SQL Server 2005 tilføjede muligheden for at inkludere nonkey-kolonner i et ikke-klynget indeks. I SQL Server 2000 og tidligere, for et ikke-klynget indeks, var alle kolonner, der var defineret for et indeks, nøglekolonner, hvilket betød, at de var en del af hvert niveau af indekset, fra roden og ned til bladniveauet. Når en kolonne er defineret som en inkluderet kolonne, er den kun en del af bladniveauet. Books Online bemærker følgende fordele ved inkluderede kolonner:
- De kan være datatyper, der ikke er tilladt som indeksnøglekolonner.
- De tages ikke i betragtning af databasemotoren, når antallet af indeksnøglekolonner eller indeksnøglestørrelse beregnes.
For eksempel kan en varchar(max) kolonne ikke være en del af en indeksnøgle, men den kan være en inkluderet kolonne. Ydermere tæller den varchar(max)-kolonne ikke mod grænsen på 900 byte (eller 16-kolonnen), der er pålagt for indeksnøglen.
Dokumentationen noterer også følgende ydeevnefordel:
Et indeks med nonkey-kolonner kan forbedre forespørgselsydeevnen betydeligt, når alle kolonner i forespørgslen er inkluderet i indekset enten som nøgle- eller nonkey-kolonner. Ydeevneforbedringer opnås, fordi forespørgselsoptimeringsværktøjet kan lokalisere alle kolonneværdierne i indekset; Der er ikke adgang til tabel- eller klyngede indeksdata, hvilket resulterer i færre disk I/O-handlinger.Vi kan udlede, at uanset om indekskolonnerne er nøglekolonner eller nonkey-kolonner, får vi en forbedring i ydeevnen i forhold til, når alle kolonner ikke er en del af indekset. Men er der en præstationsforskel mellem de to variationer?
Opsætningen
Jeg installerede en kopi af AdventuresWork2012-databasen og verificerede indekserne for Sales.SalesOrderHeader-tabellen ved hjælp af Kimberly Tripps version af sp_helpindex:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Standardindekser for Sales.SalesOrderHeader
Vi starter med en ligetil forespørgsel til test, der henter data fra flere kolonner:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Hvis vi udfører dette mod AdventureWorks2012-databasen ved hjælp af SQL Sentry Plan Explorer og kontrollerer planen og Table I/O-outputtet, ser vi, at vi får en klynget indeksscanning med 689 logiske læsninger:
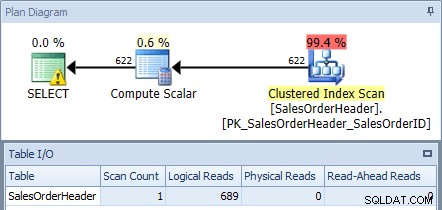
Udførelsesplan fra original forespørgsel
(I Management Studio kunne du se I/O-metrikkene ved hjælp af SET STATISTICS IO ON; .)
SELECT har et advarselsikon, fordi optimeringsværktøjet anbefaler et indeks for denne forespørgsel:
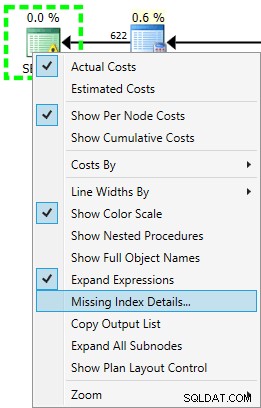
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
Vi vil først oprette det indeks, som optimeringsværktøjet anbefaler (navngivet NCI1_included), samt variationen med alle kolonnerne som nøglekolonner (kaldet NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Hvis vi kører den oprindelige forespørgsel igen, når vi antyder den med NCI1, og når vi antyder den med NCI1_included, ser vi en plan, der ligner originalen, men denne gang er der en indekssøgning for hvert ikke-klyngede indeks med tilsvarende værdier for tabel I/ O, og lignende omkostninger (begge ca. 0,006):
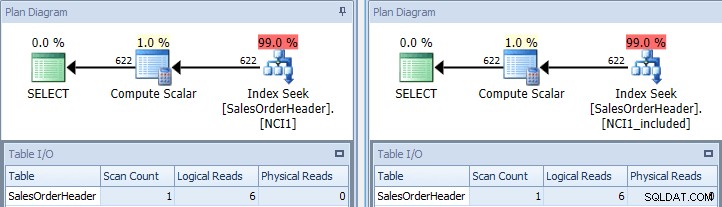
Original forespørgsel med indekssøgninger – tast til venstre, medtag på det rigtige
(Scanningstallet er stadig 1, fordi indekssøgningen faktisk er en rækkeviddescanning i forklædning.)
Nu er AdventureWorks2012-databasen ikke repræsentativ for en produktionsdatabase med hensyn til størrelse, og hvis vi ser på antallet af sider i hvert indeks, ser vi, at de er nøjagtigt de samme:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
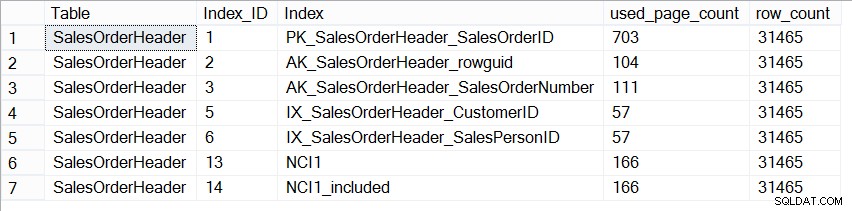
Størrelse af indekser på Sales.SalesOrderHeader
Hvis vi ser på ydeevne, er det ideelt (og sjovere) at teste med et større datasæt.
Test 2
Jeg har en kopi af AdventureWorks2012-databasen, der har en SalesOrderHeader-tabel med over 200 millioner rækker (script HER), så lad os oprette de samme ikke-klyngede indekser i den database og køre forespørgslerne igen:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
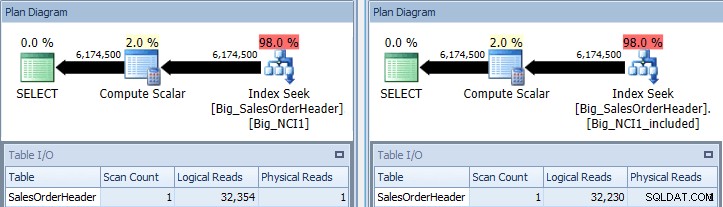
Original forespørgsel med indekssøgninger mod Big_NCI1 (l) og Big_NCI1_Included ( r)
Nu får vi nogle data. Forespørgslen returnerer over 6 millioner rækker, og søgning af hvert indeks kræver lidt over 32.000 læsninger, og den anslåede pris er den samme for begge forespørgsler (31.233). Ingen præstationsforskelle endnu, og hvis vi tjekker størrelsen på indeksene, ser vi, at indekset med de inkluderede kolonner har 5.578 færre sider:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Størrelse af indekser på Sales.Big_SalesOrderHeader
Hvis vi graver yderligere i dette og tjekker dm_dm_index_physical_stats, kan vi se, at der er forskel på de mellemliggende niveauer af indekset:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
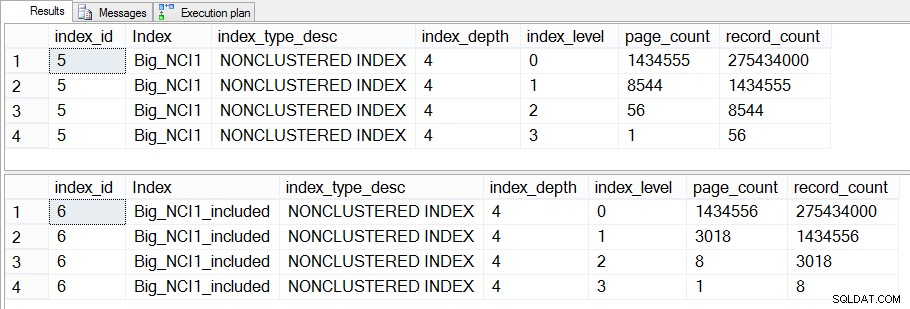
Størrelse af indekser (niveauspecifik) på Sales.Big_SalesOrderHeader
Forskellen mellem de mellemliggende niveauer af de to indekser er 43 MB, hvilket måske ikke er signifikant, men jeg ville nok stadig være tilbøjelig til at oprette indekset med inkluderede kolonner for at spare plads – både på disken og i hukommelsen. Fra et forespørgselsperspektiv ser vi stadig ikke en stor ændring i ydeevnen mellem indekset med alle kolonnerne i nøglen og indekset med de inkluderede kolonner.
Test 3
Til denne test, lad os ændre forespørgslen og tilføje et filter for [SubTotal] >= 100 til WHERE-sætningen:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
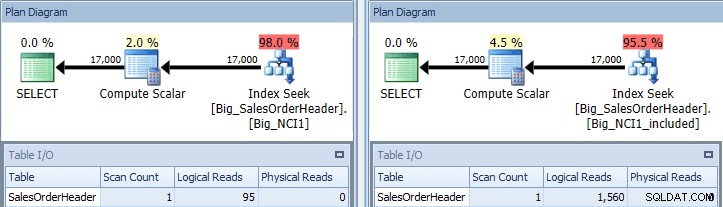
Udførelsesplan for forespørgsel med SubTotal-prædikat mod begge indekser
Nu ser vi en forskel i I/O (95 læsninger versus 1.560), omkostninger (0,848 vs 1,55) og en subtil, men bemærkelsesværdig forskel i forespørgselsplanen. Når du bruger indekset med alle kolonnerne i nøglen, er søgeprædikatet Kunde-ID og SubTotal:
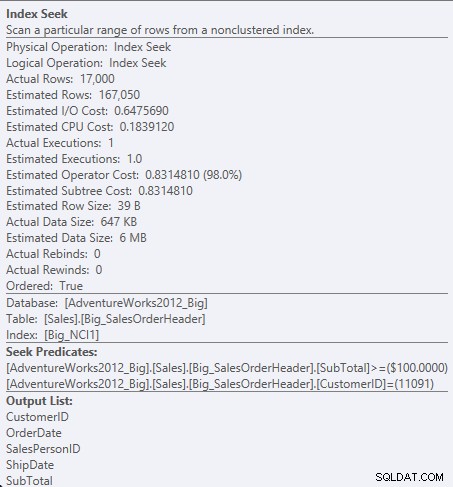
Søg prædikat mod NCI1
Fordi SubTotal er den anden kolonne i indeksnøglen, er dataene ordnet, og SubTotal eksisterer i de mellemliggende niveauer af indekset. Motoren er i stand til at søge direkte til den første post med et kunde-ID på 11091 og SubTotal større end eller lig med 100 og derefter læse indekset igennem, indtil der ikke findes flere poster for kunde-id 11091.
For indekset med de inkluderede kolonner eksisterer SubTotal kun i bladniveauet af indekset, så KundeID er søgeprædikatet, og SubTotal er et resterende prædikat (bare angivet som prædikat i skærmbilledet):
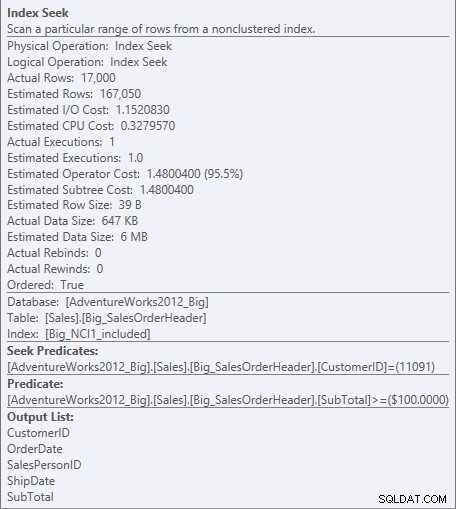
Søg prædikat og residualprædikat mod NCI1_included
Motoren kan søge direkte til den første post, hvor kunde-id er 11091, men så skal den se på hver optag for kunde-id 11091 for at se, om undertotalen er 100 eller højere, fordi dataene er sorteret efter kunde-id og salgsordre-id (klyngenøgle).
Test 4
Vi prøver endnu en variant af vores forespørgsel, og denne gang tilføjer vi en BESTILLING AF:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
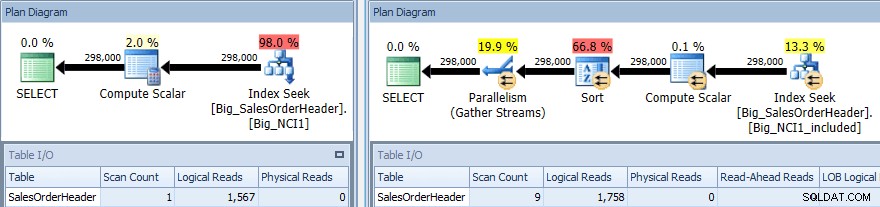
Udførelsesplan for forespørgsel med SORT mod begge indekser
Igen har vi en ændring i I/O (selvom meget lille), en ændring i omkostninger (1,5 vs. 9,3) og meget større ændring i planens form; vi ser også et større antal scanninger (1 mod 9). Forespørgslen kræver, at dataene sorteres efter SubTotal; når SubTotal er en del af indeksnøglen, sorteres det, så når posterne for kunde-ID 11091 hentes, er de allerede i den anmodede rækkefølge.
Når SubTotal eksisterer som en inkluderet kolonne, skal posterne for kunde-id 11091 sorteres, før de kan returneres til brugeren, derfor indskyder optimeringsværktøjet en sorteringsoperator i forespørgslen. Som et resultat anmoder forespørgslen, der bruger indekset Big_NCI1_included, også (og gives) en hukommelsesbevilling på 29.312 KB, hvilket er bemærkelsesværdigt (og findes i egenskaberne for planen).
Oversigt
Det oprindelige spørgsmål, vi ønskede at besvare, var, om vi ville se en præstationsforskel, når en forespørgsel brugte indekset med alle kolonner i nøglen, versus indekset med de fleste af kolonnerne inkluderet i bladniveauet. I vores første sæt af tests var der ingen forskel, men i vores tredje og fjerde test var der. Det afhænger i sidste ende af forespørgslen. Vi så kun på to variationer – den ene havde et ekstra prædikat, den anden havde en ORDER BY – der findes mange flere.
Hvad udviklere og DBA'er skal forstå er, at der er nogle store fordele ved at inkludere kolonner i et indeks, men de vil ikke altid præstere det samme som indekser, der har alle kolonner i nøglen. Det kan være fristende at flytte kolonner, der ikke er en del af prædikater og joinforbindelser, ud af nøglen og blot inkludere dem for at reducere den samlede størrelse af indekset. I nogle tilfælde kræver dette dog flere ressourcer til udførelse af forespørgsler og kan forringe ydeevnen. Nedbrydningen kan være ubetydelig; det er måske ikke ... du ved det ikke, før du tester. Når du designer et indeks, er det derfor vigtigt at tænke på kolonnerne efter den førende - og forstå, om de skal være en del af nøglen (f.eks. fordi det vil give en fordel at holde orden på data), eller om de kan tjene deres formål som inkluderet. kolonner.
Som det er typisk med indeksering i SQL Server, skal du teste dine forespørgsler med dine indekser for at bestemme den bedste strategi. Det forbliver en kunst og en videnskab – at forsøge at finde det mindste antal indekser for at tilfredsstille så mange forespørgsler som muligt.