I denne Hadoop tutorial til , Vi kommer til at give dig en komplet introduktion til MapReduce Key Value Par.
Først og fremmest vil vi diskutere, hvad der er en vigtig værdi par i Hadoop, Hvor afgørende værdi par genereres i MapReduce. Omsider vil vi forklare MapReduce nøgleværdi par generation med eksempler.
Hvad er Key Value Pair i Hadoop?
Nøgle-værdi par i MapReduce er den rekord enhed, der Hadoop MapReduce accepterer til udførelse.
Vi bruger Hadoop primært til dataanalyse. Det beskæftiger sig med strukturerede, ustrukturerede og semistrukturerede data. Med Hadoop, hvis skemaet er statisk, kan vi direkte arbejde på kolonnen i stedet for centrale værdi. Men, hvis skemaet er ikke statisk, vi vil arbejde på en tast værdi.
Nøgler værdi er ikke iboende egenskaber dataene. Men de er valgt af brugeren at analysere data.
MapReduce er det vigtigste element i Hadoop, som tilvejebringer databehandling. Det udfører bearbejdning ved at bryde jobbet ved i to faser: Kort fase og Reducer fase . Hver fase har nøgleværdi som input og output.
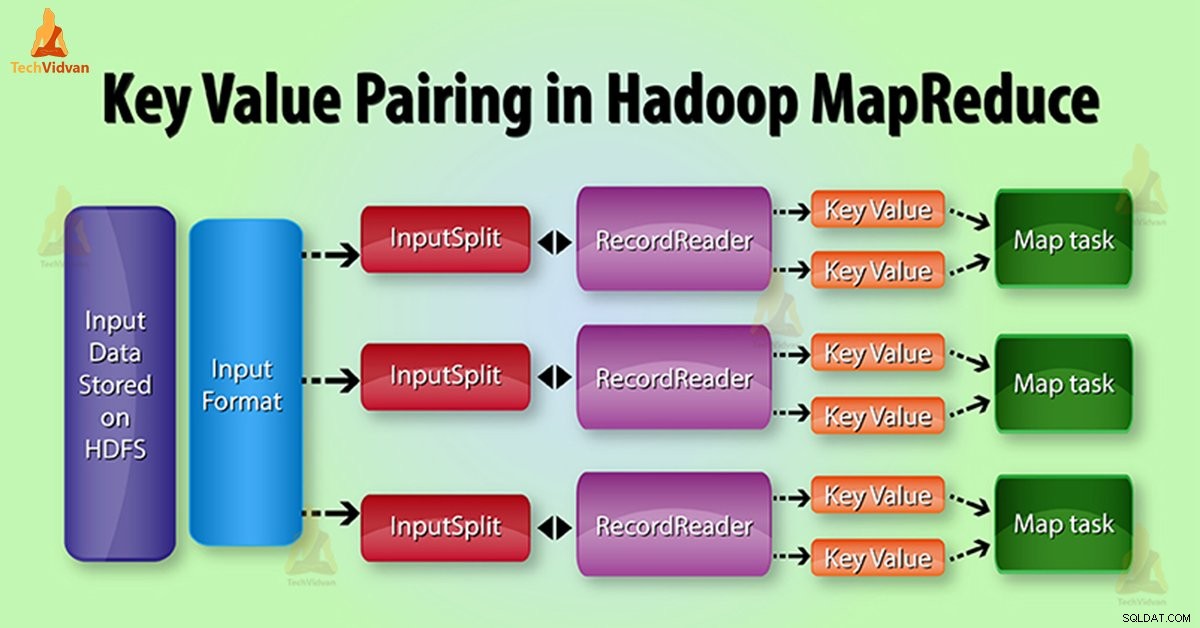
MapReduce Key værdi pair generation i Hadoop
I MapReduce job udførelse, før du sender data til Mapper , Først konvertere det til nøgleværdipar. Fordi mapper kun nøgleværdipar af data.
Nøgle-værdi par i MapReduce genereres som følger:
InputSplit - Det er den logiske repræsentation af data, som InputFormat genererer. I MapReduce program, det beskriver en enhed af arbejde, der indeholder en enkelt kort opgave.
RecordReader - Den kommunikerer med InputSplit. Efter at det konverterer dataene i Nøgleværdiparrene egnede til læsning ved Mapper. RecordReader som standard anvendelser TextInputFormat at konvertere data i centrale værdi par.
I MapReduce job udførelse, den kortfunktion behandler en bestemt nøgleværdiparret. Så udsender et vist antal nøgleværdipar. Den Reducer funktionen behandler værdierne grupperet efter den samme nøgle.
Så udsender et andet sæt af nøgleværdipar som output. MAP output typer skal matche input typer af Reduce som vist nedenfor:
- Kort: (K1, V1) -> liste (K2, V2)
- Reducer: {(K2, liste (V2}) -> liste (K3, V3)
På hvilket grundlag er en nøgleværdiparret genereret i Hadoop
MapReduce nøgleværdiparret generation helt afhænger af datasættet. Også afhænger af den krævede output. Framework angiver nøgleværdipar i 4 steder:. Kort input / output, Reducer input / output
1. Kort Input
Kort Input som standard tager linieforskydningen som nøglen. Indholdet af linjen er værdi som tekst. Vi kan ændre dem; ved hjælp af brugerdefinerede input format.
2. Kort Output
Kortet er ansvarlig for at filtrere data. Det giver også miljøet at gruppere dataene på grundlag af nøglen.
- Nøgle - Det er felt / tekst / objekt, som de datagrupper og aggregater på reduktionsgear .
- Value - Det er det område / tekst / objekt, som den enkelte reducerer metode håndtag.
3. Reducere Input
Kort output er input til at reducere. Så det er samme som kort-output.
4. Reducer Udgang
Det afhænger helt af den krævede output.
MapReduce nøgleværdiparret Eksempel
For eksempel, at indholdet af den fil, som HDFS butikker er Chandler er Joey Mark er John . Så nu ved hjælp af InputFormat, vil vi definere, hvordan denne fil vil splitte og læse. Som standard RecordReader bruger TextInputFormat at konvertere denne fil til et nøgleværdiparret.
- Nøgle - Det opvejes af begyndelsen af den linje i filen.
- Value - Det er indholdet af den linje, eksklusive linje terminatorer.
Her Key er 0 og Værdi er Chandler er Joey Mark John.
Konklusion
Som konklusion kan vi sige, at, nøgle-værdi er blot en rekord enhed, der MapReduce accepterer til udførelse. InputSplit og RecordReader generere nøgleværdiparret. Derfor, det vigtigste er byte-offset og værdi er indholdet af linjen.
Håber du kunne lide denne blog. Hvis du har nogen forslag eller forespørgsel relateret til MapReduce nøgleværdi par så du efterlade en kommentar i et afsnit nedenfor.