Brug af korrelationsfunktionen i PostgreSQL
En funktion, der kan være nyttig til at bestemme, hvordan to tal relaterer til hinanden, er korrelationsfunktionen.
I denne vejledning vil vi forklare corr() PostrgreSQL-funktionen samt vise den i den virkelige verden.
Korrelationskoefficienten er en meget brugt metode til at bestemme styrken af forholdet mellem to tal eller to sæt tal. Denne koefficient er beregnet som et tal mellem -1 og 1. 1 er den stærkest mulige positive korrelation og -1 er den stærkest mulige negative korrelation.

En positiv korrelation betyder, at når et tal stiger, vil det andet tal også stige.
En negativ korrelation betyder, at når et tal stiger, falder det andet tal.
Hvorvidt resultatet af det andet nummer er FORÅRSAGET af det første, bestemmes ikke her, bare at udfaldene af de to numre sker i samspil med hinanden.
Hvis formlen returnerer 0, er der absolut INGEN korrelation mellem de to sæt tal.
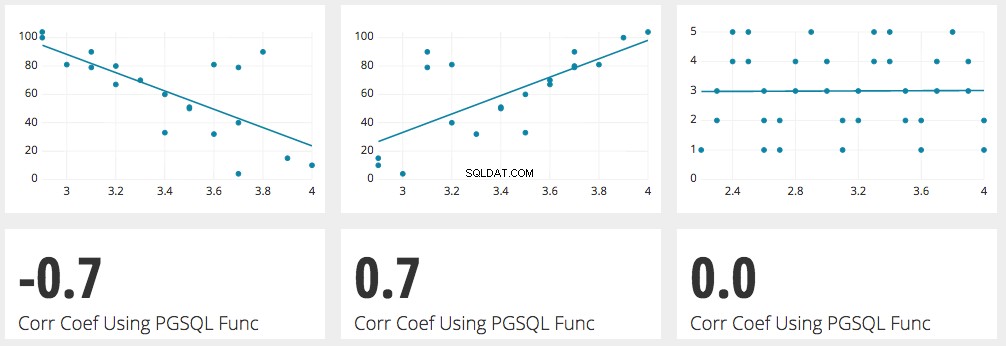
I et eksempel, hvor korrelationskoefficienten er 0,7, øges tallet på y-aksen med 0,7 for hver stigning på 1 af tallet på x-aksen.
Jo større tallet er, jo stærkere er korrelationen. Hvorvidt det er indledt med "-"-tegnet eller ej, er ligegyldigt.
En af de mest populære korrelationskoefficienter er Pearsons korrelationskoefficient, og mere information kan findes i en anden vejledning her.
Efter at vi kørte et par test på postgresql-korrelationsfunktionen, blev den lig med beregningen af Pearson-korrelationskoefficienten alle tre gange.
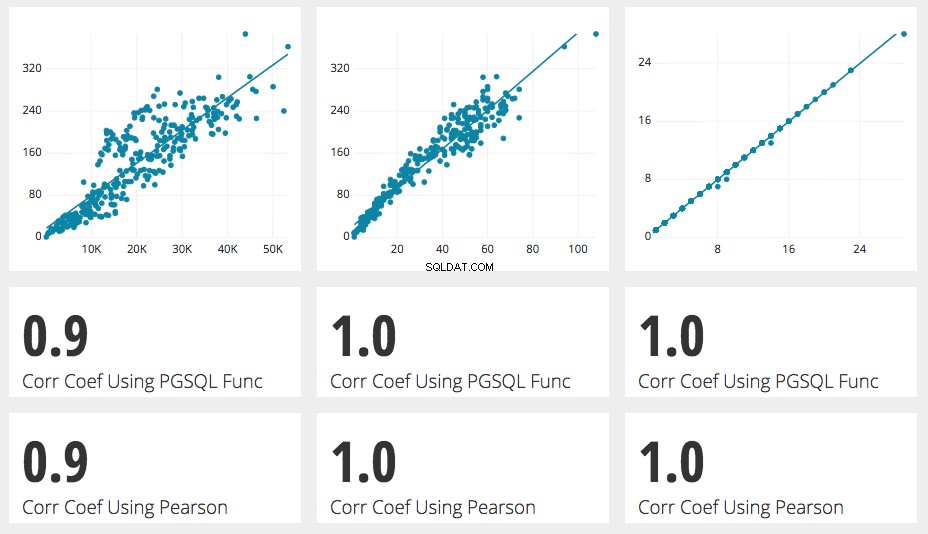
Når du bruger PostgreSQL-funktionen, er den vigtige bemærkning, at det er en aggregeringsfunktion. Det betyder, at den vil beregne korrelationen af helheden af to rækker af tal. Den viser ikke korrelationen mellem to tal i serien.
At bruge korrelationsfunktionen allerede i postgres er ret ligetil.
Vi brugte det som en aggregeret funktion af to talserier til at bestemme korrelationskoefficienten over en tidsserie af webstedsaktiviteter og indtjening i en Chartio-demokilde, vi har på vores websted.
Ved at plotte disse to målinger på et spredningsplot fremkommer et mønster af positiv korrelation. Brug af korrelationskoefficienten PostgreSQL-funktionen viser et resultat på 0,9, hvilket er en næsten direkte korrelation.
Den forespørgsel ser sådan ud:
SELECT
corr("Amount", "Activities") as "Corr Coef Using PGSQL Func"
FROM(
SELECT
DATE_TRUNC('day', p.payment_date)::DATE AS "Day",
SUM(p.amount) AS "Amount",
COUNT(DISTINCT a.activity_id) AS "Activities"
FROM
public.payments p
INNER JOIN public.subscriptions s ON p.subscription_id = s.subscription_id
INNER JOIN public.users u ON s.user_id = u.user_id
INNER JOIN public.activity a ON a.user_id = u.user_id
GROUP BY 1) as a
I dette særlige tilfælde skal du bruge aggregeringsfunktionen for de metrics, der er indsamlet i en underforespørgsel. Dette er meget ligetil, bare tilføj de to kolonner, du prøver at bestemme korrelationen mellem, mellem parenteserne adskilt af en kolonne, og dit output vil være korrelationskoefficienten beregnet af aggregeringsfunktionen, som som vi påpeger i den følgende tutorial er næsten nøjagtig det samme som Pearson Formula.