 Denne artikel er den ottende del i en serie om tabeludtryk. Indtil videre har jeg givet en baggrund til tabeludtryk, der dækkede både de logiske og optimeringsaspekter af afledte tabeller, de logiske aspekter af CTE'er og nogle af optimeringsaspekterne af CTE'er. I denne måned fortsætter jeg dækningen af optimeringsaspekter af CTE'er, specifikt om hvordan flere CTE-referencer håndteres.
Denne artikel er den ottende del i en serie om tabeludtryk. Indtil videre har jeg givet en baggrund til tabeludtryk, der dækkede både de logiske og optimeringsaspekter af afledte tabeller, de logiske aspekter af CTE'er og nogle af optimeringsaspekterne af CTE'er. I denne måned fortsætter jeg dækningen af optimeringsaspekter af CTE'er, specifikt om hvordan flere CTE-referencer håndteres.
I mine eksempler fortsætter jeg med at bruge eksempeldatabasen TSQLV5. Du kan finde scriptet, der opretter og udfylder TSQLV5 her, og dets ER-diagram her.
Flere referencer og ikke-determinisme
I sidste måned forklarede og demonstrerede jeg, at CTE'er bliver uindlejrede, mens midlertidige tabeller og tabelvariable faktisk bevarer data. Jeg gav anbefalinger med hensyn til, hvornår det giver mening at bruge CTE'er i forhold til, hvornår det giver mening at bruge midlertidige objekter ud fra et forespørgselsydeevne. Men der er et andet vigtigt aspekt af CTE-optimering, eller fysisk behandling, at overveje ud over løsningens ydeevne – hvordan flere referencer til CTE'en fra en ydre forespørgsel håndteres. Det er vigtigt at indse, at hvis du har en ydre forespørgsel med flere referencer til den samme CTE, bliver hver forespørgsel uindlejret separat. Hvis du har ikke-deterministiske beregninger i CTE'ens indre forespørgsel, kan disse beregninger have forskellige resultater i de forskellige referencer.
Sig for eksempel, at du aktiverer SYSDATETIME-funktionen i en CTE's indre forespørgsel, hvilket skaber en resultatkolonne kaldet dt. Generelt, forudsat at der ikke er ændringer i input, evalueres en indbygget funktion én gang pr. forespørgsel og reference, uanset antallet af involverede rækker. Hvis du kun henviser til CTE én gang fra en ydre forespørgsel, men interagerer med dt-kolonnen flere gange, formodes alle referencer at repræsentere den samme funktionsevaluering og returnere de samme værdier. Men hvis du henviser til CTE flere gange i den ydre forespørgsel, det være sig med flere underforespørgsler, der refererer til CTE eller en joinforbindelse mellem flere forekomster af den samme CTE (f.eks. kaldet C1 og C2), referencerne til C1.dt og C2.dt repræsenterer forskellige evalueringer af det underliggende udtryk og kan resultere i forskellige værdier.
For at demonstrere dette skal du overveje følgende tre batches:
-- Batch 1 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 VÆLG @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Batch 2 ERKLÆR @i SOM INT =1; WHILE @@ROWCOUNT =1 MED C AS (VÆLG SYSDATETIME() AS dt ) VÆLG @i +=1 FRA C WHERE dt =dt; PRINT @i;GO -- Batch 3 ERKLÆR @i SOM INT =1; WHILE @@ROWCOUNT =1 MED C AS (VÆLG SYSDATETIME() AS dt ) VÆLG @i +=1 WHERE (VÆLG dt FRA C) =(VÆLG dt FRA C); UDSKRIV @i;GO
Baseret på det, jeg lige har forklaret, kan du identificere, hvilke af batchene der har en uendelig løkke, og hvilke der vil stoppe på et tidspunkt på grund af de to sammenligninger af prædikatet, der evaluerer til forskellige værdier?
Husk, at jeg sagde, at et kald til en indbygget ikke-deterministisk funktion som SYSDATETIME evalueres én gang pr. forespørgsel og reference. Det betyder, at du i Batch 1 har to forskellige evalueringer, og efter nok iterationer af loopet vil de resultere i forskellige værdier. Prøv det. Hvor mange gentagelser rapporterede koden?
Hvad angår Batch 2, har koden to referencer til dt-kolonnen fra den samme CTE-instans, hvilket betyder, at begge repræsenterer den samme funktionsevaluering og bør repræsentere den samme værdi. Som følge heraf har Batch 2 en uendelig sløjfe. Kør det i et hvilket som helst tidsrum, du vil, men i sidste ende bliver du nødt til at stoppe kodekørsel.
Hvad angår Batch 3, har den ydre forespørgsel to forskellige underforespørgsler, der interagerer med CTE C, der hver repræsenterer en anden instans, der gennemgår en unnesting-proces separat. Koden tildeler ikke eksplicit forskellige aliaser til de forskellige forekomster af CTE, fordi de to underforespørgsler vises i uafhængige omfang, men for at gøre det lettere at forstå, kunne du tænke på de to som at bruge forskellige aliaser såsom C1 i en underforespørgsel og C2 i den anden. Så det er, som om den ene underforespørgsel interagerer med C1.dt og den anden med C2.dt. De forskellige referencer repræsenterer forskellige evalueringer af det underliggende udtryk og kan derfor resultere i forskellige værdier. Prøv at køre koden og se, at den stopper på et tidspunkt. Hvor mange gentagelser tog det, før det stoppede?
Det er interessant at prøve at identificere de tilfælde, hvor du har en enkelt versus flere evalueringer af det underliggende udtryk i forespørgselsudførelsesplanen. Figur 1 har de grafiske udførelsesplaner for de tre batches (klik for at forstørre).
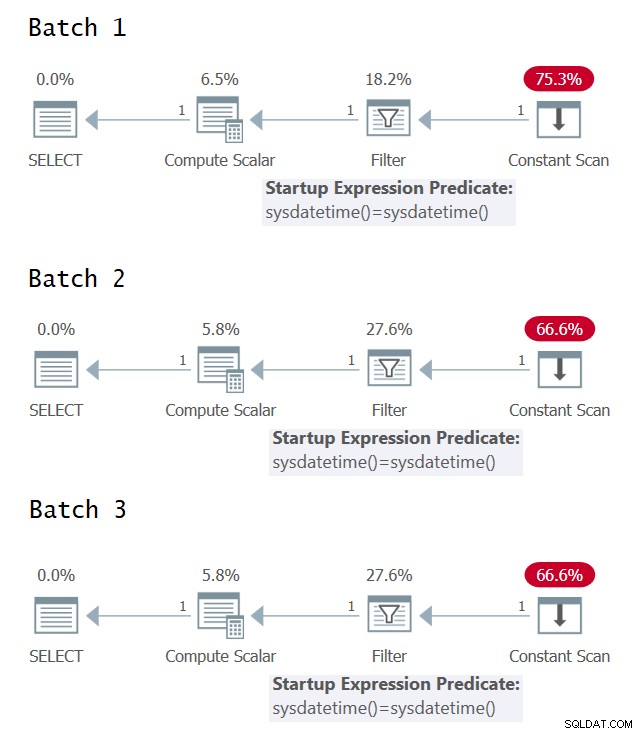 Figur 1:Grafiske udførelsesplaner for batch 1, batch 2 og batch 3
Figur 1:Grafiske udførelsesplaner for batch 1, batch 2 og batch 3
Desværre ingen glæde ved de grafiske udførelsesplaner; de virker alle identiske, selvom de tre partier semantisk set ikke har identiske betydninger. Takket være @CodeRecce og Forrest (@tsqladdict), som et fællesskab lykkedes det os at komme til bunds i dette med andre midler.
Som @CodeRecce opdagede, indeholder XML-planerne svaret. Her er de relevante dele af XML for de tre batches:
−− Batch 1
…
…
−− Batch 2
…
…
−− Batch 3
…
…
Du kan tydeligt se i XML-planen for Batch 1, at filterprædikatet sammenligner resultaterne af to separate direkte påkaldelser af den iboende SYSDATETIME-funktion.
I XML-planen for batch 2 sammenligner filterprædikatet det konstante udtryk ConstExpr1002, der repræsenterer én påkaldelse af funktionen SYSDATETIME med sig selv.
I XML-planen for batch 3 sammenligner filterprædikatet to forskellige konstante udtryk kaldet ConstExpr1005 og ConstExpr1006, der hver repræsenterer en separat påkaldelse af funktionen SYSDATETIME.
Som en anden mulighed foreslog Forrest (@tsqladdict) at bruge sporingsflag 8605, som viser den indledende forespørgselstrærepræsentation oprettet af SQL Server, efter at have aktiveret sporingsflag 3604, som forårsager, at outputtet fra TF 8605 bliver dirigeret til SSMS-klienten. Brug følgende kode til at aktivere begge sporingsflag:
Dernæst kører du koden, som du ønsker at hente forespørgselstræet for. Her er de relevante dele af outputtet, som jeg fik fra TF 8605 for de tre batcher:
−− Batch 1
*** Konverteret træ:***
LogOp_Project COL:Udtr1000
LogOp_Select
LogOp_ConstTableGet (1) [tom]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Ikke ejet,Værdi=1)
−− Batch 2
*** Konverteret træ:***
LogOp_Project COL:Udtr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [tom]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Ikke ejet,Værdi=1)
−− Batch 3
*** Konverteret træ:***
LogOp_Project COL:Udtr1004
LogOp_Select
LogOp_ConstTableGet (1) [tom]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [tom]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [tom]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Ikke ejet,Værdi=1)
I batch 1 kan du se en sammenligning mellem resultaterne af to separate evalueringer af den iboende funktion SYSDATETIME.
I batch 2 ser du en evaluering af funktionen, der resulterer i en kolonne kaldet Expr1000, og derefter en sammenligning mellem denne kolonne og sig selv.
I batch 3 ser du to separate evalueringer af funktionen. En i kolonne kaldet Expr1000 (senere fremskrevet af underforespørgselskolonnen kaldet Expr1001). En anden i kolonne kaldet Expr1002 (senere fremskrevet af underforespørgselskolonnen kaldet Expr1003). Du har så en sammenligning mellem Expr1001 og Expr1003.
Så med lidt mere gravning ud over, hvad den grafiske udførelsesplan afslører, kan du faktisk finde ud af, hvornår et underliggende udtryk kun bliver evalueret én gang versus flere gange. Nu hvor du forstår de forskellige cases, kan du udvikle dine løsninger baseret på den ønskede adfærd, du leder efter.
Vinduefunktioner med ikke-deterministisk rækkefølge
Der er en anden klasse af beregninger, der kan få dig i problemer, når de bruges i løsninger med flere referencer til den samme CTE. Det er vinduesfunktioner, der er afhængige af ikke-deterministisk rækkefølge. Tag vinduesfunktionen ROW_NUMBER som et eksempel. Når det bruges med delbestilling (rækkefølge efter elementer, der ikke entydigt identificerer rækken), kan hver evaluering af den underliggende forespørgsel resultere i en anden tildeling af rækkenumrene, selvom de underliggende data ikke ændrede sig. Med flere CTE-referencer skal du huske, at hver enkelt bliver fjernet separat, og du kan få forskellige resultatsæt. Afhængigt af hvad den ydre forespørgsel gør med hver reference, f.eks. hvilke kolonner fra hver reference den interagerer med og hvordan, kan optimeringsværktøjet beslutte at få adgang til dataene for hver af forekomsterne ved hjælp af forskellige indekser med forskellige bestillingskrav.
Overvej følgende kode som et eksempel:
BRUG TSQLV5; MED C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
Kan denne forespørgsel nogensinde returnere et ikke-tomt resultatsæt? Måske er din første reaktion, at den ikke kan. Men tænk over det, jeg lige har forklaret lidt mere omhyggeligt, og du vil indse, at det, i det mindste i teorien, er muligt på grund af de to separate CTE unnesting-processer, der vil finde sted her - en af C1 og en anden af C2. Det er dog én ting at teoretisere, at noget kan ske, og en anden at demonstrere det. For eksempel, da jeg kørte denne kode uden at oprette nye indekser, fik jeg hele tiden et tomt resultatsæt:
orderid shipcountry orderid------------ -------------------------(0 rækker påvirket)Jeg fik planen vist i figur 23 for denne forespørgsel.
Figur 2:Første plan for forespørgsel med to CTE-referencer
Det, der er interessant at bemærke her, er, at optimeringsværktøjet valgte at bruge forskellige indekser til at håndtere de forskellige CTE-referencer, fordi det var det, den anså for optimalt. Når alt kommer til alt, vedrører hver reference i den ydre forespørgsel en anden delmængde af CTE-kolonnerne. Den ene reference resulterede i en ordnet fremadrettet scanning af indekset idx_nc_orderedate, og den anden i en uordnet scanning af det klyngede indeks efterfulgt af en sorteringsoperation efter orderdate stigende. Selvom indekset idx_nc_orderedate kun er defineret på ordredato-kolonnen som nøglen, er det i praksis defineret på (orderdate, orderid) som dets nøgler, da orderid er den klyngede indeksnøgle og er inkluderet som den sidste nøgle i alle ikke-klyngede indekser. Så en bestilt scanning af indekset udsender faktisk rækkerne sorteret efter orderdate, orderid. Hvad angår den uordnede scanning af det klyngede indeks, på lagermotorniveau, scannes dataene i indeksnøglerækkefølge (baseret på orderid) for at imødekomme minimale konsistensforventninger til standardisolationsniveauet, der læses. Sort-operatoren indtager derfor dataene sorteret efter orderid, sorterer rækkerne efter orderdate og ender i praksis med at udsende rækkerne sorteret efter orderdate, orderid.
Igen, i teorien er der ingen sikkerhed for, at de to referencer altid vil repræsentere det samme resultatsæt, selvom de underliggende data ikke ændres. En simpel måde at demonstrere dette på er at arrangere to forskellige optimale indekser for de to referencer, men lade det ene ordne dataene efter ordredato ASC, ordreid ASC, og den anden sortere dataene efter ordredato DESC, ordreid ASC (eller præcis det modsatte). Vi har allerede det tidligere indeks på plads. Her er kode til at oprette sidstnævnte:
OPRET INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);Kør koden en anden gang efter oprettelse af indekset:
MED C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FRA Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Jeg fik følgende output, da jeg kørte denne kode efter at have oprettet det nye indeks:
orderid shipcountry orderid------------ -----------------------------------------10251 Frankrig 1025010250 Brasilien 1025110261 Brasilien 1026010260 Tyskland 1026110271 USA 10270...11070 Tyskland 1107311077 USA 1107411076 Frankrig 1107511075 Schweiz 1107611074 Danmark 11077(546 rækker berørt)Ups.
Undersøg forespørgselsplanen for denne udførelse som vist i figur 3:
Figur 3:Anden plan for forespørgsel med to CTE-referencer
Bemærk, at den øverste gren af planen scanner indekset idx_nc_orderdate på en ordnet fremadrettet måde, hvilket får sekvensprojektoperatøren, som beregner rækkenumrene, til at indlæse dataene i praksis sorteret efter ordredato ASC, orderid ASC. Den nederste gren af planen scanner det nye indeks idx_nc_odD_oid_I_sc på en ordnet baglæns måde, hvilket får sekvensprojektoperatøren til at indtage dataene i praksis ordnet efter orderdate ASC, orderid DESC. Dette resulterer i et andet arrangement af rækkenumre for de to CTE-referencer, når der er mere end én forekomst af den samme ordredatoværdi. Følgelig genererer forespørgslen et ikke-tomt resultatsæt.
Hvis du ønsker at undgå sådanne fejl, er en oplagt mulighed at fortsætte det indre forespørgselsresultat i et midlertidigt objekt som en midlertidig tabel eller tabelvariabel. Men hvis du har en situation, hvor du hellere vil holde dig til at bruge CTE'er, er en simpel løsning at bruge total orden i vinduesfunktionen ved at tilføje en tiebreaker. Med andre ord, sørg for at bestille efter en kombination af udtryk, der unikt identificerer en række. I vores tilfælde kan du blot tilføje orderid eksplicit som en tiebreaker, som sådan:
MED C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Du får et tomt resultatsæt som forventet:
orderid shipcountry orderid------------ -------------------------(0 rækker påvirket)Uden at tilføje yderligere indekser får du planen vist i figur 4:
Figur 4:Tredje plan for forespørgsel med to CTE-referencer
Den øverste gren af planen er den samme som for den tidligere plan vist i figur 3. Den nederste gren er dog en smule anderledes. Det nye indeks, der blev oprettet tidligere, er ikke rigtig ideel til den nye forespørgsel i den forstand, at den ikke har dataene ordnet som ROW_NUMBER-funktionen har brug for (orderdate, orderid). Det er stadig det smalleste dækkende indeks, som optimeringsværktøjet kunne finde for sin respektive CTE-reference, så det er valgt; det er dog scannet på en Ordret:Falsk måde. En eksplicit sorteringsoperator sorterer derefter dataene efter ordredato, ordre-id som ROW_NUMBER-beregningen har brug for. Selvfølgelig kan du ændre indeksdefinitionen, så både orderdate og orderid bruger samme retning, og på denne måde vil den eksplicitte sortering blive elimineret fra planen. Hovedpointen er dog, at ved at bruge total bestilling undgår du at komme i problemer på grund af denne specifikke fejl.
Når du er færdig, skal du køre følgende kode til oprydning:
DROP INDEX HVIS FINDER idx_nc_odD_oid_I_sc PÅ Salg.Ordre;Konklusion
Det er vigtigt at forstå, at flere referencer til den samme CTE fra en ydre forespørgsel resulterer i separate evalueringer af CTE'ens indre forespørgsel. Vær særlig forsigtig med ikke-deterministiske beregninger, da de forskellige evalueringer kan resultere i forskellige værdier.
Når du bruger vinduesfunktioner som ROW_NUMBER og aggregater med en ramme, skal du sørge for at bruge total rækkefølge for at undgå at få forskellige resultater for den samme række i de forskellige CTE-referencer.