Kan du lide at parse strenge? Hvis det er tilfældet, er en af de uundværlige strengfunktioner at bruge SQL SUBSTRING. Det er en af de færdigheder, en udvikler bør have til ethvert sprog.
Så hvordan gør du det?
Vigtige punkter i strengparsing
Antag, at du er ny til at analysere. Hvilke vigtige punkter skal du huske?
- Vid, hvilke oplysninger der er indlejret i strengen.
- Få de nøjagtige positioner af hver enkelt information i en streng. Du skal muligvis tælle alle tegn i strengen.
- Kend størrelsen eller længden af hver informationsdel i en streng.
- Brug den rigtige strengfunktion, der nemt kan udtrække hver enkelt information i strengen.
At kende alle disse faktorer vil forberede dig til at bruge SQL SUBSTRING() og sende argumenter til det.
SQL SUBSTRING-syntaks

Syntaksen for SQL SUBSTRING er som følger:
SUBSTRING(strengudtryk, start, længde)
- strengudtryk – a literal streng eller et SQL-udtryk, der returnerer en streng.
- start – et tal, hvor udvindingen starter. Det er også 1-baseret – det første tegn i strengudtryksargumentet skal starte med 1, ikke 0. I SQL Server er det altid et positivt tal. I MySQL eller Oracle kan det dog være positivt eller negativt. Hvis det er negativt, starter scanningen fra slutningen af strengen.
- længde – længden af tegn, der skal udtrækkes. SQL Server kræver det. I MySQL eller Oracle er det valgfrit.
4 SQL SUBSTRING-eksempler
1. Brug af SQL SUBSTRING til at udtrække fra en bogstavelig streng
Lad os starte med et simpelt eksempel ved hjælp af en bogstavelig streng. Vi bruger navnet på en berømt koreansk pigegruppe, BlackPink, og figur 1 illustrerer, hvordan SUBSTRING vil fungere:

Koden nedenfor viser, hvordan vi udpakker den:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Lad os nu også inspicere resultatsættet i figur 2:
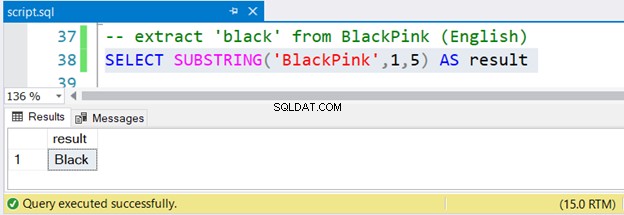
Er det ikke nemt?
For at udtrække Sort fra BlackPink , starter du fra position 1 og slutter i position 5. Siden BlackPink er koreansk, lad os finde ud af det, om SUBSTRING fungerer på Unicode-koreanske tegn.
(ANSVARSFRASKRIVELSE :Jeg kan ikke tale, læse eller skrive koreansk, så jeg fik den koreanske oversættelse fra Wikipedia. Jeg brugte også Google Oversæt til at se, hvilke tegn der svarer til Sort og Pink . Undskyld mig, hvis det er forkert. Alligevel håber jeg, at det punkt, jeg forsøger at præcisere, kommer í på tværs)
Lad os få strengen på koreansk (se figur 3). De anvendte koreanske tegn oversættes til BlackPink:

Se nu koden nedenfor. Vi vil udtrække to tegn svarende til Sort .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Lagde du mærke til den koreanske streng med N foran ? Den bruger Unicode-tegn, og SQL-serveren antager NVARCHAR og skal være foranstillet af N . Det er den eneste forskel i den engelske version. Men vil det køre fint? Se figur 4:
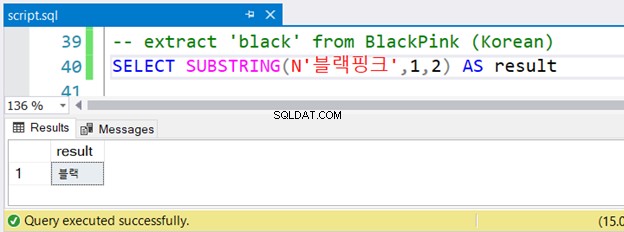
Den kørte uden fejl.
2. Brug af SQL SUBSTRING i MySQL med et negativt startargument
At have et negativt startargument virker ikke i SQL Server. Men vi kan have et eksempel på dette ved hjælp af MySQL. Lad os denne gang udtrække Pink fra BlackPink . Her er koden:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Lad os nu få resultatet i figur 5:
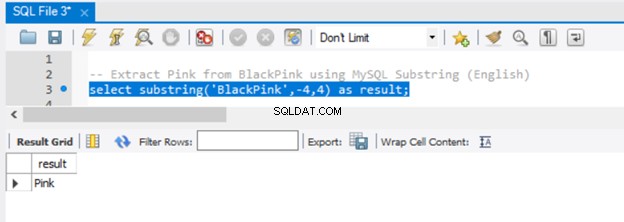
Siden vi sendte -4 til startparameteren, startede udtrækningen fra slutningen af strengen og gik 4 tegn baglæns. For at opnå det samme resultat i SQL Server skal du bruge RIGHT()-funktionen.
Unicode-tegn fungerer også med MySQL SUBSTRING, som du kan se i figur 6:
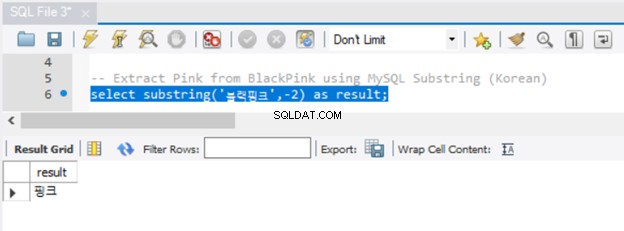
Det fungerede fint. Men lagde du mærke til, at vi ikke behøvede at sætte N foran strengen? Bemærk også, at der er flere måder at få en understreng i MySQL. Du har allerede set SUBSTRING. De tilsvarende funktioner i MySQL er SUBSTR() og MID().
3. Parsing af understrenge med variable start- og længdeargumenter
Desværre bruger ikke alle strengudtrækninger faste start- og længdeargumenter. I et sådant tilfælde har du brug for CHARINDEX for at få positionen for en streng, du målretter mod. Lad os tage et eksempel:
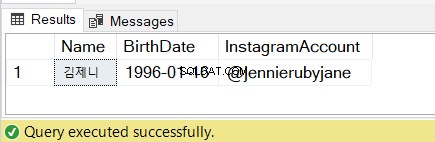
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
I koden ovenfor skal du udtrække et navn på koreansk, fødselsdatoen og Instagram-kontoen.
Vi starter med at definere tre variabler til at holde disse stykker information. Derefter kan vi parse strengen og tildele resultaterne til hver variabel.
Du tror måske, at det er nemmere at have faste starter og længder. Desuden kan vi lokalisere det ved at tælle tegnene manuelt. Men hvad hvis du har mange af disse på et bord?
Her er vores analyse:
- Det eneste faste element i strengen er @ karakter på Instagram-kontoen. Vi kan få dens position i strengen ved hjælp af CHARINDEX. Derefter bruger vi denne position til at få starten og længden af resten.
- Fødselsdatoen er i et fast format med MM/dd/åååå med 10 tegn.
- For at udtrække navnet starter vi ved 1. Da fødselsdatoen har 10 tegn plus @ tegn, kan du komme til sluttegnet af navnet i strengen. Fra positionen for @ karakter, går vi 11 tegn tilbage. SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) er vejen at gå.
- For at få fødselsdatoen anvender vi den samme logik. Få positionen for @ tegn og flyt 10 tegn tilbage for at få fødselsdatoens startværdi. 10 er en fast længde. SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10) er, hvordan man får fødselsdatoen.
- Endelig er det nemt at få en Instagram-konto. Start fra positionen for @ tegn ved hjælp af CHARINDEX. Bemærk:30 er grænsen for Instagram-brugernavne.
Se resultaterne i figur 7:
4. Brug af SQL SUBSTRING i en SELECT-sætning
Du kan også bruge SUBSTRING i SELECT-sætningen, men først skal vi have arbejdsdata. Her er koden:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Ovenstående kode laver en lang streng, der indeholder navn, e-mailadresse, by og postnummer. Vi ønsker også at gemme det i Personkontakterne tabel.
Lad os nu få koden til omvendt konstruktion ved hjælp af SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Da vi brugte kolonner med fast størrelse, er der ingen grund til at bruge CHARINDEX.
Brug af SQL SUBSTRING i en WHERE-sætning – en præstationsfælde?
Det er sandt. Ingen kan forhindre dig i at bruge SUBSTRING i en WHERE-sætning. Det er en gyldig syntaks. Men hvad hvis det forårsager ydeevneproblemer?
Det er derfor, vi beviser det med et eksempel og diskuterer derefter, hvordan man løser dette problem. Men lad os først forberede vores data:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Jeg kan ikke ødelægge SalesOrderHeader bord, så jeg dumpede det til et andet bord. Derefter lavede jeg SalesOrderID i de nye Salgsordrer tabel en primær nøgle.
Nu er vi klar til forespørgslen. Jeg bruger dbForge Studio til SQL Server med Forespørgselsprofileringstilstand TIL at analysere forespørgslerne.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Som du kan se, kører ovenstående forespørgsel fint. Se nu på forespørgselsprofilplandiagrammet i figur 8:
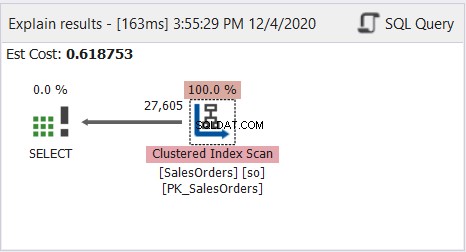
Plandiagrammet ser simpelt ud, men lad os inspicere egenskaberne for Clustered Index Scan-noden. Vi har især brug for Runtime Information:
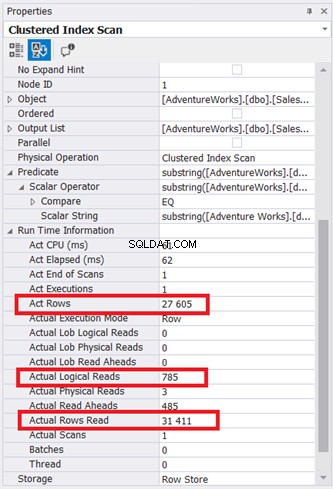
Illustration 9 viser 785 * 8KB sider læst af databasemotoren. Bemærk også, at den faktiske læste række er 31.411. Det er det samlede antal rækker i tabellen. Forespørgslen returnerede dog kun 27.605 faktiske rækker.
Hele tabellen blev læst ved at bruge det klyngede indeks som reference.
Hvorfor?
Sagen er, at SQL Server skal vide, om 4030 er en understreng af et kontonummer. Den skal læse og evaluere hver post. Kassér de rækker, der ikke er ens, og returner de rækker, vi skal bruge. Det får arbejdet gjort, men ikke hurtigt nok.
Hvad kan vi gøre for at få det til at køre hurtigere?
Undgå SUBSTRING i WHERE-klausulen og opnå det samme resultat hurtigere
Det, vi ønsker nu, er at få det samme resultat uden at bruge SUBSTRING i WHERE-sætningen. Følg nedenstående trin:
- Rediger tabellen ved at tilføje en beregnet kolonne med en SUBSTRING(kontonummer, 4,4) formel. Lad os kalde det AccountCategory i mangel af et bedre udtryk.
- Opret et ikke-klynget indeks for den nye AccountCategory kolonne. Inkluder Ordredato , Kontonummer og Kunde-id kolonner.
Det er det.
Vi ændrer WHERE-klausulen i forespørgslen for at tilpasse den nye AccountCategory kolonne:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
Der er ingen SUBSTRING i WHERE-sætningen. Lad os nu tjekke plandiagrammet:
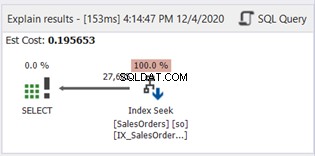
Indeksscanningen er blevet erstattet af Index Seek. Bemærk også, at SQL Server brugte det nye indeks på den beregnede kolonne. Er der også ændringer i logiske læsninger og faktiske rækker læst? Se figur 11:
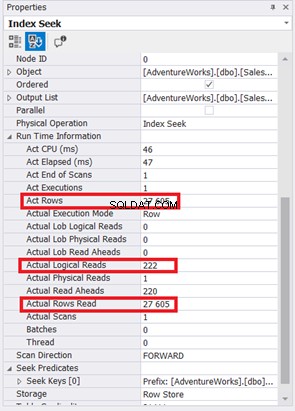
At reducere fra 785 til 222 logiske læsninger er en stor forbedring, mere end tre gange mindre end de originale logiske læsninger. Det minimerede også Faktiske rækker Læs til kun de rækker, vi har brug for.
Brug af SUBSTRING i WHERE-sætningen er således ikke godt for ydeevnen, og det gælder for enhver anden skalarværdi-funktion, der bruges i WHERE-sætningen.
Konklusion
- Udviklere kan ikke undgå at parse strenge. Et behov for det vil opstå på den ene eller anden måde.
- Ved at analysere strenge er det vigtigt at kende oplysningerne i strengen, placeringen af hver enkelt information og deres størrelser eller længder.
- En af parsingsfunktionerne er SQL SUBSTRING. Den behøver kun strengen for at parse, positionen for at starte udtrækning og længden af strengen for at udtrække.
- SUBSTRING kan have forskellig adfærd mellem SQL-varianter som SQL Server, MySQL og Oracle.
- Du kan bruge SUBSTRING med bogstavelige strenge og strenge i tabelkolonner.
- Vi brugte også SUBSTRING med Unicode-tegn.
- Brug af SUBSTRING eller en hvilken som helst funktion med skalarværdi i WHERE-udtrykket kan reducere forespørgselsydeevnen. Løs dette med en indekseret beregnet kolonne.
Hvis du finder dette indlæg nyttigt, kan du dele det på dine foretrukne sociale medieplatforme eller dele din kommentar nedenfor?