Hver PostgreSQL-udgivelse kommer med få større funktionsforbedringer, men hvad der er lige så interessant er, at hver udgivelse også forbedrer sine tidligere funktioner.
Da PostgreSQL 13 er planlagt til at blive frigivet snart, er det tid til at tjekke, hvilke funktioner og forbedringer fællesskabet bringer os. En sådan forbedring uden støj er "Logisk replikeringsforbedring til partitionering."
Lad os forstå denne funktionsforbedring med et kørende eksempel.
Terminologi
To udtryk, som er vigtige for at forstå denne funktion, er:
- Partitionstabeller
- Logisk replikering
Partitionstabeller
En måde at opdele et stort bord i flere fysiske stykker for at opnå fordele som:
- Forbedret forespørgselsydeevne
- Hurtigere opdateringer
- Hurtigere masseindlæsninger og sletninger
- Organisering af sjældent brugte data på langsomme diskdrev
Nogle af disse fordele opnås ved hjælp af partitionsbeskæring (dvs. forespørgselsplanlægger, der bruger partitionsdefinition til at beslutte, om en partition skal scannes eller ej) og det faktum, at en partition er temmelig lettere at passe ind i den endelige hukommelse sammenlignet med et stort bord.
En tabel er opdelt på basis af:
- Liste
- Hash
- Rækkevidde

Logisk replikering
Som navnet antyder, er dette en replikeringsmetode, hvor data replikeres trinvist baseret på deres identitet (f.eks. nøgle). Det ligner ikke WAL eller fysiske replikeringsmetoder, hvor data sendes byte-for-byte.
Baseret på et Publisher-Subscriber-mønster skal datakilden definere en udgiver, mens målet skal registreres som abonnent. De interessante use cases for dette er:
- Selektiv replikering (kun en del af databasen)
- Skriver samtidig til to forekomster af databasen, hvor data bliver replikeret
- Replikering mellem forskellige operativsystemer (f.eks. Linux og Windows)
- Fint sikkerhed ved replikering af data
- Udløser eksekvering, når data ankommer på modtagersiden
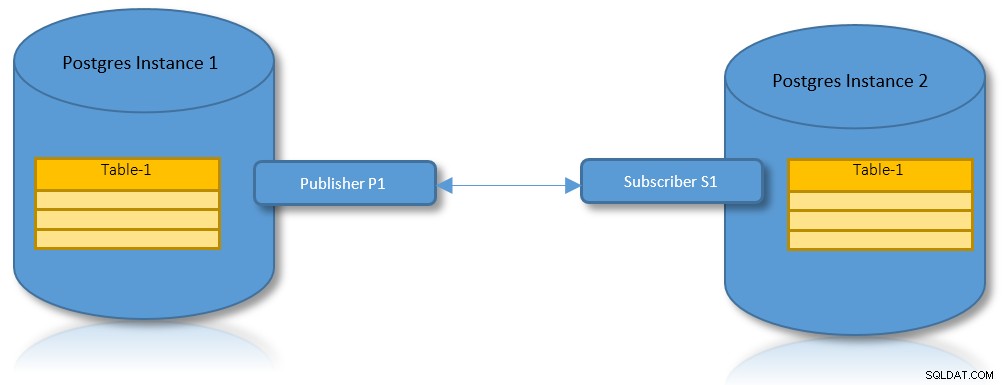
Logisk replikering til partitioner
Med fordelene ved både logisk replikering og partitionering er det en praktisk anvendelse at have et scenarie, hvor en partitioneret tabel skal replikeres på tværs af to PostgreSQL-instanser.
Følgende er trinene til at etablere og fremhæve den forbedring, der udføres i PostgreSQL 13 i denne sammenhæng.
Opsætning
Overvej en opsætning med to noder til at køre to forskellige forekomster, der indeholder en partitioneret tabel:
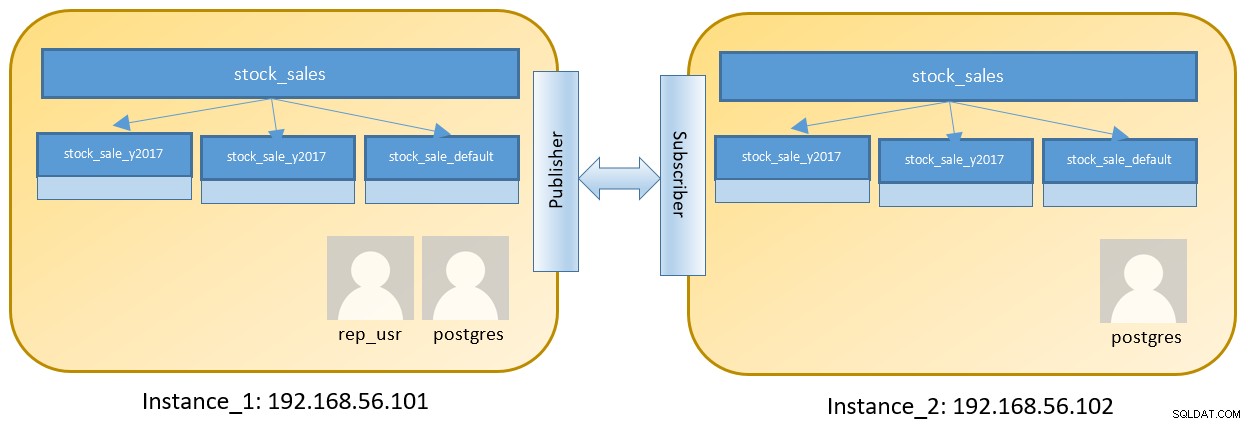
Trin på Instance_1 er som nedenfor post login på 192.168.56.101 som postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startIndstilling af 'wal_level' er sat specifikt til 'logisk' for at angive, at logisk replikering vil blive brugt til at replikere data fra denne instans. Konfigurationsfilen 'pg_hba.conf' er også blevet ændret for at tillade forbindelser fra 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Selvom postgres-rollen oprettes som standard på Instance_1-databasen, bør der også oprettes en separat bruger, som har begrænset adgang – hvilket kun begrænser omfanget for en given tabel.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Næsten lignende opsætning er påkrævet på Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startDet skal bemærkes, at da Instance_2 ikke vil være en datakilde for nogen anden node, behøver wal_level-indstillinger såvel som pg_hba.conf-filen ikke nogen ekstra indstillinger. Det er overflødigt at sige, at pg_hba.conf muligvis skal opdateres i henhold til produktionsbehov.
Logisk replikering understøtter ikke DDL, vi skal også oprette en tabelstruktur på Instance_2. Opret en partitioneret tabel ved hjælp af partitionsoprettelse ovenfor for også at oprette den samme tabelstruktur på Instance_2.
Opsætning af logisk replikering
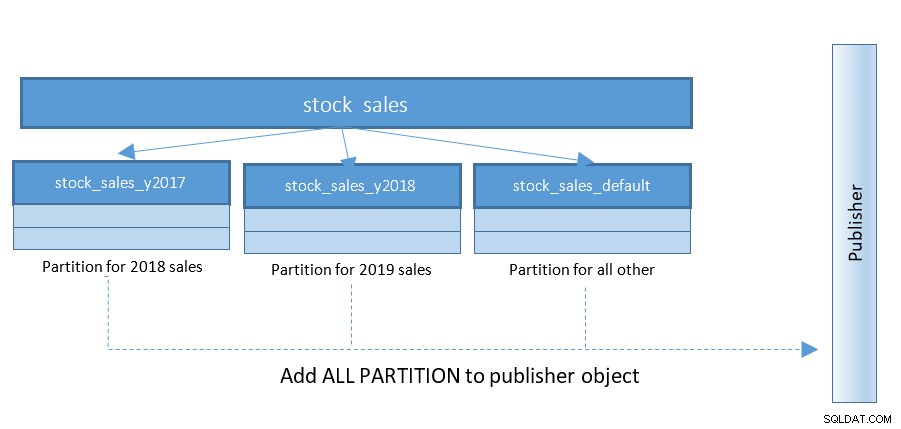
Opsætning af logisk replikering bliver meget nemmere med PostgreSQL 13. Indtil PostgreSQL 12 var strukturen som nedenfor:
Med PostgreSQL 13 bliver udgivelse af partitioner meget lettere. Se diagrammet nedenfor, og sammenlign med forrige diagram:
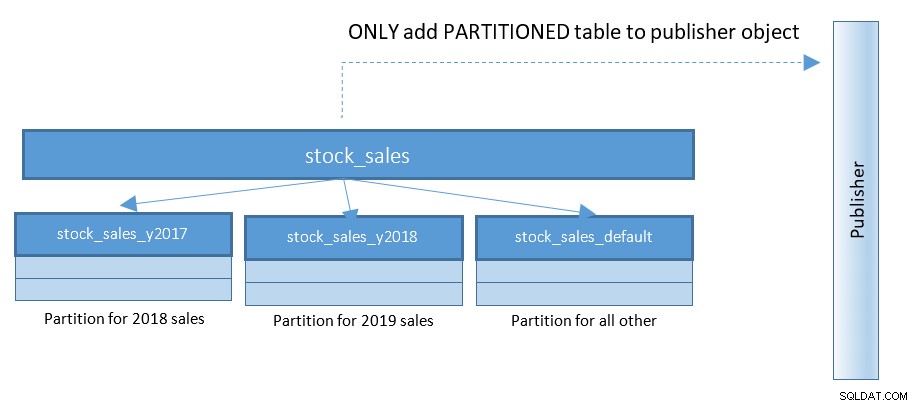
Med opsætninger, der raser med 100'er og 1000'er af partitionerede tabeller – denne lille ændring forenkler ting i vid udstrækning.
I PostgreSQL 13 vil erklæringerne for at oprette en sådan publikation være:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Konfigurationsparameteren publish_via_partition_root er ny i PostgreSQL 13, som gør det muligt for modtagernoden at have et lidt anderledes bladhierarki. Blot oprettelse af publikationer på partitionerede tabeller i PostgreSQL 12 vil returnere fejlsætninger som nedenfor:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignorerer begrænsningerne for PostgreSQL 12 og fortsætter med at bruge denne funktion på PostgreSQL 13, og vi er nødt til at etablere abonnent på Instance_2 med følgende udsagn:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Tjekker, om det virkelig virker
Vi er stort set færdige med hele opsætningen, men lad os køre et par tests for at se, om tingene fungerer.
I Instance_1 skal du indsætte flere rækker og sikre, at de opstår i flere partitioner:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Tjek dataene på Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Lad os nu tjekke, om logisk replikering fungerer, selvom bladknuderne ikke er ens på modtagersiden.
Tilføj endnu en partition på Instance_1 og indsæt post:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Tjek dataene på Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Andre partitioneringsfunktioner i PostgreSQL 13
Der er også andre forbedringer i PostgreSQL 13, som er relateret til partitionering, nemlig:
- Forbedringer i Join mellem partitionerede tabeller
- Partitionerede tabeller understøtter nu FØR udløsere på rækkeniveau
Konklusion
Jeg vil helt sikkert tjekke de førnævnte to kommende funktioner i mit næste sæt blogs. Indtil da stof til eftertanke – med den kombinerede kraft af partitionering og logisk replikering, sejler PostgreSQL tættere på en master-master-opsætning?