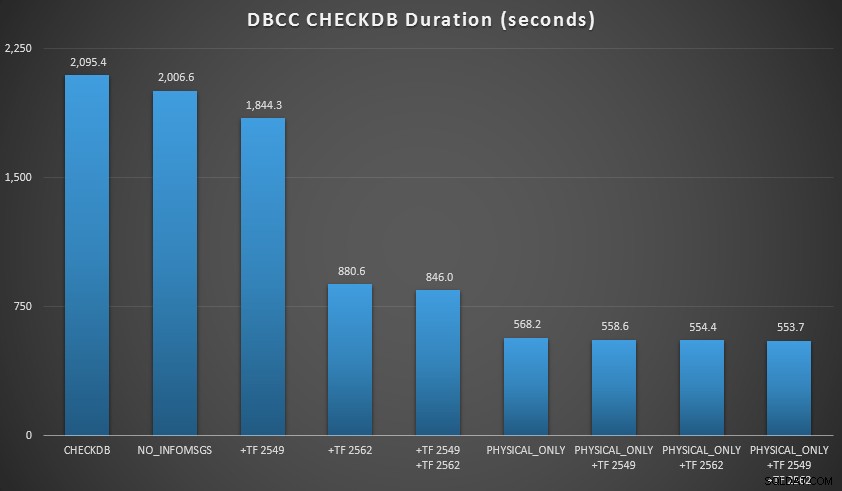
CHECKDB-resultater mod 70 GB database
I disse to scenarier har jeg lært følgende (igen, husk på, at dit kilometertal kan variere, og at du bliver nødt til at udføre dine egne tests for at drage nogen meningsfulde konklusioner):
- Når jeg skal udføre logiske kontroller:
- Ved små databasestørrelser er
NO_INFOMSGSoption kan reducere behandlingstiden betydeligt, når kontrollerne køres i SSMS. På større databaser bliver denne fordel dog mindre, da den tid og det arbejde, der bruges på at videresende informationen, bliver en så ubetydelig del af den samlede varighed. 21 sekunder ud af 2 minutter er væsentligt; 88 sekunder ud af 35 minutter, ikke så meget. - De to sporingsflag, jeg testede, havde en betydelig indvirkning på ydeevnen – hvilket repræsenterede en reduktion af kørselstid på 40-60 %, når begge blev brugt sammen.
- Ved små databasestørrelser er
- Når jeg kan skubbe logiske kontroller til en sekundær server (igen, forudsat at jeg udfører logiske kontroller andre steder mod en sand kopi ):
- Jeg kan reducere behandlingstiden på min primære instans med 70-90 % sammenlignet med en standard
CHECKDBringe uden muligheder. - I mit scenarie havde sporingsflagene meget lille indflydelse på varigheden, når de udførte
PHYSICAL_ONLYchecks.
- Jeg kan reducere behandlingstiden på min primære instans med 70-90 % sammenlignet med en standard
Selvfølgelig, og det kan jeg ikke understrege nok, er det relativt små databaser og kun brugt, så jeg kunne udføre gentagne, målte tests inden for rimelig tid. Denne server havde 80 logiske CPU'er og 128 GB RAM, og jeg var den eneste bruger. Varighed og interaktion med andre arbejdsbelastninger på systemet kan skævvride disse resultater en del. Her er et hurtigt glimt af typisk CPU-brug ved brug af SQL Sentry under en af CHECKDB operationer (og ingen af mulighederne ændrede virkelig den overordnede indvirkning på CPU, kun varighed):
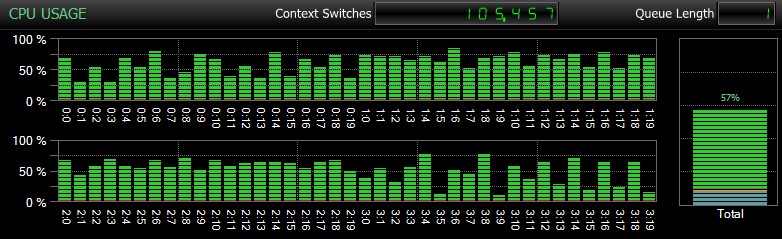
CPU-påvirkning under CHECKDB – eksempeltilstand
Og her er en anden visning, der viser lignende CPU-profiler for tre forskellige eksempler på CHECKDB operationer i historisk tilstand (jeg har overlejret en beskrivelse af de tre tests, der er samplet i dette interval):
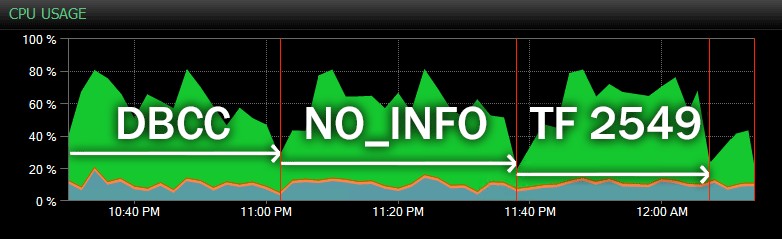
CPU-påvirkning under CHECKDB – historisk tilstand
På endnu større databaser, hostet på mere travle servere, kan du se forskellige effekter, og din kilometertal vil sandsynligvis variere. Så udfør venligst din due diligence og test disse muligheder og spor flag under en typisk samtidig arbejdsbelastning, før du beslutter dig for, hvordan du vil gribe CHECKDB an. .
Konklusion
DBCC CHECKDB er en meget vigtig, men ofte undervurderet del af dit ansvar som DBA eller arkitekt, og afgørende for beskyttelsen af din virksomheds data. Tag ikke let på dette ansvar, og gør dit bedste for at sikre, at du ikke ofrer noget for at reducere indvirkningen på dine produktionsforekomster. Vigtigst af alt:kig forbi marketingdatabladene for at være sikker på, at du fuldt ud forstår, hvor gyldige disse løfter er, og om du er villig til at satse din virksomheds data på dem. At spare på nogle checks eller overføre dem til ugyldige sekundære steder kan være en katastrofe, der venter på at ske.
Du bør også overveje at læse disse PSS-artikler:
- En hurtigere CHECKDB – Del I
- En hurtigere CHECKDB – Del II
- En hurtigere CHECKDB – Del III
- En hurtigere CHECKDB – Del IV (SQL CLR UDT'er)
Og dette indlæg fra Brent Ozar:
- 3 måder at køre DBCC CHECKDB hurtigere på
Endelig, hvis du har et uløst spørgsmål om DBCC CHECKDB , post det til #sqlhelp hash-tagget på twitter. Paul tjekker det mærke ofte, og da hans billede skulle vises i hovedartiklen i Books Online, er det sandsynligt, at hvis nogen kan svare på det, så kan han det. Hvis det er for komplekst til 140 tegn, kan du spørge her (og jeg vil sørge for, at Paul ser det på et tidspunkt), eller skrive til et forumwebsted såsom Database Administrators Stack Exchange.