Tilbage i 2014 skrev jeg en artikel kaldet Performance Tuning the Whole Query Plan. Den så på måder at finde et relativt lille antal forskellige værdier fra et moderat stort datasæt og konkluderede, at en rekursiv løsning kunne være optimal. Dette opfølgende indlæg gennemgår spørgsmålet til SQL Server 2019 igen ved at bruge et større antal rækker.
Testmiljø
Jeg vil bruge 50 GB Stack Overflow 2013-databasen, men enhver stor tabel med et lavt antal forskellige værdier ville gøre det.
Jeg vil lede efter forskellige værdier i BountyAmount kolonne i dbo.Votes tabel, præsenteret i dusørbeløbsrækkefølge stigende. Stemmetabellen har lige under 53 millioner rækker (52.928.720 for at være præcis). Der er kun 19 forskellige dusørbeløb, inklusive NULL .
Stack Overflow 2013-databasen kommer uden ikke-klyngede indekser for at minimere downloadtiden. Der er et klynget primærnøgleindeks på Id kolonne i dbo.Votes bord. Den er sat til SQL Server 2008-kompatibilitet (niveau 100), men vi starter med en mere moderne indstilling af SQL Server 2017 (niveau 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Testene blev udført på min bærbare computer ved hjælp af SQL Server 2019 CU 2. Denne maskine har fire i7 CPU'er (hyperthreaded til 8) med en basishastighed på 2,4GHz. Den har 32 GB RAM, med 24 GB tilgængelig for SQL Server 2019-instansen. Omkostningsgrænsen for parallelitet er sat til 50.
Hvert testresultat repræsenterer det bedste af ti kørsler med alle nødvendige data og indekssider i hukommelsen.
1. Rækkebutik-klyngeindeks
For at indstille en basislinje er den første kørsel en seriel forespørgsel uden nogen ny indeksering (og husk, at dette er med databasen sat til kompatibilitetsniveau 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Dette scanner det klyngede indeks og bruger et hash-aggregat i rækketilstand til at finde de distinkte værdier af BountyAmount :
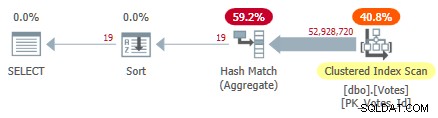 Serial Clustered Index Plan
Serial Clustered Index Plan
Dette tager 10.500 ms at fuldføre ved at bruge den samme mængde CPU-tid. Husk, at dette er den bedste tid over ti løb med alle data i hukommelsen. Automatisk oprettet stikprøvestatistik på BountyAmount kolonne blev oprettet ved første kørsel.
Omkring halvdelen af den forløbne tid bruges på Clustered Index Scan, og omkring halvdelen på Hash Match Aggregate. Sorten har kun 19 rækker at behandle, så den bruger kun 1 ms eller deromkring. Alle operatører i denne plan bruger rækketilstandsudførelse.
Fjernelse af MAXDOP 1 hint giver en parallel plan:
 Parallel Clustered Index Plan
Parallel Clustered Index Plan
Dette er den plan, optimizeren vælger uden nogen hints i min konfiguration. Det returnerer resultater i 4.200 ms bruger i alt 32.800 ms CPU (ved DOP 8).
2. Ikke-klynget indeks
Scanner hele tabellen for kun at finde BountyAmount virker ineffektivt, så det er naturligt at prøve at tilføje et ikke-klynget indeks på kun den ene kolonne, som denne forespørgsel har brug for:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Dette indeks tager et stykke tid at oprette (1m 40s). MAXDOP 1 forespørgslen bruger nu et Stream Aggregate, fordi optimizeren kan bruge det ikke-klyngede indeks til at præsentere rækker i BountyAmount ordre:
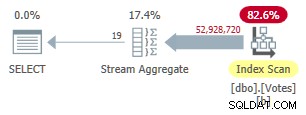 Plan for seriel ikke-klyngetilstand
Plan for seriel ikke-klyngetilstand
Dette kører 9.300 ms (forbruger den samme mængde CPU-tid). En nyttig forbedring i forhold til de originale 10.500 ms, men næppe verdensomspændende.
Fjernelse af MAXDOP 1 tip giver en parallel plan med lokal (pr. tråd) aggregering:
 Parallel ikke-klynget rækketilstandsplan
Parallel ikke-klynget rækketilstandsplan
Dette udføres i 3.400 ms bruger 25.800ms CPU-tid. Vi kan muligvis blive bedre med række- eller sidekomprimering på det nye indeks, men jeg vil gå videre til mere interessante muligheder.
3. Batch Mode on Row Store (BMOR)
Indstil nu databasen til SQL Server 2019-kompatibilitetstilstand ved hjælp af:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Dette giver optimeringsværktøjet frihed til at vælge batch-tilstand på rækkebutikken, hvis den finder det umagen værd. Dette kan give nogle af fordelene ved batch-tilstand uden at kræve et kolonnelagerindeks. For dybe tekniske detaljer og udokumenterede muligheder, se Dmitry Pilugins fremragende artikel om emnet.
Desværre vælger optimeringsværktøjet stadig udførelse af fuld rækketilstand ved hjælp af strømaggregater til både de serielle og parallelle testforespørgsler. For at få en batch-tilstand på rækkelagerudførelsesplanen, kan vi tilføje et tip til at tilskynde til aggregering ved hjælp af hash-match (som kan køre i batch-tilstand):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Dette giver os en plan med alle operatører, der kører i batch-tilstand:
 Seriel batchtilstand på Row Store Plan
Seriel batchtilstand på Row Store Plan
Resultater returneres om 2.600 ms (alt CPU som normalt). Dette er allerede hurtigere end det parallelle rækketilstandsplan (3.400 ms forløbet), mens der bruges langt mindre CPU (2.600 ms mod 25.800 ms).
Fjernelse af MAXDOP 1 tip (men beholder HASH GROUP ) giver en parallel batch-tilstand på rækkebutiksplan:
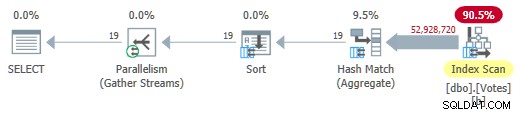 Parallel Batch Mode på Row Store Plan
Parallel Batch Mode på Row Store Plan
Dette kører på kun 725ms bruger 5.700 ms CPU.
4. Batch-tilstand på Column Store
Resultatet af den parallelle batch-tilstand på rækkelager er en imponerende forbedring. Vi kan gøre det endnu bedre ved at levere en kolonnelagerrepræsentation af dataene. For at holde alt andet ved det samme, vil jeg tilføje en ikke-klyngede kolonnelagerindeks på netop den kolonne, vi har brug for:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Dette er udfyldt fra det eksisterende b-træ ikke-klyngede indeks og tager kun 15 sekunder at oprette.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Optimeringsværktøjet vælger en fuldstændig batch-tilstandsplan inklusive en kolonnelagerindeksscanning:
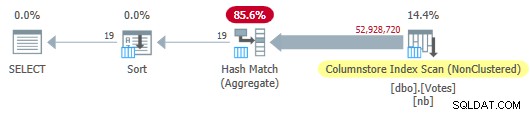 Serial Column Store Plan
Serial Column Store Plan
Dette kører på 115ms bruger den samme mængde CPU-tid. Optimeringsværktøjet vælger denne plan uden nogen antydninger til min systemkonfiguration, fordi planens estimerede omkostninger er under omkostningstærsklen for parallelisme .
For at få en parallel plan kan vi enten reducere omkostningstærsklen eller bruge et udokumenteret tip:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Under alle omstændigheder er den parallelle plan:
 Parallel Column Store Plan
Parallel Column Store Plan
Forløbet tid for forespørgsel er nu nede på 30 ms , mens den bruger 210 ms CPU.
5. Batch-tilstand på Column Store med Push Down
Den nuværende bedste eksekveringstid på 30 ms er imponerende, især sammenlignet med de originale 10.500 ms. Ikke desto mindre er det lidt synd, at vi skal passere næsten 53 millioner rækker (i 58.868 batches) fra Scan til Hash Match Aggregate.
Det ville være rart, hvis SQL Server kunne skubbe aggregeringen ned i scanningen og bare returnere distinkte værdier fra kolonnelageret direkte. Du tror måske, at vi skal udtrykke DISTINCT som en GROUP BY at få Grouped Aggregate Pushdown, men det er logisk set overflødigt og ikke hele historien i hvert fald.
Med den nuværende SQL Server-implementering skal vi faktisk beregne et aggregat for at aktivere samlet pushdown. Mere end det skal vi bruge det samlede resultat på en eller anden måde, ellers vil optimeringsværktøjet bare fjerne det som unødvendigt.
En måde at skrive forespørgslen på for at opnå samlet pushdown er at tilføje et logisk overflødigt sekundært bestillingskrav:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Serieplanen er nu:
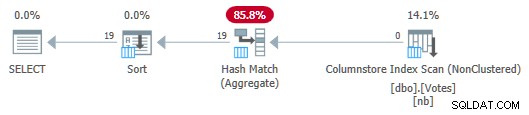 Serial Column Store Plan med Aggregate Push Down
Serial Column Store Plan med Aggregate Push Down
Bemærk, at ingen rækker overføres fra scanningen til aggregatet! Under dækkene, delvise aggregater af BountyAmount værdier og deres tilknyttede rækkeantal overføres til Hash Match Aggregate, som summerer de delvise aggregater for at danne det nødvendige endelige (globale) aggregat. Dette er meget effektivt, hvilket bekræftes af den forløbne tid på 13ms (som alt er CPU-tid). Som en påmindelse tog den tidligere serieplan 115 ms.
For at fuldende sættet kan vi få en parallel version på samme måde som før:
 Parallel Column Store Plan med Aggregate Push Down
Parallel Column Store Plan med Aggregate Push Down
Dette kører i 7ms bruger 40 ms CPU i alt.
Det er en skam, vi skal beregne og bruge et aggregat, vi ikke har brug for bare for at blive presset ned. Måske vil dette blive forbedret i fremtiden, så DISTINCT og GROUP BY uden aggregater kan skubbes ned til scanningen.
6. Rækketilstand Rekursivt almindeligt tabeludtryk
I begyndelsen lovede jeg at gense den rekursive CTE-løsning, der blev brugt til at finde et lille antal dubletter i et stort datasæt. Implementering af det nuværende krav ved hjælp af denne teknik er ret ligetil, selvom koden nødvendigvis er længere end noget, vi har set indtil dette punkt:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Idéen har sine rødder i en såkaldt indeksspringsscanning:Vi finder den laveste værdi af interesse i begyndelsen af det stigende-ordnede b-træindeks, søger derefter at finde den næste værdi i indeksrækkefølge, og så videre. Strukturen af et b-træ-indeks gør det meget effektivt at finde den næsthøjeste værdi - der er ingen grund til at scanne gennem dubletterne.
Det eneste rigtige trick her er at overbevise optimeringsværktøjet til at tillade os at bruge TOP i den 'rekursive' del af CTE for at returnere en kopi af hver særskilt værdi. Se venligst min tidligere artikel, hvis du har brug for en genopfriskning af detaljerne.
Udførelsesplanen (forklaret generelt af Craig Freedman her) er:
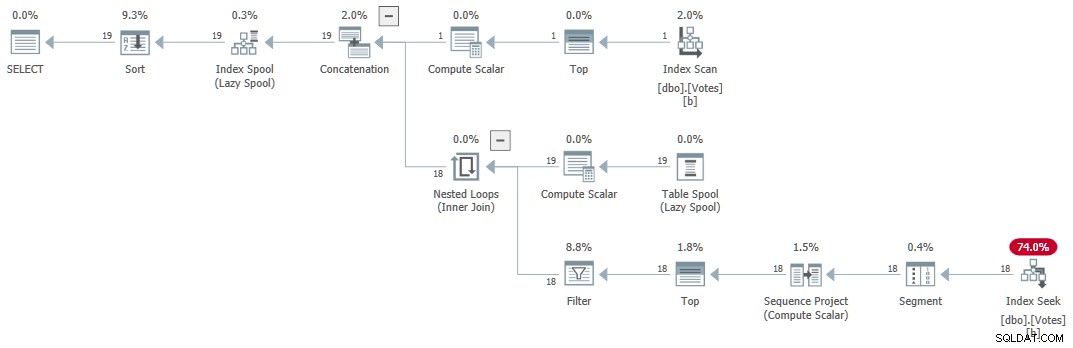 Seriel rekursiv CTE
Seriel rekursiv CTE
Forespørgslen returnerer korrekte resultater om 1 ms bruger 1 ms CPU ifølge Sentry One Plan Explorer.
7. Iterativ T-SQL
Lignende logik kan udtrykkes ved hjælp af en WHILE sløjfe. Koden kan være lettere at læse og forstå end den rekursive CTE. Det undgår også at skulle bruge tricks til at omgå de mange restriktioner på den rekursive del af en CTE. Ydeevnen er konkurrencedygtig på omkring 15 ms. Denne kode er angivet til interesse og er ikke inkluderet i præstationsoversigtstabellen.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tabel over præstationsoversigt
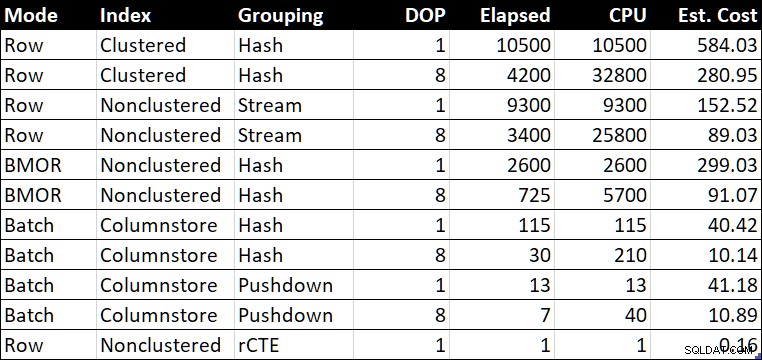 Ydeevneoversigtstabel (varighed / CPU i millisekunder)
Ydeevneoversigtstabel (varighed / CPU i millisekunder)
Den "Est. Pris"-kolonnen viser optimeringsværktøjets omkostningsestimat for hver forespørgsel som rapporteret på testsystemet.
Sidste tanker
At finde et lille antal forskellige værdier kan virke som et ganske specifikt krav, men jeg er stødt på det ret ofte gennem årene, normalt som en del af tuning af en større forespørgsel.
De sidste flere eksempler var ret tæt på ydeevnen. Mange mennesker ville være tilfredse med et hvilket som helst af de sekundære resultater, afhængigt af prioriteter. Selv den serielle batch-tilstand på rækkelagerresultatet på 2.600 ms kan sammenlignes godt med den bedste parallelle rækketilstandsplaner, hvilket lover godt for betydelige hastigheder blot ved at opgradere til SQL Server 2019 og aktivere databasekompatibilitetsniveau 150. Ikke alle vil være i stand til hurtigt at flytte til kolonnelagerlager, og det vil alligevel ikke altid være den rigtige løsning . Batch-tilstand på rækkelager giver en pæn måde at opnå nogle af de gevinster, der er mulige med kolonnebutikker, forudsat at du kan overbevise optimeringsværktøjet til at vælge at bruge det.
Parallelkolonnens akkumulerede push-down-resultat på 57 millioner rækker behandlet på 7ms (ved at bruge 40ms CPU) er bemærkelsesværdigt, især i betragtning af hardwaren. Det serielle samlede push-down-resultat på 13ms er lige så imponerende. Det ville være fantastisk, hvis jeg ikke havde været nødt til at tilføje et meningsløst samlet resultat for at få disse planer.
For dem, der endnu ikke kan flytte til SQL Server 2019 eller kolonnelagerlagring, er den rekursive CTE stadig en levedygtig og effektiv løsning, når der findes et passende b-tree-indeks, og antallet af nødvendige distinkte værdier er garanteret ret lille. Det ville være fint, hvis SQL Server kunne få adgang til et b-træ som dette uden at skulle skrive en rekursiv CTE (eller tilsvarende iterativ looping T-SQL-kode ved hjælp af WHILE ).
En anden mulig løsning på problemet er at oprette en indekseret visning. Dette vil give forskellige værdier med stor effektivitet. Ulempen er som sædvanlig, at hver ændring af den underliggende tabel skal opdatere rækkeantallet, der er gemt i den materialiserede visning.
Hver af de løsninger, der præsenteres her, har sin plads, afhængigt af kravene. At have en bred vifte af værktøjer til rådighed er generelt set en god ting, når du tuner forespørgsler. Det meste af tiden ville jeg vælge en af batchtilstandsløsningerne, fordi deres ydeevne vil være ret forudsigelig, uanset hvor mange dubletter der er til stede.