I sidste uge publicerede jeg et indlæg kaldet #BackToBasics :DATEFROMPARTS() , hvor jeg viste, hvordan man bruger denne 2012+ funktion til renere, sargable datointervalforespørgsler. Jeg brugte det til at demonstrere, at hvis du bruger et åbent datoprædikat, og du har et indeks på den relevante dato/klokkeslæt kolonne, kan du ende med meget bedre indeksforbrug og lavere I/O (eller i værste fald , det samme, hvis en søgning ikke kan bruges af en eller anden grund, eller hvis der ikke findes et passende indeks):
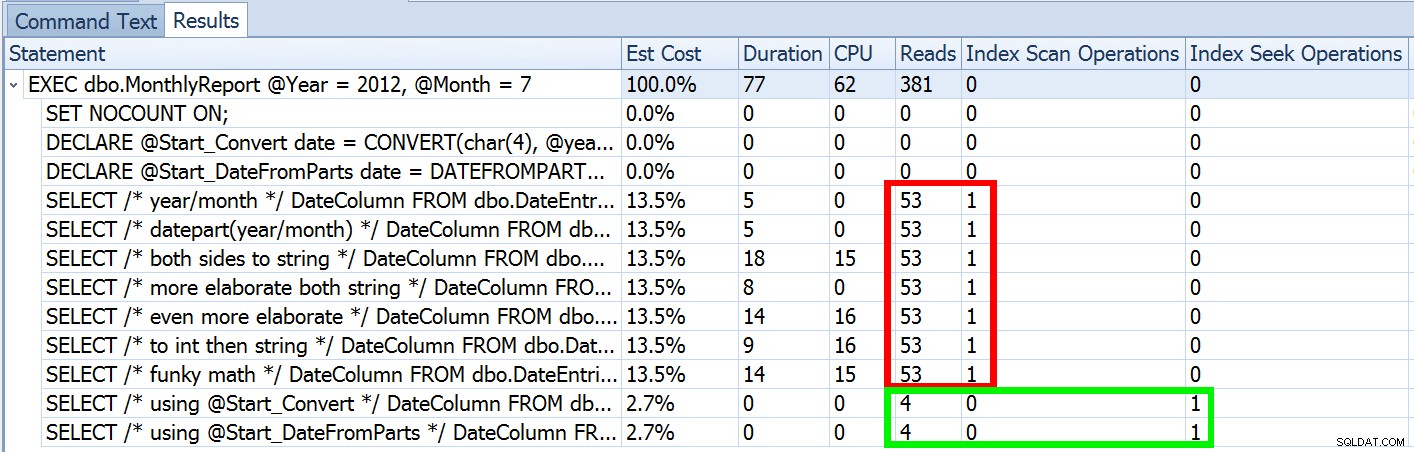
Men det er kun en del af historien (og for at være klar, DATEFROMPARTS() er ikke teknisk påkrævet for at få en søgning, det er bare renere i så fald). Hvis vi zoomer lidt ud, bemærker vi, at vores estimater er langt fra nøjagtige, en kompleksitet, jeg ikke ønskede at introducere i det forrige indlæg:
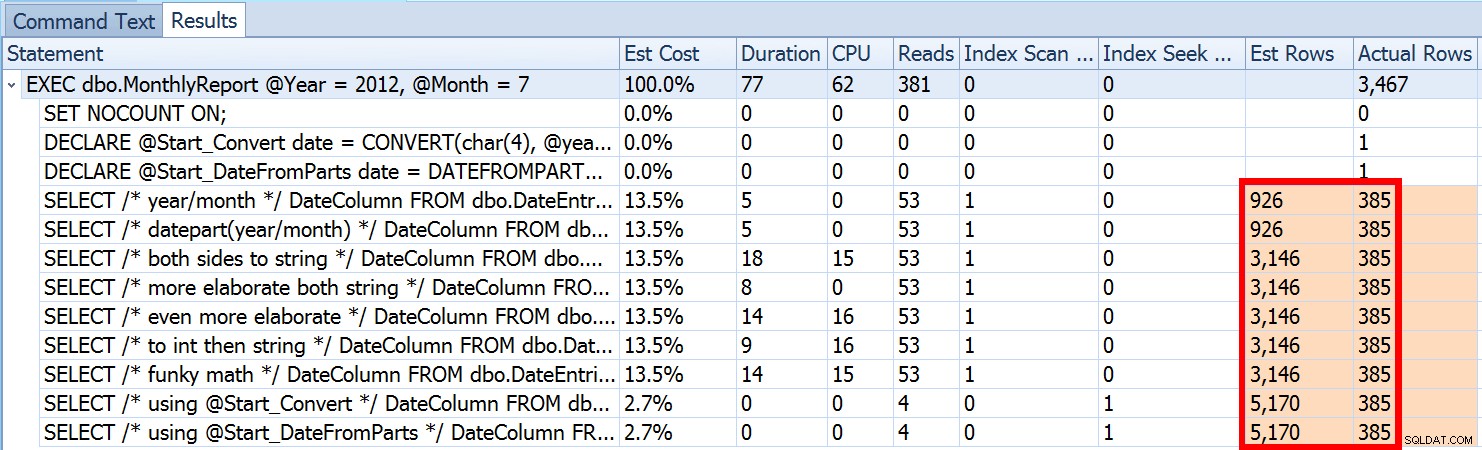
Dette er ikke ualmindeligt for både ulighedsprædikater og med tvungne scanninger. Og selvfølgelig, ville den metode, jeg foreslog, ikke give den mest unøjagtige statistik? Her er den grundlæggende tilgang (du kan få tabelskemaet, indekser og eksempeldata fra mit tidligere indlæg):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Nu vil unøjagtige estimater ikke altid være et problem, men det kan forårsage problemer med ineffektive planvalg i de to yderpunkter. En enkelt plan er muligvis ikke optimal, når det valgte interval vil give en meget lille eller meget stor procentdel af tabellen eller indekset, og det kan blive meget svært for SQL Server at forudsige, hvornår datafordelingen er ujævn. Joseph Sack skitserede de mere typiske ting, dårlige estimater kan påvirke i sit indlæg, "Ti almindelige trusler mod kvaliteten af eksekveringsplanen:"
"[...] dårlige rækkeestimater kan påvirke en række beslutninger, herunder valg af indeks, søgning vs. scanningsoperationer, parallel versus seriel udførelse, valg af joinalgoritmer, valg af indre vs. ydre fysisk sammenføjning (f.eks. build vs. sonde), spoolgenerering, bogmærkeopslag vs. fuld klynge- eller heap-tabeladgang, strøm- eller hash-samlet valg, og om en dataændring bruger en bred eller smal plan."
Der er også andre, såsom hukommelsesstipendier, der er for store eller for små. Han fortsætter med at beskrive nogle af de mere almindelige årsager til dårlige skøn, men den primære årsag i dette tilfælde mangler på hans liste:gæt. Fordi vi bruger en lokal variabel til at ændre den indgående int parametre til en enkelt lokal date variabel, ved SQL Server ikke, hvad værdien vil være, så den foretager standardiserede gæt på kardinalitet baseret på hele tabellen.
Vi så ovenfor, at estimatet for min foreslåede tilgang var 5.170 rækker. Nu ved vi, at med et ulighedsprædikat, og med SQL Server, der ikke kender parameterværdierne, vil den gætte 30% af tabellen. 31,645 * 0.3 er ikke 5.170. Det er heller ikke 31,465 * 0.3 * 0.3 , når vi husker, at der faktisk er to prædikater, der arbejder mod den samme kolonne. Så hvor kommer denne værdi på 5.170 fra?
Som Paul White beskriver i sit indlæg, "Cardinality Estimation for Multiple Predicates", bruger den nye kardinalitetsestimator i SQL Server 2014 eksponentiel backoff, så den multiplicerer rækkeantallet i tabellen (31.465) med selektiviteten af det første prædikat (0,3) , og gange derefter det med kvadratroden af selektiviteten af det andet prædikat (~0,547723).
31.645 * (0.3) * SQRT(0.3) ~=5.170.227Så nu kan vi se, hvor SQL Server kom med sit estimat; hvad er nogle af de metoder, vi kan bruge til at gøre noget ved det?
- Indtast datoparametre. Når det er muligt, kan du ændre applikationen, så den passerer i korrekte datoparametre i stedet for separate heltalsparametre.
- Brug en indpakningsprocedure. En variation af metode #1 – for eksempel hvis du ikke kan ændre applikationen – ville være at oprette en anden lagret procedure, der accepterer konstruerede datoparametre fra den første.
- Brug
OPTION (RECOMPILE). Med små omkostninger ved kompilering, hver gang forespørgslen køres, tvinger dette SQL Server til at optimere baseret på de værdier, der præsenteres hver gang, i stedet for at optimere en enkelt plan for ukendte, første eller gennemsnitlige parameterværdier. (For en grundig behandling af dette emne, se Paul Whites "Parameter Sniffing, Embedding, and the RECOMPILE Options."
- Brug dynamisk SQL. At have dynamisk SQL accepterer den konstruerede
datevariabel fremtvinger korrekt parametrering (ligesom hvis du havde kaldt en lagret procedure med endateparameter), men den er lidt grim og sværere at vedligeholde.
- Rodder med hints og sporingsflag. Paul White fortæller om nogle af disse i det førnævnte indlæg.
Jeg vil ikke foreslå, at dette er en udtømmende liste, og jeg vil ikke gentage Pauls råd om hints eller sporingsflag, så jeg vil kun fokusere på at vise, hvordan de første fire tilgange kan afbøde problemet med dårlige skøn .
1. Datoparametre
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Indpakningsprocedure
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. MULIGHED (GENKOMPILER)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Dynamisk SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Testene
Med de fire sæt procedurer på plads var det nemt at konstruere tests, der kunne vise mig planerne og estimaterne, som SQL Server udledte. Da nogle måneder er mere travle end andre, valgte jeg tre forskellige måneder og udførte dem alle flere gange.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Resultatet? Hver enkelt plan giver det samme indekssøgning, men estimaterne er kun korrekte på tværs af alle tre datointervaller i OPTION (RECOMPILE) version. Resten fortsætter med at bruge estimaterne afledt af det første sæt parametre (juli 2012), og så mens de får bedre estimater for den første udførelse, vil det estimat ikke nødvendigvis være bedre for efterfølgende eksekveringer ved hjælp af forskellige parametre (et klassisk, lærebogstilfælde af parametersniffing):
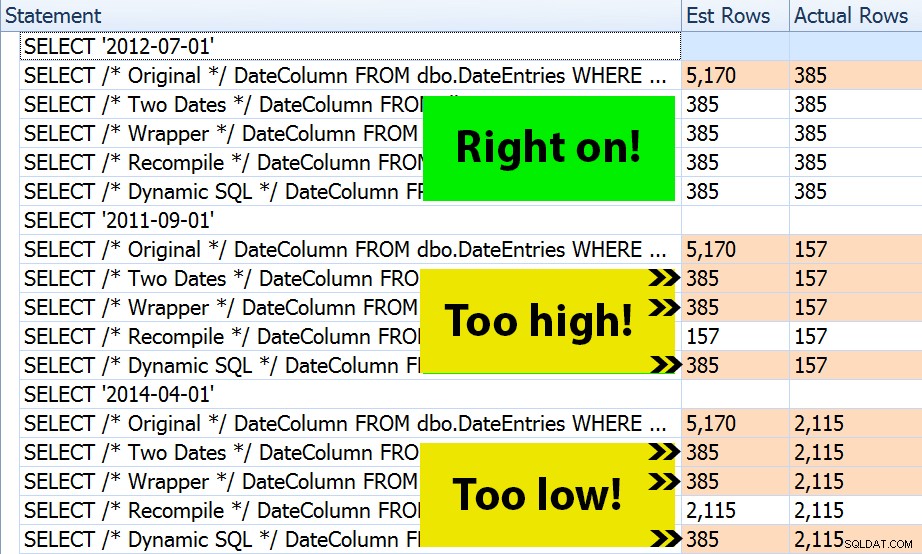
Bemærk, at ovenstående ikke er *præcis* output fra SQL Sentry Plan Explorer – for eksempel fjernede jeg sætningstrærækkerne, der viste de ydre lagrede procedurekald og parametererklæringer.
Det vil være op til dig at afgøre, om taktikken med at kompilere hver gang er bedst for dig, eller om du skal "rette" noget i første omgang. Her endte vi med de samme planer og ingen mærkbare forskelle i runtime-ydeevnemålinger. Men på større tabeller, med mere skæv datafordeling og større varianser i prædikatværdier (overvej f.eks. en rapport, der kan dække en uge, et år og alt derimellem), kan det være værd at undersøge. Og bemærk, at du kan kombinere metoder her - for eksempel kan du skifte til korrekte datoparametre *og* tilføje OPTION (RECOMPILE) , hvis du ville.
Konklusion
I dette specifikke tilfælde, som er en bevidst forenkling, gav indsatsen for at få de korrekte estimater ikke rigtig pote – vi fik ikke en anden plan, og runtime-ydelsen var tilsvarende. Der er dog helt sikkert andre tilfælde, hvor dette vil gøre en forskel, og det er vigtigt at erkende estimatforskelle og afgøre, om det kan blive et problem, efterhånden som dine data vokser og/eller din distribution skævvokser. Desværre er der ikke noget sort-hvidt svar, da mange variabler vil påvirke, om kompileringsomkostninger er berettiget – som med mange scenarier, IT DEPENDS™ …