Primære og fremmede nøgler er grundlæggende kendetegn ved relationelle databaser, som oprindeligt bemærket i E.F. Codds papir, "A Relational Model of Data for Large Shared Data Banks", udgivet i 1970. Citatet, der ofte gentages, er:"Nøglen, hele nøglen, og intet andet end nøglen, så hjælp mig Codd."
Baggrund:Primære nøgler
En primær nøgle er en begrænsning i SQL Server, som fungerer til entydigt at identificere hver række i en tabel. Nøglen kan defineres som en enkelt ikke-NULL-kolonne eller en kombination af ikke-NULL-kolonner, der genererer en unik værdi og bruges til at håndhæve entitetsintegritet for en tabel. En tabel kan kun have én primærnøgle, og når en primærnøglebegrænsning er defineret for en tabel, oprettes et unikt indeks. Dette indeks vil som standard være et klynget indeks, medmindre det er angivet som et ikke-klynget indeks, når den primære nøglebegrænsning er defineret.
Overvej Sales.SalesOrderHeader tabellen i AdventureWorks2012 database. Denne tabel indeholder grundlæggende oplysninger om en salgsordre, inklusive ordredato og kunde-id, og hvert salg er unikt identificeret med et SalesOrderID , som er den primære nøgle til tabellen. Hver gang en ny række føjes til tabellen, vil den primære nøglebegrænsning (kaldet PK_SalesOrderHeader_SalesOrderID ) kontrolleres for at sikre, at der ikke allerede eksisterer en række med den samme værdi for SalesOrderID .
Udenlandske nøgler
Adskilt fra primære nøgler, men meget relaterede, er fremmednøgler. En fremmednøgle er en kolonne eller kombination af kolonner, der er den samme som den primære nøgle, men i en anden tabel. Fremmednøgler bruges til at definere en relation og håndhæve integritet mellem to tabeller.
For at fortsætte med at bruge det førnævnte eksempel, SalesOrderID kolonnen findes som en fremmednøgle i Sales.SalesOrderDetail tabel, hvor yderligere oplysninger om salget opbevares, såsom produkt-id og pris. Når et nyt salg føjes til SalesOrderHeader tabel, er det ikke nødvendigt at tilføje en række for det pågældende salg til SalesOrderDetail tabel Men når du tilføjer en række til SalesOrderDetail tabel, en tilsvarende række for SalesOrderID skal findes i SalesOrderHeader tabel.
Omvendt, når du sletter data, en række for et specifikt SalesOrderID kan til enhver tid slettes fra SalesOrderDetail tabel, men for at en række skal slettes fra SalesOrderHeader tabel, tilknyttede rækker fra SalesOrderDetail skal slettes først.
I modsætning til primærnøglebegrænsninger, når en fremmednøglebegrænsning er defineret for en tabel, oprettes et indeks ikke som standard af SQL Server. Det er dog ikke ualmindeligt, at udviklere og databaseadministratorer tilføjer dem manuelt. Den fremmede nøgle kan være en del af en sammensat primær nøgle til tabellen, i hvilket tilfælde et klyngeindeks ville eksistere med den fremmede nøgle som en del af klyngingsnøglen. Alternativt kan forespørgsler kræve et indeks, der inkluderer den fremmede nøgle og en eller flere yderligere kolonner i tabellen, så et ikke-klynget indeks ville blive oprettet for at understøtte disse forespørgsler. Ydermere kan indekser på fremmede nøgler give ydeevnefordele for tabelsammenføjninger, der involverer den primære og fremmede nøgle, og de kan påvirke ydeevnen, når den primære nøgleværdi opdateres, eller hvis rækken slettes.
I AdventureWorks2012 database, er der én tabel, SalesOrderDetail , med SalesOrderID som fremmednøgle. For SalesOrderDetail tabel, SalesOrderID og SalesOrderDetailID kombinere for at danne den primære nøgle, understøttet af et klynget indeks. Hvis SalesOrderDetail tabellen havde ikke et indeks på SalesOrderID kolonne, og derefter når en række slettes fra SalesOrderHeader , skal SQL Server verificere, at ingen rækker for samme SalesOrderID værdi eksisterer. Uden nogen indekser, der indeholder SalesOrderID kolonne, skal SQL Server udføre en komplet tabelscanning af SalesOrderDetail . Som du kan forestille dig, jo større den refererede tabel er, jo længere tid vil sletningen tage.
Et eksempel
Vi kan se dette i følgende eksempel, som bruger kopier af de førnævnte tabeller fra AdventureWorks2012 database, der er blevet udvidet ved hjælp af et script, som kan findes her. Scriptet er udviklet af Jonathan Kehayias (blog | @SQLPoolBoy) og skaber en SalesOrderHeaderEnlarged tabel med 1.258.600 rækker og en SalesOrderDetailEnlarged bord med 4.852.680 rækker. Efter at scriptet blev kørt, blev den fremmede nøgle-begrænsning tilføjet ved hjælp af sætningerne nedenfor. Bemærk, at begrænsningen er oprettet med ON DELETE CASCADE mulighed. Med denne mulighed, når en opdatering eller sletning udstedes mod SalesOrderHeaderEnlarged tabel, rækker i den eller de tilsvarende tabeller – i dette tilfælde kun SalesOrderDetailEnlarged – opdateres eller slettes.
Derudover er standard, klyngede indeks for SalesOrderDetailEnglarged blev droppet og genskabt for kun at have SalesOrderDetailID som den primære nøgle, da den repræsenterer et typisk design.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Med den fremmede nøgle-begrænsning og intet understøttende indeks blev der udstedt en enkelt sletning mod SalesOrderHeaderEnlarged tabel, hvilket resulterede i fjernelse af én række fra SalesOrderHeaderEnlarged og 72 rækker fra SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Statistikkens IO og timingoplysninger viste følgende:
SQL Server-parse og kompileringstid:CPU-tid =8 ms, forløbet tid =8 ms.
Tabel 'SalgOrdredetaljeforstørret'. Scanning tæller 1, logisk læser 50647, fysisk læser 8, read-ahead læser 50667, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Worktable'. Scanningsantal 2, logisk læser 7, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'SalesOrderHeaderEnlarged'. Scanningsantal 0, logisk læser 15, fysisk læser 14, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
SQL Server-udførelsestider:
CPU-tid =1045 ms, forløbet tid =1898 ms.
Ved at bruge SQL Sentry Plan Explorer viser eksekveringsplanen en klynget indeksscanning mod SalesOrderDetailEnlarged da der ikke er noget indeks på SalesOrderID :
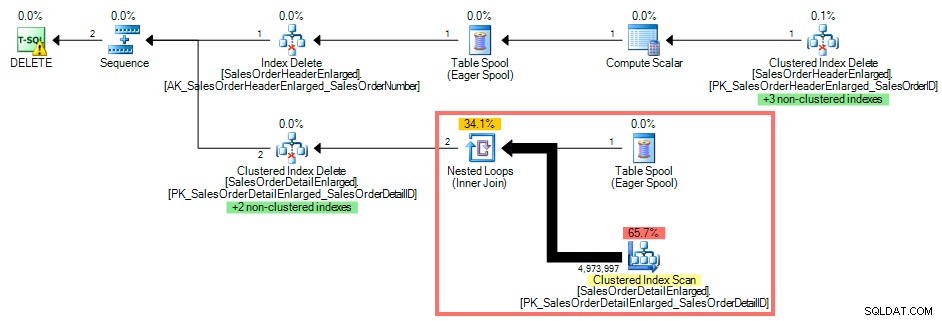
Forespørgselsplan uden indeks på fremmednøgle
Det ikke-klyngede indeks, der understøtter SalesOrderDetailEnlarged blev derefter oprettet ved hjælp af følgende sætning:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Endnu en sletning blev udført for et SalesOrderID der påvirkede én række i SalesOrderHeaderEnlarged og 72 rækker i SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Statistikkens IO og timingoplysninger viste en dramatisk forbedring:
SQL Server-parse og kompileringstid:CPU-tid =0 ms, forløbet tid =7 ms.
Tabel 'SalgOrdredetaljeforstørret'. Scanning tæller 1, logisk læser 48, fysisk læser 13, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Arbejdstabel'. Scanningsantal 2, logisk læser 7, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'SalesOrderHeaderEnlarged'. Scanningsantal 0, logisk læser 15, fysisk læser 15, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
SQL Server-udførelsestider:
CPU-tid =0 ms, forløbet tid =27 ms.
Og forespørgselsplanen viste en indekssøgning af det ikke-klyngede indeks på SalesOrderID , som forventet:
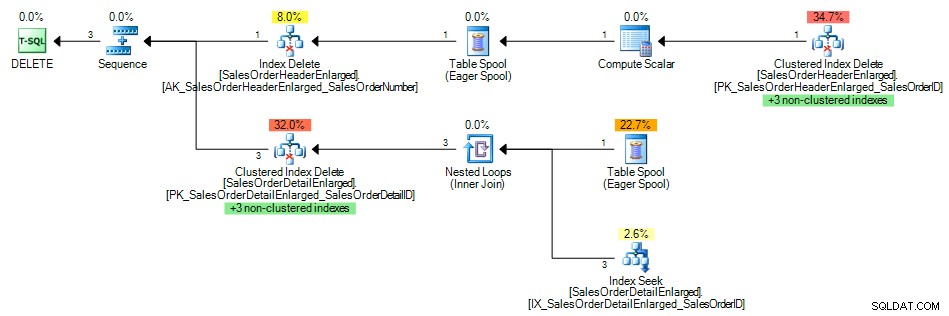
Forespørgselsplan med indeks på udenlandsk nøgle
Forespørgselsudførelsestiden faldt fra 1898 ms til 27 ms – en reduktion på 98,58 % og viser SalesOrderDetailEnlarged tabel faldet fra 50647 til 48 - en forbedring på 99,9%. Bortset fra procenter, overvej den I/O alene, der genereres af sletningen. SalesOrderDetailEnlarged tabellen er kun 500 MB i dette eksempel, og for et system med 256 GB tilgængelig hukommelse virker en tabel, der fylder 500 MB i buffercachen, ikke som en frygtelig situation. Men en tabel med 5 millioner rækker er relativt lille; de fleste store OLTP-systemer har tabeller med hundredvis af millioner rækker. Derudover er det ikke ualmindeligt, at der findes flere fremmednøglereferencer for en primærnøgle, hvor en sletning af den primære nøgle kræver sletninger fra flere relaterede tabeller. I så fald er det muligt at se forlængede varigheder for sletninger, hvilket ikke kun er et ydeevneproblem, men også et blokeringsproblem, afhængigt af isolationsniveau.
Konklusion
Det anbefales generelt at oprette et indeks, der fører til fremmednøglekolonnen(-erne), for ikke kun at understøtte joinforbindelser mellem primær- og fremmednøgler, men også opdateringer og sletninger. Bemærk, at dette er en generel anbefaling, da der er edge case-scenarier, hvor det ekstra indeks på den fremmede nøgle ikke blev brugt på grund af ekstrem lille tabelstørrelse, og de yderligere indeksopdateringer faktisk påvirkede ydeevnen negativt. Som med alle skemaændringer bør indekstilføjelser testes og overvåges efter implementering. Det er vigtigt at sikre, at de yderligere indekser giver de ønskede effekter og ikke påvirker løsningens ydeevne negativt. Det er også værd at bemærke, hvor meget ekstra plads der kræves af indekserne til fremmednøglerne. Dette er vigtigt at overveje, før du opretter indekserne, og hvis de giver en fordel, skal det overvejes for kapacitetsplanlægning fremover.