Som SQL Server DBA'er har vi hørt, at indeksstrukturer dramatisk kan forbedre ydeevnen af enhver given forespørgsel (eller et sæt af forespørgsler). Alligevel er der visse detaljer, som mange DBA'er overser, såsom følgende:
- Indeksstrukturer kan blive fragmenterede, hvilket potentielt kan føre til problemer med ydeevnen.
- Når en indeksstruktur er blevet implementeret for en databasetabel, opdaterer SQL Server den, hver gang skrivehandlinger finder sted for den tabel. Dette sker, hvis de kolonner, der er i overensstemmelse med indekset, påvirkes.
- Der er metadata inde i SQL Server, som kan bruges til at vide, hvornår statistikken for en bestemt indeksstruktur blev opdateret (hvis nogensinde) for sidste gang. Utilstrækkelig eller forældet statistik kan påvirke ydeevnen af visse forespørgsler.
- Der er metadata inde i SQL Server, som kan bruges til at vide, hvor meget en indeksstruktur enten er blevet forbrugt af læseoperationer eller opdateret af skriveoperationer af SQL Server selv. Disse oplysninger kan være nyttige for at vide, om der er indekser, hvis skrivevolumen langt overstiger den læste. Det kan potentielt være en indeksstruktur, der ikke er så brugbar at have med.*
*Det er meget vigtigt at huske på, at systemvisningen, der indeholder denne særlige metadata, slettes, hver gang SQL Server-forekomsten genstartes, så det vil ikke være information fra dens udformning.
På grund af vigtigheden af disse detaljer, har jeg oprettet en lagret procedure for at holde styr på information vedrørende indeksstrukturer i hans/hendes miljø, for at agere så proaktivt som muligt.
Indledende overvejelser
- Sørg for, at kontoen, der udfører denne lagrede procedure, har nok privilegier. Du kunne sandsynligvis starte med sysadmin og derefter gå så detaljeret som muligt for at sikre, at brugeren har det minimum af privilegier, der kræves for at SP'en fungerer korrekt.
- Databaseobjekterne (databasetabel og lagret procedure) vil blive oprettet i den database, der er valgt på det tidspunkt, hvor scriptet udføres, så vælg med omhu.
- Scriptet er lavet på en måde, så det kan udføres flere gange uden at få en fejl. Til den lagrede procedure brugte jeg CREATE OR ALTER PROCEDURE-sætningen, tilgængelig siden SQL Server 2016 SP1.
- Du er velkommen til at ændre navnet på de oprettede databaseobjekter, hvis du vil bruge en anden navnekonvention.
- Når du vælger at bevare data, der returneres af den lagrede procedure, afkortes måltabellen først, så kun det seneste resultatsæt gemmes. Du kan foretage de nødvendige justeringer, hvis du ønsker, at dette skal opføre sig anderledes, uanset årsagen (for at beholde historiske oplysninger måske?).
Hvordan bruges den lagrede procedure?
- Kopiér og indsæt T-SQL-koden (tilgængelig i denne artikel).
- SP forventer 2 parametre:
- @persistData:'Y', hvis DBA'en ønsker at gemme outputtet i en måltabel, og 'N', hvis DBA'en kun ønsker at se outputtet direkte.
- @db:'alle' for at få oplysningerne for alle databaser (system &bruger), 'bruger' til at målrette brugerdatabaser, 'system' til kun at målrette mod systemdatabaser (undtagen tempdb), og til sidst det faktiske navn på en bestemt database.
Felter præsenteret og deres betydning
- dbName: navnet på databasen, hvor indeksobjektet ligger.
- skemanavn: navnet på det skema, hvor indeksobjektet er placeret.
- tabelnavn: navnet på tabellen, hvor indeksobjektet ligger.
- indeksnavn: navnet på indeksstrukturen.
- type: typen af indeks (f.eks. Clustered, Non-Clustered).
- allocation_unit_type: specificerer typen af data, der refererer til (f.eks. in-row data, lob data).
- fragmentering: mængden af fragmentering (i %), som indeksstrukturen har i øjeblikket.
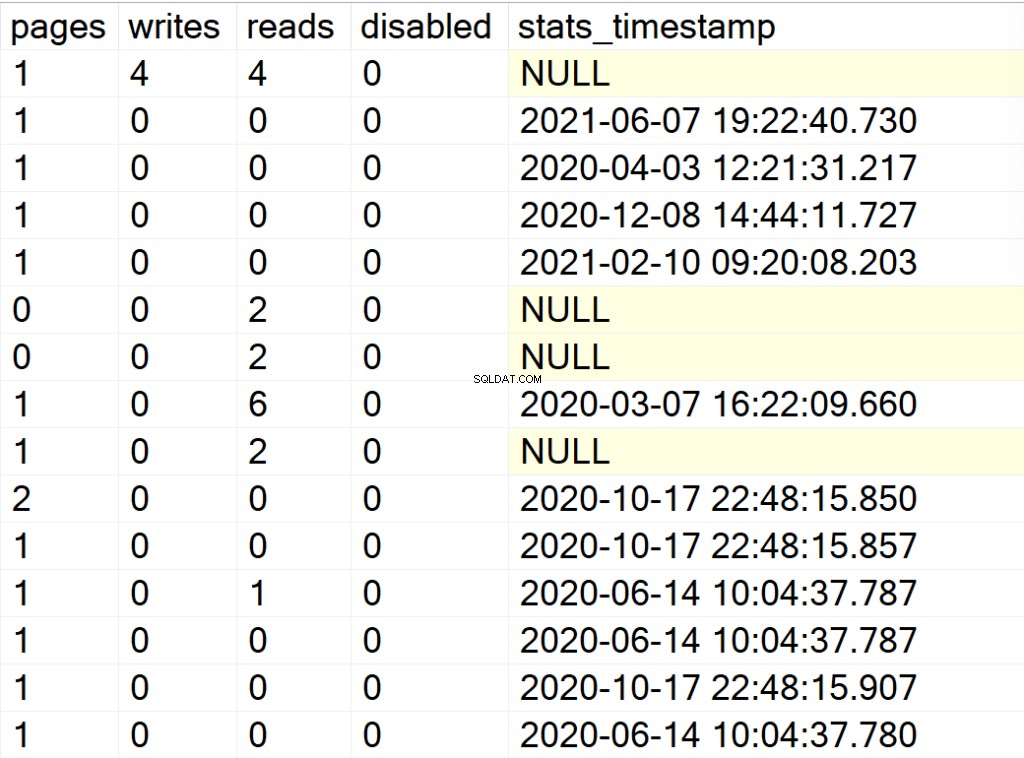
- sider: antallet af 8KB sider, der danner indeksstrukturen.
- skriver: antallet af skrivninger, som indeksstrukturen har oplevet siden SQL Server-forekomsten sidst blev genstartet.
- læser: antallet af læsninger, som indeksstrukturen har oplevet siden SQL Server-forekomsten sidst blev genstartet.
- deaktiveret: 1 hvis indeksstrukturen i øjeblikket er deaktiveret eller 0 hvis strukturen er aktiveret.
- stats_timestamp: tidsstempelværdien for, hvornår statistikkerne for den bestemte indeksstruktur sidst blev opdateret (NULL hvis aldrig).
- data_indsamling_tidsstempel: kun synlig, hvis 'Y' sendes til parameteren @persistData, og den bruges til at vide, hvornår SP'en blev udført, og informationen blev gemt i tabellen DBA_Index.
Udførelsestest
Jeg vil demonstrere et par udførelser af den lagrede procedure, så du kan få en idé om, hvad du kan forvente af den:
*Du kan finde den komplette T-SQL-kode for scriptet i slutningen af denne artikel, så sørg for at udføre den, før du går videre med det følgende afsnit.
*Resultatsættet vil være for bredt til at passe pænt ind i 1 skærmbillede, så jeg deler alle de nødvendige skærmbilleder for at præsentere den komplette information.
/* Vis alle indeksoplysninger for alle system- og brugerdatabaser */
EXEC GetIndexData @persistData = 'N',@db = 'all'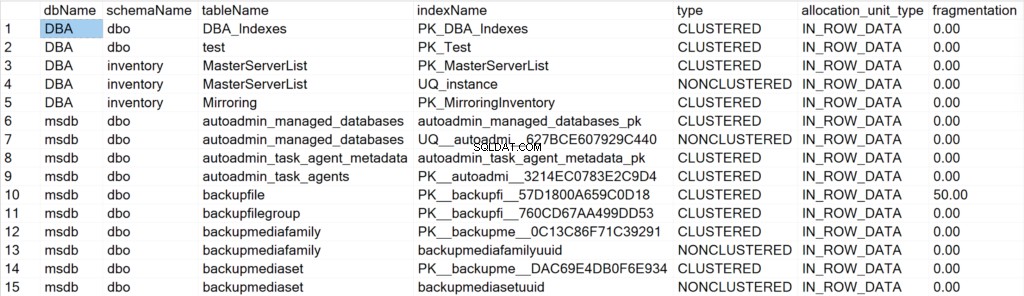
/* Vis alle indeksoplysninger for alle systemdatabaser */
EXEC GetIndexData @persistData = 'N',@db = 'system'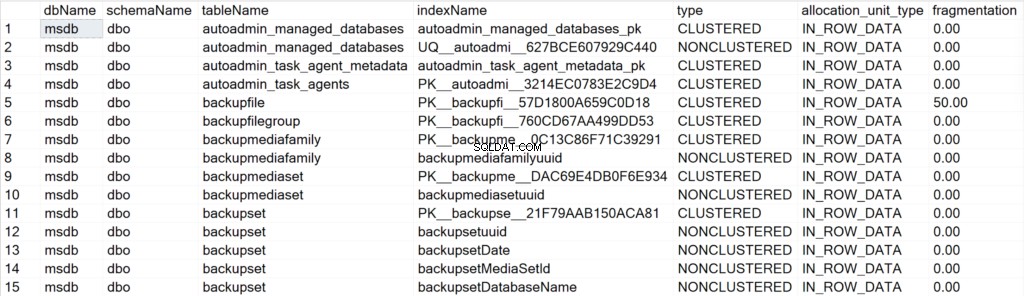
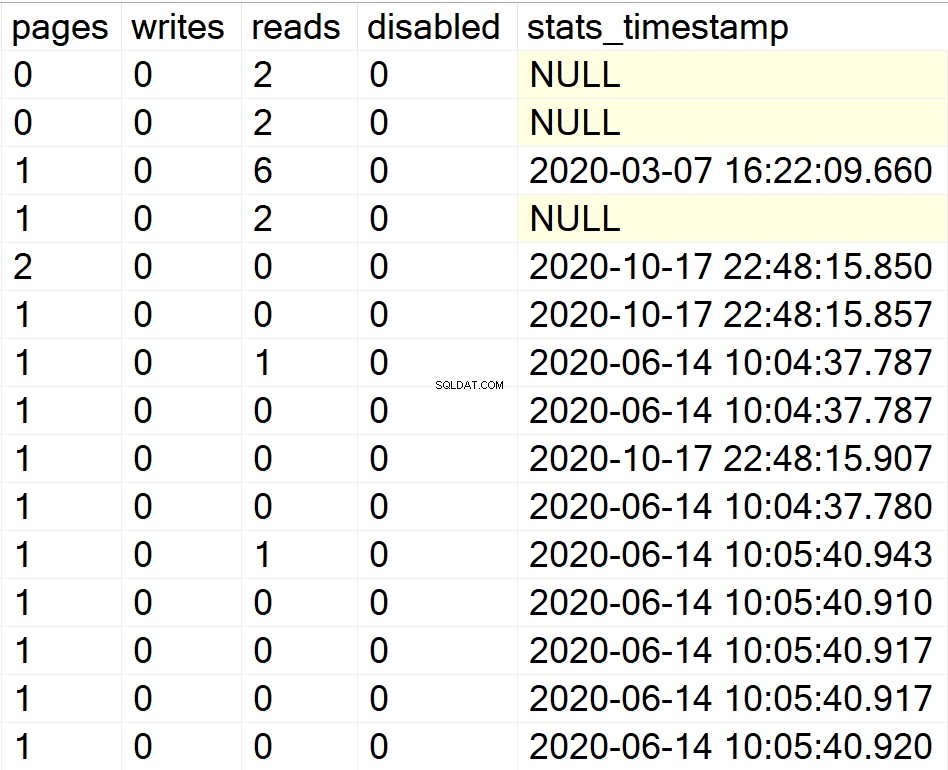
/* Vis alle indeksoplysninger for alle brugerdatabaser */
EXEC GetIndexData @persistData = 'N',@db = 'user'
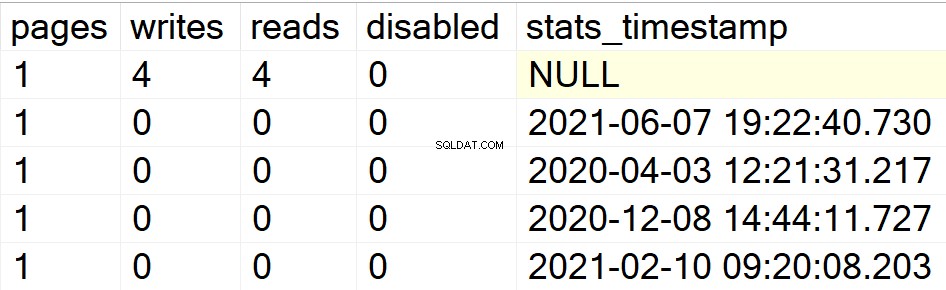
/* Vis alle indeksoplysninger for specifikke brugerdatabaser */
I mine tidligere eksempler var det kun databasen DBA, der dukkede op som min eneste brugerdatabase med indekser i. Lad mig derfor oprette en indeksstruktur i en anden database, jeg har liggende i samme instans, så du kan se, om SP'en gør sit eller ej.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Alle de eksempler, der er vist indtil videre, viser det output, du får, når du ikke ønsker at bevare data, for de forskellige kombinationer af muligheder for @db-parameteren. Outputtet er tomt, når du enten angiver en mulighed, der ikke er gyldig, eller måldatabasen ikke eksisterer. Men hvad med, når DBA ønsker at bevare data i en databasetabel? Lad os finde ud af det.
*Jeg vil kun køre SP for én sag, fordi resten af mulighederne for @db-parameteren stort set er blevet vist ovenfor, og resultatet er det samme, men forbliver i en databasetabel.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
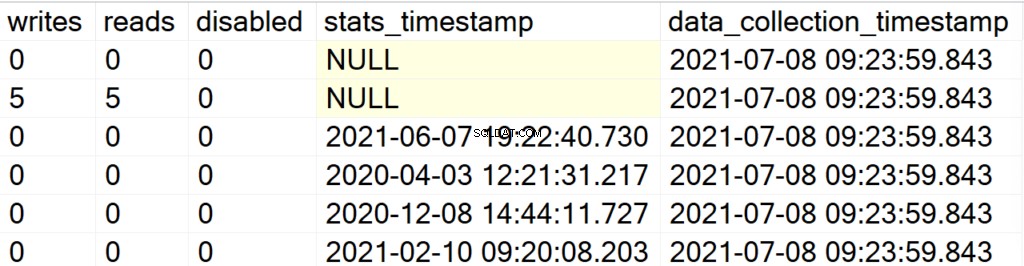
Nu, efter at du har udført den lagrede procedure, får du ikke noget output. For at forespørge resultatsættet skal du udstede en SELECT-sætning mod tabellen DBA_Index. Hovedattraktionen her er, at du kan forespørge på det opnåede resultatsæt til efteranalyse og tilføjelsen af feltet data_collection_timestamp, der vil fortælle dig, hvor nyere/gamle de data, du ser på, er.
Sideforespørgsler
Nu, for at levere mere værdi til DBA, har jeg forberedt et par forespørgsler, der kan hjælpe dig med at få nyttige oplysninger fra de data, der findes i tabellen.
*Forespørgsel for at finde meget fragmenterede indekser generelt.
*Vælg det antal %, som du mener passer.
*De 1500 sider er baseret på en artikel, jeg læste, baseret på Microsofts anbefaling.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Forespørgsel for at finde deaktiverede indekser i dit miljø.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Forespørgsel for at finde indekser (for det meste ikke-klyngede), der ikke er brugt så meget af forespørgsler, i hvert fald ikke siden sidste gang, SQL Server-instansen blev genstartet.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Forespørgsel for at finde statistikker, der enten aldrig er blevet opdateret eller er gamle.
*Du bestemmer, hvad der er gammelt i dit miljø, så sørg for at justere antallet af dage i overensstemmelse hermed.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Her er den komplette kode for den lagrede procedure:
*I begyndelsen af scriptet vil du se standardværdien, som den lagrede procedure antager, hvis der ikke sendes nogen værdi for hver parameter.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOKonklusion
- Du kan implementere denne SP i alle SQL Server-instanser under din support og implementere en advarselsmekanisme på tværs af hele din stak af understøttede instanser.
- Hvis du implementerer et agentjob, der relativt hyppigt forespørger efter disse oplysninger, kan du forblive på toppen af spillet for at tage dig af indeksstrukturerne i dine(de) understøttede miljø(er).
- Sørg for at teste denne mekanisme korrekt i et sandkassemiljø, og når du planlægger en produktionsimplementering, skal du sørge for at vælge perioder med lav aktivitet.
Indeksfragmenteringsproblemer kan være vanskelige og stressende. For at finde og rette dem kan du bruge forskellige værktøjer, såsom dbForge Index Manager, der kan downloades her.