Indekser er hastighedsboostere i SQL-databaser. De kan være grupperede eller ikke-klynger. Men hvad betyder det, og hvor skal du ansøge hver?
Jeg kender denne følelse. Jeg har været der. Nybegyndere er ofte i tvivl om, hvilket indeks de skal bruge på hvilke kolonner. Men selv eksperter skal tænke dette spørgsmål igennem, før de træffer en beslutning, og forskellige situationer kræver forskellige beslutninger. Som du vil se senere, er der forespørgsler, hvor et klynget indeks vil skinne sammenlignet med et ikke-klynget indeks og omvendt.
Alligevel skal vi først kende hver af dem. Hvis du leder efter de samme oplysninger, er i dag din heldige dag.
Denne artikel vil fortælle dig, hvad disse indekser er, og hvornår du skal bruge hver. Selvfølgelig vil der være kodeeksempler, som du kan prøve i praksis. Så tag dine chips eller pizza og noget sodavand eller kaffe, og gør dig klar til at fordybe dig i denne indsigtsfulde rejse.
Klar?
Hvad er Clustered Index
Et klynget indeks er et indeks, der definerer den fysiske sorteringsrækkefølge af rækker i en tabel eller visning.
For at se dette i faktisk form, lad os tage medarbejderen tabellen i AdventureWorks2017 database.
Den primære nøgle er også et klynget indeks, og nøglen er baseret på BusinessEntityID kolonne. Når du laver et SELECT på denne tabel uden en ORDER BY, vil du se, at den er sorteret efter den primære nøgle.
Prøv det selv ved at bruge koden nedenfor:
BRUG AdventureWorks2017GOSELECT TOP 10 * FRA HumanResources.EmployeeGO Se nu resultatet i figur 1:
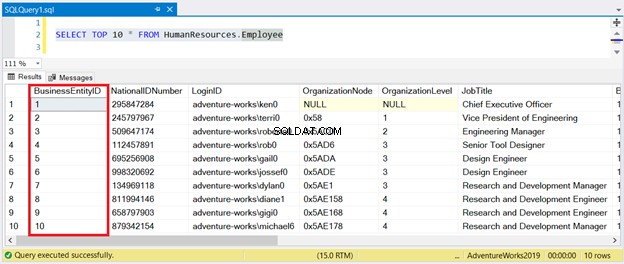
Som du kan se, behøver du ikke sortere resultatsættet med BusinessEntityID . Det klyngede indeks sørger for det.
I modsætning til ikke-klyngede indekser, kan du kun have 1 klyngede indeks pr. tabel. Hvad hvis vi prøver dette på medarbejderen bord?
OPRET CLUSTERED INDEX IX_Employee_NationalIDON HumanResources.Employee (NationalIDNumber)GO Vi har en lignende fejl nedenfor:
Meddelelse 1902, niveau 16, tilstand 3, linje 4. Kan ikke oprette mere end ét klynget indeks på tabellen 'HumanResources.Employee'. Slet det eksisterende klyngede indeks 'PK_Employee_BusinessEntityID', før du opretter et andet. Hvornår skal man bruge et grupperet indeks?
En kolonne er den bedste kandidat til et klynget indeks, hvis et af følgende er sandt:
- Det bruges i et stort antal forespørgsler i WHERE-sætningen og joins.
- Den vil blive brugt som en fremmednøgle til en anden tabel og i sidste ende til joins.
- Unikke kolonneværdier.
- Det er mindre sandsynligt, at værdien ændres.
- Denne kolonne bruges til at forespørge på en række værdier. Operatorer såsom>, <,>=, <=eller BETWEEN bruges sammen med kolonnen i WHERE-sætningen.
Men klyngede indekser er ikke gode, hvis kolonnen eller kolonnerne
- ændres ofte
- er brede taster eller en kombination af kolonner med en stor nøglestørrelse.
Eksempler
Klyngede indekser kan oprettes ved hjælp af T-SQL-kode eller et hvilket som helst SQL Server GUI-værktøj. Du kan gøre det i T-SQL ved oprettelse af tabel, sådan her:
OPRET TABEL [Person].[Person]( [BusinessEntityID] [int] NOT NULL, [PersonType] [nchar](2) NOT NULL, [NameStyle] [dbo].[NameStyle] NOT NULL, [Titel] [nvarchar](8) NULL, [FirstName] [dbo].[Name] NOT NULL, [MiddleName] [dbo].[Name] NULL, [LastName] [dbo].[Name] NOT NULL, [ Suffiks] [nvarchar](10) NULL, [EmailPromotion] [int] IKKE NULL, [AdditionalContactInfo] [xml](INDHOLD [Person].[AdditionalContactInfoSchemaCollection]) NULL, [Demografi] [xml](INDHOLD [Person].[ IndividualSurveySchemaCollection]) NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_Person_BusinessEntityID] PRIMÆR NØGLE KLUSTERET ([BusinessEntityID] ASC) Eller du kan gøre dette ved at bruge ALTER TABLE efter oprettelse af tabellen uden et klynget indeks:
ÆNDRE TABEL Person.Person TILFØJ BEGRÆNSNING [PK_Person_BusinessEntityID] PRIMÆR NØGLE KLUSTERET (BusinessEntityID)GO En anden måde er at bruge CREATE CLUSTERED INDEX:
OPRET KLUSTERET INDEKS [PK_Person_BusinessEntityID] PÅ Person.Person (BusinessEntityID)GO Endnu et alternativ er at bruge et SQL Server-værktøj som SQL Server Management Studio eller dbForge Studio til SQL Server.
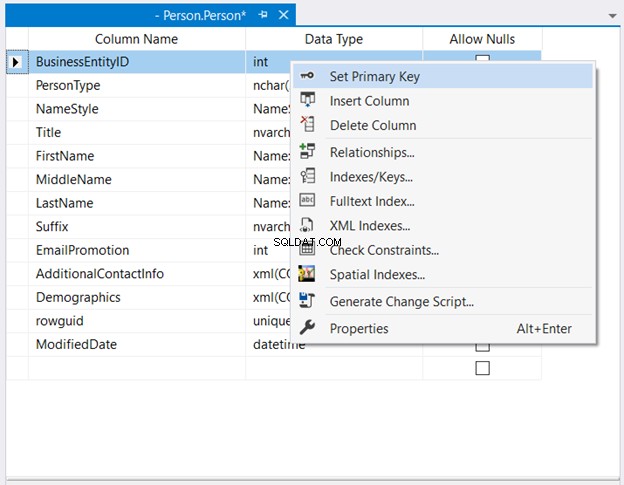
I Object Explorer , udvid databasen og tabelknuderne. Højreklik derefter på den ønskede tabel og vælg Design . Til sidst skal du højreklikke på den kolonne, du ønsker skal være den primære nøgle> Indstil primær nøgle > Gem ændringerne i tabellen.
Figur 2 nedenfor viser hvor BusinessEntityID er indstillet som den primære nøgle.
Bortset fra at oprette et enkelt-kolonne klynget indeks, kan du bruge flere kolonner. Se et eksempel i T-SQL:
OPRET KLUSTERET INDEKS [IX_Person_Efternavn_Fornavn_Mellemnavn] PÅ [Person].[Person]( [Efternavn] ASC, [Fornavn] ASC, [MiddleName] ASC)GO Efter at have oprettet dette klyngede indeks, er Personen tabellen bliver fysisk sorteret efter Efternavn , Fornavn , og Mellemnavn .
En af fordelene ved denne tilgang er forbedret forespørgselsydeevne baseret på navnet. Desuden sorterer den resultater efter navn uden at angive BESTIL EFTER. Men bemærk, at hvis navnet ændres, skal tabellen omarrangeres. Selvom dette ikke sker hver dag, kan indvirkningen være enorm, hvis bordet er meget stort.
Hvad er ikke-klynget indeks
Et ikke-klynget indeks er et indeks med en nøgle og en pegepind til rækkerne eller de klyngede indeksnøgler. Dette indeks kan gælde for både tabeller og visninger.
I modsætning til klyngede indekser er strukturen her adskilt fra tabellen. Da det er separat, har det brug for en pegepind til tabelrækkerne, også kaldet en rækkeplacering. Således indeholder hver post i et ikke-klynget indeks en locator og en nøgleværdi.
Ikke-klyngede indekser sorterer ikke fysisk tabellen baseret på nøglen.
Indeksnøgler til ikke-klyngede indekser har en maksimal størrelse på 1700 bytes. Du kan omgå denne grænse ved at tilføje inkluderede kolonner. Denne metode er god, hvis din forespørgsel skal dække flere kolonner uden at øge nøglestørrelsen.
Du kan også oprette filtrerede ikke-klyngede indekser. Dette vil reducere indeksvedligeholdelsesomkostninger og -lagring, samtidig med at forespørgselsydeevnen forbedres.
Hvornår skal man bruge et ikke-klynget indeks?
En eller flere kolonner er gode kandidater til ikke-klyngede indekser, hvis følgende er sandt:
- Kolonnen eller kolonnerne bruges i en WHERE-sætning eller join.
- Forespørgslen returnerer ikke et stort resultatsæt.
- Den nøjagtige overensstemmelse i WHERE-sætningen ved hjælp af lighedsoperatoren er nødvendig.
Eksempler
Denne kommando vil oprette et unikt, ikke-klynget indeks i Medarbejder tabel:
OPRET UNIKT IKKE-KLUSTERET INDEX [AK_Employee_NationalIDNumber] PÅ [HumanResources].[Medarbejder]( [NationalIDNumber] ASC)GO Bortset fra en tabel kan du oprette et ikke-klynget indeks for en visning:
OPRET IKKE-KLUSTERET INDEKS [IDX_vProductAndDescription_ProductModel] PÅ [Production].[vProductAndDescription]( [ProductModel] ASC)GO Andre almindelige spørgsmål og tilfredsstillende svar
Hvad er forskellene mellem grupperet og ikke-klynget indeks?
Ud fra det, du så tidligere, kan du allerede danne dig ideer om, hvor forskellige klyngede og ikke-klyngede indekser er. Men lad os have det på et bord for nem reference.
| Oplysninger | Clustered Index | Ikke-klynget indeks |
| Gælder for | Tabeller og visninger | Tabeller og visninger |
| Tilladt pr. tabel | 1 | 999 |
| Nøglestørrelse | 900 bytes | 1700 bytes |
| Kolonner pr. indeksnøgle | 32 | 32 |
| God til | Rangeforespørgsler (>,<,>=, <=, MELLEM) | Nøjagtige matches (=) |
| Ikke-nøgle inkluderede kolonner | Ikke tilladt | Tilladt |
| Filtrer med betingelse | Ikke tilladt | Tilladt |
Skal primære nøgler være grupperet eller ikke-klynget indeks?
En primær nøgle er en begrænsning. Når du gør en kolonne til en primær nøgle, oprettes der automatisk et klynget indeks ud af det, medmindre et eksisterende klynget indeks allerede er på plads.
Forveksle ikke en primær nøgle med et klynget indeks! En primær nøgle kan også være den klyngede indeksnøgle. Men en klynget indeksnøgle kan være en anden kolonne end den primære nøgle.
Lad os tage et andet eksempel. I Person tabel over AdventureWorks201 7, har vi BusinessEntityID primærnøgle. Det er også den klyngede indeksnøgle. Du kan droppe det klyngede indeks. Opret derefter et klynget indeks baseret på Efternavn , Fornavn og Mellemnavn . Den primære nøgle er stadig BusinessEntityID kolonne.
Men skal dine primære nøgler altid være grupperet?
Det kommer an på. Se igen spørgsmålet om, hvornår du skal bruge et klynget indeks.
Hvis en kolonne eller kolonner vises i din WHERE-sætning i mange forespørgsler, er dette en kandidat til et klynget indeks. Men en anden overvejelse er, hvor bred den klyngede indeksnøgle er. For brede – og størrelsen af hvert ikke-klyngede indeks vil stige, hvis de findes. Husk, at ikke-klyngede indekser også bruger den klyngede indeksnøgle som en pointer. Så hold din klyngede indeksnøgle så smal som muligt.
Hvis et stort antal forespørgsler bruger den primære nøgle i WHERE-sætningen, skal du lade den også være den klyngede indeksnøgle. Hvis ikke, skal du oprette din primære nøgle som et ikke-klynget indeks.
Men hvad hvis du stadig er usikker? Derefter kan du vurdere ydelsesfordelen ved en kolonne, når den er klynget eller ikke-klynget. Så tuner ind på næste afsnit om det.
Hvad er hurtigere:Klynget eller ikke-klynget indeks?
Godt spørgsmål. Der er ingen generel regel. Du skal kontrollere de logiske læsninger og udførelsesplanen for dine forespørgsler.
Vores korte eksperiment vil omfatte kopier af følgende tabeller fra AdventureWorks2017 database:
- Person
- BusinessEntityAddress
- Adresse
- Adressetype
Her er scriptet:
HVIS IKKE FINDER(VÆLG navn FRA sys.databases WHERE navn ='TestDatabase')BEGIN OPRET DATABASE TestDatabaseENDUSE TestDatabaseGOIF NOT EXISTS(SELECT name FROM sys.tables WHERE name ='Person_pkClustered')BEGIN SELECT,LasttityName FirstName ,MiddleName ,Suffix ,PersonType ,Title INTO Person_pkClustered FROM AdventureWorks2017.Person.Person ALTER TABLE Person_pkClustered ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID) CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)ENDIF NOT EXISTS(SELECT name FROM sys.tables WHERE name ='Person_pkNonClustered')BEGIN SELECT BusinessEntityID ,Efternavn ,FirstName ,MiddleName ,Suffix ,PersonType ,Title INTO Person_pkNonClustered FROM , Mellemnavn, Suffiks) ÆNDRINGSTABEL Person_pkNonClustered ADD CONSTRAINT [PK_Person _BusinessEntityID1] PRIMÆR NØGLE IKKE KLUSTERET (BusinessEntityID)ENDIF NOT EXISTS(SELECT name FROM sys.tables WHERE name ='AddressType')BEGIN SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType AddresseType KLUTTypE ENDIF NOT EXISTS(VÆLG navn FRA sys.tables HVOR navn ='Adresse')BEGIN VÆLG * INTO ADRESSE FRA AdventureWorks2017.Person.Address ÆNDRINGSTABEL Adresse TILFØJ BEGRÆNSNING [PK_Adresse] PRIMÆR NØGLE KLUSTERET (Adresse-ID)ENDHVIS IKKE FINDER SYSTEEM(VÆLG navn) .tables WHERE name ='BusinessEntityAddress')BEGIN VÆLG * INTO BusinessEntityAddress FRA AdventureWorks2017.Person.BusinessEntityAddress ÆNDRINGSTABEL BusinessEntityAddress ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMÆR NØGLE Addresse CLUSTERED (BusinessEntityAddress)END,GOTypAddressID (BusinessEntityAddress) Ved at bruge strukturen ovenfor vil vi sammenligne forespørgselshastigheder for klyngede og ikke-klyngede indekser.
Vi har 2 kopier af Personen bord. Den første bruger BusinessEntityID som den primære og klyngede indeksnøgle. Den anden bruger stadig BusinessEntityID som den primære nøgle. Det klyngede indeks er baseret på Efternavn , Fornavn , Mellemnavn og Suffiks .
Lad os begynde.
SØG TIL NØJKE SLAG BASEREDE PÅ EFTERNAVNET
Lad os først have en simpel forespørgsel. Skal også slå STATISTICS IO til. Derefter indsætter vi resultaterne i statisticsparser.com til en tabelpræsentation.
SET STATISTICS IO ONGOSELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.TitleFROM Person_pkClustered pWHERE p.LastName ='Martinez' OR p.LastName ='Smith' VÆLG p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title FROM Person_pkNonClustered pWHERE p.LastName ='Martinez' ELLER p.LastName ='Smith'SET STATISTICS IO OFFGO Forventningen er, at den første SELECT vil være langsommere, fordi WHERE-sætningen ikke matcher den klyngede indeksnøgle. Men lad os tjekke de logiske læsninger.
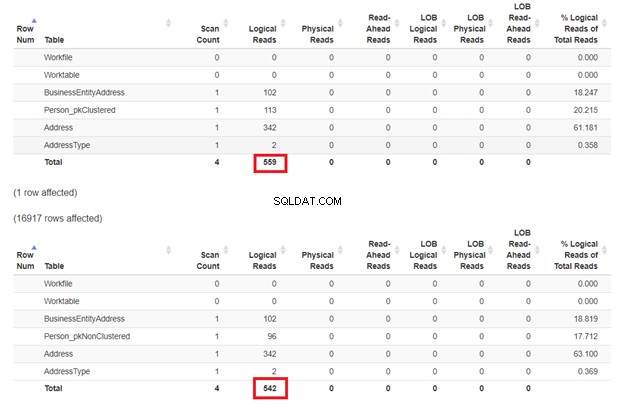
Som forventet i figur 3, Person_pkClustered havde mere logisk læsning. Derfor har forespørgslen brug for mere I/O. Grunden? Tabellen er sorteret efter BusinessEntityID . Alligevel har den anden tabel det klyngede indeks baseret på navnet. Da forespørgslen ønsker et resultat baseret på navnet, Person_pkNonClustered vinder. Jo mindre logiske læsninger, jo hurtigere er forespørgslen.
Hvad sker der ellers? Se figur 4.
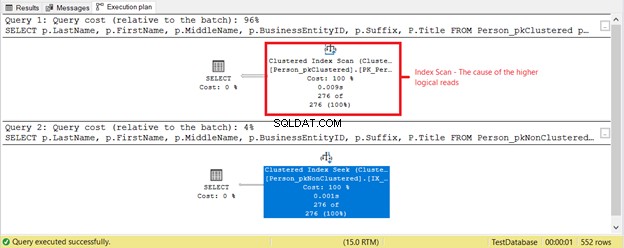
Der skete noget andet baseret på udførelsesplanen i figur 4. Hvorfor er en Clustered Index Scan i det første SELECT i stedet for en Index Seek? Synderen er titlen kolonnen i SELECT. Det er ikke dækket af nogen af de eksisterende indekser. SQL Server Optimizer anså det for hurtigere at bruge det klyngede indeks baseret på BusinessEntityID. Derefter scannede SQL Server den for de rigtige efternavne og fik fornavnet, mellemnavnet og titlen.
Fjern titlen kolonne, og den anvendte operator vil være Indekssøgning . Hvorfor? Fordi resten af felterne er dækket af det ikke-klyngede indeks baseret på Efternavn , Fornavn , Mellemnavn og Suffiks . Det inkluderer også BusinessEntityID som den grupperede indeksnøglefinder.
OMRÅDEFORSPØRGSEL BASEREDE PÅ VIRKSOMHEDSENHEDS-ID
Klyngede indekser kan være gode til intervalforespørgsler. Er det altid tilfældet? Lad os finde ud af det ved at bruge koden nedenfor.
SET STATISTICS IO ONGOSELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title FROM Person_pkClustered pWHERE p.BusinessEntityID>=285 AND p.P.BusinessEntitySELECT .LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title FROM Person_pkNonClustered pWHERE p.BusinessEntityID>=285 AND p.BusinessEntityID <=290SET STATISTICScode IO> Fortegnelsen skal bruge rækker baseret på en række BusinessEntityID'er fra 285 til 290. Igen er de klyngede og ikke-klyngede indekser i de 2 tabeller intakte. Lad os nu få den logiske læsning i figur 5. Den forventede vinder er Person_pkClustered fordi den primære nøgle også er den klyngede indeksnøgle.

Ser du lavere logiske læsninger på Person_pkClustered ? Klyngede indekser beviste deres værd på intervalforespørgsler i dette scenarie. Lad os se, hvad mere udførelsesplanen vil afsløre i figur 6.
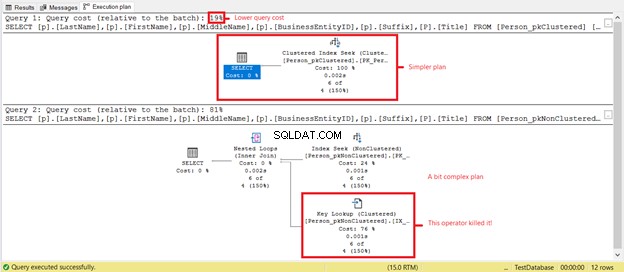
Den første SELECT har en enklere plan og lavere forespørgselsomkostninger baseret på figur 7. Dette understøtter også lavere logiske læsninger. I mellemtiden har den anden SELECT en Key Lookup-operator, der sænker forespørgslen. Synderen? Igen er det titlen kolonne. Fjern kolonnen i forespørgslen, eller tilføj den som en Inkluderet kolonne i det ikke-klyngede indeks. Så vil du have en bedre plan og lavere logiske læsninger.
SØG TIL NØJKE SLAG MED EN JOIN
Mange SELECT-sætninger inkluderer joins. Lad os få nogle tests. Her starter vi med eksakte matches:
INDSTIL STATISTIK IO ONGOSELECT p.BusinessEntityID,P.LastName,P.FirstName,P.MiddleName,P.Suffix,a.AddressLine1,a.AddressLine2,a.City,a2.NameFROM Person_pkClustered pinINNER JOIN BusinessEnt ON P.BusinessEntityID =bea.BusinessEntityIDINNER JOIN Adresse a ON bea.AddressID =a.AddressIDINNER JOIN AddressType a2 ON bea.AddressTypeID =a2.AddressTypeIDWHERE P.LastName ='Martinez'SELECT p.BusinessNavn,P.FirstName,P.LastityName,P.Lastity P.MiddleName,P.Suffix,a.AddressLine1,a.AddressLine2,a.City,a2.NameFROM Person_pkNonClustered pinNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID =bea.BusinessEntityIDINNER JOIN JOIN Address a ON a ON a ON bea.AddressTypeID =a2.AddressTypeIDWHERE P.LastName ='Martinez'SET STATISTICS IO OFFGO Vi forventer, at den anden SELECT fra Person_pkNonClustered med et klynget indeks på navnet vil have mindre logiske læsninger. Men er det? Se figur 7.
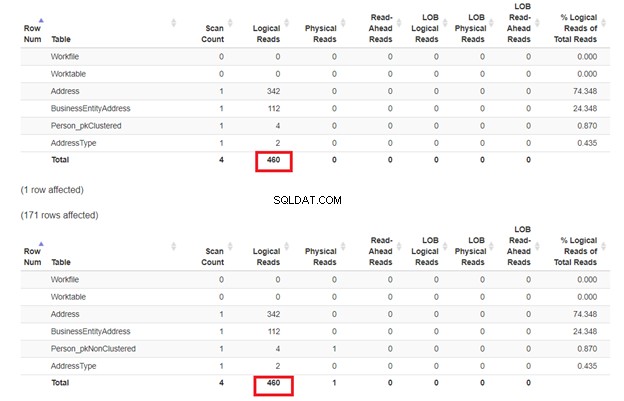
Det ser ud til, at det ikke-klyngede indeks på navnet klarede sig fint. De logiske aflæsninger er de samme. Hvis du tjekker udførelsesplanen, er forskellen i operatorerne Clustered Index Seek på Person_pkNonClustered , og indekssøgningen på Person_pkClustered .
Så vi er nødt til at tjekke de logiske læsninger og udførelsesplanen for at være sikre.
RANGE FORESPØRGSEL MED JOINS
Da vores forventninger kan være forskellige fra virkeligheden, lad os prøve det med rækkeviddeforespørgsler. Klyngede indekser er generelt gode med det. Men hvad nu hvis du inkluderer en joinforbindelse?
INDSTIL STATISTIK IO ONGOSELECT p.BusinessEntityID,P.LastName,P.FirstName,P.MiddleName,P.Suffix,a.AddressLine1,a.AddressLine2,a.City,a2.NameFROM Person_pkClustered pinINNER JOIN BusinessEnt ON P.BusinessEntityID =bea.BusinessEntityIDINNER JOIN Adresse a ON bea.AddressID =a.AddressIDINNER JOIN AdresseType a2 ON bea.AddressTypeID =a2.AddressTypeIDWHERE p.BusinessEntityID BETWEEN 100000Navn,P.FiastNavn,PAND,VÆLG .MiddleName,P.Suffix,a.AddressLine1,a.AddressLine2,a.City,a2.NameFROM Person_pkNonClustered PINNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID =bea.BusinessEntityIDINNER JOIN JOIN Address a ON aID bea2 bea.AddressTypeID =a2.AddressTypeIDWHERE p.BusinessEntityID MELLEM 100 OG 19000SET STATISTICS IO OFFGO Undersøg nu de logiske læsninger af disse 2 forespørgsler i figur 8:
Hvad er der sket? I figur 9 bider virkeligheden i Person_pkClustered . Der blev observeret flere I/O-omkostninger i den sammenlignet med Person_pkNonClustered . Det er anderledes end hvad vi forventer. Men baseret på dette forumsvar, kan en ikke-klynget indekssøgning være hurtigere end klynget indekssøgning, når alle kolonner i forespørgslen er 100 % dækket af indekset. I vores tilfælde er forespørgslen efter Person_pkNonClustered dækkede kolonnerne ved hjælp af det ikke-klyngede indeks (BusinessEntityID – nøgle; Efternavn , Fornavn , Mellemnavn , Suffiks – pointer til klynget indeksnøgle).
INDSÆT YDELSE
Prøv derefter at teste INSERT ydeevne over de samme tabeller.
INDSTIL STATISTIK IO ONGOINSERT INTO Person_pkClustered (BusinessEntityID, Efternavn, Fornavn, Mellemnavn, Suffiks, PersonType, Titel)VÆRDIER (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'), (20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');INSERT INTO Person_pkNonClustered (BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType , Titel)VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'), (20779, 'Galilei','Galileo', '', NULL, N 'SC', N'Mr.');SET STATISTICS IO OFFGO Figur 9 viser INSERT logiske læsninger:

Begge genererede den samme I/O. Således præsterede begge det samme.
SLETT YDELSE
Vores sidste test involverer SLET:
INDSTIL STATISTIK IO ONGODELETE FRA Person_pkClusteredWHERE LastName='Sanchez'AND FirstName ='Edwin'DELETE FROM Person_pkNonClusteredWHERE LastName='Sanchez'AND FirstName ='Edwin'SET STATISTICS IO OFFGO> Figur 10 viser de logiske aflæsninger. Bemærk forskellen.

Hvorfor har vi højere logiske læsninger på Person_pkClustered ? Sagen er, at DELETE-sætningsbetingelsen er baseret på et nøjagtigt match af et navn. Optimizeren bliver nødt til at ty til det ikke-klyngede indeks først. Det betyder mere I/O. Lad os bekræfte ved at bruge udførelsesplanen i figur 11.
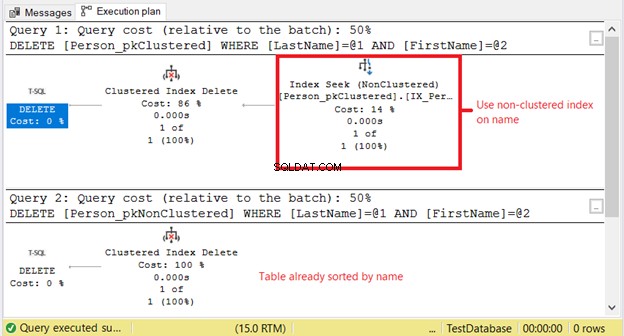
Det første SELECT har brug for en indekssøgning på det ikke-klyngede indeks. Årsagen er WHERE-sætningen på Efternavn og Fornavn . I mellemtiden, Person_pkNonClustered er allerede fysisk sorteret efter navn på grund af det klyngede indeks.
Takeaways
At danne højtydende forespørgsler handler ikke om held. Du kan ikke bare sætte et klynget og et ikke-klynget indeks og så pludselig har dine forespørgsler hastighedskraften. Du skal blive ved med at bruge værktøjerne som din linse for at fokusere på de små detaljer ud over resultatet.
Men nogle gange har du bare ikke tid til at gøre alt dette. Det tror jeg er normalt. Men så længe du ikke roder så meget, har du dit job dagen efter, og du kan finde ud af det. Dette bliver ikke let i starten. Det vil faktisk være forvirrende. Du vil også have en masse spørgsmål. Men med konstant øvelse kan du opnå det. Så hold hagen oppe.
Husk, både klyngede og ikke-klyngede indekser er til at booste forespørgsler. At kende de vigtigste forskelle, brugsscenarierne og værktøjerne vil hjælpe dig i din søgen efter at kode højtydende forespørgsler.
Jeg håber, at dette indlæg besvarer dine mest presserende spørgsmål om klyngede og ikke-klyngede indekser. Har du andet at tilføje til vores læsere? Kommentarsektionen er åben.
Og hvis du finder dette indlæg oplysende, så del det på dine foretrukne sociale medieplatforme.
Flere oplysninger om indekser og forespørgselsydeevne findes i nedenstående artikler:
- 22 smarte SQL-indekseksempler til at fordreje dine forespørgsler
- SQL-forespørgselsoptimering:5 kernefakta til at booste dine forespørgsler