Emnet om caching dukkede op i PostgreSQL så langt tilbage som for 22 år siden, og på det tidspunkt var fokus på databasens pålidelighed.
Spol frem til 2020, diskpladerne er skjult endnu dybere i virtualiserede miljøer, hypervisorer og tilhørende lagerenheder. Ydermere skriger indbyrdes forbundne, distribuerede applikationer, der opererer på global skala, efter forbindelser med lav latenstid og pludselig tuning af servercaches, og SQL-forespørgsler konkurrerer med at sikre, at resultaterne returneres til klienter inden for millisekunder. Applikationsniveau og in-memory caches er født, og læseforespørgsler gemmes nu tæt på applikationsserverne. Som et resultat reduceres I/O-operationer til kun at skrive, og netværksforsinkelsen er dramatisk forbedret. Med én fangst. Implementeringer er ansvarlige for deres egen cachehåndtering, hvilket nogle gange fører til ydeevneforringelse.
Caching af skrivninger er en meget mere kompliceret sag, som forklaret i PostgreSQL-wikien.
Denne blog er en oversigt over de forespørgselscaches i hukommelsen og load balancere, der bruges med PostgreSQL.
PostgreSQL-belastningsbalancering
Idéen om belastningsbalancering blev frembragt samtidig med caching, i 1999, da Bruce Momjiam skrev:
[...] det er muligt, at vi kan blive _meget_ populære i den nærmeste fremtid.
Grundlaget for implementering af belastningsbalancering i PostgreSQL er leveret af den indbyggede Hot Standby-funktion. Det eneste krav er, at applikationen håndterer failover, og det er her, tredjepartsløsninger kommer ind. Vi vil se på nogle af disse løsninger i de næste afsnit.
Load balancerede forespørgsler kan kun returnere konsistente resultater, så længe den synkrone replikeringsforsinkelse holdes lav. I praksis kan selv den nyeste netværksinfrastruktur som AWS udvise titusvis af millisekunders forsinkelser:
Vi observerer typisk forsinkelsestider i 10'erne af millisekunder. [...] Under typiske forhold er under et minuts replikationsforsinkelse dog almindelig. [...]
Replikaer på tværs af regioner, der bruger logisk replikering, vil blive påvirket af ændrings-/anvendelseshastigheden og forsinkelser i netværkskommunikation mellem de specifikke valgte regioner. Replikaer på tværs af regioner, der bruger Aurora Global Database, vil have en typisk forsinkelse på under et sekund.
Som tidligere nævnt er 3. parts løsninger afhængige af kerne PostgreSQL-funktioner. For eksempel opnås belastningsbalancering af læseforespørgsler ved hjælp af flere synkrone standbys.
Løsninger
pgpool-II
pgpool-II er et funktionsrigt produkt, der giver både belastningsbalancering og cachelagring af forespørgsler i hukommelsen. Det er en drop-in erstatning, der kræves ingen ændringer på applikationssiden.
Som belastningsbalancer undersøger pgpool-II hver SQL-forespørgsel — for at være belastningsbalanceret skal SELECT-forespørgsler opfylde flere betingelser.
Opsætningen kan være så enkel som én node, vist nedenfor er en to-node klynge:
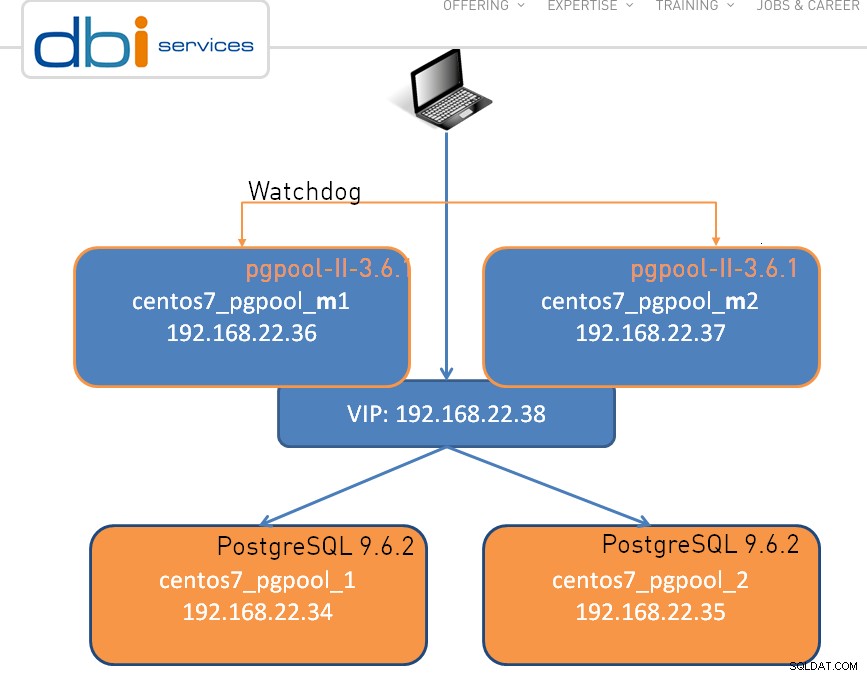
Som det er tilfældet med ethvert godt stykke software, er der visse begrænsninger , og pgpool-II gør ingen undtagelse:
- Det håndterer ikke forespørgsler med flere sætninger.
- SELECT-forespørgsler på midlertidige tabeller kræver /*NO LOAD BALANCE*/ SQL-kommentaren.
Applikationer, der kører i højtydende miljøer, vil drage fordel af en blandet konfiguration, hvor pgBouncer er forbindelsespooleren, og pgpool-II håndterer belastningsbalancering og caching. Resultatet er en imponerende stigning på 4 gange gennemløb og 40 procents latensreduktion:
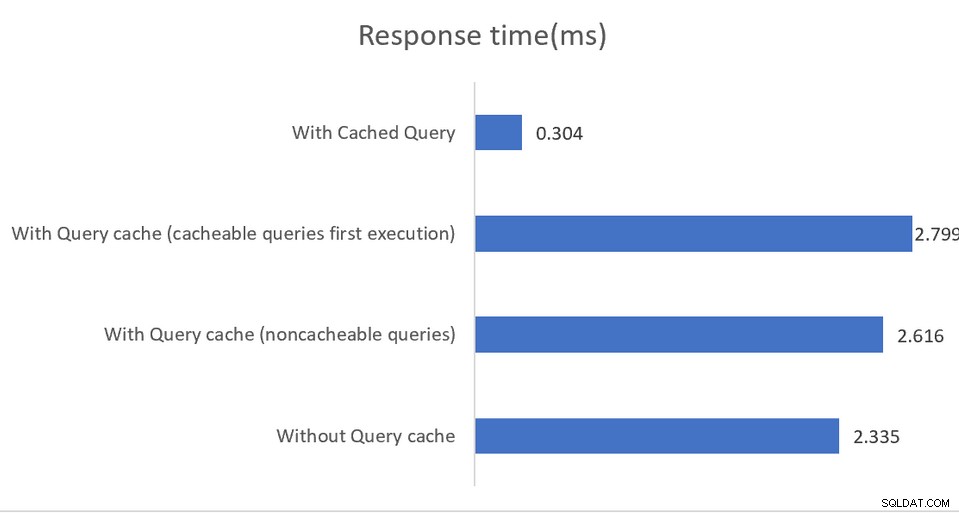
Caching i hukommelsen fungerer igen, kun på læseforespørgsler med cachelagret data gemmes enten i den delte hukommelse eller i en ekstern memcached installation. Selvom dokumentationen er ret god til at forklare de forskellige konfigurationsmuligheder, antyder den indirekte, at implementeringer skal overvåge SHOW POOL CACHE-output for at advare om hitforhold, der falder under 70 %-mærket, hvorefter den ydeevneforstærkning, som caching giver, går tabt.
Bucardo
Bucardo er et PostgreSQL-replikeringsværktøj skrevet i Perl og PL/Perl.
Jeg har nævnt Bucardo, fordi belastningsbalancering er en af dens funktioner, ifølge PostgreSQL wiki, men en internetsøgning giver ingen relevante resultater. For at præcisere gik jeg over til den officielle dokumentation, som går i detaljer om, hvordan softwaren faktisk fungerer:

Det gør det ret klart, at Bucardo ikke er en load balancer, ligesom blev peget af folk på Database Soup.
HAProxy
HAProxy er en generel load balancer, der fungerer på TCP-niveau (med henblik på databaseforbindelser). Sundhedstjek sikrer, at forespørgsler kun sendes til levende noder.
Sammenlignet med pgpool-II skal applikationer, der bruger HAProxy som en belastningsbalancer, gøres opmærksom på anmodningerne om afsendelse af slutpunkter til læserknudepunkter.
Apache Ignite
Apache Ignite er en cache på andet niveau, der forstår ANSI-99 SQL og understøtter ACID-transaktioner. Apache Ignite forstår ikke PostgreSQL Frontend/Backend-protokollen, og applikationer skal derfor bruge enten et persistenslag, såsom Hibernate ORM. Som et alternativ til ændring af applikationer giver Apache Ignite 'memcached integration'_ som kræver den memcached PostgreSQL-udvidelse. Desværre er denne sidste mulighed ikke kompatibel med nyere versioner af PostgreSQL, da pgmemcache-udvidelsen sidst blev opdateret i 2017.
Heimdall Data
Som et kommercielt produkt markerer Heimdall Data begge felter:belastningsbalancering og caching. Det er et modent produkt, der er blevet vist frem på PostgreSQL-konferencer så langt tilbage som PGCon 2017:

Flere detaljer og en produktdemo kan findes på Azure til PostgreSQL-bloggen .
Konklusion
I nutidens distribuerede computere er Query Caching og Load Balancing lige så vigtige for PostgreSQL-ydeevnejustering som de velkendte GUC'er, OS-kerner, storage og forespørgselsoptimering. Mens pgpool-II og Heimdall Data er open source og henholdsvis de kommercielle foretrukne løsninger, er der tilfælde, hvor bevidst fremstillede værktøjer kan bruges som byggesten for at opnå lignende resultater.