Indlæg af Dan Holmes, der blogger på sql.dnhlms.com.
SQL Server Books Online (BOL), hvidbøger og mange andre kilder viser dig, hvordan og hvorfor du måske ønsker at opdatere statistik på en tabel eller et indeks. Du får dog kun én måde at forme disse værdier på. Jeg vil vise dig, hvordan du kan oprette statistikken præcis, som du ønsker inden for grænserne af de 200 tilgængelige trin.
Ansvarsfraskrivelse :Dette virker for mig, fordi jeg kender min applikation, min database og min brugers almindelige arbejdsgang og applikationsbrugsmønstre. Det bruger dog udokumenterede kommandoer, og hvis det bruges forkert, kan det få din applikation til at yde væsentligt dårligere.I vores applikation læser og skriver planlægningsbrugeren regelmæssigt data, der repræsenterer begivenheder for i morgen og de næste par dage. Data for i dag og tidligere bruges ikke af planlæggeren. Først om morgenen starter datasættet for i morgen ved et par hundrede rækker og ved middagstid kan det være 1400 og højere. Følgende diagram vil illustrere rækkeantallet. Disse data blev indsamlet om morgenen onsdag den 18. november 2015. Historisk set kan du se, at det almindelige rækkeantal er cirka 1.400 med undtagelse af weekenddage og den næste dag.
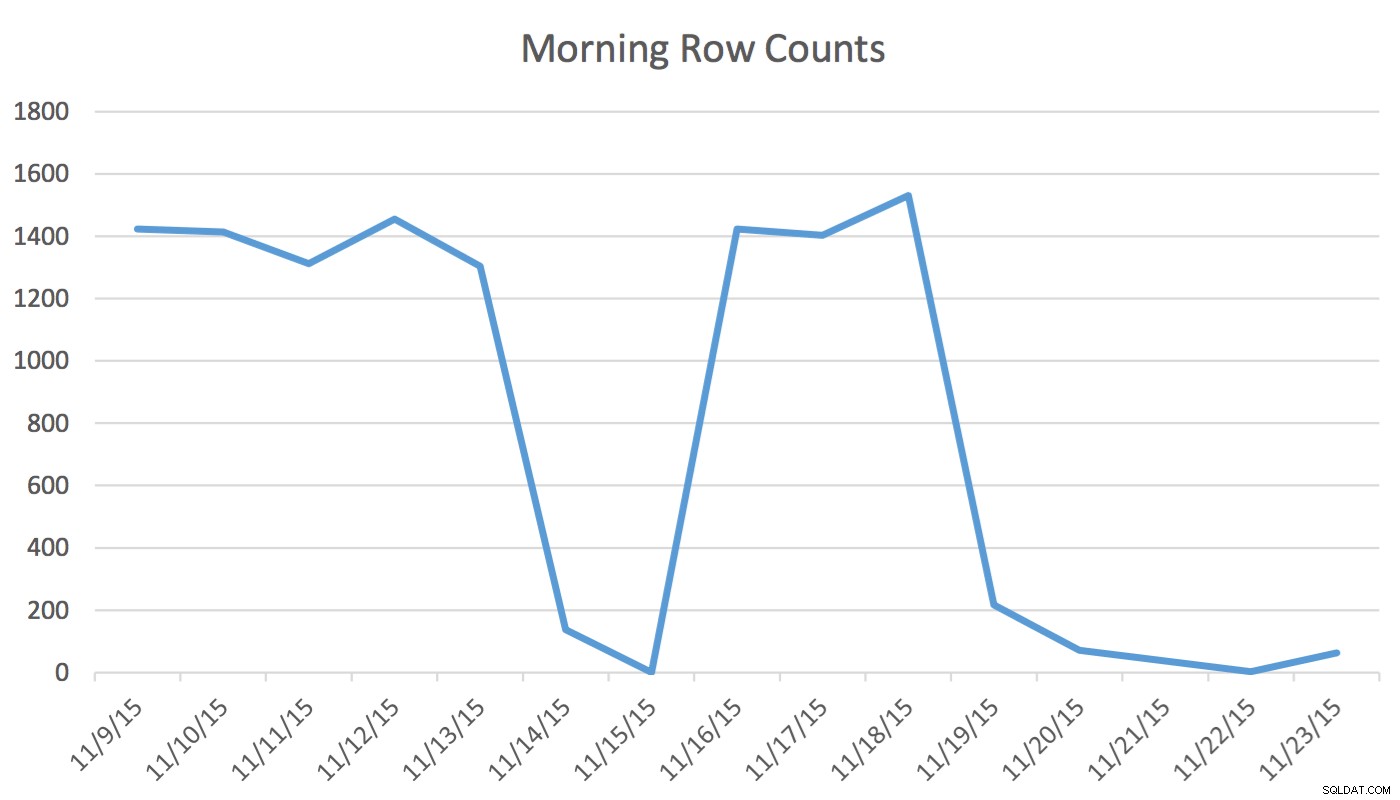
For Scheduler er de eneste relevante data de næste par dage. Hvad der sker i dag og skete i går er ikke relevant for hans aktivitet. Så hvordan forårsager dette et problem? Denne tabel har 2.259.205 rækker, hvilket betyder, at ændringen i rækkeantal fra morgen til middag ikke vil være nok til at udløse en SQL Server-initieret statistikopdatering. Desuden et manuelt planlagt job, der bygger statistik ved hjælp af UPDATE STATISTICS udfylder histogrammet med en stikprøve af alle data i tabellen, men inkluderer muligvis ikke de relevante oplysninger. Dette rækketalsdelta er nok til at ændre planen. Uden en statistikopdatering og et nøjagtigt histogram vil planen dog ikke ændre sig til det bedre, efterhånden som dataene ændres.
Et relevant udvalg af histogrammet for denne tabel fra en sikkerhedskopi dateret den 11/4/2015 kan se sådan ud:
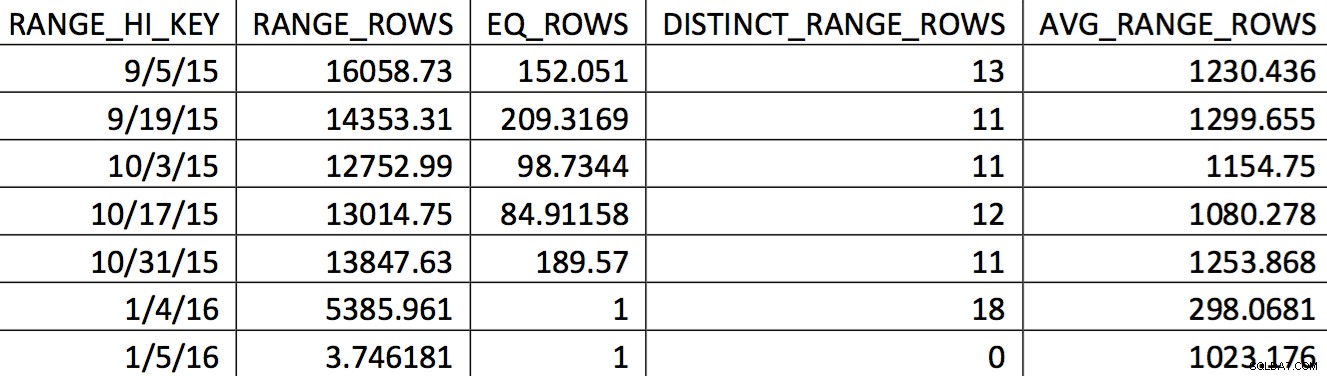
Værdierne af interesse afspejles ikke nøjagtigt i histogrammet. Hvad der ville blive brugt til datoen 11/5/2015 ville være den høje værdi 1/4/2016. Baseret på grafen er dette histogram tydeligvis ikke en god kilde til information for optimeringsværktøjet til interessedatoen. At tvinge brugsværdierne ind i histogrammet er ikke pålideligt, så hvordan kan du gøre det? Mit første forsøg var gentagne gange at bruge WITH SAMPLE mulighed for UPDATE STATISTICS og forespørg på histogrammet, indtil de værdier, jeg havde brug for, var i histogrammet (en indsats beskrevet her). I sidste ende viste den tilgang sig at være upålidelig.
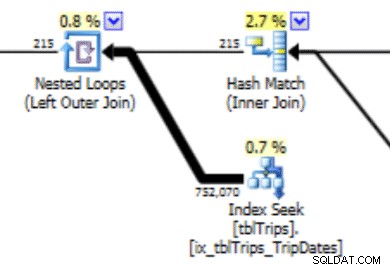
Dette histogram kan føre til en plan med denne type adfærd. Undervurderingen af rækker producerer en Nested Loop-sammenføjning og en indekssøgning. Aflæsningerne er efterfølgende højere, end de burde være på grund af dette planvalg. Dette vil også have en effekt på opgørelsens varighed.
Det, der ville fungere meget bedre, er at oprette dataene præcis, som du vil have det, og her er, hvordan du gør det.
Der er en ikke-understøttet mulighed for UPDATE STATISTICS :STATS_STREAM . Dette bruges af Microsoft Kundesupport til at eksportere og importere statistik, så de kan få en optimering genskabt uden at have alle data i tabellen. Vi kan bruge den funktion. Ideen er at skabe en tabel, der efterligner DDL for den statistik, vi ønsker at tilpasse. De relevante data tilføjes til tabellen. Statistikken eksporteres og importeres til den oprindelige tabel.
I dette tilfælde er det en tabel med 200 rækker med ikke-NULL-datoer og 1 række, der inkluderer NULL-værdierne. Derudover er der et indeks på den tabel, der matcher det indeks, der har de dårlige histogramværdier.
Tabellens navn er tblTripsScheduled . Den har et ikke-klynget indeks på (id, TheTripDate) og et klynget indeks på TheTripDate . Der er en håndfuld andre kolonner, men kun dem, der er involveret i indekset, er vigtige.
Opret en tabel (temp-tabel hvis du vil), der efterligner tabellen og indekset. Tabellen og indekset ser således ud:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Dernæst skal tabellen udfyldes med 200 rækker data, som statistikken skal baseres på. For min situation er det dagen fra de næste tres dage. De sidste og efter 60 dage er udfyldt med et "tilfældigt" udvalg på hver 10. dag. (cnt værdi i CTE er en fejlretningsværdi. Det spiller ikke en rolle i de endelige resultater.) Den faldende rækkefølge for rn kolonne sikrer, at de 60 dage er inkluderet, og så så meget af fortiden som muligt.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Vores tabel er nu udfyldt med hver række, der er værdifuld for brugeren i dag, og et udvalg af historiske rækker. Hvis kolonnen TheTripdate var nullbar, ville indsættelsen også have inkluderet følgende:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Dernæst opdaterer vi statistikken på indekset for vores midlertidige tabel.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Eksporter nu disse statistikker til en midlertidig tabel. Det bord ser sådan ud. Det matcher outputtet af DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS har mulighed for at eksportere statistikken som en stream. Det er den strøm, vi vil have. Den strøm er også den samme strøm som UPDATE STATISTICS stream mulighed bruger. For at gøre det:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Det sidste trin er at oprette den SQL, der opdaterer statistikkerne for vores måltabel, og derefter udføre den.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); På dette tidspunkt har vi erstattet histogrammet med vores specialbyggede. Du kan bekræfte ved at tjekke histogrammet:
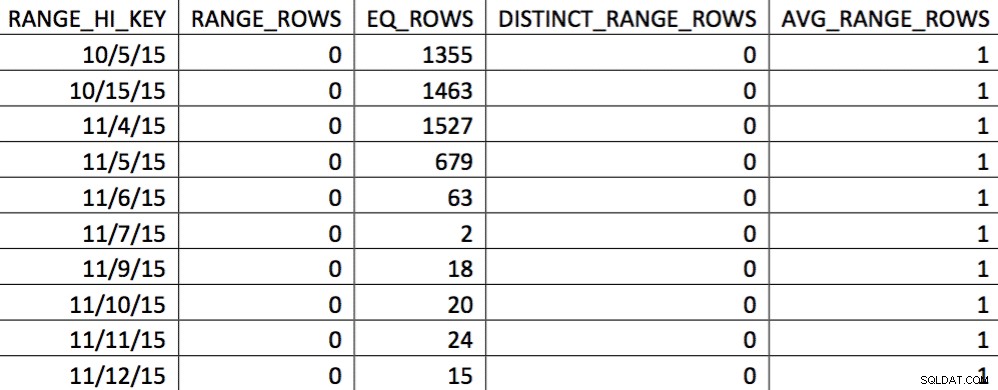
I dette udvalg af data den 11/4 er alle dagene fra 11/4 og frem repræsenteret, og de historiske data er repræsenteret og nøjagtige. Ved at gense den del af forespørgselsplanen, der er vist tidligere, kan du se, at optimeringsværktøjet har gjort et bedre valg baseret på den korrigerede statistik:
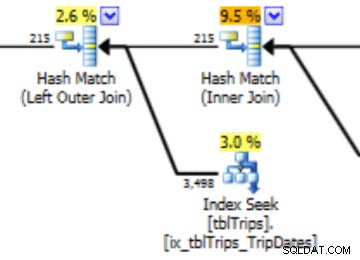
Der er en ydeevnefordel ved importeret statistik. Omkostningerne til at beregne statistikken er på en "offline"-tabel. Den eneste nedetid for produktionstabellen er varigheden af streamimporten.
Denne proces bruger udokumenterede funktioner, og det ser ud til, at det kan være farligt, men husk, at der er en nem fortrydelse:opdateringsstatistikerklæringen. Hvis noget går galt, kan statistikken altid opdateres ved hjælp af standard T-SQL.
At planlægge denne kode til at køre regelmæssigt kan i høj grad hjælpe optimeringsværktøjet til at producere bedre planer givet et datasæt, der ændrer sig over vendepunktet, men ikke nok til at udløse en statistikopdatering.
Da jeg var færdig med det første udkast til denne artikel, ændrede rækkeantallet på tabellen i det første diagram sig fra 217 til 717. Det er en ændring på 300 %. Det er nok til at ændre optimeringsfunktionen, men ikke nok til at udløse en statistikopdatering. Denne dataændring ville have efterladt en dårlig plan på plads. Det er med den proces, der er beskrevet her, at dette problem er løst.
Referencer:
- OPDATERING STATISTIK (Bøger online)
- SQL 2008 statistik hvidbog
- Tipping Point-søgning