[ Del 1 | Del 2 | Del 3 | Del 4 ]
I del 3 af denne serie viste jeg to løsninger for at undgå at udvide en IDENTITY kolonne – en, der simpelthen køber dig tid, og en anden, der forlader IDENTITY i det hele taget. Førstnævnte forhindrer dig i at skulle håndtere eksterne afhængigheder såsom fremmednøgler, men sidstnævnte løser stadig ikke dette problem. I dette indlæg ønskede jeg at beskrive den tilgang, jeg ville tage, hvis jeg absolut havde brug for at flytte til bigint , havde brug for at minimere nedetid og havde masser af tid til planlægning.
På grund af alle de potentielle blokkere og behovet for minimal afbrydelse, kan tilgangen ses som lidt kompleks, og det bliver det kun mere, hvis der bruges yderligere eksotiske funktioner (f.eks. partitionering, OLTP i hukommelsen eller replikering) .
På et meget højt niveau er tilgangen at skabe et sæt skyggetabeller, hvor alle indsættelser dirigeres til en ny kopi af tabellen (med den større datatype), og eksistensen af de to sæt tabeller er lige så gennemsigtig. som muligt for applikationen og dens brugere.
På et mere detaljeret niveau ville trinene være som følger:
- Opret skyggekopier af tabellerne med de rigtige datatyper.
- Rediger de lagrede procedurer (eller ad hoc-kode) for at bruge bigint til parametre. (Dette kan kræve ændringer ud over parameterlisten, såsom lokale variabler, temp-tabeller osv., men dette er ikke tilfældet her.)
- Omdøb de gamle tabeller, og opret visninger med de navne, der forbinder de gamle og nye tabeller.
- Disse visninger har i stedet for triggere til korrekt at dirigere DML-handlinger til den eller de relevante tabeller, så data stadig kan ændres under migreringen.
- Dette kræver også, at SCHEMABINDING slettes fra alle indekserede visninger, eksisterende visninger skal have foreninger mellem nye og gamle tabeller, og procedurer, der er afhængige af SCOPE_IDENTITY(), for at blive ændret.
- Migrer de gamle data til de nye tabeller i bidder.
- Ryd op, bestående af:
- Sletning af de midlertidige visninger (hvilket vil droppe ISTEDEN FOR triggere).
- Omdøbning af de nye tabeller tilbage til de oprindelige navne.
- Reparering af de lagrede procedurer for at vende tilbage til SCOPE_IDENTITY().
- Slet de gamle, nu tomme tabeller.
- At sætte SCHEMABINDING tilbage på indekserede visninger og genskabe klyngede indekser.
Du kan sikkert undgå mange af visningerne og triggerne, hvis du kan kontrollere al dataadgang gennem lagrede procedurer, men da det scenarie er sjældent (og umuligt at stole på 100%), vil jeg vise den sværere vej.
Indledende skema
I et forsøg på at holde denne tilgang så enkel som muligt, mens vi stadig adresserer mange af de blokere, jeg nævnte tidligere i serien, lad os antage, at vi har dette skema:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Så en simpel personaletabel med en klynget IDENTITY-kolonne, et ikke-klynget indeks, en beregnet kolonne baseret på IDENTITY-kolonnen, en indekseret visning og en separat HR/snavstabel, der har en fremmednøgle tilbage til personaletabellen (I Jeg opmuntrer ikke nødvendigvis til det design, jeg bruger det bare til dette eksempel). Det er alle ting, der gør dette problem mere kompliceret, end det ville være, hvis vi havde en selvstændig, uafhængig tabel.
Med det skema på plads, har vi sandsynligvis nogle lagrede procedurer, der gør ting som CRUD. Disse er mere for dokumentationens skyld end noget andet; Jeg vil lave ændringer i det underliggende skema, så det skal være minimalt at ændre disse procedurer. Dette er for at simulere det faktum, at det muligvis ikke er muligt at ændre ad hoc SQL fra dine applikationer og måske ikke er nødvendigt (nå, så længe du ikke bruger en ORM, der kan registrere tabel vs. visning).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Lad os nu tilføje 5 rækker med data til de originale tabeller:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Trin 1 – nye tabeller
Her opretter vi et nyt par tabeller, der spejler originalerne med undtagelse af datatypen for EmployeeID-kolonnerne, det indledende startpunkt for IDENTITY-kolonnen og et midlertidigt suffiks på navnene:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Trin 2 – ret procedureparametre
Procedurerne her (og potentielt din ad hoc-kode, medmindre den allerede bruger den større heltalstype) vil have brug for en meget mindre ændring, så de i fremtiden vil være i stand til at acceptere EmployeeID-værdier ud over de øvre grænser for et heltal. Selvom du kan argumentere for, at hvis du vil ændre disse procedurer, kan du blot pege dem mod de nye tabeller, så prøver jeg at argumentere for, at du kan nå det ultimative mål med *minimal* indtrængen i den eksisterende, permanente kode.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Trin 3 – visninger og udløsere
Desværre kan dette ikke *alt* gøres lydløst. Vi kan udføre de fleste operationer parallelt og uden at påvirke samtidig brug, men på grund af SCHEMABINDING skal den indekserede visning ændres og indekset senere genskabes.
Dette gælder for alle andre objekter, der bruger SCHEMABINDING og refererer til en af vores tabeller. Jeg anbefaler at ændre det til at være en ikke-indekseret visning i begyndelsen af operationen og bare genopbygge indekset én gang, efter at alle data er blevet migreret, i stedet for flere gange i processen (da tabeller vil blive omdøbt flere gange). Det, jeg faktisk vil gøre, er at ændre visningen til at forene de nye og gamle versioner af medarbejdertabellen i hele processens varighed.
En anden ting, vi skal gøre, er at ændre Employee_Add lagret procedure til at bruge @@IDENTITY i stedet for SCOPE_IDENTITY(), midlertidigt. Dette skyldes, at INSTEAD OF-udløseren, der vil håndtere nye opdateringer til "Medarbejdere", ikke vil have synlighed af SCOPE_IDENTITY()-værdien. Dette forudsætter selvfølgelig, at tabellerne ikke har efter-triggere, der vil påvirke @@IDENTITY. Forhåbentlig kan du enten ændre disse forespørgsler i en lagret procedure (hvor du blot kan pege INSERT mod den nye tabel), eller din applikationskode behøver ikke at stole på SCOPE_IDENTITY() i første omgang.
Vi vil gøre dette under SERIALIZABLE, så ingen transaktioner forsøger at snige sig ind, mens objekterne er i bevægelse. Dette er et sæt operationer, der stort set kun er metadata, så det burde være hurtigt.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Trin 4 – Migrer gamle data til ny tabel
Vi vil migrere data i bidder for at minimere indvirkningen på både samtidighed og transaktionsloggen, idet vi låner den grundlæggende teknik fra et gammelt indlæg af mig, "Opdel store sletningsoperationer i bidder." Vi vil også udføre disse batches i SERIALIZABLE, hvilket betyder, at du skal være forsigtig med batchstørrelsen, og jeg har udeladt fejlhåndtering for kortheds skyld.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Resultater:
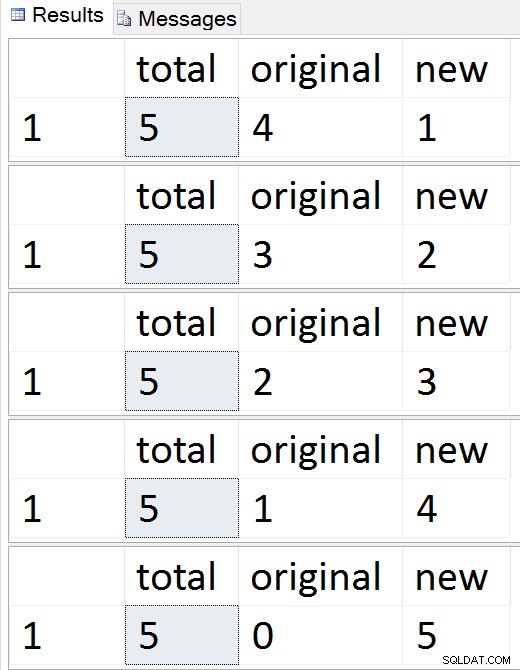 Se rækkerne migrere én efter én
Se rækkerne migrere én efter én
Du kan til enhver tid i løbet af denne sekvens teste indsættelser, opdateringer og sletninger, og de skal håndteres korrekt. Når migreringen er fuldført, kan du gå videre til resten af processen.
Trin 5 – Ryd op
En række trin er påkrævet for at rydde op i de objekter, der blev oprettet midlertidigt, og for at gendanne Medarbejdere / EmployeeFile som ordentlige, førsteklasses borgere. Mange af disse kommandoer er simpelthen metadata-operationer – med undtagelse af at oprette det klyngede indeks på den indekserede visning, bør de alle være øjeblikkelige.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO På dette tidspunkt skulle alt være tilbage til normal drift, selvom du måske vil overveje typiske vedligeholdelsesaktiviteter efter større skemaændringer, såsom opdatering af statistikker, genopbygning af indekser eller fjernelse af planer fra cachen.
Konklusion
Dette er en ret kompleks løsning på, hvad der burde være et simpelt problem. Jeg håber, at SQL Server på et tidspunkt gør det muligt at gøre ting som at tilføje/fjerne IDENTITY-egenskaben, genopbygge indekser med nye måldatatyper og ændre kolonner på begge sider af et forhold uden at ofre forholdet. I mellemtiden vil jeg være interesseret i at høre, om enten denne løsning hjælper dig, eller om du har en anden tilgang.
Stort shout-out til James Lupolt (@jlupoltsql) for at hjælpe fornuften med at tjekke min tilgang og sætte den på den ultimative prøve på et af hans egne, rigtige borde. (Det gik godt. Tak James!)
—
[ Del 1 | Del 2 | Del 3 | Del 4 ]