Få et overblik over de tilgængelige mekanismer til sikkerhedskopiering af data gemt i Apache HBase, og hvordan du gendanner disse data i tilfælde af forskellige datagendannelse/failover-scenarier
Med øget indførelse og integration af HBase i kritiske forretningssystemer, har mange virksomheder brug for at beskytte dette vigtige forretningsaktiv ved at udvikle robuste backup- og katastrofegendannelsesstrategier (BDR) for deres HBase-klynger. Hvor skræmmende det end kan lyde hurtigt og nemt at sikkerhedskopiere og gendanne potentielt petabytes af data, tilbyder HBase og Apache Hadoop-økosystemet mange indbyggede mekanismer til at opnå netop dette.
I dette indlæg får du et overblik på højt niveau over de tilgængelige mekanismer til sikkerhedskopiering af data gemt i HBase, og hvordan du gendanner disse data i tilfælde af forskellige datagendannelse/failover-scenarier. Efter at have læst dette indlæg, bør du være i stand til at træffe en kvalificeret beslutning om, hvilken BDR-strategi der passer bedst til dine forretningsbehov. Du bør også forstå fordele, ulemper og præstationsimplikationer af hver mekanisme. (Oplysningerne heri gælder for CDH 4.3.0/HBase 0.94.6 og nyere.)
Bemærk:I skrivende stund tilbyder Cloudera Enterprise 4 produktionsklar backup og disaster recovery funktionalitet til HDFS og Hive Metastore via Cloudera BDR 1.0 som en individuelt licenseret funktion. HBase er ikke inkluderet i denne GA-udgivelse; derfor er de forskellige mekanismer beskrevet i denne blog påkrævet. (Cloudera Enterprise 5, som i øjeblikket er i beta, tilbyder HBase snapshot-administration via Cloudera BDR.)
Sikkerhedskopi
HBase er et log-struktureret fusionstræ-distribueret datalager med komplekse interne mekanismer til at sikre datanøjagtighed, konsistens, versionering og så videre. Så hvordan i alverden kan du få en ensartet sikkerhedskopi af disse data, der ligger i en kombination af hFiles og Write-Ahead-Logs (WAL'er) på HDFS og i hukommelsen på snesevis af regionsservere?
Lad os starte med det mindst forstyrrende, mindste datafodaftryk, mindst præstationspåvirkende mekanisme og arbejde os op til det mest forstyrrende værktøj i gaffeltruckstil:
- Snapshots
- Replikering
- Eksporter
- CopyTable
- HTable API
- Offline sikkerhedskopiering af HDFS-data
Følgende tabel giver et overblik til hurtigt at sammenligne disse tilgange, som jeg vil beskrive i detaljer nedenfor.
| Ydeevnepåvirkning | Datafodaftryk | Nedetid | Inkrementelle sikkerhedskopier | Let at implementere | Mean Time To Recovery (MTTR) | |
| Snapshots | Minimal | Tiny | Kort (kun ved gendannelse) | Nej | Nemt | Sekunder |
| replikering | Minimal | Stor | Ingen | Iboende | Medium | Sekunder |
| Eksporter | Høj | Stor | Ingen | Ja | Nemt | Høj |
| CopyTable | Høj | Stor | Ingen | Ja | Nemt | Høj |
| API | Medium | Stor | Ingen | Ja | Svært | Op til dig |
| Manual | Ikke relevant | Stor | Lang | Nej | Medium | Høj |
Øjebliksbilleder
Fra og med CDH 4.3.0 er HBase-snapshots fuldt funktionelle, rige på funktioner og kræver ingen klynge-nedetid under deres oprettelse. Min kollega Matteo Bertozzi dækkede øjebliksbilleder meget godt i sit blogindlæg og efterfølgende dyb dyk. Her vil jeg kun give et overblik på højt niveau.
Snapshots fanger ganske enkelt et øjeblik til dit bord ved at skabe det, der svarer til UNIX-hardlinks til dit bords lagerfiler på HDFS (Figur 1). Disse snapshots færdiggøres på få sekunder, placerer næsten ingen ydeevne overhead på klyngen og skaber et minimalt datafodaftryk. Dine data er slet ikke duplikeret, men blot katalogiseret i små metadatafiler, hvilket gør det muligt for systemet at rulle tilbage til det tidspunkt, hvis du skulle få brug for at gendanne det øjebliksbillede.
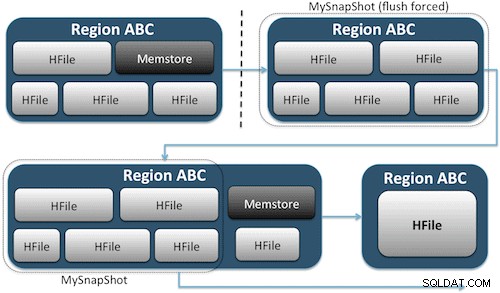
At lave et øjebliksbillede af en tabel er lige så simpelt som at køre denne kommando fra HBase-skallen:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Efter at have udstedt denne kommando, vil du finde nogle små datafiler placeret i /hbase/.snapshot/myTable (CDH4) eller /hbase/.hbase-snapshots (Apache 0.94.6.1) i HDFS, som omfatter den nødvendige information til at gendanne dit snapshot . Gendannelse er så simpelt som at udstede disse kommandoer fra skallen:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Bemærk:Som du kan se, kræver gendannelse af et snapshot et kort afbrydelse, da bordet skal være offline. Alle data, der tilføjes/opdateres, efter at det gendannede snapshot blev taget, vil gå tabt.
Hvis dine forretningskrav er sådan, at du skal have en ekstern sikkerhedskopi af dine data, kan du bruge kommandoen exportSnapshot til at duplikere en tabels data til din lokale HDFS-klynge eller en fjern-HDFS-klynge efter eget valg.
Snapshots er et fuldstændigt billede af dit bord hver gang; ingen inkrementelle snapshot-funktionalitet er i øjeblikket tilgængelig.
HBase-replikering
HBase-replikering er et andet værktøj til backup af meget lav overhead. (Min kollega Himanshu Vashishtha dækker replikering i detaljer i dette blogindlæg.) Sammenfattende kan replikering defineres på kolonnefamilieniveau, fungerer i baggrunden og holder alle redigeringer synkroniseret mellem klynger i replikeringskæden.
Replikering har tre tilstande:master->slave, master<->master og cyklisk. Denne tilgang giver dig fleksibilitet til at indtage data fra ethvert datacenter og sikrer, at det bliver replikeret på tværs af alle kopier af denne tabel i andre datacentre. I tilfælde af et katastrofalt udfald i ét datacenter kan klientapplikationer omdirigeres til en alternativ placering for dataene ved hjælp af DNS-værktøjer.
Replikering er en robust, fejltolerant proces, der giver "eventuel konsistens", hvilket betyder, at de seneste redigeringer af en tabel på et hvilket som helst tidspunkt muligvis ikke er tilgængelige i alle replikaer af den tabel, men at de med garanti kommer dertil.
Bemærk:For eksisterende tabeller skal du først manuelt kopiere kildetabellen til destinationstabellen via en af de andre måder, der er beskrevet i dette indlæg. Replikering virker kun på nye skrivninger/redigeringer, efter du har aktiveret det.

(Fra Apaches replikeringsside)
Eksporter
HBases eksportværktøj er et indbygget HBase-værktøj, der gør det nemt at eksportere data fra en HBase-tabel til almindelige SequenceFiles i en HDFS-mappe. Det opretter et MapReduce-job, der foretager en række HBase API-kald til din klynge, og én efter én, henter hver række data fra den angivne tabel og skriver disse data til din specificerede HDFS-mappe. Dette værktøj er mere præstationsintensivt for din klynge, fordi det bruger MapReduce og HBase-klient-API'et, men det er funktionsrigt og understøtter filtrering af data efter version eller datointerval – og muliggør derved trinvise sikkerhedskopier.
Her er et eksempel på kommandoen i dens enkleste form:
hbase org.apache.hadoop.hbase.mapreduce.Export
Når din tabel er eksporteret, kan du kopiere de resulterende datafiler hvor som helst du ønsker (såsom offsite/off-cluster storage). Du kan også angive en ekstern HDFS-klynge/-mappe som outputplacering for kommandoen, og Export vil direkte skrive indholdet til fjernklyngen. Bemærk venligst, at denne tilgang vil introducere et netværkselement i skrivestien til eksporten, så du bør bekræfte, at din netværksforbindelse til fjernklyngen er pålidelig og hurtig.
CopyTable
CopyTable-værktøjet er dækket godt i Jon Hsiehs blogindlæg, men jeg vil opsummere det grundlæggende her. I lighed med Export opretter CopyTable et MapReduce-job, der bruger HBase API til at læse fra en kildetabel. Den vigtigste forskel er, at CopyTable skriver sit output direkte til en destinationstabel i HBase, som kan være lokal for din kildeklynge eller på en fjernklynge.
Et eksempel på den enkleste form for kommandoen er:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Denne kommando vil kopiere indholdet af en tabel med navnet "test" til en tabel i den samme klynge med navnet "testCopy."
Bemærk, at der er en betydelig ydeevne overhead til CopyTable, idet den bruger individuelle "puts" til at skrive dataene, række for række, ind i destinationstabellen. Hvis din tabel er meget stor, kan CopyTable få memstore på destinationsregionsserverne til at fylde op, hvilket kræver memstore flushes, som i sidste ende vil føre til komprimeringer, affaldsopsamling og så videre.
Derudover skal du tage højde for præstationsimplikationerne ved at køre MapReduce over HBase. Med store datasæt er den tilgang måske ikke ideel.
HTable API (såsom en tilpasset Java-applikation)
Som det altid er tilfældet med Hadoop, kan du altid skrive din egen brugerdefinerede applikation, der bruger den offentlige API og forespørger direkte i tabellen. Du kan gøre dette gennem MapReduce-job for at udnytte denne rammes fordele ved distribueret batchbehandling eller gennem andre måder, du selv har designet. Denne tilgang kræver dog en dyb forståelse af Hadoop-udvikling og alle API'er og præstationsimplikationer ved at bruge dem i din produktionsklynge.
Offline sikkerhedskopiering af rå HDFS-data
Den mest brute-force backup-mekanisme - også den mest forstyrrende - involverer det største datafodaftryk. Du kan lukke din HBase-klynge helt ned og manuelt kopiere alle data- og mappestrukturer, der findes i /hbase i din HDFS-klynge. Da HBase er nede, vil det sikre, at alle data er blevet overført til HFiles i HDFS, og du vil få en nøjagtig kopi af dataene. Inkrementelle sikkerhedskopier vil dog være næsten umulige at opnå, da du ikke vil være i stand til at fastslå, hvilke data der er ændret eller tilføjet, når du forsøger fremtidige sikkerhedskopier.
Det er også vigtigt at bemærke, at gendannelse af dine data vil kræve en offline meta reparation, fordi .META. tabel ville indeholde potentielt ugyldige oplysninger på tidspunktet for gendannelse. Denne tilgang kræver også et hurtigt pålideligt netværk til at overføre dataene offsite og gendanne dem senere, hvis det er nødvendigt.
Af disse grunde fraråder Cloudera denne tilgang til HBase-sikkerhedskopier.
Katastrofegendannelse
HBase er designet til at være et ekstremt fejltolerant distribueret system med indbygget redundans, forudsat at hardware ofte fejler. Disaster recovery i HBase kommer normalt i flere former:
- Katastrofale fejl på datacenterniveau, der kræver failover til en sikkerhedskopi
- Behov for at gendanne en tidligere kopi af dine data på grund af brugerfejl eller utilsigtet sletning
- Muligheden for at gendanne en punkt-i-tidskopi af dine data til revisionsformål
Som med enhver katastrofegenopretningsplan vil forretningskravene styre, hvordan planen er opbygget, og hvor mange penge der skal investeres i den. Når du har etableret sikkerhedskopierne efter eget valg, antager gendannelsen forskellige former afhængigt af den nødvendige gendannelsestype:
- Failover til backup-klynge
- Importér tabel/gendan et øjebliksbillede
- Peg HBase-rodmappen til sikkerhedskopieringsplaceringen
Hvis din backupstrategi er sådan, at du har replikeret dine HBase-data til en backup-klynge i et andet datacenter, er det lige så nemt at fejle som at pege dine slutbrugerapplikationer til backup-klyngen med DNS-teknikker.
Husk dog, at hvis du planlægger at tillade, at data bliver skrevet til din backup-klynge under udfaldsperioden, skal du sørge for, at data kommer tilbage til den primære klynge, når udfaldet er overstået. Master-til-master eller cyklisk replikering vil håndtere denne proces automatisk for dig, men et master-slave-replikeringsskema vil efterlade din master-klynge ude af synkronisering, hvilket kræver manuel indgriben efter udfaldet.
Sammen med den tidligere beskrevne eksportfunktion er der et tilsvarende importværktøj, der kan tage de data, der tidligere er sikkerhedskopieret af Export, og gendanne dem til en HBase-tabel. De samme præstationsimplikationer, som gjaldt for eksport, er også i spil med Import. Hvis dit sikkerhedskopieringsskema involverede at tage snapshots, er det lige så enkelt at vende tilbage til en tidligere kopi af dine data som at gendanne det øjebliksbillede.
Du kan også komme dig efter en katastrofe ved blot at ændre egenskaben hbase.root.dir i hbase-site.xml og pege den til en sikkerhedskopi af din /hbase-mappe, hvis du havde lavet brute-force offline-kopien af HDFS-datastrukturerne . Dette er dog også den mindst ønskværdige af gendannelsesmuligheder, da det kræver et længere udfald, mens du kopierer hele datastrukturen tilbage til din produktionsklynge, og som tidligere nævnt, .META. kan være ude af synkronisering.
Konklusion
Sammenfattende kræver gendannelse af data efter en form for tab eller udfald en veldesignet BDR-plan. Jeg anbefaler stærkt, at du grundigt forstår dine forretningskrav til oppetid, datanøjagtighed/tilgængelighed og gendannelse efter katastrofer. Bevæbnet med detaljeret viden om dine forretningskrav kan du omhyggeligt vælge de værktøjer, der bedst opfylder disse behov.
Valg af værktøjer er dog kun begyndelsen. Du bør køre storstilet test af din BDR-strategi for at sikre, at den fungerer funktionelt i din infrastruktur, opfylder dine forretningsbehov, og at dine driftsteams er meget fortrolige med de trin, der kræves, før et afbrydelse sker, og du finder ud af på den hårde måde, at din BDR-plan virker ikke.
Hvis du gerne vil kommentere eller diskutere dette emne yderligere, så brug vores fællesskabsforum for HBase.
Yderligere læsning:
- Jon Hsiehs Strata + Hadoop World 2012-præsentation
- HBase:The Definitive Guide (Lars George)
- HBase i aktion (Nick Dimiduk/Amandeep Khurana)