Jeg er begyndt at skrive om værktøjet (pglupgrade), som jeg udviklede til at udføre automatiserede opgraderinger af PostgreSQL-klynger med næsten nul nedetid. I dette indlæg vil jeg tale om værktøjet og diskutere dets designdetaljer.
Du kan se den første del af serien her: Near-Zero Downtime Automated Upgrades of PostgreSQL Clusters in Cloud (Del I).

Værktøjet er skrevet i Ansible. Jeg har tidligere erfaring med at arbejde med Ansible, og jeg arbejder i øjeblikket med det i 2ndQuadrant også, hvorfor det var en behagelig mulighed for mig. Når det er sagt, kan du implementere den minimale nedetidsopgraderingslogik, som vil blive forklaret senere i dette indlæg, med dit foretrukne automatiseringsværktøj.
Yderligere læsning:Blogindlæg Ansible elsker PostgreSQL , PostgreSQL Planet i Ansible Galaxy og præsentation administration af PostgreSQL med Ansible.
Pglupgrade Playbook
I Ansible, playbooks er de vigtigste scripts, der er udviklet til at automatisere processerne, såsom levering af cloud-instanser og opgradering af databaseklynger. Playbooks kan indeholde et eller flere afspil . Playbooks kan også indeholde variabler , roller , og handlere hvis defineret.
Værktøjet består af to hovedspilbøger. Den første spillebog er provision.yml der automatiserer processen til oprettelse af Linux-maskiner i skyen i henhold til specifikationerne (Dette er en valgfri afspilningsbog, der kun er skrevet til levering af cloud-forekomster og ikke er direkte relateret til opgraderingen ). Den anden (og den vigtigste) spillebog er pglupgrade.yml der automatiserer opgraderingsprocessen af databaseklynger.
Pglupgrade playbook har otte afspilninger til at orkestrere opgraderingen. Hver af afspilningerne, brug én konfigurationsfil (config.yml ), udføre nogle opgaver på værterne eller værtsgrupperne, der er defineret i værts inventory file (host.ini ).
Inventarfil
En inventarfil lader Ansible vide, hvilke servere den skal forbinde ved hjælp af SSH, hvilke forbindelsesoplysninger den kræver, og eventuelt hvilke variabler der er knyttet til disse servere. Nedenfor kan du se en prøveopgørelsesfil, der er blevet brugt til at udføre automatiske klyngeopgraderinger til et af casestudierne designet til værktøjet. Vi vil diskutere disse casestudier i kommende indlæg i denne serie.
[old-primary]54.171.211.188[new-primary]54.246.183.100[old-standbys]54.77.249.8154.154.49.180[new-standbys:children]old-standbys[pgbouncer.54.18].>Inventarfil (
host.ini)Eksempelbeholdningsfilen indeholder fem værter under fem værtsgrupper der inkluderer
old-primary,new-primary,old-standbys,new-standbysogpgbouncer. En server kan tilhøre mere end én gruppe. For eksempelold-standbyser en gruppe, der indeholdernew-standbysgruppe, hvilket betyder de værter, der er defineret underold-standbysgruppen (54.77.249.81 og 54.154.49.180) hører også tilnew-standbysgruppe. Med andre ord,new-standbysgruppe er arvet fra (børn af)old-standbysgruppe. Dette opnås ved at bruge den specielle:childrensuffiks.Når inventarfilen er klar, kan Ansible playbook køre via
ansible-playbookkommando ved at pege på inventarfilen (hvis inventarfilen ikke er placeret på standardplaceringen, ellers vil den bruge standardinventarfilen) som vist nedenfor:$ ansible-playbook -i hosts.ini pglupgrade.ymlKørsel af en Ansible-afspilningsbog
Konfigurationsfil
Pglupgrade playbook bruger en konfigurationsfil (
config.yml), der giver brugerne mulighed for at angive værdier for de logiske opgraderingsvariabler.Som vist nedenfor er
config.ymlgemmer hovedsageligt PostgreSQL-specifikke variabler, der er nødvendige for at konfigurere en PostgreSQL-klynge såsompostgres_old_datadirogpostgres_new_datadirat gemme stien til PostgreSQL-databiblioteket for den gamle og nye PostgreSQL-version;postgres_new_confdirat gemme stien til PostgreSQL-konfigurationsmappen for den nye PostgreSQL-version;postgres_old_dsnogpostgres_new_dsnfor at gemme forbindelsesstrengen forpglupgrade_userfor at kunne oprette forbindelse tilpglupgrade_databaseaf de nye og de gamle primære servere. Selve forbindelsesstrengen består af de konfigurerbare variabler, så brugeren (pglupgrade_user) og databasen (pglupgrade_database) oplysninger kan ændres for de forskellige brugssager.ansible_user:adminpglupgrade_user:pglupgradepglupgrade_pass:pglupgrade123pglupgrade_database:postgresreplica_user:postgresreplica_pass:""pgbouncer_user:pgbouncerpostgres_old_version:9.5postgres_new_version:9.6subscription_name:upgradereplication_set:upgradeinitial_standbys:1postgres_old_dsn:"dbname={{pglupgrade_database}} host={{groups['old- primær'][0]}} bruger {{pglupgrade_user}}"postgres_new_dsn:"dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} bruger={{pglupgrade_user}}" postgres_old_datadir:"/var/lib/postgresql/{{postgres_old_version}}/main" postgres_new_datadir:"/var/lib/postgresql/{{postgres_new_version}}/main"postgres_new_confdir:"/etc/postgresql/_new{_postgres}} hoved"Konfigurationsfil (
config.yml)Som et nøgletrin for enhver opgradering kan PostgreSQL-versionsoplysningerne specificeres for den aktuelle version (
postgres_old_version) og den version, der vil blive opgraderet til (postgres_new_version). I modsætning til fysisk replikering, hvor replikeringen er en kopi af systemet på byte-/blokniveau, tillader logisk replikering selektiv replikering hvor replikeringen kan kopiere de logiske data, omfatter specificerede databaser og tabellerne i disse databaser. Af denne grund,config.ymlgør det muligt at konfigurere hvilken database der skal replikeres viapglupgrade_databasevariabel. Desuden skal logisk replikeringsbruger have replikeringsrettigheder, hvilket er grunden tilpglupgrade_uservariabel skal angives i konfigurationsfilen. Der er andre variabler, der er relateret til arbejdende internals af pglogical, såsomsubscription_nameogreplication_setsom bruges i den pglogiske rolle.Højtilgængelighedsdesign af Pglupgrade-værktøjet
Pglupgrade-værktøjet er designet til at give brugeren fleksibilitet med hensyn til High Availability (HA)-egenskaber til de forskellige systemkrav.
initial_standbysvariabel (seconfig.yml) er nøglen til at udpege HA-egenskaber for klyngen, mens opgraderingen foregår.For eksempel, hvis
initial_standbyser sat til 1 (kan indstilles til et hvilket som helst tal, som klyngekapaciteten tillader), det betyder, at der oprettes 1 standby i den opgraderede klynge sammen med masteren, før replikeringen starter. Med andre ord, hvis du har 4 servere, og du indstiller initial_standbys til 1, vil du have 1 primær og 1 standby-server i den opgraderede nye version, samt 1 primær og 1 standby-server i den gamle version.Denne mulighed gør det muligt at genbruge de eksisterende servere, mens opgraderingen stadig foregår. I eksemplet med 4 servere kan de gamle primære og standby-servere genopbygges som 2 nye standby-servere, efter at replikeringen er afsluttet.
Når
initial_standbysvariabel er sat til 0, vil der ikke være oprettet nogen initial standby-servere i den nye klynge, før replikeringen starter.Hvis
initial_standbyskonfigurationen lyder forvirrende, bare rolig. Dette vil blive forklaret bedre i det næste blogindlæg, når vi diskuterer to forskellige casestudier.Endelig tillader konfigurationsfilen at specificere gamle og nye servergrupper. Dette kan tilvejebringes på to måder. For det første, hvis der er en eksisterende klynge, IP-adresser på serverne (kan være enten bare-metal eller virtuelle servere ) skal indtastes i
hosts.inifil ved at overveje ønskede HA-egenskaber under opgradering.Den anden måde er at køre
provision.ymlplaybook (det er sådan, jeg klargjorde cloud-forekomsterne, men du kan bruge dine egne klargøringsscripts eller manuelt klargøre forekomster ) for at klargøre tomme Linux-servere i skyen (AWS EC2-forekomster) og få servernes IP-adresser ind ihosts.inifil. Uanset hvad,config.ymlvil få værtsoplysninger gennemhosts.inifil.Opgraderingsprocessens arbejdsgang
Efter at have forklaret konfigurationsfilen (
config.yml) som bruges af pglupgrade playbook, kan vi forklare arbejdsgangen i opgraderingsprocessen.
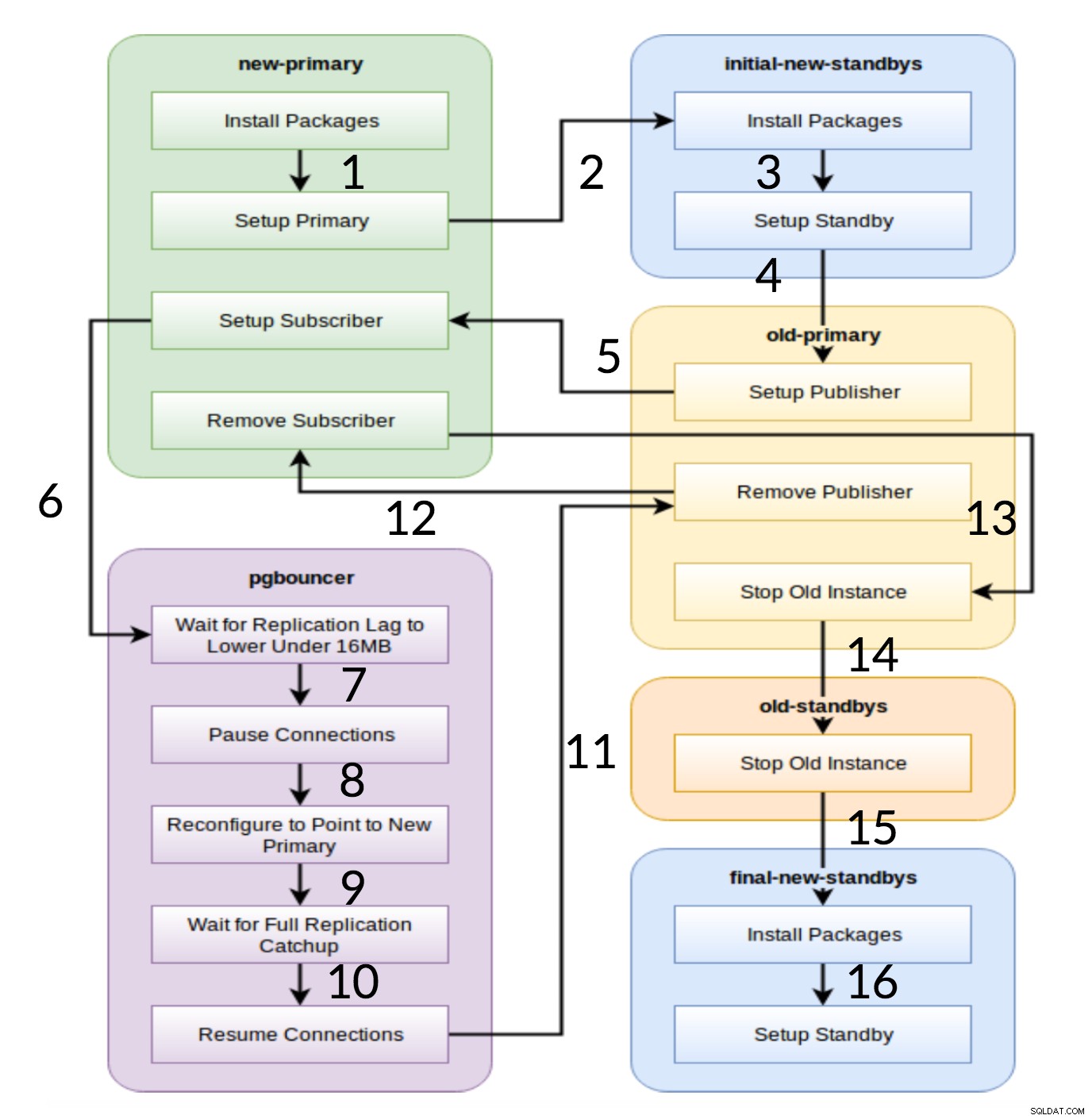
Pglupgrade Workflow
Som det ses af diagrammet ovenfor, er der seks servergrupper, der genereres i begyndelsen baseret på konfigurationen (begge
hosts.iniogconfig.yml). Dennew-primaryogold-primarygrupper vil altid have én server,pgbouncergruppe kan have en eller flere servere, og alle standby-grupper kan have nul eller flere servere i dem. Implementeringsmæssigt er hele processen opdelt i otte trin. Hvert trin svarer til et spil i pglupgrade-afspilningsbogen, som udfører de nødvendige opgaver på de tildelte værtsgrupper. Opgraderingsprocessen forklares gennem følgende afspilninger:
- Byg værter baseret på konfiguration: Forberedelsesspil som bygger interne grupper af servere baseret på konfigurationen. Resultatet af dette spil (i kombination med
hosts.ini). indhold) er de seks servergrupper (illustreret med forskellige farver i arbejdsflowdiagrammet), som vil blive brugt af de følgende syv afspilninger.- Konfigurer ny klynge med indledende standby(er): Opretter en tom PostgreSQL-klynge med den eller de nye primære og indledende standby(er) (hvis der er defineret nogen). Det sikrer, at der ikke er noget tilbage fra PostgreSQL-installationer fra den tidligere brug.
- Rediger den gamle primære for at understøtte logisk replikering: Installerer pglogical extension. Indstiller derefter udgiveren ved at tilføje alle tabeller og sekvenser til replikeringen.
- Repliker til den nye primære: Opsætter abonnenten på den nye master, som fungerer som en trigger for at starte logisk replikering. Denne afspilning afslutter replikeringen af de eksisterende data og begynder at indhente, hvad der er ændret, siden det startede replikeringen.
- Skift pgbouncer (og programmer) til ny primær: Når replikeringsforsinkelsen konvergerer til nul, pauser pgbounceren for gradvist at skifte applikationen. Derefter peger den pgbouncer config til den nye primære og venter, indtil replikeringsforskellen bliver nul. Til sidst genoptages pgbouncer, og alle ventende transaktioner overføres til den nye primære og begynder at behandle der. Indledende standby-tilstande er allerede i brug og besvarer læseanmodninger.
- Ryd op i replikeringsopsætningen mellem gammel primær og ny primær: Afbryder forbindelsen mellem den gamle og den nye primære server. Da alle applikationer flyttes til den nye primære server, og opgraderingen er udført, er logisk replikering ikke længere nødvendig. Replikering mellem primære og standby-servere fortsættes med fysisk replikering.
- Stop den gamle klynge: Postgres-tjenesten er stoppet i gamle værter for at sikre, at ingen applikationer kan oprette forbindelse til den længere.
- Genkonfigurer resten af standbys for den nye primære: Genopbygger andre standbys, hvis der er nogen resterende værter ud over indledende standbys. I det andet casestudie er der ingen resterende standby-servere at genopbygge. Dette trin giver mulighed for at genopbygge den gamle primære server som en ny standby, hvis det peges i gruppen med nye standbys på hosts.ini. Genanvendeligheden af eksisterende servere (selv den gamle primære) opnås ved at bruge to-trins standby-konfigurationsdesignet af pglupgrade-værktøjet. Brugeren kan angive, hvilke servere der skal blive standbys for den nye klynge før opgraderingen, og hvilke der skal blive standbys efter opgraderingen.
Konklusion
I dette indlæg diskuterede vi implementeringsdetaljerne og det høje tilgængelighedsdesign af pglupgrade-værktøjet. I den forbindelse nævnte vi også nogle få nøglekoncepter for Ansible-udvikling (dvs. playbook, inventar og konfigurationsfiler) ved at bruge værktøjet som eksempel. Vi illustrerede arbejdsgangen i opgraderingsprocessen og opsummerede, hvordan hvert trin fungerer med et tilsvarende spil. Vi vil fortsætte med at forklare pglupgrade ved at vise casestudier i kommende indlæg i denne serie.
Tak fordi du læste med!