Bemærk:Dette indlæg blev oprindeligt kun offentliggjort i vores e-bog, High Performance Techniques for SQL Server, bind 2. Du kan finde ud af om vores e-bøger her.
Resumé:Denne artikel undersøger noget overraskende adfærd af ISTEDET FOR triggere og afslører en alvorlig fejl i estimering af kardinalitet i SQL Server 2014.
Triggere og rækkeversionering
Kun DML AFTER-udløsere bruger rækkeversionering (i SQL Server 2005 og frem) til at give den indsatte og slettet pseudo-tabeller inde i en triggerprocedure. Denne pointe er ikke tydeligt fremført i meget af den officielle dokumentation. De fleste steder siger dokumentationen blot, at rækkeversionering bruges til at bygge den indsatte og slettet tabeller i triggere uden kvalifikation (eksempler nedenfor):
Rækkeversioneringsressourceforbrug
Forstå rækkeversionsbaserede isolationsniveauer
Styring af triggerudførelse ved masseimport af data
Formentlig er de originale versioner af disse poster skrevet, før ISTED FOR udløsere blev føjet til produktet og aldrig opdateret. Enten det, eller også er det en simpel (men gentaget) forglemmelse.
I hvert fald er den måde, hvorpå rækkeversionering fungerer med AFTER-triggere, ret intuitiv. Disse udløsere udløses efter de pågældende ændringer er blevet udført, så det er nemt at se, hvordan vedligeholdelse af versioner af de ændrede rækker gør det muligt for databasemotoren at levere den indsatte og slettet pseudo-tabeller. Den slettede pseudo-tabel er konstrueret ud fra versioner af de berørte rækker, før ændringerne fandt sted; den indsatte pseudo-tabel er dannet ud fra versionerne af de berørte rækker på det tidspunkt, hvor triggerproceduren startede.
I stedet for udløsere
I STEDET FOR triggere er forskellige, fordi denne type DML-trigger fuldstændig erstatter den udløste handling. Den indsatte og slettet pseudo-tabeller repræsenterer nu ændringer, som ville have blevet foretaget, havde den udløsende erklæring faktisk udført. Rækkeversionering kan ikke bruges til disse triggere, fordi der pr. definition ikke er sket nogen ændringer. Så hvis du ikke bruger rækkeversioner, hvordan gør SQL Server det?
Svaret er, at SQL Server ændrer udførelsesplanen for den udløsende DML-sætning, når der findes en INSTEAD OF-trigger. I stedet for at ændre de berørte tabeller direkte, skriver udførelsesplanen information om ændringerne til en skjult arbejdstabel. Denne arbejdstabel indeholder alle de data, der er nødvendige for at udføre de oprindelige ændringer, typen af modifikation, der skal udføres på hver række (slet eller indsæt), samt enhver information, der er nødvendig i triggeren for en OUTPUT-klausul.
Udførelsesplan uden en trigger
For at se alt dette i aktion, vil vi først køre en simpel test uden en ISTEDEN FOR trigger til stede:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Udførelsesplanen for sletningen er meget ligetil:
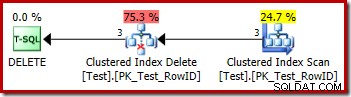
Hver række, der kvalificerer sig, sendes direkte til en Clustered Index Delete-operator, som sletter den. Nemt.
Udførelsesplan med en ISTEDEN FOR trigger
Lad os nu ændre testen til at inkludere en ISTEDEN FOR SLET-trigger (en, der bare udfører den samme sletningshandling for nemheds skyld):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Udførelsesplanen for DELETE er nu en helt anden:
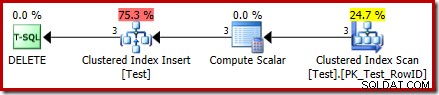
Operatoren Clustered Index Delete er blevet erstattet af en Clustered Index Indsæt . Dette er indsættelsen til den skjulte arbejdstabel, som omdøbes (i den offentlige udførelsesplan-repræsentation) til navnet på den basistabel, der er berørt af sletningen. Omdøbningen sker, når XML-showplanen er genereret fra den interne eksekveringsplanrepræsentation, så der er ingen dokumenteret måde at se den skjulte arbejdstabel på.
Som et resultat af denne ændring ser planen derfor ud til at udføre en indsættelse til basistabellen for at slette rækker fra den. Dette er forvirrende, men det afslører i det mindste tilstedeværelsen af en I STEDET FOR trigger. At erstatte Insert-operatoren med en Delete kan være endnu mere forvirrende. Måske ville det ideelle være et nyt grafisk ikon til et I STEDET FOR trigger-arbejdsbord? Det er i hvert fald, hvad det er.
Den nye Compute Scalar-operator definerer den type handling, der udføres på hver række. Denne handlingskode er et heltal med følgende betydninger:
- 3 =SLET
- 4 =INDSÆT
- 259 =SLET i en FLOT-plan
- 260 =INDSÆT i en FLOT-plan
For denne forespørgsel er handlingen en konstant 3, hvilket betyder, at hver række skal slettes :
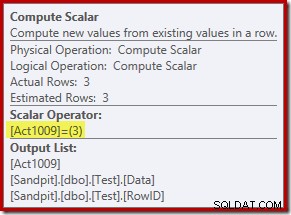
Opdater handlinger
Som en sidebemærkning erstatter en INSTEAD OF UPDATE-udførelsesplan en enkelt opdateringsoperatør med to Clustered Index Indsætter til den samme skjulte arbejdstabel – en til de indsatte pseudo-tabel rækker, og en for de slettede pseudo-tabel rækker. Et eksempel på en udførelsesplan:

En FLUTNING, der udfører en OPDATERING, producerer også en udførelsesplan med to indstik til den samme basistabel af lignende årsager:

Triggerudførelsesplanen
Udførelsesplanen for triggerkroppen har også nogle interessante funktioner:
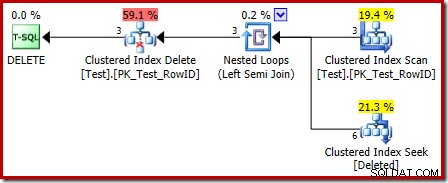
Den første ting at bemærke er, at det grafiske ikon, der bruges til den slettede tabel, ikke er det samme som ikonet, der bruges i AFTER trigger-planer:
Repræsentationen i INSTEAD OF trigger-planen er en Clustered Index Seek. Det underliggende objekt er den samme interne arbejdstabel, som vi så tidligere, selvom den her hedder slettet i stedet for at blive givet basistabelnavnet, formentlig for en form for overensstemmelse med AFTER-udløsere.
Søgeoperationen på den slettede tabellen er muligvis ikke, hvad du forventede (hvis du forventede en søgning på RowID):
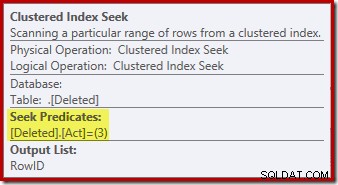
Denne 'søgning' returnerer alle rækker fra arbejdstabellen, der har en handlingskode på 3 (slet), hvilket gør det nøjagtigt svarende til Slettet scanning operatør set i AFTER trigger planer. Den samme interne arbejdstabel bruges til at holde rækker for begge indsatte og slettet pseudo-tabeller i I STEDET FOR triggere. Det svarer til en indsat scanning er en søgning på handlingskode 4 (hvilket er muligt i en slet trigger, men resultatet vil altid være tomt). Der er ingen indekser på den interne arbejdstabel bortset fra det ikke-unikke klyngede indeks på handlingen kolonne alene. Derudover er der ingen statistik knyttet til dette interne indeks.
Analysen indtil videre vil måske lade dig undre dig over, hvor sammenføjningen mellem RowID-kolonnerne udføres. Denne sammenligning forekommer ved Nested Loops Left Semi Join-operatøren som et resterende prædikat:
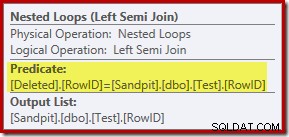
Nu hvor vi ved, at 'søgningen' i praksis er en fuld scanning af de slettede tabel, virker den eksekveringsplan, der er valgt af forespørgselsoptimeringsværktøjet, ret ineffektiv. Det overordnede flow af udførelsesplanen er, at hver række fra testtabellen potentielt sammenlignes med hele sættet af slettede rækker, hvilket lyder meget som et kartesisk produkt.
Den gemme nåde er, at joinforbindelsen er en semi-join, hvilket betyder, at sammenligningsprocessen stopper for en given testrække, så snart den første slettet række opfylder restprædikatet. Ikke desto mindre virker strategien nysgerrig. Måske ville udførelsesplanen være bedre, hvis testtabellen indeholdt flere rækker?
Triggertest med 1.000 rækker
Følgende script kan bruges til at teste triggeren med et større antal rækker. Vi starter med 1.000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Udførelsesplanen for triggerlegemet er nu:
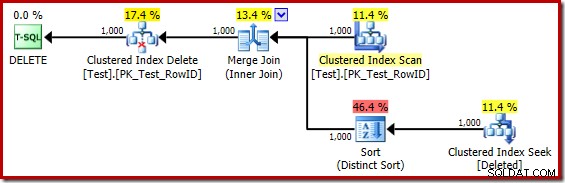
Hvis man mentalt erstatter den (vildledende) Clustered Index-søgning med en slettet scanning, ser planen generelt ret godt ud. Optimizeren har valgt en en-til-mange Merge Join i stedet for en Nested Loops Semi Join, hvilket virker rimeligt. Distinct Sort er dog en nysgerrig tilføjelse:
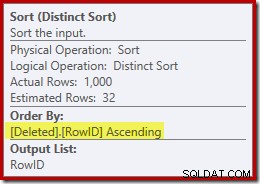
Denne slags udfører to funktioner. For det første leverer den sammenfletningen med det sorterede input, den har brug for, hvilket er rimeligt nok, fordi der ikke er noget indeks på den interne arbejdstabel til at give den nødvendige rækkefølge. Den anden ting, den slags gør, er at skelne på RowID. Dette kan virke underligt, fordi RowID er den primære nøgle i basistabellen.
Problemet er, at rækker i slettet tabel er simpelthen kandidatrækker, som den oprindelige DELETE-forespørgsel identificerede. I modsætning til en AFTER-trigger er disse rækker endnu ikke blevet kontrolleret for begrænsninger eller nøgleovertrædelser, så forespørgselsprocessoren har ingen garanti for, at de faktisk er unikke.
Generelt er dette et meget vigtigt punkt at huske på med STEDET FOR triggere:der er ingen garanti for, at de angivne rækker opfylder nogen af begrænsningerne på basistabellen (inklusive IKKE NULL). Dette er ikke kun vigtigt for triggerforfatteren at huske; det begrænser også de forenklinger og transformationer, som forespørgselsoptimeringsværktøjet kan udføre.
Et andet problem, der er vist i sorteringsegenskaberne ovenfor, men ikke fremhævet, er, at outputestimatet kun er 32 rækker. Den interne arbejdstabel har ingen statistik tilknyttet, så optimeringsværktøjet gætter ved virkningen af Distinct-operationen. Vi 'ved', at RowID-værdierne er unikke, men uden nogen svær information at gå på, giver optimeringsværktøjet et dårligt gæt. Dette problem vil vende tilbage og forfølge os i den næste test.
Triggertest med 5.000 rækker
Rediger nu testscriptet til at generere 5.000 rækker:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Udløsningsplanen er:
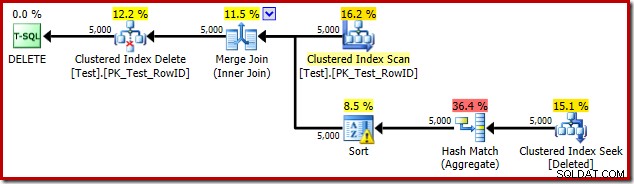
Denne gang har optimeringsværktøjet besluttet at opdele de særskilte og sortere operationer. Distinkten på RowID udføres af Hash Match (Aggregate) operatoren:
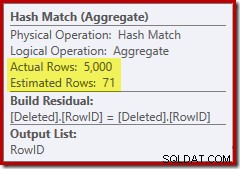
Bemærk, at optimizerens estimat for output er 71 rækker. Faktisk overlever alle 5.000 rækker det særskilte, fordi RowID er unikt. Det unøjagtige estimat betyder, at en utilstrækkelig brøkdel af forespørgselshukommelsesbevillingen allokeres til sorteringen, hvilket ender med at spredes til tempdb :
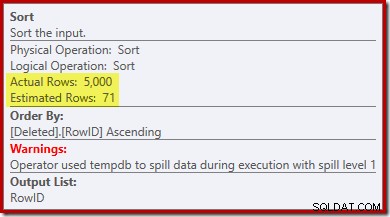
Denne test skal udføres på SQL Server 2012 eller højere for at se sorteringsadvarslen i udførelsesplanen. I tidligere versioner indeholder planen ingen information om spild – et Profiler-spor på sorteringsadvarsler-hændelsen ville være nødvendigt for at afsløre det (og du skal på en eller anden måde korrelere det tilbage til kildeforespørgslen).
Triggertest med 5.000 rækker på SQL Server 2014
Hvis den forrige test gentages på SQL Server 2014, i en database sat til kompatibilitetsniveau 120, så den nye kardinalitetsestimator (CE) bruges, er udløsningsplanen anderledes igen:
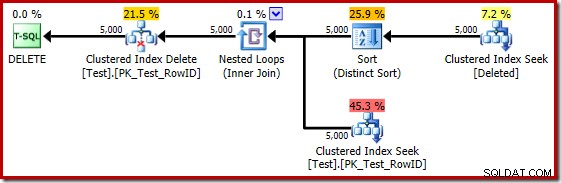
På nogle måder virker denne udførelsesplan som en forbedring. Den (unødvendige) Distinct Sort er der stadig, men den overordnede strategi virker mere naturlig:for hver særskilt kandidat RowID i slettet tabel, slutte sig til basistabellen (så kontrollere, at kandidatrækken faktisk eksisterer) og derefter slette den.
Desværre er 2014-planen baseret på dårligere kardinalitetsestimater, end vi så i SQL Server 2012. Skifter SQL Sentry Plan Explorer til at vise den estimerede rækketælling viser problemet tydeligt:
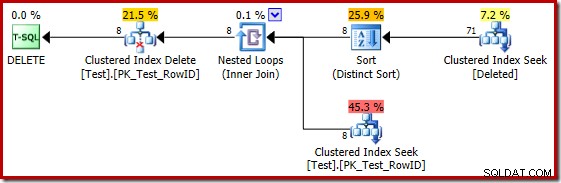
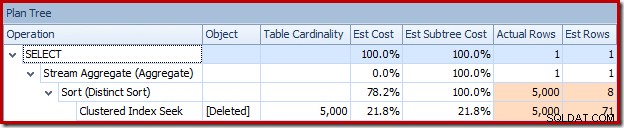
Optimizeren valgte en Nested Loops-strategi for joinforbindelsen, fordi den forventede et meget lille antal rækker på dens øverste input. Det første problem opstår ved Clustered Index Seek. Optimizeren ved, at den slettede tabel indeholder 5.000 rækker på dette tidspunkt, som vi kan se ved at skifte til Plan Tree-visning og tilføje den valgfri Tabel Cardinality-kolonne (som jeg ville ønske var inkluderet som standard):
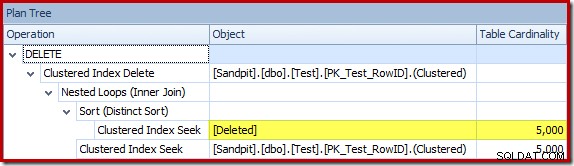
Den 'gamle' kardinalitetsestimator i SQL Server 2012 og tidligere er smart nok til at vide, at 'seek' på den interne arbejdstabel ville returnere alle 5.000 rækker (så den valgte en flette-join). Den nye CE er ikke så smart. Den ser arbejdsbordet som en 'sort boks' og gætter på effekten af søgningen på handlingskode =3:
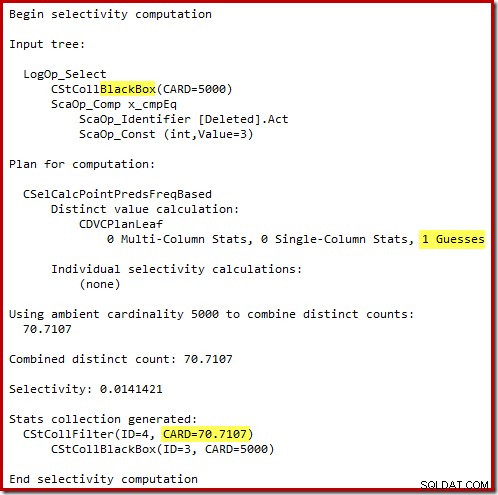
Gættet på 71 rækker (rundet op) er et ret elendigt resultat, men fejlen forværres, når den nye CE estimerer rækkerne for den særskilte operation på disse 71 rækker:
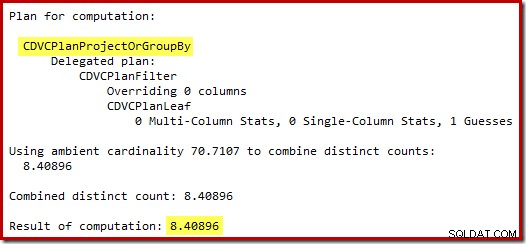
Baseret på de forventede 8 rækker vælger optimeringsprogrammet strategien Nested Loops. En anden måde at se disse estimeringsfejl på er at tilføje følgende sætning til udløserlegemet (kun til testformål):
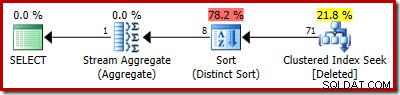
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Den estimerede plan viser estimeringsfejlene tydeligt:
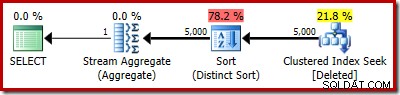
Den faktiske plan viser selvfølgelig stadig 5.000 rækker:
Eller du kan sammenligne estimat med faktisk på samme tid i plantrævisning:
En million rækker...
De dårlige gæt-estimatorer ved brug af 2014-kardinalitetsestimatoren får optimizeren til at vælge en Nested Loops-strategi, selv når testtabellen indeholder en million rækker. 2014 nye CE estimeret planen for den test er:
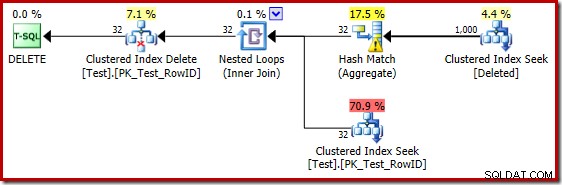
'Søgen' anslår 1.000 rækker fra den kendte kardinalitet på 1.000.000, og det distinkte estimat er 32 rækker. Post-udførelsesplanen afslører effekten på hukommelsen reserveret til Hash Match:
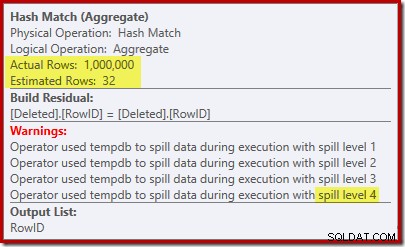
Hash Matchet forventer kun 32 rækker, og kommer i virkelige problemer, og spilder rekursivt sin hash-tabel, før den til sidst afsluttes.
Sidste tanker
Selvom det er rigtigt, at en trigger aldrig bør skrives for at gøre noget, der kan opnås med deklarativ referentiel integritet, er det også rigtigt, at en velskrevet trigger, der bruger en effektiv eksekveringsplanen kan sammenlignes i ydeevne med omkostningerne ved at opretholde et ekstra ikke-klynget indeks.
Der er to praktiske problemer med ovenstående udsagn. For det første (og med den bedste vilje i verden) skriver folk ikke altid god triggerkode. For det andet kan det være svært at få en god eksekveringsplan fra forespørgselsoptimeringsværktøjet under alle omstændigheder. Naturen af triggere er, at de kaldes med en bred vifte af inputkardinaliteter og datadistributioner.
Selv for AFTER-udløsere, manglen på indekser og statistikker på de slettede og indsat Pseudo-tabeller betyder, at planvalg ofte er baseret på gæt eller misinformation. Selv hvor en god plan først vælges, kan senere henrettelser genbruge den samme plan, når en omkompilering ville have været et bedre valg. Der er måder at omgå begrænsningerne på, primært gennem brug af midlertidige tabeller og eksplicitte indekser/statistikker, men selv der er stor omhu påkrævet (da triggere er en form for lagret procedure).
Med INSTEAD OF triggers kan risikoen være endnu større, fordi indholdet af den indsatte og slettet tabeller er ubekræftede kandidater – forespørgselsoptimeringsværktøjet kan ikke bruge begrænsninger på basistabellen til at forenkle og forfine sin eksekveringsplan. Den nye kardinalitetsestimator i SQL Server 2014 repræsenterer også et reelt skridt tilbage, når det kommer til I STEDET FOR triggerplaner. At gætte på effekten af en søgeoperation, som motoren selv introducerede, er en overraskende og uvelkommen forglemmelse.