Sidste år præsenterede jeg en løsning til at simulere Availability Group læsbare sekundære uden at investere i Enterprise Edition. Ikke for at forhindre folk i at købe Enterprise Edition, da der er mange fordele uden for AG'er, men mere for dem, der ikke har nogen chance for nogensinde at få Enterprise Edition i første omgang:
- Læsbare sekundærer på et budget
Jeg prøver at være en ubarmhjertig fortaler for Standard Edition-kunden; det er næsten en løbende joke, der helt sikkert – i betragtning af antallet af funktioner, den får i hver ny udgivelse – den udgave som helhed er på vej til afskrivning. I private møder med Microsoft har jeg presset på for, at funktioner også skal inkluderes i Standard Edition, især med funktioner, der er meget mere gavnlige for små virksomheder end dem med ubegrænset hardwarebudget.
Enterprise Edition-kunder nyder godt af administrations- og ydeevnefordelene ved tabelopdeling, men denne funktion er ikke tilgængelig i Standard Edition. En idé slog mig for nylig, at der er en måde at opnå i det mindste nogle af partitioneringens fordele på enhver udgave, og det involverer ikke opdelte visninger. Dette betyder ikke, at opdelte visninger ikke er en levedygtig mulighed, der er værd at overveje; disse er beskrevet godt af andre, herunder Daniel Hutmacher (Opdelte visninger over tabelopdeling) og Kimberly Tripp (Opdelte borde v. Opdelte visninger – hvorfor findes de overhovedet stadig?). Min idé er bare lidt nemmere at implementere.
Din nye helt:Filtrerede indekser
Nu ved jeg, at denne funktion er et ord på fire bogstaver for nogle; før du går videre, bør du være glad for at være fortrolig med filtrerede indekser, eller i det mindste være opmærksom på deres begrænsninger. Noget læsning for at give dig en rimelig balance, før jeg prøver at sælge dig på dem:
- Jeg taler om flere mangler i Hvordan filtrerede indekser kunne være en mere kraftfuld funktion, og påpeger masser af Connect-elementer, som du kan stemme op;
- Paul White (@SQL_Kiwi) taler om tuning-problemer i Optimizer-begrænsninger med filtrerede indekser og også i en uventet bivirkning ved at tilføje et filtreret indeks; og,
- Jes Borland (@grrl_geek) fortæller os, hvad du kan (og ikke kan) med filtrerede indekser.
Læs alle dem? Og du er her stadig? Fantastisk.
TL;DR af dette er, at du kan bruge filtrerede indekser til at holde alle dine "hot data" i en separat fysisk struktur, og endda på separat underliggende hardware (du kan have et hurtigt SSD- eller PCIe-drev tilgængeligt, men det kan' t holde hele bordet).
Et hurtigt eksempel
Der er mange brugssager, hvor en del af dataene forespørges meget hyppigere end resten – tænk på en detailbutik, der administrerer ordrer, et bageri, der planlægger bryllupskageleverancer, eller et fodboldstadion, der måler tilstedeværelses- og koncessionsdata. I disse tilfælde handler det meste eller hele den daglige forespørgselsaktivitet om "aktuelle" data.
Lad os holde det enkelt; vi opretter en database med en meget smal ordretabel:
CREATE DATABASE PoorManPartition;GO USE PoorManPartition;GO CREATE TABLE dbo.Orders( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, . .andre kolonner...);
Lad os nu sige, at du har plads nok på dit hurtige lager til at beholde en måneds data (med masser af plads til at tage højde for sæsonbestemte og fremtidig vækst). Vi kan tilføje en ny filgruppe og placere en datafil på det hurtige drev.
ÆNDR DATABASE PoorManPartition TILFØJ FILGRUPPE HotData;GO ÆNDRING DATABASE PoorManPartition TILFØJ FIL ( Navn =N'HotData', Filnavn =N'Z:\folder\HotData.mdf', Størrelse =100MB, FileGrowth =25MB) TIL FILEGROUP;
Lad os nu oprette et filtreret indeks på vores HotData-filgruppe, hvor filteret inkluderer alt fra begyndelsen af november 2015, og de almindelige kolonner involveret i tidsbaserede forespørgsler er i nøgle- eller inkluderingslisten:
OPRET INDEX FilteredIndex PÅ dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151101' OG OrderDate <'20151201' ON HotData;
Vi kan indsætte et par rækker og tjekke udførelsesplanen for at være sikker på, at dækkede forespørgsler faktisk kan bruge indekset:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Resultater:index_id rows -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal FRA dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106';
Den resulterende eksekveringsplan bruger ganske vist det filtrerede indeks (selvom filterprædikatet i forespørgslen ikke matcher indeksdefinitionen nøjagtigt):
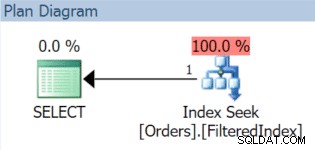
Nu ruller 1. december rundt, og det er tid til at udskifte vores novemberdata og erstatte dem med december. Vi kan bare genskabe det filtrerede indeks med et nyt filterprædikat og bruge DROP_EXISTING mulighed:
OPRET INDEX FilteredIndex PÅ dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151201' OG OrderDate <'20160101' MED (DROP_EXISTING =ON) ON HotData;
Nu kan vi tilføje et par rækker mere, kontrollere partitionsstatistikken og køre vores tidligere forespørgsel og en ny for at kontrollere de anvendte indekser:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Resultater:index_id rows -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal FRA dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106'; VÆLG OrderID, OrderDate, OrderTotal FRA dbo.Orders WHERE OrderDate>='20151202' OG OrderDate <'20151204';
I dette tilfælde får vi en klynget indeksscanning med november-forespørgslen:
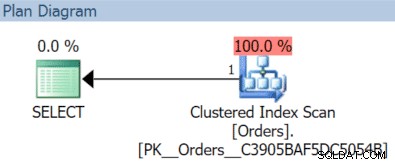
(Men det ville være anderledes, hvis vi havde et separat, ikke-filtreret indeks med OrderDate som nøglen.)
Og jeg vil ikke vise det igen, men med december-forespørgslen får vi den samme filtrerede indekssøgning som før.
Du kan også vedligeholde flere indekser, et for den aktuelle måned, et for den foregående måned og så videre, og du kan bare administrere dem separat (den 1. december dropper du bare indekset fra oktober og lader for eksempel novembers være) . Du kan også opretholde flere indekser over kortere eller længere tidsrum (nuværende og forrige uge, nuværende og forrige kvartal) osv. Løsningen er ret fleksibel.
På grund af begrænsningerne af filtrerede indekser, vil jeg ikke forsøge at skubbe dette som en perfekt løsning, og heller ikke en komplet erstatning for tabelopdeling eller partitionerede visninger. Udskiftning af en partition er for eksempel en metadataoperation, mens du genskaber et indeks med DROP_EXISTING kan have en masse logning (og da du ikke er på Enterprise Edition, kan den ikke køres online). Du kan også opleve, at partitionerede visninger er mere din hastighed – der er mere arbejde omkring at vedligeholde separate fysiske tabeller og de begrænsninger, der gør den opdelte visning mulig, men udbyttet i form af forespørgselsydeevne kan være bedre i nogle tilfælde.
Automatisering
Handlingen med at genskabe indekset kan automatiseres ganske nemt ved at bruge et simpelt job, der gør noget som dette en gang om måneden (eller hvad din "varme" vinduesstørrelse er):
DECLARE @sql NVARCHAR(MAX), @dt DATE =DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' MED (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Du kan også oprette flere indekser måneder i forvejen, ligesom at oprette fremtidige partitioner på forhånd – trods alt vil de fremtidige indekser ikke optage plads, før der er data, der er relevante for deres prædikater. Og du kan bare droppe de indekser, der segmenterede de ældre data, som du nu ønsker skal blive kolde.
Bagblik
Efter at jeg var færdig med denne artikel, stødte jeg selvfølgelig på et andet af Kimberly Tripps indlæg, som du bør læse, før du fortsætter med noget, jeg fortaler her (og som jeg havde læst, før jeg startede):
- Hvad med filtrerede indekser i stedet for partitionering?
Af flere grunde er Kimberly meget mere tilhænger af partitionerede visninger for at implementere noget, der ligner partitionering i Standard Edition; Men for visse scenarier fascinerer brugen af filtrerede indekser mig stadig nok til at fortsætte med mine eksperimenter. Et af de områder, hvor filtrerede indekser kan være fordelagtige, er, når dine "varme" data har flere kriterier – ikke kun opdelt efter dato, men også efter andre attributter (måske vil du have hurtige forespørgsler mod alle ordrer fra denne måned, der er for et specifikt niveau af kunde eller over et vist dollarbeløb).
Næste...
I et fremtidigt indlæg vil jeg lege med dette koncept på et avanceret system med en vis volumen og arbejdsbyrde i den virkelige verden. Jeg ønsker at opdage ydeevneforskelle mellem denne løsning, et ikke-filtreret dækkende indeks, en opdelt visning og en opdelt tabel. Inde i en VM på en bærbar computer med kun tilgængelige SSD'er ville sandsynligvis ikke give realistiske eller retfærdige tests i stor skala.