[ Del 1 | Del 2 | Del 3 ]
I ånden af Grant Fritcheys seneste rædsel og Erin Stellatos indsats, siden jeg tænkte, før vi mødtes, ønsker jeg at komme med på vognen for at trompetere og fremme ideen om at droppe spor til fordel for Extended Events. Når nogen siger spor , tænker de fleste umiddelbart Profiler . Selvom Profiler er sit eget specielle mareridt, ville jeg i dag tale om SQL Servers standardsporing.
I vores miljø er det aktiveret på alle 200+ produktionsservere, og det samler en hel masse affald, vi aldrig kommer til at undersøge. Faktisk så meget skrald, at vigtige begivenheder, som vi kan finde nyttige til fejlfinding, ruller ud af sporingsfilerne, før vi nogensinde får chancen. Så jeg begyndte at overveje muligheden for at slå det fra, fordi:
- det er ikke gratis (observatøren overhead af selve sporingsaktiviteten, I/O involveret i at skrive til sporingsfilerne og den plads, de bruger);
- på de fleste servere er det aldrig set på; på andre, sjældent; og,
- det er let at tænde igen til specifik, isoleret fejlfinding.
Et par andre ting påvirker værdien af standardsporingen. Den kan ikke konfigureres på nogen måde - du kan ikke ændre, hvilke hændelser den indsamler, du kan ikke tilføje filtre, og du kan ikke kontrollere, hvor mange filer den beholder (5), hvor store de kan blive (20 MB hver) , eller hvor de er gemt (SERVERPROPERTY('ErrorLogFileName') ). Så vi er fuldstændig prisgivet arbejdsbyrden - på en given server kan vi ikke forudsige, hvor langt tilbage dataene kan gå (hændelser med større TextData værdier kan for eksempel fylde meget mere og skubbe ældre begivenheder hurtigere ud). Nogle gange kan det gå en uge tilbage, andre gange kan det gå tilbage kun få minutter.
Analyse af nuværende tilstand
Jeg kørte følgende kode mod 224 produktionsforekomster, bare for at forstå, hvilken slags støj der fylder standardsporet i vores miljø. Dette er sandsynligvis mere kompliceret, end det behøver at være, og er ikke engang så komplekst som den sidste forespørgsel, jeg brugte, men det er et anstændigt udgangspunkt for at analysere nedbrydningen af hændelsestyper på højt niveau, der i øjeblikket bliver fanget:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (EventSubClass-prædikatet er der for at forhindre dobbelttælling af DDL-hændelser.For et kort over EventClass-værdier har jeg listet dem i dette svar på Stack Exchange.)
Og resultaterne er ikke smukke (typiske resultater fra en tilfældig server). Det følgende repræsenterer ikke det nøjagtige output af den forespørgsel, men jeg brugte noget tid på at aggregere resultaterne i et mere fordøjeligt format for at se, hvor meget af dataene var nyttige, og hvor meget der var støj (klik for at forstørre):
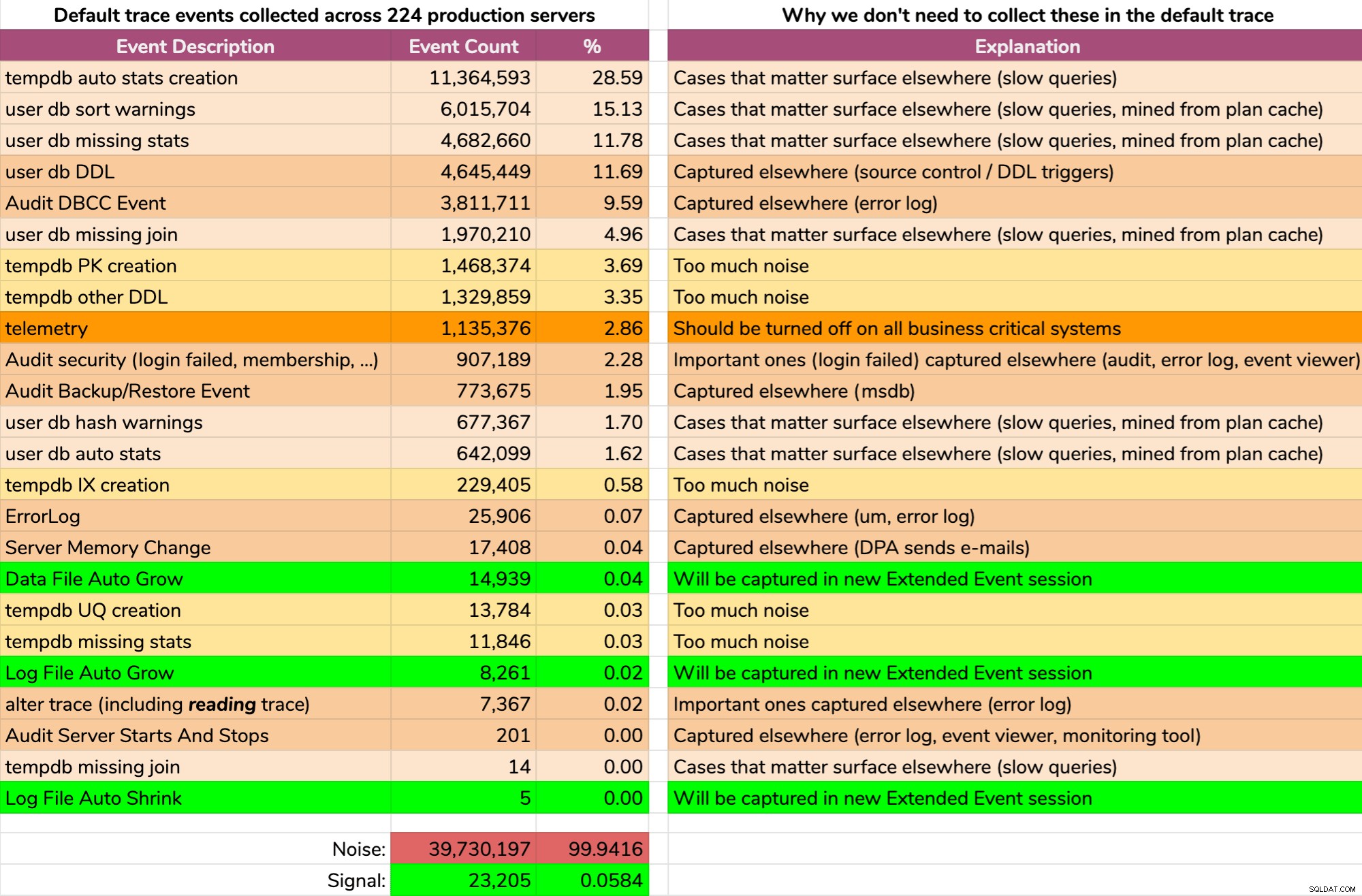
Næsten al støj (99,94%). Den eneste nyttige ting, vi nogensinde havde brug for fra standardsporingen, var filvækst og krympehændelser, da de var det eneste, vi ikke fangede andre steder på den ene eller anden måde. Men selv det er vi ikke altid i stand til at stole på, fordi dataene ruller væk så hurtigt.
En anden måde, jeg opdelte data på:ældste hændelse pr. forekomst. Nogle tilfælde havde så meget støj, at de ikke kunne holde på standardsporingsdata i mere end et par minutter! Jeg slørede servernavnene, men dette er rigtige data (disse er de 20 servere med den korteste historie – klik for at forstørre):
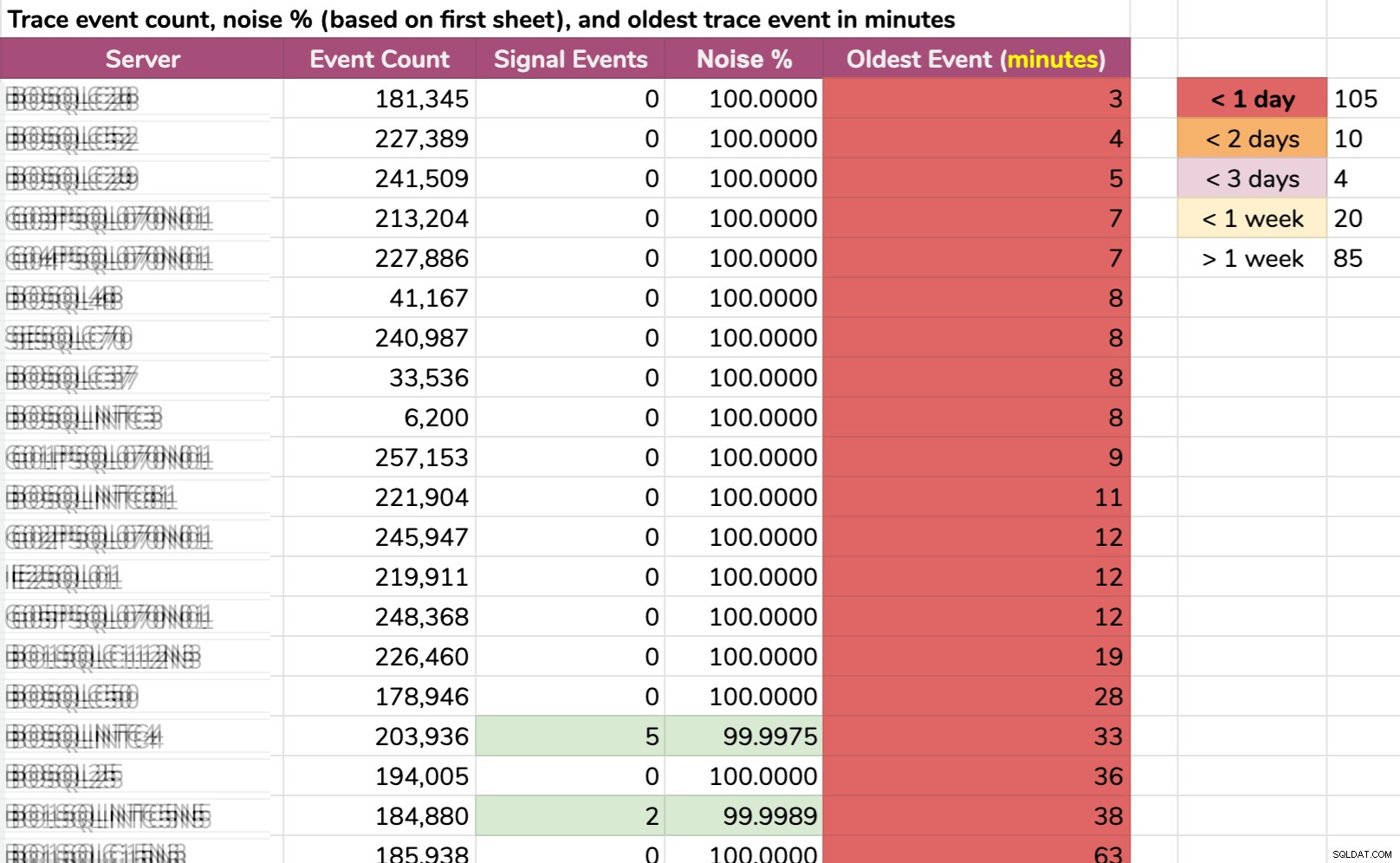
Også selvom sporet kun blev indsamlet relevant info, og der skete noget interessant, vi skulle handle hurtigt for at fange det, afhængigt af serveren. Hvis det skete:
- For 20 minutter siden , så ville den allerede være væk på 15 forekomster .
- denne gang i går , ville den være væk på 105 forekomster .
- for to dage siden , ville den være væk i 115 tilfælde .
- mere end en uge siden , ville det være væk i 139 tilfælde .
Vi havde også en håndfuld servere i den anden ende, men de er uinteressante i denne sammenhæng; disse servere er på den måde, simpelthen fordi der ikke sker noget interessant der (f.eks. er de ikke optaget eller en del af en kritisk arbejdsbyrde).
På plussiden...
Undersøgelsen af standardsporingen afslørede nogle fejlkonfigurationer på et par af vores servere:
- Flere servere havde stadig telemetri aktiveret . Jeg er helt for at hjælpe Microsoft i visse miljøer, men ikke for enhver overhead på forretningskritiske systemer.
- Nogle baggrundssynkroniseringsopgaver var tilføjelse af medlemmer til roller blindt , igen og igen, uden at tjekke om de allerede var i disse roller. Dette er ikke skadeligt i sig selv, især da disse hændelser ikke længere vil fylde standardsporet op, men de fylder sandsynligvis også revisioner med støj, og der er sandsynligvis andre blinde genanvendelsesoperationer, der sker i samme mønster.
- Nogen havde aktiveret autoshrink et eller andet sted (god sorg!), så dette var noget, jeg ville spore op og forhindre i at ske igen (ny XE vil også fange disse begivenheder).
Dette førte til opfølgende opgaver for at løse disse problemer og/eller tilføje betingelser til eksisterende automatisering, der allerede er på plads. Så vi kan forhindre gentagelse uden at stole på bare at være så heldige at komme ud for dem i en fremtidig standardsporingsgennemgang, før de rullede ud.
...men problemet består
Ellers er alt enten information, vi umuligt kan handle på, eller, som beskrevet i grafikken ovenfor, begivenheder, vi allerede fanger andre steder. Og igen, de eneste data, jeg er interesseret i fra standardsporingen, som vi ikke allerede fanger på andre måder, er begivenheder relateret til filvækst og krympning (selvom standardsporingen kun fanger den automatiske sort).
Men det største problem er ikke rigtig mængden af støj. Jeg kan håndtere store massive sporingsfiler med en masse affald, da WHERE-klausuler blev opfundet til netop dette formål. Det virkelige problem er, at vigtige begivenheder forsvandt for hurtigt.
Svaret
Svaret, i hvert fald i vores scenarie, var enkelt:deaktiver standardsporingen, da det ikke er værd at køre, hvis det ikke kan stole på.
Men i betragtning af mængden af støj ovenfor, hvad skal erstatte det? Noget?
Du vil måske have en udvidet begivenhedssession, der fanger alt standardsporet fanget. Hvis ja, har Jonathan Kehayias dig dækket. Dette ville give dig den samme information, men med kontrol over ting som opbevaring, hvor dataene bliver gemt og, efterhånden som du bliver mere komfortabel, muligheden for at fjerne nogle af de mere støjende eller mindre nyttige begivenheder, gradvist over tid.
Min plan var lidt mere aggressiv og blev hurtigt en "simpel" proces til at udføre følgende på alle servere i miljøet (via CMS):
- udvikle en udvidet begivenhedssession, der kun fanger filændringshændelser (både manuel og automatisk)
- deaktiver standardsporingen
- opret en visning for at gøre det nemt for vores teams at forbruge måldata
Bemærk, at Jeg foreslår ikke, at du blindt deaktiverer standardsporingen , bare forklare hvorfor jeg valgte at gøre det i vores miljø. I kommende indlæg i denne serie vil jeg vise den nye udvidede begivenhedssession, visningen, der afslører de underliggende data, koden, jeg brugte til at implementere disse ændringer på alle servere, og potentielle bivirkninger, du bør huske på.
[ Del 1 | Del 2 | Del 3 ]