Kevin Kline (@kekline) og jeg holdt for nylig et forespørgselstuning-webinar (nå ja, faktisk et i en serie), og en af de ting, der dukkede op, er folks tendens til at oprette et manglende indeks, som SQL Server fortæller dem vil være. en god ting™ . De kan lære om disse manglende indekser fra Database Engine Tuning Advisor (DTA), de manglende indeks-DMV'er eller en eksekveringsplan, der vises i Management Studio eller Plan Explorer (som alle bare videresender information fra nøjagtig samme sted):
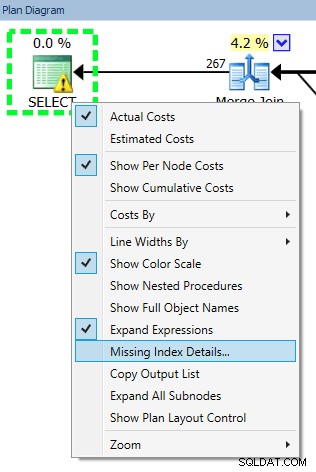
Problemet med bare blindt at oprette dette indeks er, at SQL Server har besluttet, at det er nyttigt til en bestemt forespørgsel (eller en håndfuld forespørgsler), men ignorerer fuldstændigt og ensidigt resten af arbejdsbyrden. Som vi alle ved, er indekser ikke "gratis" – du betaler for indekser både i rålager og vedligeholdelse påkrævet på DML-operationer. Det giver ikke meget mening, i en skrivetung arbejdsbyrde, at tilføje et indeks, der hjælper med at gøre en enkelt forespørgsel lidt mere effektiv, især hvis forespørgslen ikke køres ofte. Det kan være meget vigtigt i disse tilfælde at forstå din overordnede arbejdsbyrde og finde en god balance mellem at gøre dine forespørgsler effektive og ikke betale for meget for det med hensyn til indeksvedligeholdelse.
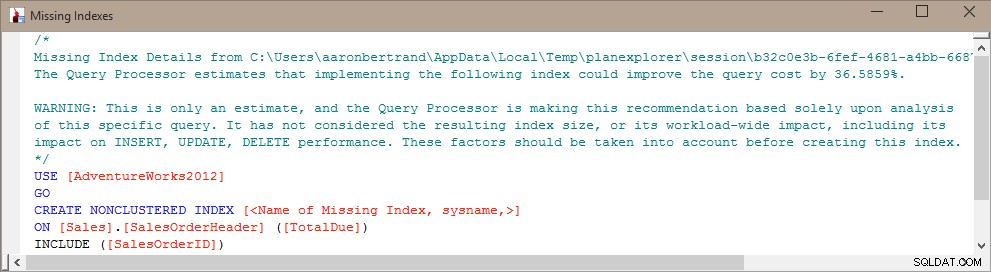
Så en idé, jeg havde, var at "mash up" information fra de manglende indeks-DMV'er, indeksbrugsstatistikken DMV og information om forespørgselsplaner for at bestemme, hvilken type balance der findes i øjeblikket, og hvordan tilføjelsen af indekset kan klare sig generelt.
Manglende indekser
Først kan vi tage et kig på de manglende indekser, som SQL Server i øjeblikket foreslår:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Dette viser den eller de tabeller og kolonner, der ville have været nyttige i et indeks, hvor mange kompileringer/søgninger/scanninger der ville have været brugt, og hvornår den sidste hændelse fandt sted for hvert potentielt indeks. Du kan også inkludere kolonner som s.avg_total_user_cost og s.avg_user_impact hvis du vil bruge de tal til at prioritere.
Planlæg driften
Lad os derefter tage et kig på de operationer, der blev brugt i alle de planer, vi har cachelagret mod de objekter, der er blevet identificeret af vores manglende indekser.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; En ven på dba.SE, Mikael Eriksson, foreslog følgende to forespørgsler, som på et større system vil fungere meget bedre end den XML/UNION-forespørgsel, jeg har lavet sammen ovenfor, så du kan eksperimentere med dem først. Hans slutkommentar var, at han "ikke overraskende fandt ud af, at mindre XML er en god ting for ydeevne. :)" Faktisk.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Nu i #planops tabel har du en masse værdier for plan_handle så du kan gå hen og undersøge hver af de individuelle planer i spil i forhold til de objekter, der er blevet identificeret som mangler et brugbart indeks. Vi kommer ikke til at bruge det til det lige nu, men du kan nemt krydshenvise dette med:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Nu kan du klikke på en af outputplanerne for at se, hvad de i øjeblikket gør mod dine objekter. Bemærk, at nogle af planerne vil blive gentaget, da en plan kan have flere operatører, der refererer til forskellige indekser på den samme tabel.
Indeks brugsstatistik
Lad os derefter tage et kig på indeksbrugsstatistikker, så vi kan se, hvor meget faktisk aktivitet der i øjeblikket kører mod vores kandidattabeller (og især opdateringer).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Bliv ikke forskrækket, hvis meget få eller ingen planer i cachen viser opdateringer for et bestemt indeks, selvom indeksbrugsstatistikken viser, at disse indekser er blevet opdateret. Dette betyder bare, at opdateringsplanerne ikke er i cachen i øjeblikket, hvilket kan være af forskellige årsager – for eksempel kan det være en meget læsetung arbejdsbyrde, og de er blevet forældet, eller de er alle single- brug og optimize for ad hoc workloads er aktiveret.
Sæt det hele sammen
Følgende forespørgsel viser dig, for hvert foreslået manglende indeks, antallet af læsninger et indeks kunne have hjulpet, antallet af skrivninger og læsninger, der i øjeblikket er blevet registreret i forhold til de eksisterende indekser, forholdet mellem disse, antallet af planer forbundet med dette objekt, og det samlede antal brug tæller for disse planer:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Hvis dit skrive:læse-forhold til disse indekser allerede er> 1 (eller> 10!), synes jeg, det giver grund til en pause, før du blindt opretter et indeks, der kun kunne øge dette forhold. Antallet af potential_read_ops vist, kan dog opveje det, efterhånden som antallet bliver større. Hvis potential_read_ops tallet er meget lille, vil du sandsynligvis ignorere anbefalingen fuldstændigt, før du overhovedet gider at undersøge de andre metrics – så du kan tilføje en WHERE klausul for at filtrere nogle af disse anbefalinger fra.
Et par bemærkninger:
- Dette er læse- og skriveoperationer, ikke individuelt målte læsninger og skrivninger på 8K sider.
- Forholdet og sammenligningerne er stort set uddannelsesmæssige; det kunne meget vel være tilfældet, at 10.000.000 skriveoperationer alle påvirkede en enkelt række, mens 10 læseoperationer kunne have haft væsentlig mere effekt. Dette er kun ment som en grov retningslinje og forudsætter, at læse- og skriveoperationer vægtes nogenlunde ens.
- Du kan også bruge små variationer på nogle af disse forespørgsler for at finde ud af – uden for de manglende indekser SQL Server anbefaler – hvor mange af dine nuværende indekser der er spild. Der er masser af ideer om dette online, inklusive dette indlæg af Paul Randal (@PaulRandal).
Jeg håber, det giver nogle ideer til at få mere indsigt i dit systems adfærd, før du beslutter dig for at tilføje et indeks, som et eller andet værktøj fortalte dig at oprette. Jeg kunne have lavet dette som en massiv forespørgsel, men jeg tror, at de enkelte dele vil give dig nogle kaninhuller at undersøge, hvis du ønsker det.
Andre bemærkninger
Du vil måske også udvide dette til at fange aktuelle størrelsesmålinger, tabellens bredde og antallet af aktuelle rækker (såvel som eventuelle forudsigelser om fremtidig vækst); dette kan give dig en god idé om, hvor meget plads et nyt indeks vil optage, hvilket kan være et problem afhængigt af dit miljø. Jeg vil muligvis behandle dette i et fremtidigt indlæg.
Selvfølgelig skal du huske på, at disse målinger kun er så nyttige, som din oppetid tilsiger. DMV'erne ryddes ud efter en genstart (og nogle gange i andre, mindre forstyrrende scenarier), så hvis du mener, at disse oplysninger vil være nyttige over en længere periode, kan det være noget, du vil overveje at tage periodiske snapshots.