Når vi arbejder i IT-branchen, har vi sikkert hørt ordet "failover" mange gange, men det kan også rejse spørgsmål som:Hvad er egentlig en failover? Hvad kan vi bruge det til? Er det vigtigt at have det? Hvordan kan vi gøre det?
Selvom de kan virke ret grundlæggende spørgsmål, er det vigtigt at tage højde for dem i ethvert databasemiljø. Og oftere end ikke tager vi ikke højde for det grundlæggende...
Lad os til at begynde med se på nogle grundlæggende begreber.
Hvad er Failover?
Failover er et systems evne til at fortsætte med at fungere, selvom der opstår en fejl. Det antyder, at systemets funktioner overtages af sekundære komponenter, hvis de primære komponenter svigter.
I tilfælde af PostgreSQL er der forskellige værktøjer, der giver dig mulighed for at implementere en databaseklynge, der er modstandsdygtig over for fejl. En redundansmekanisme, der er tilgængelig native i PostgreSQL, er replikering. Og nyheden i PostgreSQL 10 er implementeringen af logisk replikering.
Hvad er replikering?
Det er processen med at kopiere og holde dataene opdateret i en eller flere databasenoder. Den bruger et koncept med en masterknude, der modtager ændringerne, og slaveknudepunkter, hvor de replikeres.
Vi har flere måder at kategorisere replikering på:
- Synkron replikering:Der er intet tab af data, selvom vores masterknude går tabt, men commits i masteren skal vente på en bekræftelse fra slaven, hvilket kan påvirke ydeevnen.
- Asynkron replikering:Der er mulighed for tab af data, hvis vi mister vores masterknude. Hvis replikaen af en eller anden grund ikke er opdateret på tidspunktet for hændelsen, kan den information, der ikke er blevet kopieret, gå tabt.
- Fysisk replikering:Diskblokke kopieres.
- Logisk replikering:Streaming af dataændringerne.
- Varme Standby-slaver:De understøtter ikke forbindelser.
- Hot Standby Slaves:Understøtter skrivebeskyttede forbindelser, nyttige til rapporter eller forespørgsler.
Hvad bruges Failover til?
Der er flere mulige anvendelser af failover. Lad os se nogle eksempler.
Migrering
Hvis vi ønsker at migrere fra et datacenter til et andet ved at minimere vores nedetid, kan vi bruge failover.
Antag, at vores master er i datacenter A, og vi ønsker at migrere vores systemer til datacenter B.
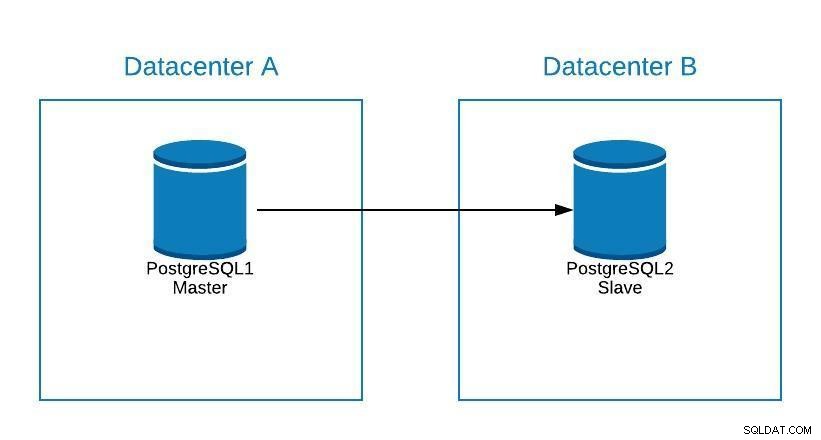 Migreringsdiagram 1
Migreringsdiagram 1 Vi kan oprette en replika i datacenter B. Når den er synkroniseret, skal vi stoppe vores system, promovere vores replika til ny master og failover, før vi peger vores system til den nye master i datacenter B.
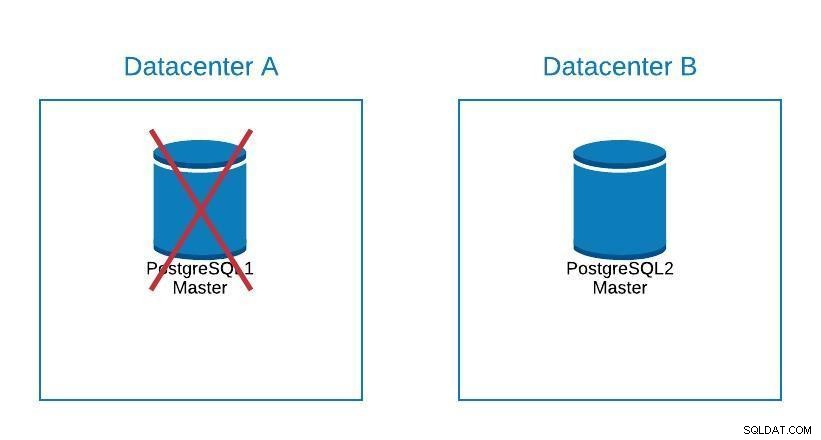 Migreringsdiagram 2
Migreringsdiagram 2 Failover handler ikke kun om databasen, men også applikationen/applikationerne. Hvordan ved de, hvilken database de skal oprette forbindelse til? Vi ønsker bestemt ikke at skulle ændre vores applikation, da dette kun vil forlænge vores nedetid.. Så vi kan konfigurere en load balancer, så når vi tager vores master ned, vil den automatisk pege på den næste server, der er fremmet.
En anden mulighed er brugen af DNS. Ved at promovere masterreplikaen i det nye datacenter, ændrer vi direkte IP-adressen på det værtsnavn, der peger på masteren. På den måde undgår vi at skulle ændre vores applikation, og selvom det ikke kan gøres automatisk, er det et alternativ, hvis vi ikke ønsker at implementere en load balancer.
At have en enkelt load balancer-instans er ikke fantastisk, da det kan blive et enkelt fejlpunkt. Derfor kan du også implementere failover for belastningsbalanceren ved at bruge en service som keepalved. På denne måde, hvis vi har et problem med vores primære load balancer, er keepalived ansvarlig for at migrere IP'en til vores sekundære load balancer, og alt fortsætter med at fungere gennemsigtigt.
Vedligeholdelse
Hvis vi skal udføre vedligeholdelse på vores postgreSQL-masterdatabaseserver, kan vi promovere vores slave, udføre opgaven og rekonstruere en slave på vores gamle master.
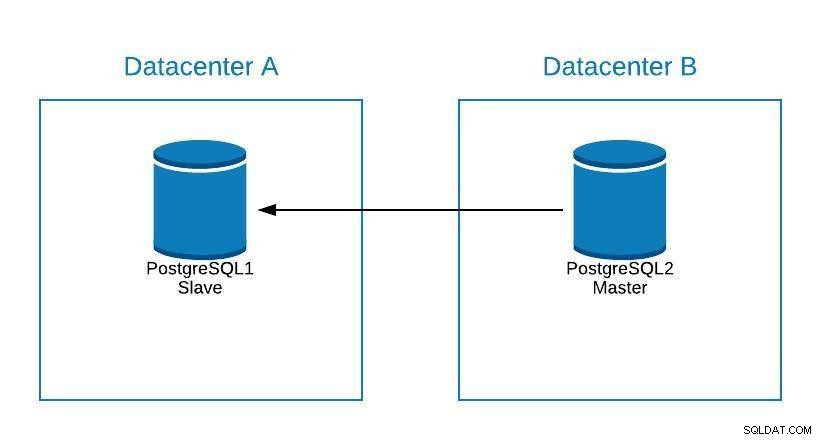 Vedligeholdelsesdiagram 1
Vedligeholdelsesdiagram 1 Efter dette kan vi re-promovere den gamle mester og gentage genopbygningsprocessen for slaven, og vende tilbage til den oprindelige tilstand.
Vedligeholdelsesdiagram 2 På denne måde kunne vi arbejde på vores server uden at risikere at være offline eller miste information, mens vi udfører vedligeholdelse.
Opgrader
Selvom PostgreSQL 11 endnu ikke er tilgængelig, ville det teknisk set være muligt at opgradere fra PostgreSQL version 10 ved hjælp af logisk replikering, da det kan gøres med andre motorer.
Trinnene ville være de samme som at migrere til et nyt datacenter (se migrationsafsnittet), kun at vores slave ville være i PostgreSQL 11.
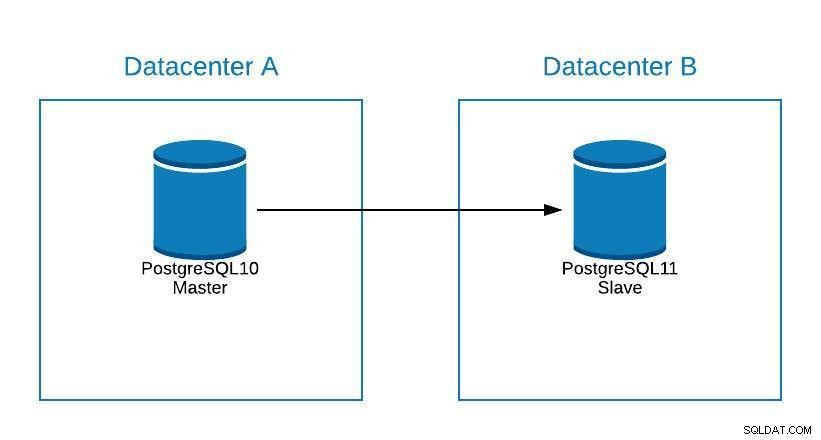 Opgraderingsdiagram 1
Opgraderingsdiagram 1 Problemer
Den vigtigste funktion af failover er at minimere vores nedetid eller undgå tab af information, når der er problemer med vores hoveddatabase.
Hvis vi af en eller anden grund mister vores masterdatabase, kan vi udføre en failover for at promovere vores slave til master og holde vores systemer kørende.
For at gøre dette giver PostgreSQL os ikke nogen automatiseret løsning. Vi kan gøre det manuelt eller automatisere det ved hjælp af et script eller et eksternt værktøj.
For at fremme vores slave til herre:
-
Kør pg_ctl promote
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Opret en fil trigger_file, som vi skal have tilføjet i recovery.conf i vores datamappe.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
For at implementere en failover-strategi er vi nødt til at planlægge den og grundigt teste gennem forskellige fejlscenarier. Da fejl kan ske på forskellige måder, og løsningen burde ideelt set fungere til de fleste af de almindelige scenarier. Hvis vi leder efter en måde at automatisere dette på, kan vi tage et kig på, hvad ClusterControl har at tilbyde.
ClusterControl for PostgreSQL-failover
ClusterControl har en række funktioner relateret til PostgreSQL-replikering og automatiseret failover.
Tilføj slave
Hvis vi ønsker at tilføje en slave i et andet datacenter, enten som en nødsituation eller for at migrere dine systemer, kan vi gå til Cluster Actions og vælge Tilføj replikeringsslave.
 ClusterControl Tilføj slave 1
ClusterControl Tilføj slave 1 Vi bliver nødt til at indtaste nogle grundlæggende data, såsom IP eller værtsnavn, datakatalog (valgfrit), synkron eller asynkron slave. Vi burde have vores slave i gang efter et par sekunder.
I tilfælde af brug af et andet datacenter, anbefaler vi at oprette en asynkron slave, da latensen ellers kan påvirke ydeevnen betydeligt.
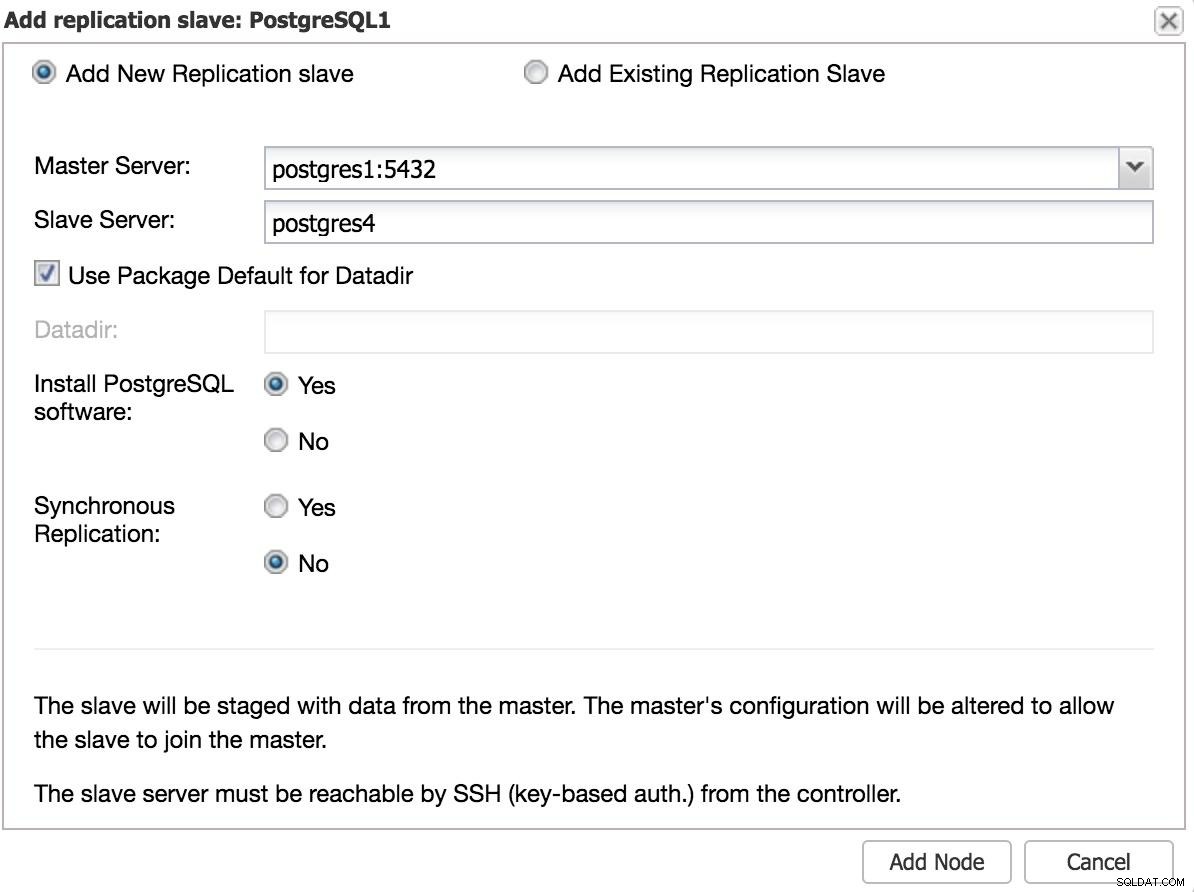 ClusterControl Tilføj slave 2
ClusterControl Tilføj slave 2 Manuel failover
Med ClusterControl kan failover udføres manuelt eller automatisk.
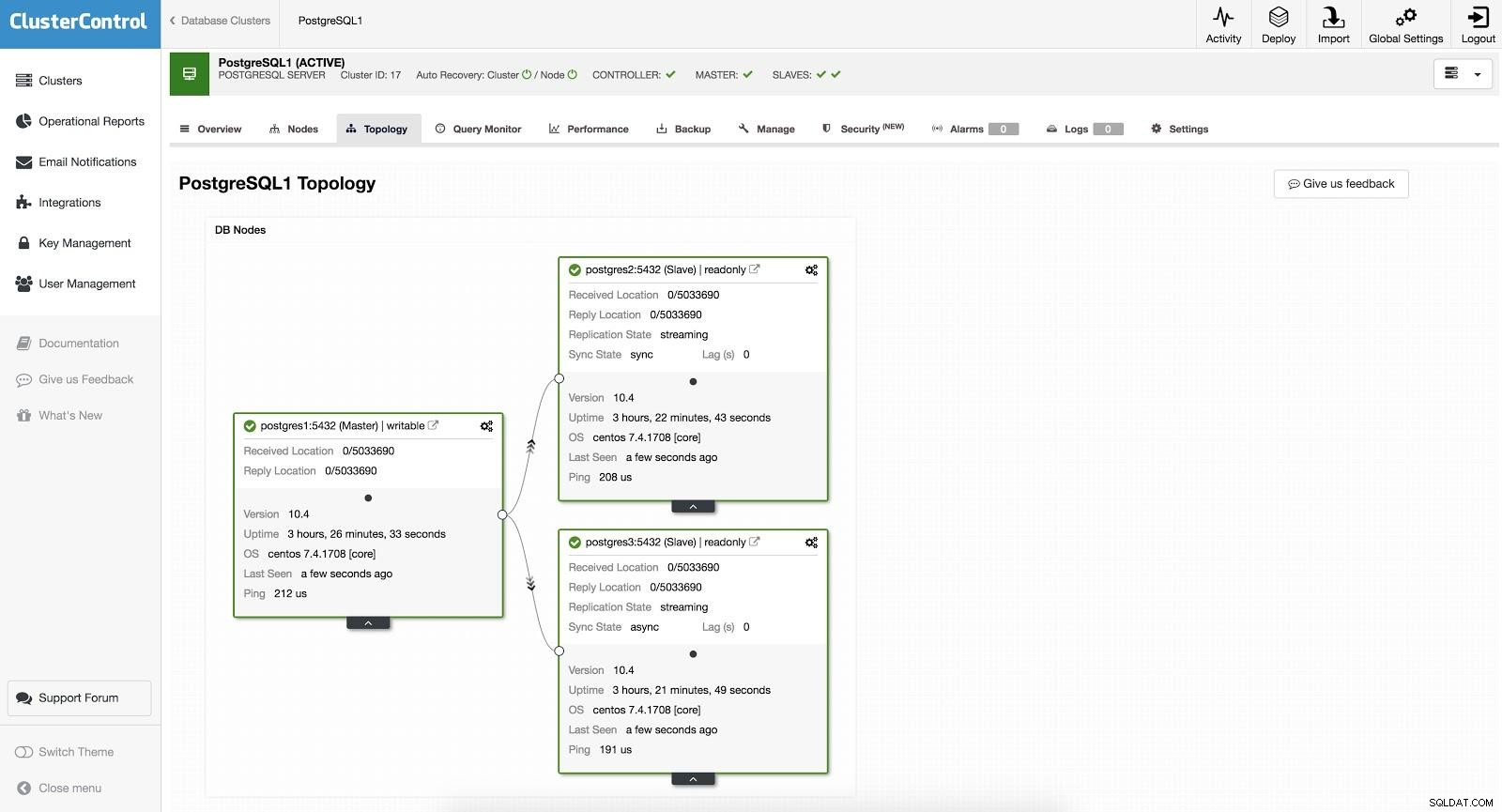 ClusterControl Failover 1
ClusterControl Failover 1 For at udføre en manuel failover skal du gå til ClusterControl -> Vælg Cluster -> Noder, og i Action Node for en af vores slaver skal du vælge "Promote Slave". På denne måde, efter et par sekunder, bliver vores slave herre, og hvad der var vores herre tidligere, bliver til en slave.
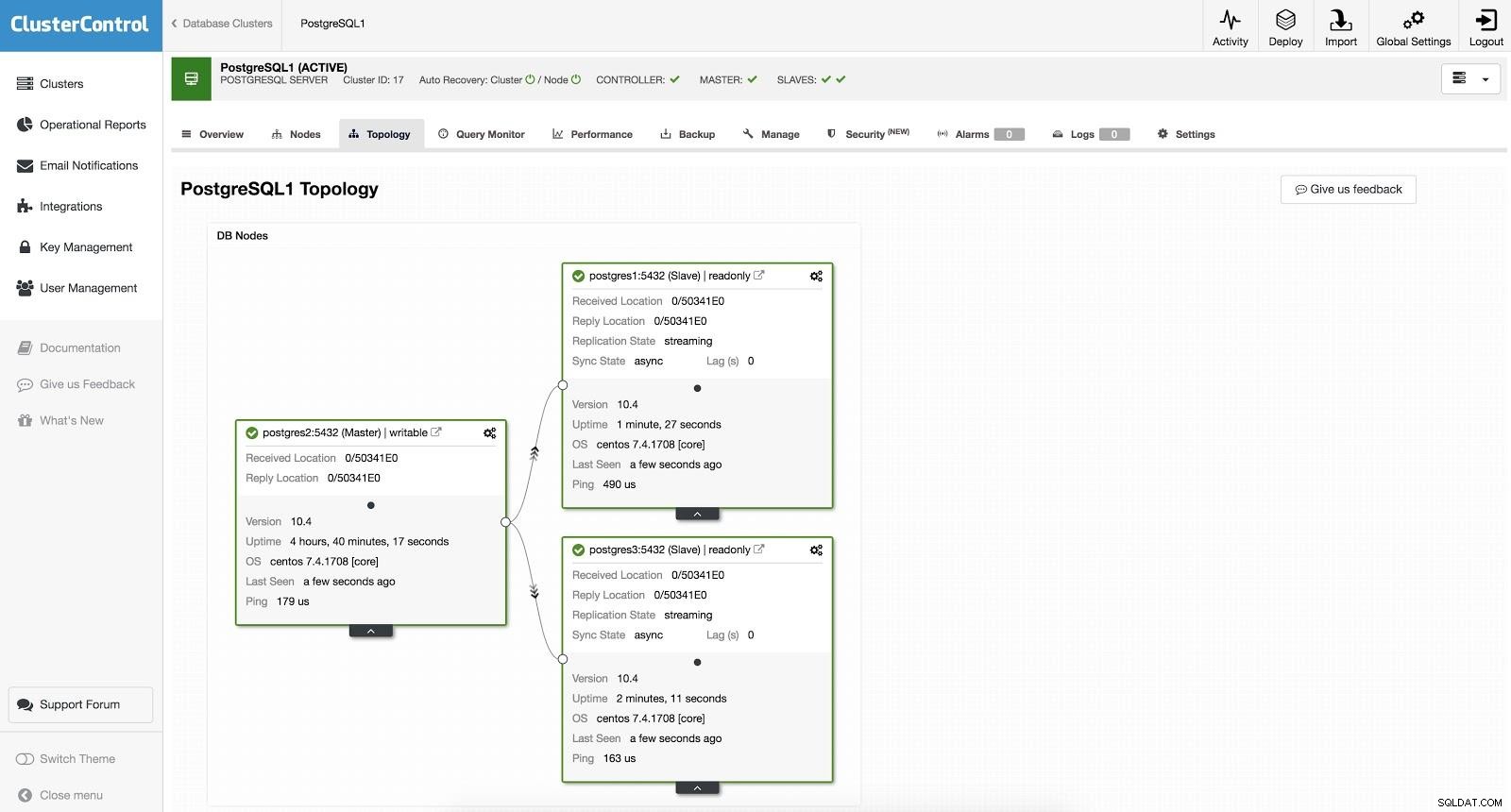 ClusterControl Failover 2
ClusterControl Failover 2 Ovenstående er nyttigt til opgaverne med migrering, vedligeholdelse og opgraderinger, som vi så tidligere.
Automatisk failover
I tilfælde af automatisk failover, registrerer ClusterControl fejl i masteren og promoverer en slave med de seneste data som den nye master. Det virker også på resten af slaverne at få dem til at replikere fra den nye master.
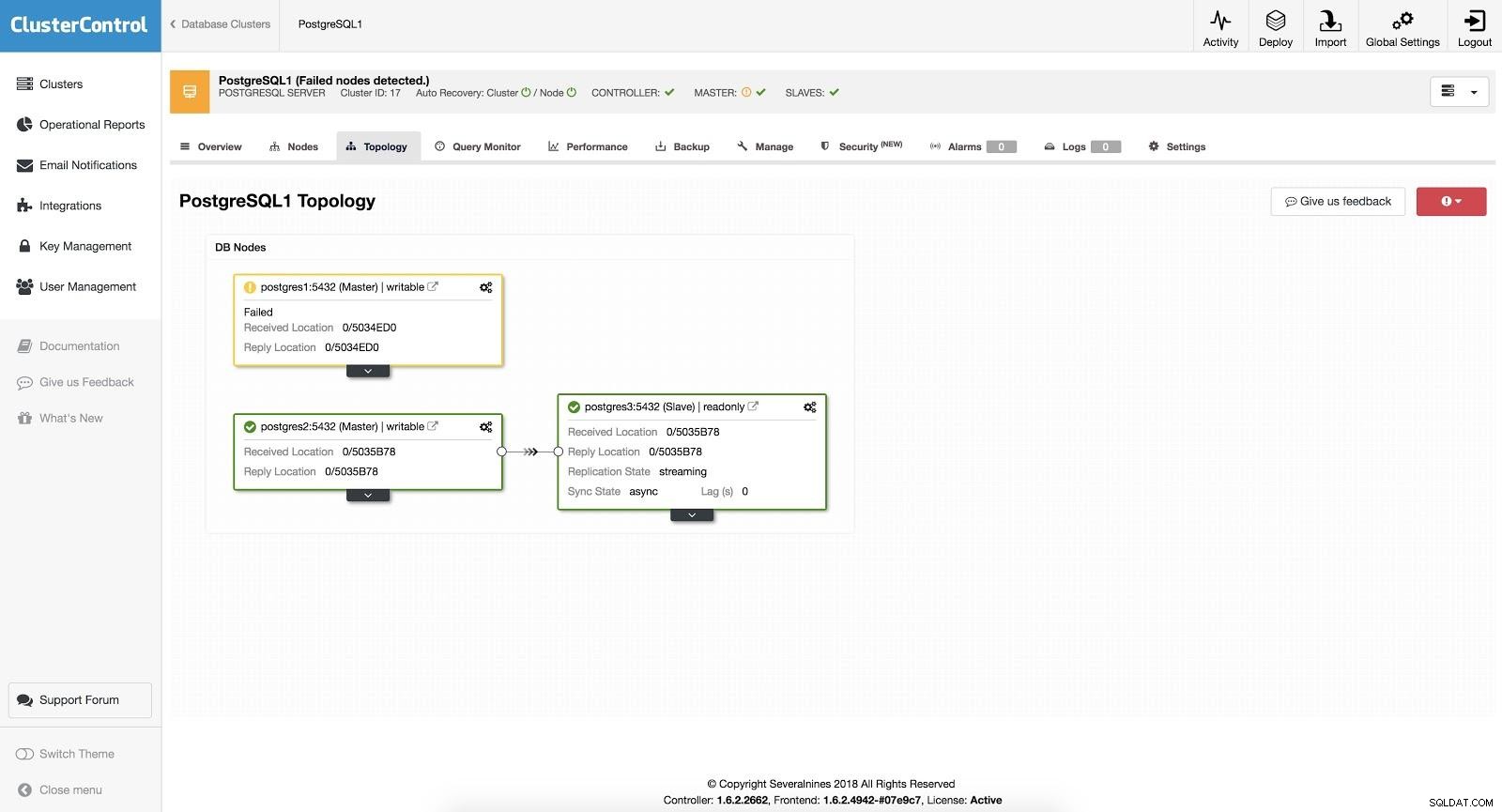 ClusterControl Failover 3
ClusterControl Failover 3 Når "Autorecovery"-indstillingen er TIL, vil vores ClusterControl udføre en automatisk failover samt give os besked om problemet. På denne måde kan vores systemer genoprettes på få sekunder og uden vores indgriben.
Cluster Control giver os mulighed for at konfigurere en hvidliste/sortliste for at definere, hvordan vi ønsker, at vores servere skal tages i betragtning (eller ikke tages i betragtning), når vi beslutter os for en masterkandidat.
Blandt dem, der er tilgængelige i henhold til ovenstående konfiguration, vil ClusterControl vælge den mest avancerede slave og bruge til dette formål pg_current_xlog_location (PostgreSQL 9+) eller pg_current_wal_lsn (PostgreSQL 10+) afhængigt af versionen af vores database.
ClusterControl udfører også flere kontroller over failover-processen for at undgå nogle almindelige fejl. Et eksempel er, at hvis det lykkes os at genoprette vores gamle mislykkede mester, vil den IKKE automatisk blive genindført i klyngen, hverken som mester eller som slave. Vi skal gøre det manuelt. Dette vil undgå muligheden for tab af data eller inkonsekvens i tilfælde af, at vores slave (som vi promoverede) blev forsinket på tidspunktet for fejlen. Vi vil måske også analysere problemet i detaljer, men når vi føjer det til vores klynge, vil vi muligvis miste diagnostiske oplysninger.
Hvis failover mislykkes, gøres der ikke yderligere forsøg, manuel indgriben er påkrævet for at analysere problemet og udføre de tilsvarende handlinger. Dette er for at undgå den situation, hvor ClusterControl, som den høje tilgængelighedsmanager, forsøger at promovere den næste slave og den næste. Der kan være et problem, og vi ønsker ikke at gøre tingene værre ved at forsøge flere failovers.
Load Balancers
Som vi nævnte tidligere, er belastningsbalanceren et vigtigt værktøj at overveje for vores failover, især hvis vi ønsker at bruge automatisk failover i vores databasetopologi.
For at failoveren skal være gennemsigtig for både brugeren og applikationen, har vi brug for en komponent imellem, da det ikke er nok at forfremme en master til en slave. Til dette kan vi bruge HAProxy + Keepalived.
Hvad er HAProxy?
HAProxy er en load balancer, der distribuerer trafik fra en oprindelse til en eller flere destinationer og kan definere specifikke regler og/eller protokoller for denne opgave. Hvis en af destinationerne holder op med at svare, markeres den som offline, og trafikken sendes til resten af de tilgængelige destinationer. Dette forhindrer trafik i at blive sendt til en utilgængelig destination og forhindrer tab af denne trafik ved at dirigere den til en gyldig destination.
Hvad er Keepalived?
Keepalved giver dig mulighed for at konfigurere en virtuel IP inden for en aktiv/passiv gruppe af servere. Denne virtuelle IP er tildelt en aktiv "Primær" server. Hvis denne server fejler, migreres IP'en automatisk til den "Sekundære" server, der blev fundet passiv, hvilket gør det muligt for den at fortsætte med at arbejde med den samme IP på en gennemsigtig måde for vores systemer.
For at implementere denne løsning med ClusterControl startede vi, som om vi skulle tilføje en slave. Gå til Cluster Actions og vælg Add Load Balancer (se ClusterControl Tilføj Slave 1 billede).
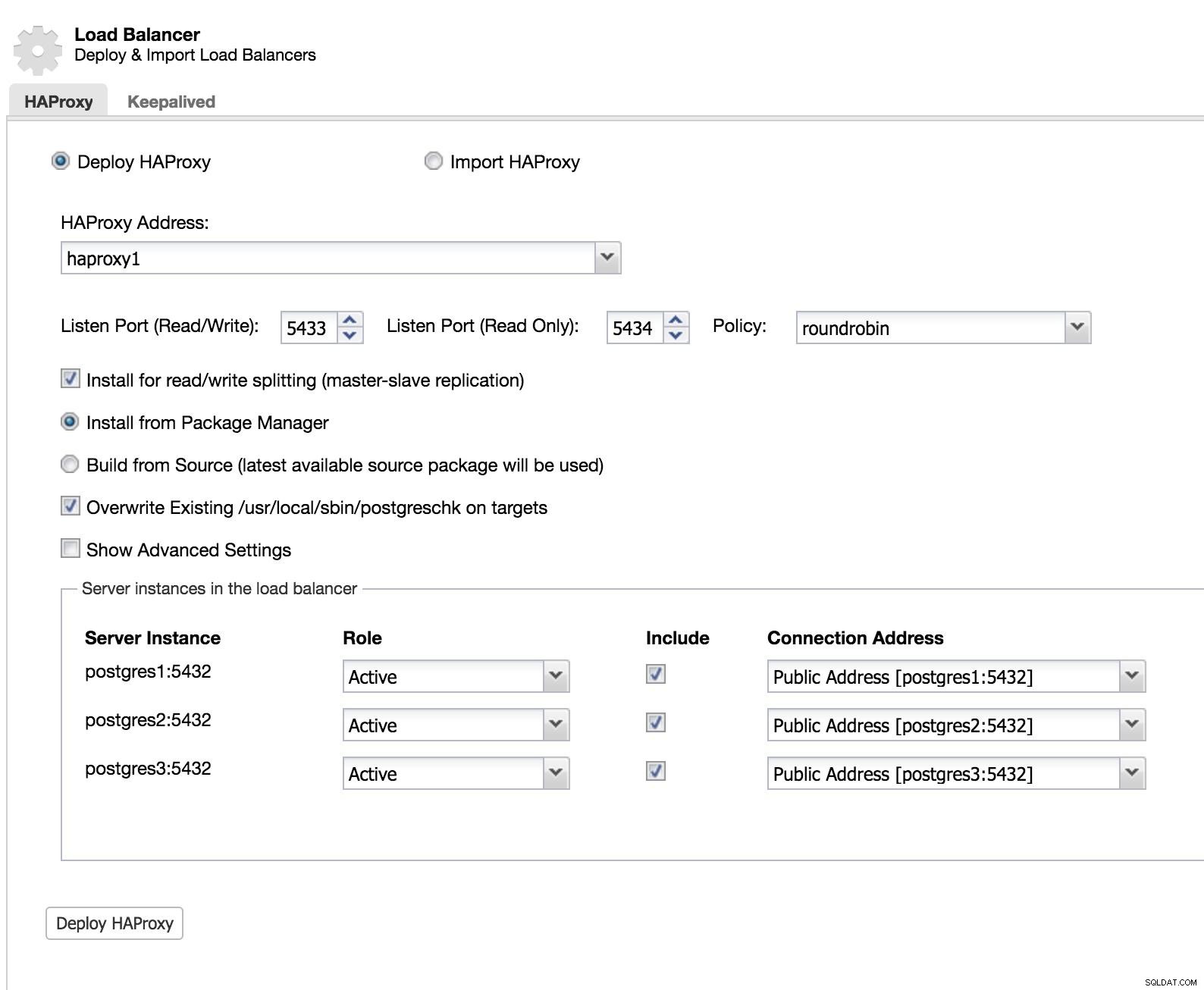 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Vi tilføjer oplysningerne om vores nye load balancer, og hvordan vi ønsker, at den skal opføre sig (Politik).
I tilfælde af at vi ønsker at implementere failover for vores load balancer, skal vi konfigurere mindst to forekomster.
Så kan vi konfigurere Keepalived (Vælg Cluster -> Administrer -> Load Balancer -> Keepalived).
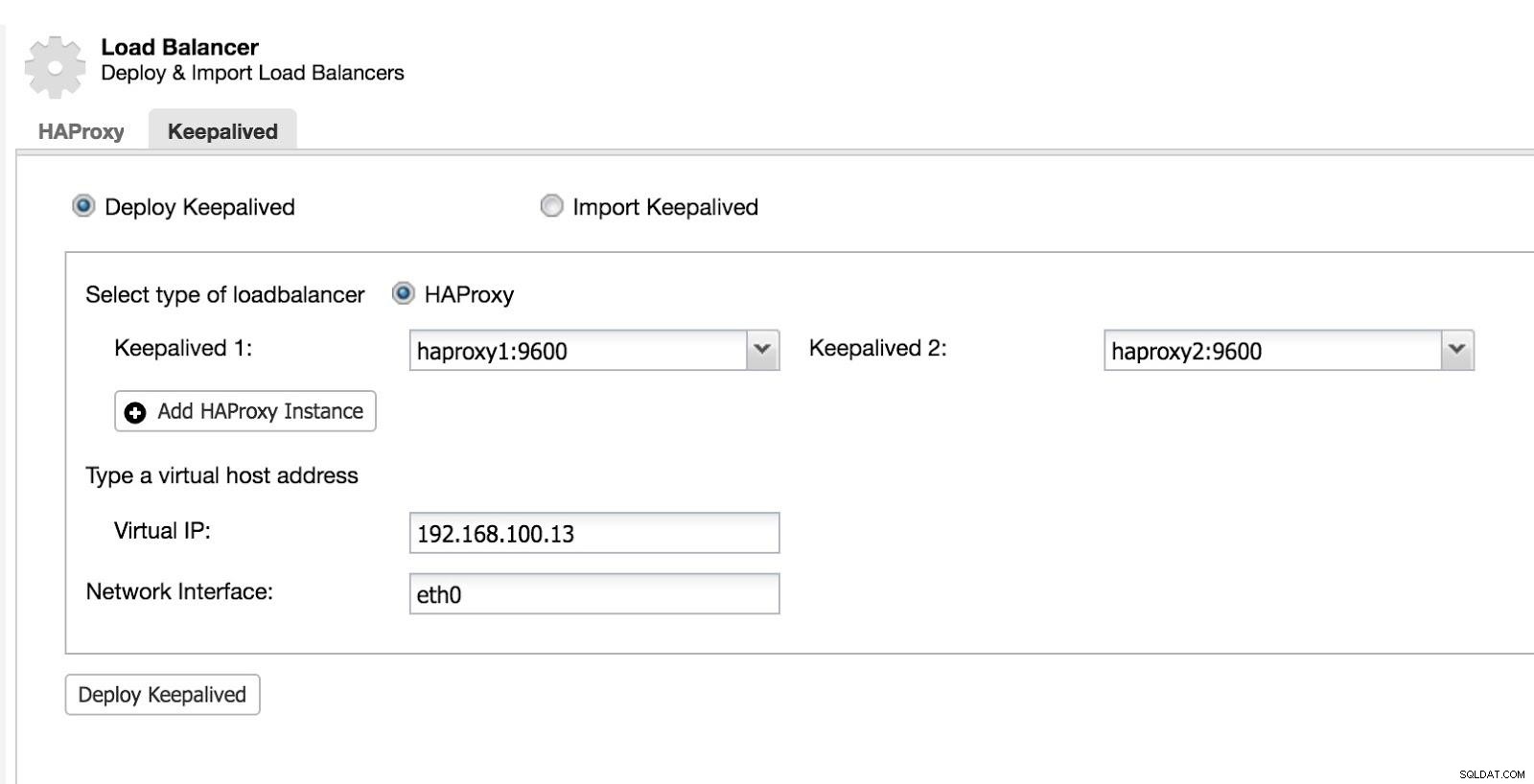 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Efter dette har vi følgende topologi:
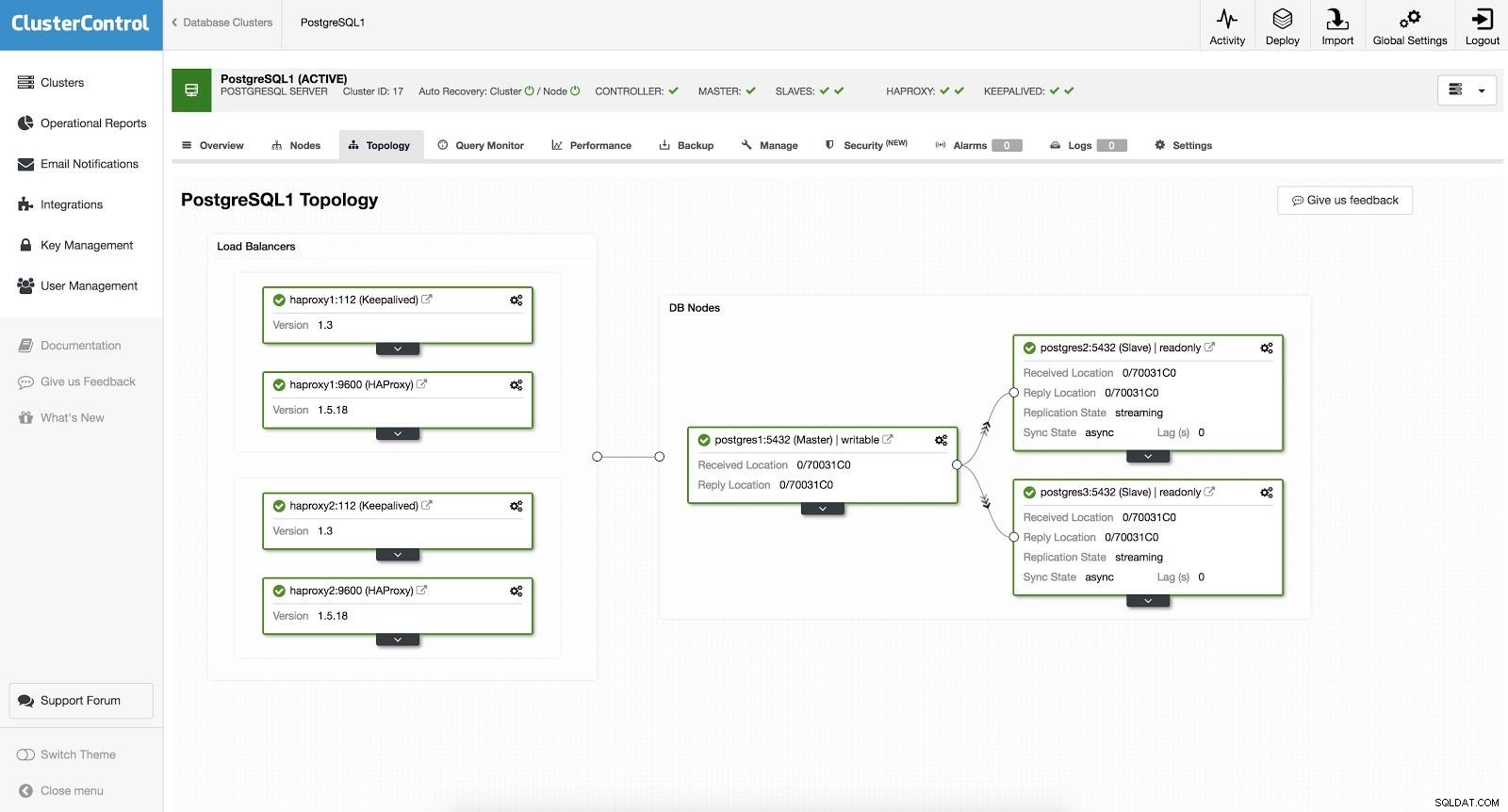 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy er konfigureret med to forskellige porte, en read-write og en read-only.
I vores læse-skrive-port har vi vores masterserver som online og resten af vores noder som offline. I den skrivebeskyttede port har vi både masteren og slaverne online. På denne måde kan vi afbalancere læsetrafikken mellem vores noder. Når du skriver, vil læse-skrive-porten blive brugt, som vil pege på masteren.
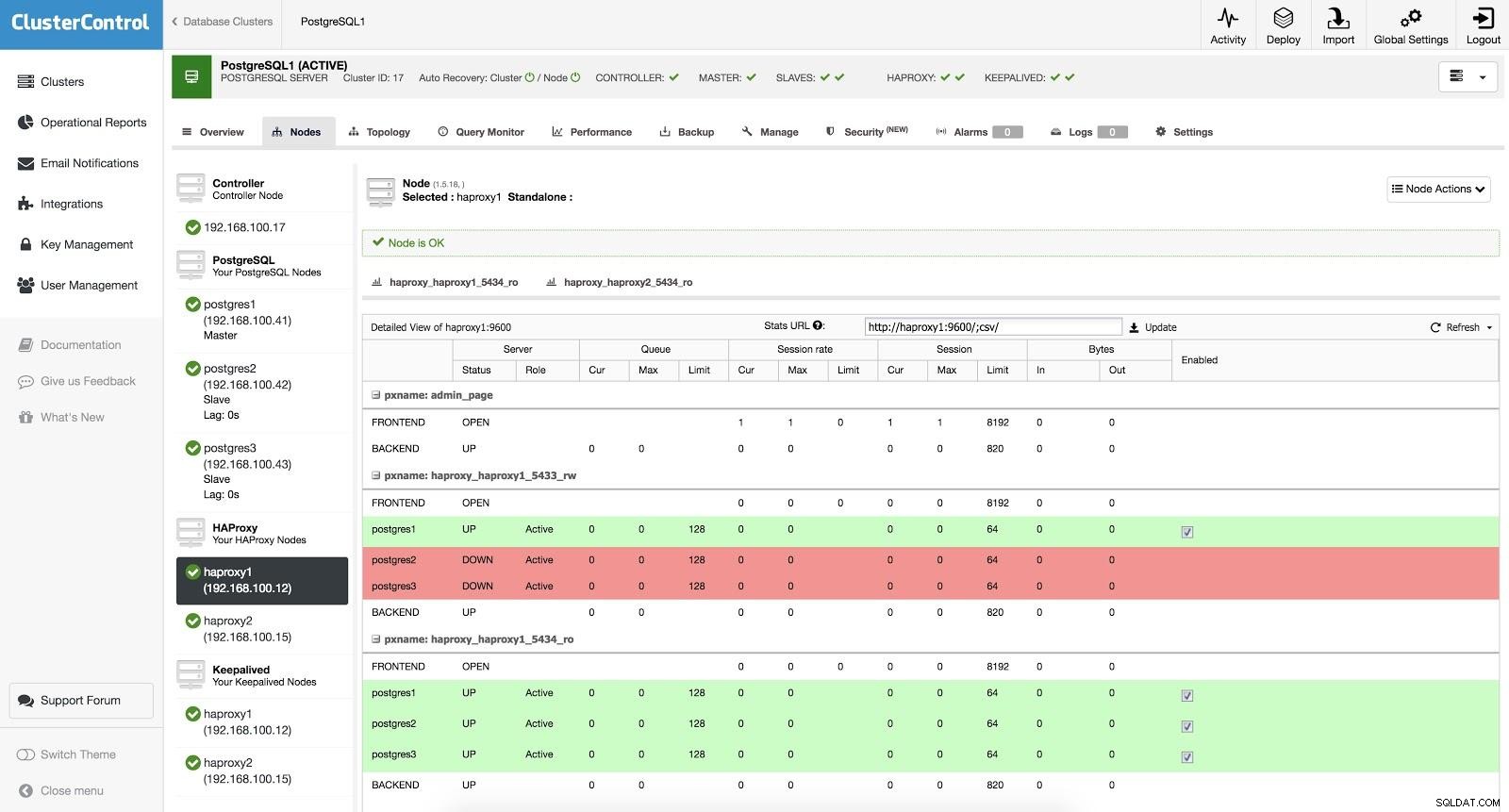 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Når HAProxy registrerer, at en af vores noder, enten master eller slave, ikke er tilgængelig, markerer den den automatisk som offline. HAProxy vil ikke sende nogen trafik til det. Denne kontrol udføres af sundhedstjekscripts, der er konfigureret af ClusterControl på tidspunktet for implementeringen. Disse kontrollerer, om forekomsterne er oppe, om de er under gendannelse eller er skrivebeskyttede.
Når ClusterControl fremmer en slave til master, markerer vores HAProxy den gamle master som offline (for begge porte) og sætter den promoverede node online (i læse-skriveporten). På denne måde fortsætter vores systemer med at fungere normalt.
Hvis vores aktive HAProxy (som er tildelt en virtuel IP-adresse, som vores systemer opretter forbindelse til) fejler, migrerer Keepalved denne IP til vores passive HAProxy automatisk. Det betyder, at vores systemer så kan fortsætte med at fungere normalt.
Konklusion
Som vi kunne se, er failover en grundlæggende del af enhver produktionsdatabase. Det kan være nyttigt, når du udfører almindelige vedligeholdelsesopgaver eller migreringer. Vi håber, at denne blog har været nyttig som en introduktion til emnet, så du kan fortsætte med at researche og skabe dine egne failover-strategier.