En af de største bekymringer, når man håndterer og administrerer databaser, er dens data- og størrelseskompleksitet. Ofte bliver organisationer bekymrede over, hvordan de skal håndtere vækst og styre vækstpåvirkningen, fordi databasestyringen fejler. Kompleksitet kommer med bekymringer, som ikke blev behandlet i starten og ikke blev set eller kunne overses, fordi den teknologi, der bruges i øjeblikket, skal være i stand til at håndtere af sig selv. Håndtering af en kompleks og stor database skal planlægges i overensstemmelse hermed, især når den type data, du administrerer eller håndterer, forventes at vokse massivt enten forventet eller på en uforudsigelig måde. Hovedmålet med planlægningen er at undgå uønskede katastrofer, eller skal vi sige undgå at gå op i røg! I denne blog vil vi dække, hvordan man effektivt administrerer store databaser.
Datastørrelse betyder noget
Størrelsen af databasen har betydning, da den har indflydelse på ydeevnen og dens styringsmetodologi. Hvordan dataene behandles og opbevares, vil bidrage til, hvordan databasen vil blive styret, hvilket gælder både i transit og hvilende data. For mange store organisationer er data guld, og vækst i data kan have en drastisk ændring i processen. Derfor er det vigtigt at have forudgående planer for at håndtere voksende data i en database.
I min erfaring med at arbejde med databaser har jeg set kunder have problemer med at håndtere ydeevnestraffe og håndtere ekstrem datavækst. Spørgsmål opstår, om man skal normalisere tabellerne eller denormalisere tabellerne.
Normalisering af tabeller
Normalisering af tabeller bevarer dataintegriteten, reducerer redundans og gør det nemt at organisere dataene på en mere effektiv måde at administrere, analysere og udtrække. Arbejde med normaliserede tabeller giver effektivitet, især når man analyserer datastrømmen og henter data enten ved hjælp af SQL-sætninger eller arbejder med programmeringssprog som C/C++, Java, Go, Ruby, PHP eller Python-grænseflader med MySQL-forbindelserne.
Selvom bekymringer med normaliserede tabeller har ydeevnestraffe og kan bremse forespørgslerne på grund af serier af joinforbindelser, når dataene hentes. Mens denormaliserede tabeller, alt hvad du skal overveje for optimering, afhænger af indekset eller den primære nøgle til at gemme data i bufferen for hurtigere hentning end at udføre flere disksøgninger. Denormaliserede tabeller kræver ingen joinforbindelser, men det ofrer dataintegriteten, og databasestørrelsen har tendens til at blive større og større.
Når din database er stor, overvej at have en DDL (Data Definition Language) til din databasetabel i MySQL/MariaDB. Tilføjelse af en primær eller unik nøgle til din tabel kræver en tabelgenopbygning. Ændring af en kolonnedatatype kræver også en tabelgenopbygning, da den gældende algoritme kun er ALGORITHM=COPY.
Hvis du gør dette i dit produktionsmiljø, kan det være udfordrende. Fordoble udfordringen, hvis dit bord er stort. Forestil dig en million eller en milliard antal rækker. Du kan ikke anvende en ALTER TABLE-sætning direkte på din tabel. Det kan blokere al indgående trafik, der skal have adgang til den tabel, du bruger DDL i øjeblikket. Dette kan dog afbødes ved at bruge pt-online-schema-change eller den store gh-ost. Ikke desto mindre kræver det overvågning og vedligeholdelse, mens du udfører processen med DDL.
Sharding og partitionering
Med sharding og partitionering hjælper det med at adskille eller segmentere dataene i henhold til deres logiske identitet. For eksempel ved at adskille baseret på dato, alfabetisk rækkefølge, land, stat eller primær nøgle baseret på det givne interval. Dette hjælper din databasestørrelse til at være overskuelig. Hold din databasestørrelse op til dens grænse, så den er håndterbar for din organisation og dit team. Let at skalere, hvis det er nødvendigt eller let at administrere, især når en katastrofe opstår.
Når vi siger håndterbar, skal du også overveje kapacitetsressourcerne på din server og også dit ingeniørteam. Du kan ikke arbejde med store og store data med få ingeniører. At arbejde med big data såsom 1000 databaser med et stort antal datasæt kræver et enormt tidsforbrug. Færdigheder og ekspertise er et must. Hvis omkostningerne er et problem, er det det tidspunkt, hvor du kan udnytte tredjepartstjenester, der tilbyder administrerede tjenester eller betalt rådgivning eller support til et sådant ingeniørarbejde, der skal imødekommes.
Tegnsæt og sortering
Tegnsæt og sorteringer påvirker datalagring og ydeevne, især på det givne tegnsæt og de valgte sorteringer. Hvert tegnsæt og samlinger har sit formål og kræver for det meste forskellige længder. Hvis du har tabeller, der kræver andre tegnsæt og sorteringer på grund af tegnkodning, skal dataene lagres og behandles til din database og tabeller eller endda med kolonner.
Dette påvirker, hvordan du administrerer din database effektivt. Det påvirker din datalagring og ydeevne som tidligere nævnt. Hvis du har forstået den slags tegn, der skal behandles af din ansøgning, skal du notere dig det tegnsæt og de sorteringer, der skal bruges. LATIN-typer af tegnsæt skal for det meste være tilstrækkelige til, at den alfanumeriske type af tegn kan lagres og behandles.
Hvis det er uundgåeligt, hjælper sharding og partitionering i det mindste med at afbøde og begrænse dataene for at undgå at svulme for mange data i din databaseserver. Håndtering af meget store data på en enkelt databaseserver kan påvirke effektiviteten, især til sikkerhedskopieringsformål, katastrofe og gendannelse eller datagendannelse i tilfælde af datakorruption eller tab af data.
Databasekompleksitet påvirker ydeevnen
En stor og kompleks database har en tendens til at have en faktor, når det kommer til præstationsstraf. Kompleks betyder i dette tilfælde, at indholdet af din database består af matematiske ligninger, koordinater eller numeriske og økonomiske poster. Blandede nu disse poster med forespørgsler, der aggressivt bruger de matematiske funktioner, der er hjemmehørende i dens database. Tag et kig på SQL-eksemplet (MySQL/MariaDB-kompatibel) forespørgsel nedenfor,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Tænk på, at denne forespørgsel anvendes på en tabel, der spænder fra en million rækker. Der er en enorm mulighed for, at dette kan stoppe serveren, og det kan være ressourcekrævende og forårsage fare for stabiliteten af din produktionsdatabaseklynge. Involverede kolonner har en tendens til at blive indekseret for at optimere og gøre denne forespørgsel effektiv. Men tilføjelse af indekser til de refererede kolonner for optimal ydeevne garanterer ikke effektiviteten af at administrere dine store databaser.
Når man håndterer kompleksitet, er den mere effektive måde at undgå streng brug af komplekse matematiske ligninger og aggressiv brug af denne indbyggede komplekse beregningsevne. Dette kan betjenes og transporteres gennem komplekse beregninger ved hjælp af backend-programmeringssprog i stedet for at bruge databasen. Hvis du har komplekse beregninger, hvorfor så ikke gemme disse ligninger i databasen, hente forespørgslerne, organisere dem til en lettere at analysere eller fejlfinde, når det er nødvendigt.
Bruger du den rigtige databasemaskine?
En datastruktur påvirker databaseserverens ydeevne baseret på kombinationen af den angivne forespørgsel og de poster, der læses eller hentes fra tabellen. Databasemotorerne i MySQL/MariaDB understøtter InnoDB og MyISAM, som bruger B-Trees, mens NDB- eller Memory-databasemotorer bruger Hash Mapping. Disse datastrukturer har sin asymptotiske notation, som sidstnævnte udtrykker ydeevnen af de algoritmer, der bruges af disse datastrukturer. Vi kalder disse i datalogi som Big O notation, der beskriver ydeevnen eller kompleksiteten af en algoritme. Da InnoDB og MyISAM bruger B-Trees, bruger den O(log n) til søgning. Hvorimod Hash Tables eller Hash Maps bruger O(n). Begge deler gennemsnittet og det værste tilfælde for dets ydeevne med dets notation.
Nu tilbage på den specifikke motor, givet motorens datastruktur, påvirker forespørgslen, der skal anvendes baseret på de måldata, der skal hentes, naturligvis ydeevnen af din databaseserver. Hash-tabeller kan ikke udføre rækkeviddehentning, hvorimod B-Trees er meget effektiv til at udføre disse typer søgninger, og den kan også håndtere store mængder data.
Ved at bruge den rigtige motor til de data, du gemmer, skal du identificere, hvilken type forespørgsel du anvender for disse specifikke data, du gemmer. Hvilken type logik skal disse data formulere, når de forvandles til en forretningslogik.
Hvis du håndterer tusindvis af eller tusindvis af databaser, skal du bruge den rigtige motor i kombination af dine forespørgsler og data, som du vil hente og gemme, til at levere god ydeevne. Givet at du har forudbestemt og analyseret dine krav til dets formål for det rigtige databasemiljø.
rigtige værktøjer til at administrere store databaser
Det er meget svært og svært at administrere en meget stor database uden en solid platform, som du kan stole på. Selv med gode og dygtige databaseingeniører er den databaseserver, du bruger, teknisk set tilbøjelig til menneskelige fejl. En fejl ved enhver ændring af dine konfigurationsparametre og variabler kan resultere i en drastisk ændring, der forårsager forringelse af serverens ydeevne.
At udføre backup til din database på en meget stor database kan til tider være udfordrende. Der er tilfælde, hvor sikkerhedskopiering kan mislykkes af nogle mærkelige årsager. Forespørgsler, der kan stoppe serveren, hvor sikkerhedskopien kører, forårsager almindeligvis fejl. Ellers skal du undersøge årsagen til det.
Brug af automatisering såsom Chef, Puppet, Ansible, Terraform eller SaltStack kan bruges som din IaC for at give hurtigere opgaver at udføre. Mens du også bruger andre tredjepartsværktøjer til at hjælpe dig med at overvåge og levere grafbilleder af høj kvalitet. Alarm- og alarmmeddelelsessystemer er også meget vigtige for at give dig besked om problemer, der kan opstå fra advarsel til kritisk statusniveau. Det er her ClusterControl er meget nyttig i denne slags situationer.
ClusterControl gør det nemt at administrere et stort antal databaser eller endda med opdelte typer miljøer. Det er blevet testet og installeret tusinde gange og har kørt ind i produktioner, der giver alarmer og meddelelser til DBA'er, ingeniører eller DevOp'er, der driver databasemiljøet. Lige fra iscenesættelse eller udvikling, QA'er, til produktionsmiljø.
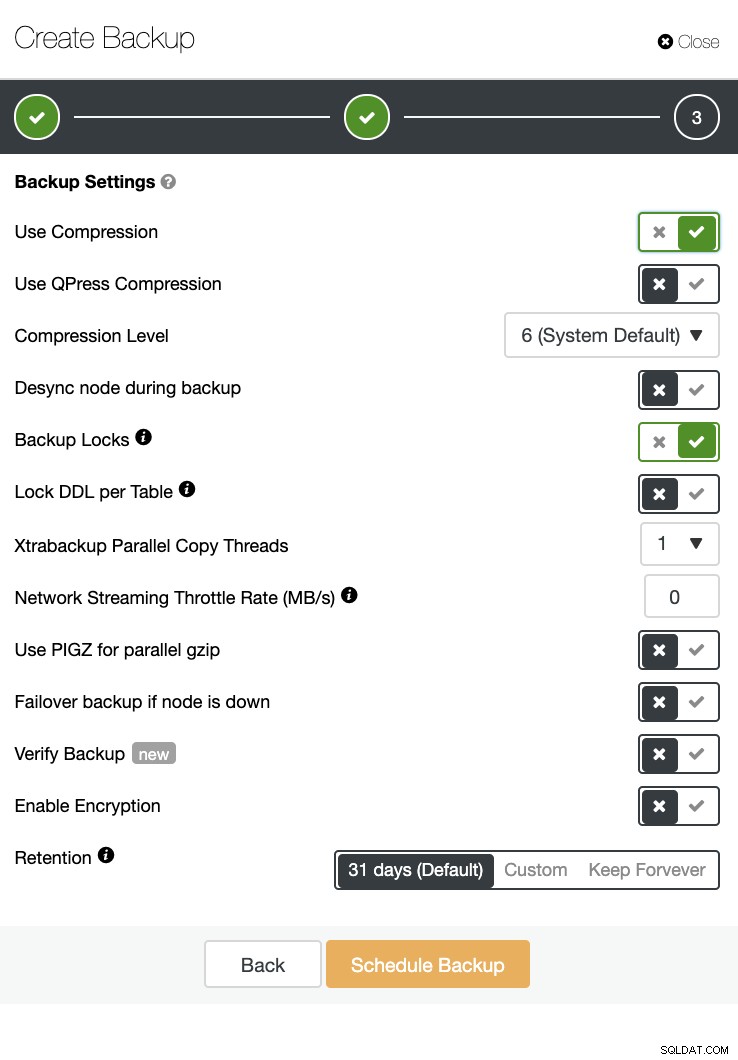
ClusterControl kan også udføre en sikkerhedskopiering og gendannelse. Selv med store databaser kan det være effektivt og nemt at administrere, da brugergrænsefladen giver planlægning og også har muligheder for at uploade den til skyen (AWS, Google Cloud og Azure).
Der er også en sikkerhedskopibekræftelse og en masse muligheder såsom kryptering og komprimering. Se for eksempel skærmbilledet nedenfor (oprettelse af en sikkerhedskopi til MySQL ved hjælp af Xtrabackup):
Konklusion
Håndtering af store databaser som tusinde eller flere kan gøres effektivt, men det skal bestemmes og forberedes på forhånd. Det hjælper drastisk at bruge de rigtige værktøjer såsom automatisering eller endda abonnere på administrerede tjenester. Selvom det medfører omkostninger, kan vendingen af den service og det budget, der skal bruges til at anskaffe dygtige ingeniører, reduceres, så længe de rigtige værktøjer er tilgængelige.