Hvordan vil du gerne fusionere "top"-processen for alle dine 5 databasenoder og sortere efter CPU-brug med kun en one-liner-kommando? Ja, du læste det rigtigt! Hvad med interaktive grafer, der vises i terminalgrænsefladen? Vi introducerede CLI-klienten til ClusterControl kaldet s9s for omkring et år siden, og den har været et godt supplement til webgrænsefladen. Det er også open source..
I dette blogindlæg viser vi dig, hvordan du kan overvåge dine databaser ved hjælp af din terminal og s9s CLI.
Introduktion til s9s, The ClusterControl CLI
ClusterControl CLI (eller s9s eller s9s CLI), er et open source-projekt og valgfri pakke introduceret med ClusterControl version 1.4.1. Det er et kommandolinjeværktøj til at interagere, kontrollere og administrere din databaseinfrastruktur ved hjælp af ClusterControl. s9s kommandolinjeprojekt er open source og kan findes på GitHub.
Fra version 1.4.1 vil installationsscriptet automatisk installere pakken (s9s-tools) på ClusterControl-noden.
Nogle forudsætninger. For at du kan køre s9s-tools CLI, skal følgende være sandt:
- En kørende ClusterControl Controller (cmon).
- s9s-klient, installer som en separat pakke.
- Port 9501 skal være tilgængelig for s9s-klienten.
Installation af s9s CLI er ligetil, hvis du installerer den på selve ClusterControl Controller-værten:$ rm
$ rm -Rf ~/.s9s
$ wget https://repo.severalnines.com/s9s-tools/install-s9s-tools.sh
$ ./install-s9s-tools.shDu kan installere s9s-værktøjer uden for ClusterControl-serveren (din bærbare arbejdsstation eller bastion-vært), så længe ClusterControl Controller RPC-grænsefladen (TLS) er udsat for det offentlige netværk (standard til 127.0.0.1:9501). Du kan finde flere detaljer om, hvordan du konfigurerer dette på dokumentationssiden.
For at kontrollere, om du kan oprette forbindelse til ClusterControl RPC-grænsefladen korrekt, bør du få OK-svaret, når du kører følgende kommando:
$ s9s cluster --ping
PING OK 2.000 msSom en sidebemærkning, se også på begrænsningerne, når du bruger dette værktøj.
Eksempel på implementering
Vores eksempelimplementering består af 8 noder på tværs af 3 klynger:
- PostgreSQL-streamingreplikering - 1 master, 2 slaver
- MySQL-replikering - 1 master, 1 slave
- MongoDB Replica Set - 1 primær, 2 sekundære noder
Alle databaseklynger blev implementeret af ClusterControl ved hjælp af "Deploy Database Cluster"-implementeringsguiden, og fra UI-synspunktet er dette, hvad vi ville se i klyngens dashboard:
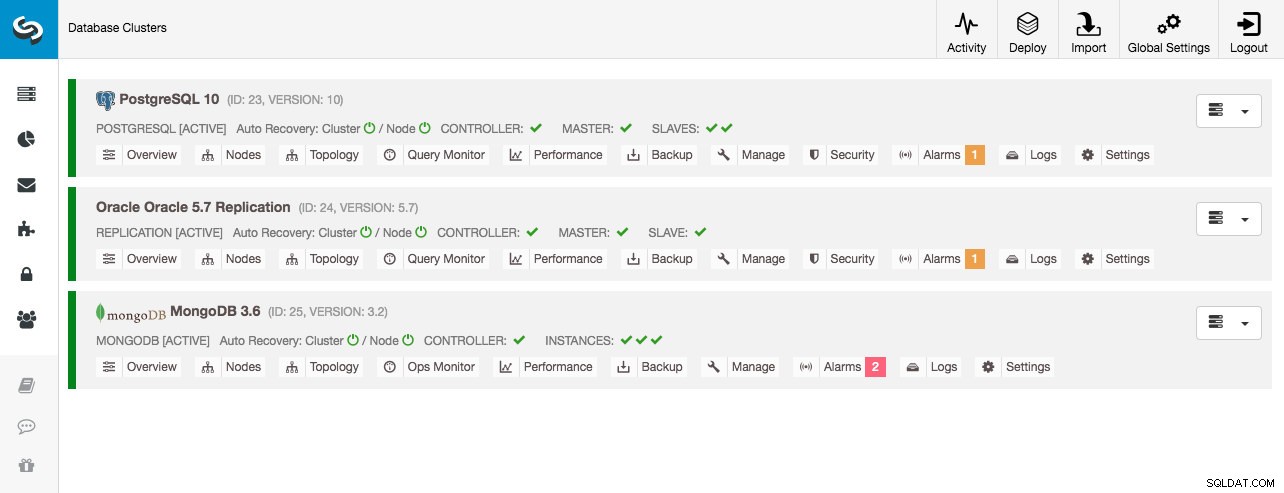
Klyngeovervågning
Vi starter med at liste klyngerne:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
23 STARTED postgresql_single system admins PostgreSQL 10 All nodes are operational.
24 STARTED replication system admins Oracle 5.7 Replication All nodes are operational.
25 STARTED mongodb system admins MongoDB 3.6 All nodes are operational.Vi ser de samme klynger som brugergrænsefladen. Vi kan få flere detaljer om den bestemte klynge ved at bruge --stat-flaget. Flere klynger og noder kan også overvåges på denne måde, kommandolinjeindstillingerne kan endda bruge jokertegn i node- og klyngenavnene:
$ s9s cluster --stat *Replication
Oracle 5.7 Replication Name: Oracle 5.7 Replication Owner: system/admins
ID: 24 State: STARTED
Type: REPLICATION Vendor: oracle 5.7
Status: All nodes are operational.
Alarms: 0 crit 1 warn
Jobs: 0 abort 0 defnd 0 dequd 0 faild 7 finsd 0 runng
Config: '/etc/cmon.d/cmon_24.cnf'
LogFile: '/var/log/cmon_24.log'
HOSTNAME CPU MEMORY SWAP DISK NICs
10.0.0.104 1 6% 992M 120M 0B 0B 19G 13G 10K/s 54K/s
10.0.0.168 1 6% 992M 116M 0B 0B 19G 13G 11K/s 66K/s
10.0.0.156 2 39% 3.6G 2.4G 0B 0B 19G 3.3G 338K/s 79K/sOutputtet ovenfor giver en oversigt over vores MySQL-replikering sammen med klyngestatus, tilstand, leverandør, konfigurationsfil og så videre. Nede i linjen kan du se listen over noder, der falder ind under dette klynge-id med en opsummeret visning af systemressourcer for hver vært, såsom antal CPU'er, samlet hukommelse, hukommelsesforbrug, swap-disk og netværksgrænseflader. Alle viste oplysninger hentes fra CMON-databasen, ikke direkte fra de faktiske noder.
Du kan også få en opsummeret visning af alle databaser på alle klynger:
$ s9s cluster --list-databases --long
SIZE #TBL #ROWS OWNER GROUP CLUSTER DATABASE
7,340,032 0 0 system admins PostgreSQL 10 postgres
7,340,032 0 0 system admins PostgreSQL 10 template1
7,340,032 0 0 system admins PostgreSQL 10 template0
765,460,480 24 2,399,611 system admins PostgreSQL 10 sbtest
0 101 - system admins Oracle 5.7 Replication sys
Total: 5 databases, 789,577,728, 125 tables.Den sidste linje opsummerer, at vi har i alt 5 databaser med 125 tabeller, 4 af dem er på vores PostgreSQL-klynge.
For et komplet eksempel på brug af s9s cluster kommandolinjeindstillinger, se s9s cluster dokumentation.
Knudeovervågning
Til nodeovervågning har s9s CLI lignende funktioner med klyngeindstillingen. For at få en opsummeret visning af alle noder kan du blot gøre:
$ s9s node --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.6.2.2662 23 PostgreSQL 10 10.0.0.156 9500 Up and running
poM- 10.4 23 PostgreSQL 10 10.0.0.44 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.58 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.60 5432 Up and running
soS- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.104 3306 Up and running.
coC- 1.6.2.2662 24 Oracle 5.7 Replication 10.0.0.156 9500 Up and running
soM- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.168 3306 Up and running.
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.125 27017 Up and Running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.131 27017 Up and Running
coC- 1.6.2.2662 25 MongoDB 3.6 10.0.0.156 9500 Up and running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.35 27017 Up and Running
Total: 11Kolonnen længst til venstre angiver nodens type. For denne implementering repræsenterer "c" ClusterControl Controller, "p" for PostgreSQL, "m" for MongoDB, "e" for Memcached og s for generiske MySQL-noder. Den næste er værtsstatus - "o" for online, " l" for off-line, "f" for mislykkede noder og så videre. Den næste er rollen for noden i klyngen. Det kan være M for master, S for slave, C for controller og - for alt andet. De resterende kolonner er ret selvforklarende.
Du kan få hele listen ved at se på man-siden for denne komponent:
$ man s9s-nodeDerfra kan vi hoppe ind i en mere detaljeret statistik for alle noder med --stats flag:
$ s9s node --stat --cluster-id=24
10.0.0.104:3306
Name: 10.0.0.104 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.104 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: slave
OS: centos 7.0.1406 core Access: read-only
VM ID: -
Version: 5.7.23-log
Message: Up and running.
LastSeen: Just now SSH: 0 fail(s)
Connect: y Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 16592 Uptime: 01:44:38
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.168:3306
Name: 10.0.0.168 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.168 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: master
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 5.7.23-log
Message: Up and running.
Slaves: 10.0.0.104:3306
LastSeen: Just now SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 975 Uptime: 01:52:53
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.156:9500
Name: 10.0.0.156 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.156 Port: 9500
Alias: - Owner: system/admins
Class: CmonHost Type: controller
Status: CmonHostOnline Role: controller
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 1.6.2.2662
Message: Up and running
LastSeen: 28 seconds ago SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: n SuperReadOnly: n
Pid: 12746 Uptime: 01:10:05
Config: ''
LogFile: '/var/log/cmon_24.log'
PidFile: ''
DataDir: ''Udskrivning af grafer med s9s-klienten kan også være meget informativt. Dette præsenterer de data, den registeransvarlige har indsamlet i forskellige grafer. Der er næsten 30 grafer, der understøttes af dette værktøj som anført her, og s9s-node opregner dem alle. Det følgende viser serverbelastningshistogram for alle noder for klynge-ID 1 som indsamlet af CMON, lige fra din terminal:
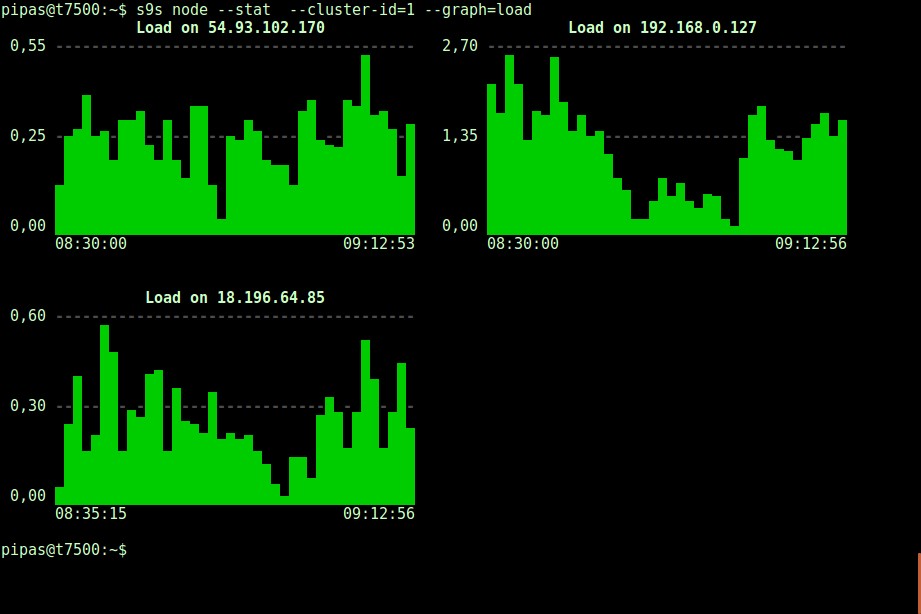
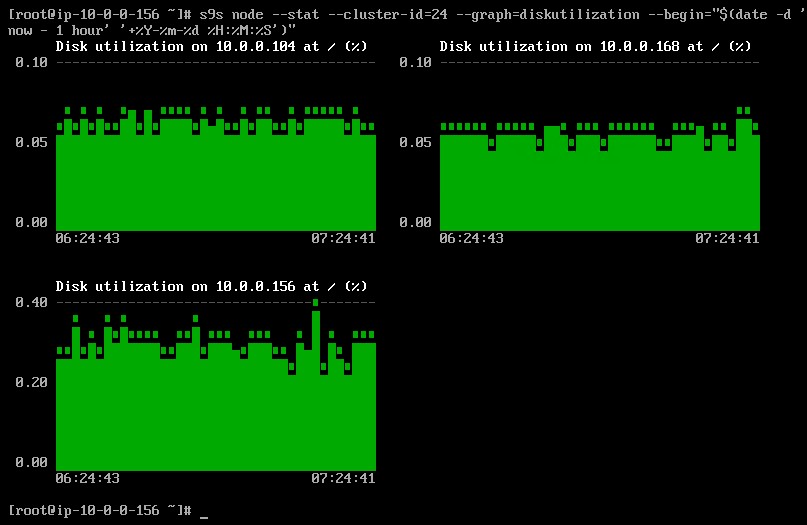
Det er muligt at indstille start- og slutdato og klokkeslæt. Man kan se korte perioder (som den sidste time) eller længere perioder (som en uge eller en måned). Følgende er et eksempel på visning af diskudnyttelsen for den sidste time:
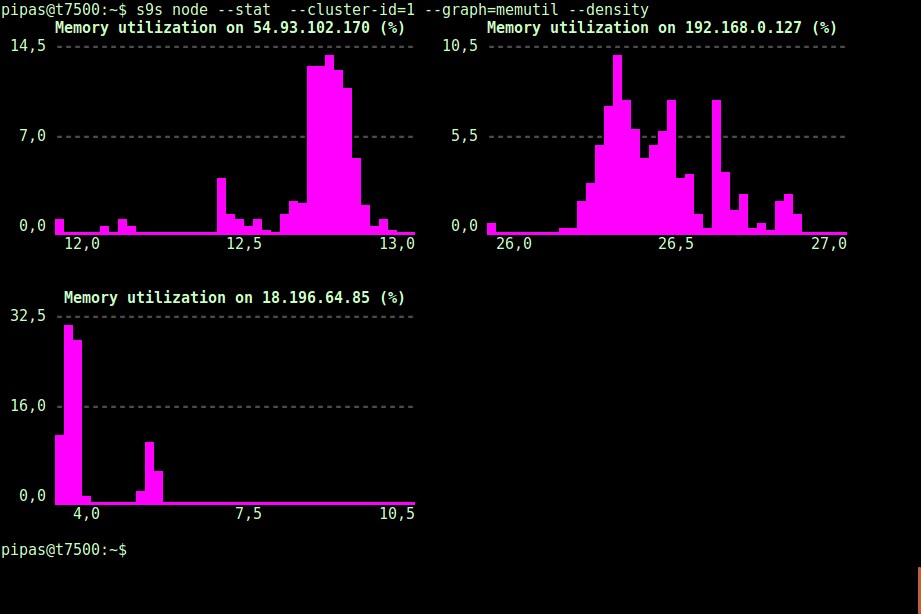
Ved at bruge --density-indstillingen kan en anden visning udskrives for hver graf. Denne tæthedsgraf viser ikke tidsserien, men hvor ofte de givne værdier blev set (X-aksen repræsenterer tæthedsværdien):
Hvis terminalen ikke understøtter Unicode-tegn, kan --only-ascii-indstillingen slå dem fra:
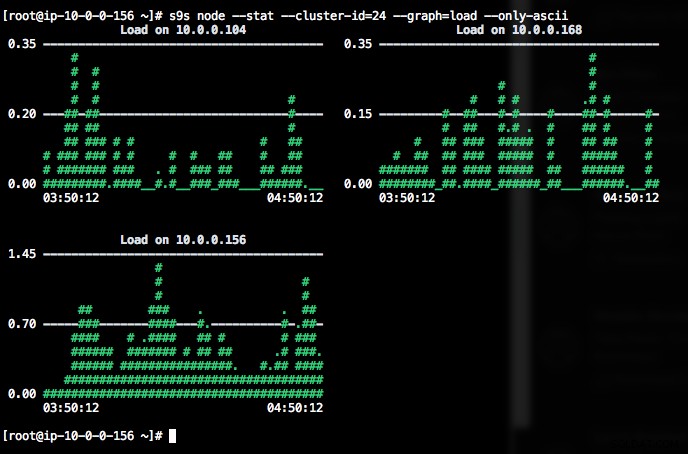
Graferne har farver, hvor farligt høje værdier for eksempel er vist med rødt. Listen over noder kan filtreres med --nodes mulighed, hvor du kan angive nodenavne eller bruge jokertegn, hvis det er praktisk.
Procesovervågning
En anden cool ting ved s9s CLI er, at den giver en procesliste over hele klyngen - en "top" for alle noder, alle processer slået sammen til én. Følgende kommando kører "top"-kommandoen på alle databasenoder for klynge-ID 24, sorteret efter det største CPU-forbrug og opdateret løbende:
$ s9s process --top --cluster-id=24
Oracle 5.7 Replication - 04:39:17 All nodes are operational.
3 hosts, 4 cores, 10.6 us, 4.2 sy, 84.6 id, 0.1 wa, 0.3 st,
GiB Mem : 5.5 total, 1.7 free, 2.6 used, 0.1 buffers, 1.1 cached
GiB Swap: 0 total, 0 used, 0 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
12746 root 10.0.0.156 20 1359348 58976 S 25.25 1.56 cmon
1587 apache 10.0.0.156 20 462572 21632 S 1.38 0.57 httpd
390 root 10.0.0.156 20 4356 584 S 1.32 0.02 rngd
975 mysql 10.0.0.168 20 1144260 71936 S 1.11 7.08 mysqld
16592 mysql 10.0.0.104 20 1144808 75976 S 1.11 7.48 mysqld
22983 root 10.0.0.104 20 127368 5308 S 0.92 0.52 sshd
22548 root 10.0.0.168 20 127368 5304 S 0.83 0.52 sshd
1632 mysql 10.0.0.156 20 3578232 1803336 S 0.50 47.65 mysqld
470 proxysql 10.0.0.156 20 167956 35300 S 0.44 0.93 proxysql
338 root 10.0.0.104 20 4304 600 S 0.37 0.06 rngd
351 root 10.0.0.168 20 4304 600 R 0.28 0.06 rngd
24 root 10.0.0.156 20 0 0 S 0.19 0.00 rcu_sched
785 root 10.0.0.156 20 454112 11092 S 0.13 0.29 httpd
26 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/1
25 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/0
22498 root 10.0.0.168 20 127368 5200 S 0.09 0.51 sshd
14538 root 10.0.0.104 20 0 0 S 0.09 0.00 kworker/0:1
22933 root 10.0.0.104 20 127368 5200 S 0.09 0.51 sshd
28295 root 10.0.0.156 20 127452 5016 S 0.06 0.13 sshd
2238 root 10.0.0.156 20 197520 10444 S 0.06 0.28 vc-agent-007
419 root 10.0.0.156 20 34764 1660 S 0.06 0.04 systemd-logind
1 root 10.0.0.156 20 47628 3560 S 0.06 0.09 systemd
27992 proxysql 10.0.0.156 20 11688 872 S 0.00 0.02 proxysql_galera
28036 proxysql 10.0.0.156 20 11688 876 S 0.00 0.02 proxysql_galeraDer er også et --list flag, som returnerer et lignende resultat uden kontinuerlig opdatering (svarende til "ps" kommando):
$ s9s process --list --cluster-id=25Jobovervågning
Jobs er opgaver, der udføres af controlleren i baggrunden, så klientapplikationen ikke behøver at vente, indtil hele jobbet er færdigt. ClusterControl udfører administrationsopgaver ved at tildele et ID for hver opgave og lader den interne planlægger bestemme, om to eller flere job kan køres parallelt. For eksempel kan mere end én klyngeimplementering udføres samtidigt, såvel som andre langvarige operationer som sikkerhedskopiering og automatisk upload af sikkerhedskopier til skylager.
I enhver administrationsoperation ville det være nyttigt, hvis vi kunne overvåge fremskridt og status for et specifikt job, som f.eks. skalere en ny slave til vores MySQL-replikering. Følgende kommando tilføjer en ny slave, 10.0.0.77 for at udskalere vores MySQL-replikering:
$ s9s cluster --add-node --nodes="10.0.0.77" --cluster-id=24
Job with ID 66992 registered.Vi kan derefter overvåge jobID 66992 ved hjælp af jobindstillingen:
$ s9s job --log --job-id=66992
addNode: Verifying job parameters.
10.0.0.77:3306: Adding host to cluster.
10.0.0.77:3306: Testing SSH to host.
10.0.0.77:3306: Installing node.
10.0.0.77:3306: Setup new node (installSoftware = true).
10.0.0.77:3306: Setting SELinux in permissive mode.
10.0.0.77:3306: Disabling firewall.
10.0.0.77:3306: Setting vm.swappiness = 1
10.0.0.77:3306: Installing software.
10.0.0.77:3306: Setting up repositories.
10.0.0.77:3306: Installing helper packages.
10.0.0.77: Upgrading nss.
10.0.0.77: Upgrading ca-certificates.
10.0.0.77: Installing socat.
...
10.0.0.77: Installing pigz.
10.0.0.77: Installing bzip2.
10.0.0.77: Installing iproute2.
10.0.0.77: Installing tar.
10.0.0.77: Installing openssl.
10.0.0.77: Upgrading openssl openssl-libs.
10.0.0.77: Finished with helper packages.
10.0.0.77:3306: Verifying helper packages (checking if socat is installed successfully).
10.0.0.77:3306: Uninstalling existing MySQL packages.
10.0.0.77:3306: Installing replication software, vendor oracle, version 5.7.
10.0.0.77:3306: Installing software.
...Eller vi kan bruge flaget --wait og få en spinner med statuslinje:
$ s9s job --wait --job-id=66992
Add Node to Cluster
- Job 66992 RUNNING [ █] ---% Add New Node to ClusterDet er det for dagens overvågningstillæg. Vi håber, at du vil give CLI en chance og få værdi ud af det. God klyngedannelse