SQL Server har traditionelt holdt sig væk fra at levere native løsninger til nogle af de mere almindelige statistiske spørgsmål, såsom at beregne en median. Ifølge WikiPedia er "medianen beskrevet som den numeriske værdi, der adskiller den højere halvdel af en stikprøve, en population eller en sandsynlighedsfordeling, fra den nedre halvdel. Medianen af en endelig liste af tal kan findes ved at arrangere alle observationerne fra laveste værdi til højeste værdi og vælge den midterste. Hvis der er et lige antal observationer, er der ingen enkelt mellemværdi; medianen defineres så normalt som middelværdien af de to midterste værdier."
Med hensyn til en SQL Server-forespørgsel er den vigtigste ting, du vil tage væk fra, at du skal "arrangere" (sortere) alle værdierne. Sortering i SQL Server er typisk en temmelig dyr operation, hvis der ikke er et understøttende indeks, og tilføjelse af et indeks for at understøtte en operation, som sandsynligvis ikke er anmodet om, som ofte ikke er umagen værd.
Lad os undersøge, hvordan vi typisk har løst dette problem i tidligere versioner af SQL Server. Lad os først oprette en meget enkel tabel, så vi kan se, at vores logik er korrekt og udlede en nøjagtig median. Vi kan teste følgende to tabeller, den ene med et lige antal rækker og den anden med et ulige antal rækker:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Blot fra tilfældig observation kan vi se, at medianen for tabellen med ulige rækker skal være 6, og for den lige tabel skal den være 7,5 ((6+9)/2). Så lad os nu se nogle løsninger, der er blevet brugt gennem årene:
SQL Server 2000
I SQL Server 2000 var vi begrænset til en meget begrænset T-SQL-dialekt. Jeg undersøger disse muligheder til sammenligning, fordi nogle mennesker derude stadig kører SQL Server 2000, og andre kan have opgraderet, men da deres medianberegninger blev skrevet "tilbage i dag", kan koden stadig se sådan ud i dag.
2000_A – maks. den ene halvdel, min. af den anden
Denne tilgang tager den højeste værdi fra de første 50 procent, den laveste værdi fra de sidste 50 procent og dividerer dem derefter med to. Dette virker for lige eller ulige rækker, fordi i lige tilfælde er de to værdier de to midterste rækker, og i ulige tilfælde er de to værdier faktisk fra samme række.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #temp tabel
Dette eksempel opretter først en #temp-tabel, og ved hjælp af samme type matematik som ovenfor bestemmes de to "midterste" rækker med hjælp fra en sammenhængende IDENTITY kolonne ordnet efter valkolonnen. (Rækkefølgen for tildeling af IDENTITY værdier kan kun stole på på grund af MAXDOP indstilling.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 introducerede nogle interessante nye vinduesfunktioner, såsom ROW_NUMBER() , som kan hjælpe med at løse statistiske problemer som median lidt lettere, end vi kunne i SQL Server 2000. Disse tilgange fungerer alle i SQL Server 2005 og nyere:
2005_A – duellerende rækkenumre
Dette eksempel bruger ROW_NUMBER() at gå op og ned af værdierne én gang i hver retning, så finder den "midterste" en eller to rækker baseret på den beregning. Dette ligner det første eksempel ovenfor, med lettere syntaks:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – rækkenummer + optælling
Denne er ret lig ovenstående ved at bruge en enkelt beregning af ROW_NUMBER() og derefter bruge den samlede COUNT() for at finde den "midterste" en eller to rækker:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – variation af rækkenummer + antal
Fellow MVP Itzik Ben-Gan viste mig denne metode, som opnår samme svar som de to ovenstående metoder, men på en meget lidt anderledes måde:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
I SQL Server 2012 har vi nye vinduesmuligheder i T-SQL, der tillader statistiske beregninger som median at blive udtrykt mere direkte. For at beregne medianen for et sæt værdier kan vi bruge PERCENTILE_CONT() . Vi kan også bruge den nye "paging"-udvidelse til ORDER BY klausul (OFFSET / FETCH ).
2012_A – ny distributionsfunktionalitet
Denne løsning bruger en meget ligetil beregning ved hjælp af distribution (hvis du ikke ønsker gennemsnittet mellem de to midterste værdier i tilfælde af et lige antal rækker).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – personsøgningstrick
Dette eksempel implementerer en smart brug af OFFSET / FETCH (og ikke lige en, som den var beregnet til) – vi flytter simpelthen til rækken, der er en før halvdelen af optællingen, og tager derefter den næste en eller to rækker afhængigt af, om optællingen var ulige eller lige. Tak til Itzik Ben-Gan for at påpege denne tilgang.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Men hvilken klarer sig bedst?
Vi har verificeret, at ovenstående metoder alle giver de forventede resultater på vores lille bord, og vi ved, at SQL Server 2012-versionen har den reneste og mest logiske syntaks. Men hvilken skal du bruge i dit travle produktionsmiljø? Vi kan bygge en meget større tabel ud fra systemmetadata og sikre, at vi har masser af duplikerede værdier. Dette script vil producere en tabel med 10.000.000 ikke-unikke heltal:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
På mit system skal medianen for denne tabel være 146.099.561. Jeg kan beregne dette ret hurtigt uden en manuel stikprøvekontrol på 10.000.000 rækker ved at bruge følgende forespørgsel:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Resultater:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Så nu kan vi oprette en lagret procedure for hver metode, verificere, at hver enkelt producerer det korrekte output, og derefter måle ydeevnemålinger såsom varighed, CPU og læsninger. Vi udfører alle disse trin med den eksisterende tabel og også med en kopi af tabellen, der ikke drager fordel af det klyngede indeks (vi dropper det og genskaber tabellen som en bunke).
Jeg har lavet syv procedurer, der implementerer forespørgselsmetoderne ovenfor. For kortheds skyld vil jeg ikke angive dem her, men hver af dem hedder dbo.Median_<version> , for eksempel. dbo.Median_2000_A , dbo.Median_2000_B osv. svarende til de ovenfor beskrevne fremgangsmåder. Hvis vi kører disse syv procedurer ved hjælp af den gratis SQL Sentry Plan Explorer, er her, hvad vi observerer med hensyn til varighed, CPU og læsninger (bemærk, at vi kører DBCC FREEPROCCACHE og DBCC DROPCLEANBUFFERS mellem udførelser):
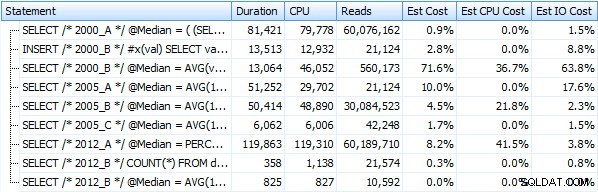
Og disse målinger ændrer sig ikke meget, hvis vi i stedet opererer mod en bunke. Den største procentvise ændring var den metode, der stadig endte med at være den hurtigste:personsøgningstricket ved hjælp af OFFSET / FETCH:
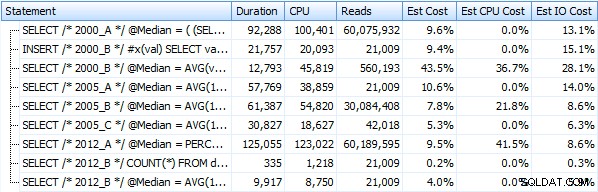
Her er en grafisk fremstilling af resultaterne. For at gøre det mere klart fremhævede jeg den langsomste performer i rødt og den hurtigste tilgang i grønt.
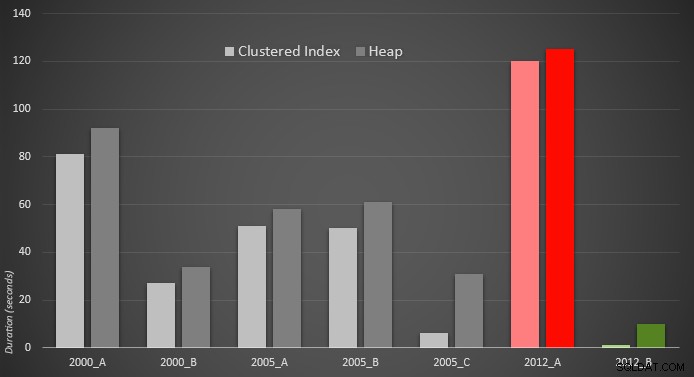
Jeg var overrasket over at se, at i begge tilfælde PERCENTILE_CONT() – som er designet til denne type beregning – er faktisk værre end alle de andre tidligere løsninger. Jeg gætter på, at det bare viser, at selvom nyere syntaks nogle gange kan gøre vores kodning lettere, garanterer det ikke altid, at ydeevnen forbedres. Jeg var også overrasket over at se OFFSET / FETCH vise sig at være så nyttige i scenarier, der normalt ikke ser ud til at passe til formålet – paginering.
Jeg håber i hvert fald, at jeg har demonstreret, hvilken tilgang du skal bruge, afhængig af din version af SQL Server (og at valget skal være det samme, uanset om du har et understøttende indeks til beregningen).