Begrebet godt eller dårligt design er relativt. Samtidig er der nogle programmeringsstandarder, som i de fleste tilfælde garanterer effektivitet, vedligeholdelse og testbarhed. For eksempel i objektorienterede sprog er dette brugen af indkapsling, arv og polymorfi. Der er et sæt designmønstre, der i en række tilfælde har en positiv eller negativ effekt på applikationsdesignet afhængig af situationen. På den anden side er der modsætninger, hvilket nogle gange fører til problemdesignet.
Dette design har normalt følgende indikatorer (en eller flere ad gangen):
- Stivhed (det er svært at ændre koden, da en simpel ændring påvirker mange steder);
- Immobilitet (det er kompliceret at opdele koden i moduler, der kan bruges i andre programmer);
- Viskositet (det er ret svært at udvikle eller teste koden);
- Unødvendig kompleksitet (der er en ubrugt funktionalitet i koden);
- Unødvendig gentagelse (Kopier/Sæt ind);
- Dårlig læsbarhed (det er svært at forstå, hvad koden er designet til og at vedligeholde den);
- Skørelighed (det er nemt at bryde funktionaliteten selv med små ændringer).
Du skal være i stand til at forstå og skelne mellem disse funktioner for at undgå et problemdesign eller forudsige mulige konsekvenser af dets brug. Disse indikatorer er beskrevet i bogen «Agile Principles, Patterns, And Practices in C#» af Robert Martin. Der er dog en kort beskrivelse og ingen kodeeksempler i denne artikel såvel som i andre oversigtsartikler.
Vi vil fjerne denne ulempe ved at dvæle ved hver funktion.
Stivhed
Som det er blevet nævnt, er en rigid kode svær at ændre, selv de mindste ting. Dette er muligvis ikke et problem, hvis koden ikke ændres ofte eller overhovedet. Dermed viser koden sig at være ganske god. Men hvis det er nødvendigt at ændre koden og svært at gøre dette, bliver det et problem, selvom det virker.
Et af de populære rigiditetstilfælde er eksplicit at specificere klassetyperne i stedet for at bruge abstraktioner (grænseflader, basisklasser osv.). Nedenfor kan du finde et eksempel på koden:
Her afhænger klasse A meget af klasse B. Så hvis du i fremtiden skal bruge en anden klasse i stedet for klasse B, vil dette kræve ændring af klasse A og vil føre til, at den testes igen. Desuden, hvis klasse B påvirker andre klasser, vil situationen blive meget kompliceret.
Løsningen er en abstraktion, der skal introducere IComponent-grænsefladen via konstruktøren af klasse A. I dette tilfælde vil den ikke længere afhænge af den bestemte klasse В og vil kun afhænge af IComponent-grænsefladen. Сlass В skal på sin side implementere IComponent-grænsefladen.
interface IComponent{ void DoSomething();}klasse A{ IComponent _component; public A(IComponent component) { _component =component; } void Foo() {// Lav noget tilpasset logik. _component.DoSomething(); // Lav noget tilpasset logik. }}klasse B :IComponent{ void DoSomething() {// Gør noget }} Lad os give et specifikt eksempel. Antag, at der er et sæt klasser, der logger oplysningerne – ProductManager og Consumer. Deres opgave er at gemme et produkt i databasen og bestille det tilsvarende. Begge klasser logger relevante hændelser. Forestil dig, at der først var en log ind i en fil. For at gøre dette blev FileLogger-klassen brugt. Derudover var klasserne placeret i forskellige moduler (samlinger).
// Module 1 (Client)static void Main(){ var product =new Product("milk"); var productManager =new ProductManager(); productManager.AddProduct(product); var forbruger =ny forbruger(); consumer.PurchaseProduct(product.Name);}// Modul 2 (Business logic)public class ProductManager{ private readonly FileLogger _logger =new FileLogger(); public void AddProduct(Produktprodukt) {// Tilføj produktet til databasen. _logger.Log("Produktet er tilføjet."); }}offentlig klasse Forbruger{ privat skrivebeskyttet FileLogger _logger =new FileLogger(); public void PurchaseProduct(string product) {// Køb produktet. _logger.Log("Produktet er købt."); }}offentlig klasse Produkt{ offentlig streng Navn { get; privat sæt; } offentligt produkt(strengnavn) { Navn =navn; }}// Modul 3 (Logger implementering) offentlig klasse FileLogger{ const string FileName ="log.txt"; public void Log(string message) {// Skriv beskeden til filen. }} Hvis det først var nok kun at bruge filen, og så bliver det nødvendigt at logge ind på andre depoter, såsom en database eller en cloud-baseret dataindsamling og lagringstjeneste, så bliver vi nødt til at ændre alle klasser i forretningslogikken modul (Modul 2), der bruger FileLogger. Det kan trods alt vise sig at være svært. For at løse dette problem kan vi introducere en abstrakt grænseflade til at arbejde med loggeren, som vist nedenfor.
// Modul 1 (Client)static void Main(){ var logger =new FileLogger(); var produkt =nyt produkt("mælk"); var productManager =new ProductManager(logger); productManager.AddProduct(product); var forbruger =ny forbruger(logger); consumer.PurchaseProduct(product.Name);}// Modul 2 (Business logic)class ProductManager{ private readonly ILogger _logger; public ProductManager(ILogger logger) { _logger =logger; } public void AddProduct(Produktprodukt) {// Tilføj produktet til databasen. _logger.Log("Produktet er tilføjet."); }}offentlig klasse Forbruger{ privat skrivebeskyttet ILogger _logger; public Consumer(ILogger logger) { _logger =logger; } public void PurchaseProduct(string product) {// Køb produktet. _logger.Log("Produktet er købt."); }}offentlig klasse Produkt{ offentlig streng Navn { get; privat sæt; } offentligt produkt(strengnavn) { Navn =navn; }}// Module 3 (interfaces)public interface ILogger{ void Log(string message);}// Module 4 (Logger implementering)public class FileLogger :ILogger{ const string FileName ="log.txt"; public virtual void Log(string message) {// Skriv beskeden til filen. }} I dette tilfælde, når du ændrer en loggertype, er det nok at ændre klientkoden (Main), som initialiserer loggeren og tilføjer den til konstruktøren af ProductManager og Consumer. Således lukkede vi klasserne af forretningslogik fra ændringen af loggertypen efter behov.
Ud over direkte links til de brugte klasser, kan vi overvåge stivhed i andre varianter, der kan føre til vanskeligheder ved ændring af koden. Der kan være et uendeligt sæt af dem. Vi vil dog forsøge at give et andet eksempel. Antag, at der er en kode, der viser arealet af et geometrisk mønster på konsollen.
static void Main(){ var rectangle =new Rectangle() { W =3, H =5 }; var cirkel =new Circle() { R =7 }; var shapes =new Shape[] { rektangel, cirkel }; ShapeHelper.ReportShapesSize(shapes);}class ShapeHelper{ private static double GetShapeArea(Shape shape) { if (form er rektangel) { return ((Rektangel)form).W * ((Rektangel)form).H; } if (form er Cirkel) { return 2 * Math.PI * ((Cirkel)form).R * ((Cirkel)form).R; } throw new InvalidOperationException("Ikke understøttet form"); } public static void ReportShapesSize(Shape[] shapes) { foreach(Shape shape in shapes) { if (shape is rektangel) { double area =GetShapeArea(shape); Console.WriteLine($"Rektangels område er {areal}"); } if (form er Cirkel) { dobbeltareal =GetShapeArea(form); Console.WriteLine($"Cirkels område er {område}"); } } }}public class Shape{ }public class Rektangel :Shape{ public double W { get; sæt; } offentlig dobbelt H { få; sæt; }}public class Circle :Shape{ public double R { get; sæt; }} Som du kan se, når vi tilføjer et nyt mønster, bliver vi nødt til at ændre metoderne i ShapeHelper-klassen. En af mulighederne er at videregive algoritmen for gengivelse i klasserne af geometriske mønstre (Rektangel og Cirkel), som vist nedenfor. På denne måde vil vi isolere den relevante logik i de tilsvarende klasser og derved reducere ShapeHelper-klassens ansvar, før vi viser information på konsollen.
static void Main(){ var rectangle =new Rectangle() { W =3, H =5 }; var cirkel =new Circle() { R =7 }; var shapes =new Shape[]() { rektangel, cirkel }; ShapeHelper.ReportShapesSize(shapes);}class ShapeHelper{ public static void ReportShapesSize(Shape[] shapes) { foreach(Shape shape in shapes) { shape.Report(); } }}public abstract class Shape{ public abstract void Report();}public class Rectangle :Shape{ public double W { get; sæt; } offentlig dobbelt H { få; sæt; } public override void Report() { double area =B * H; Console.WriteLine($"Rektangels område er {areal}"); }}public class Circle :Shape{ public double R { get; sæt; } public override void Rapport() { dobbeltareal =2 * Math.PI * R * R; Console.WriteLine($"Cirkels område er {område}"); }} Som et resultat lukkede vi faktisk ShapeHelper-klassen for ændringer, der tilføjer nye typer mønstre ved at bruge arv og polymorfi.
Immobilitet
Vi kan overvåge immobilitet, når vi opdeler koden i genanvendelige moduler. Som følge heraf kan projektet stoppe med at udvikle sig og være konkurrencedygtigt.
Som et eksempel vil vi overveje et skrivebordsprogram, hvis hele koden er implementeret i den eksekverbare applikationsfil (.exe) og er designet således, at forretningslogikken ikke er bygget i separate moduler eller klasser. Senere har udvikleren stået over for følgende forretningskrav:
- At ændre brugergrænsefladen ved at omdanne den til en webapplikation;
- At udgive programmets funktionalitet som et sæt webtjenester, der er tilgængelige for tredjepartsklienter, som kan bruges i deres egne applikationer.
I dette tilfælde er disse krav svære at opfylde, da hele koden er placeret i det eksekverbare modul.
Billedet nedenfor viser et eksempel på et immobilt design i modsætning til det, der ikke har denne indikator. De er adskilt af en stiplet linje. Som du kan se, tillader allokeringen af koden på genanvendelige moduler (Logic), samt offentliggørelsen af funktionaliteten på niveau med webtjenester, at bruge den i forskellige klientapplikationer (App), hvilket er en utvivlsom fordel.
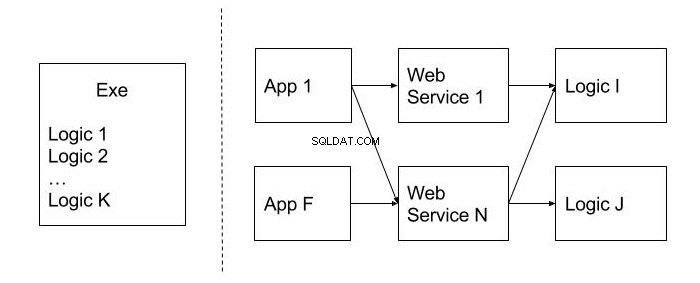
Immobilitet kan også kaldes et monolitisk design. Det er svært at opdele det i mindre og nyttige enheder af koden. Hvordan kan vi undgå dette problem? På designstadiet er det bedre at tænke på, hvor sandsynligt det er at bruge denne eller den funktion i andre systemer. Den kode, der forventes at blive genbrugt, placeres bedst i separate moduler og klasser.
Viskositet
Der er to typer:
- Udviklingsviskositet
- Miljøets viskositet
Vi kan se udviklingsviskositet, mens vi forsøger at følge det valgte applikationsdesign. Dette kan ske, når en programmør skal opfylde for mange krav, mens der er en nemmere måde at udvikle på. Derudover kan udviklingsviskositeten ses, når processen med montering, implementering og test ikke er effektiv.
Som et simpelt eksempel kan vi betragte arbejdet med konstanter, der skal placeres (By Design) i et separat modul (Modul 1), der skal bruges af andre komponenter (Module 2 og Modul 3).
// Modul 1 (Konstanter)statisk klasse Konstanter{ public const decimal MaxLøn =100M; public const int MaxNumberOfProducts =100;} // Finance Module#using Module1static class FinanceHelper{ public static bool ApproveSalary(decimal salary) { return løn <=Constants.MaxSalary; }} // Marketing Module#using Module1class ProductManager{ public void MakeOrder() { int productsNumber =0; while(productsNumber++ <=Constants.MaxNumberOfProducts) {// Køb et produkt } }} Hvis monteringsprocessen af en eller anden grund tager meget tid, vil det være svært for udviklere at vente, indtil det er færdigt. Derudover skal det bemærkes, at konstantmodulet indeholder blandede enheder, der tilhører forskellige dele af forretningslogikken (finans- og marketingmoduler). Så konstantmodulet kan ændres ret ofte af årsager, der er uafhængige af hinanden, hvilket kan føre til yderligere problemer såsom synkronisering af ændringerne.
Alt dette bremser udviklingsprocessen og kan stresse programmører. Varianterne af det mindre tyktflydende design ville være enten at skabe separate konstantmoduler – af ét til det tilsvarende modul af forretningslogik – eller at sende konstanter til det rigtige sted uden at tage et separat modul til dem.
Et eksempel på miljøets viskositet kan være udvikling og test af applikationen på den virtuelle fjernklientmaskine. Nogle gange bliver denne arbejdsgang uudholdelig på grund af en langsom internetforbindelse, så udvikleren kan systematisk ignorere integrationstesten af den skrevne kode, hvilket i sidste ende kan føre til fejl på klientsiden, når denne funktion bruges.
Uødvendig kompleksitet
I dette tilfælde har designet faktisk ubrugt funktionalitet. Dette faktum kan komplicere support og vedligeholdelse af programmet, samt øge udviklings- og testtiden. Overvej for eksempel det program, der kræver at læse nogle data fra databasen. For at gøre dette blev DataManager-komponenten oprettet, som bruges i en anden komponent.
class DataManager{ object[] GetData() {// Hent og returner data }} Hvis udvikleren tilføjer en ny metode til DataManager til at skrive data ind i databasen (WriteData), som næppe vil blive brugt i fremtiden, så vil det også være en unødvendig kompleksitet.
Et andet eksempel er en grænseflade til alle formål. For eksempel vil vi overveje en grænseflade med den enkelte procesmetode, der accepterer et objekt af strengtypen.
interface IProcessor{ void Process(string message);} Hvis opgaven var at behandle en bestemt type meddelelse med en veldefineret struktur, så ville det være lettere at skabe en strengt skrevet grænseflade i stedet for at få udviklere til at deserialisere denne streng til en bestemt meddelelsestype hver gang.
At overbruge designmønstre i tilfælde, hvor dette slet ikke er nødvendigt, kan også føre til viskositetsdesign.
Hvorfor spilde din tid på at skrive en potentielt ubrugt kode? Nogle gange skal QA teste denne kode, fordi den faktisk er udgivet og er åben til brug af tredjepartsklienter. Dette udsætter også udgivelsestiden. At inkludere en funktion for fremtiden er kun værd, hvis dens mulige fordel overstiger omkostningerne til dens udvikling og test.
Unødvendig gentagelse
Måske har de fleste udviklere stødt på eller vil støde på denne funktion, som består i flere kopiering af den samme logik eller koden. Den største trussel er sårbarheden af denne kode, mens du ændrer den - ved at rette noget ét sted kan du glemme at gøre dette et andet sted. Derudover tager det længere tid at foretage ændringer i forhold til situationen, hvor koden ikke indeholder denne funktion.
Unødvendig gentagelse kan skyldes uagtsomhed fra udviklere, såvel som på grund af designs stivhed/skrøbelighed, når det er meget vanskeligere og mere risikabelt ikke at gentage koden i stedet for at gøre dette. Men under alle omstændigheder er repeterbarhed ikke en god idé, og det er nødvendigt konstant at forbedre koden ved at videregive genbrugelige dele til almindelige metoder og klasser.
Dårlig læsbarhed
Du kan overvåge denne funktion, når det er svært at læse en kode og forstå, hvad den er skabt til. Årsagerne til dårlig læsbarhed kan være manglende overholdelse af kravene til kodeudførelsen (syntaks, variabler, klasser), en kompliceret implementeringslogik osv.
Nedenfor kan du finde eksemplet med den svære at læse kode, som implementerer metoden med den boolske variabel.
void Process_true_false(string trueorfalsevalue){ if (trueorfalsevalue.ToString().Length ==4) { // Det betyder, at trueorfalsevalue sandsynligvis er "true". Gør noget her. } else if (trueorfalsevalue.ToString().Length ==5) { // Det betyder, at trueorfalsevalue sandsynligvis er "false". Gør noget her. } else { throw new Exception("ikke sandt af falsk. det er ikke rart. returner.") }} Her kan vi skitsere flere problemstillinger. For det første er navne på metoder og variabler ikke i overensstemmelse med almindeligt anerkendte konventioner. For det andet er implementeringen af metoden ikke den bedste.
Måske er det værd at tage en boolsk værdi i stedet for en streng. Det er dog bedre at konvertere den til en boolsk værdi i begyndelsen af metoden i stedet for at bruge metoden til at bestemme længden af strengen.
For det tredje svarer teksten til undtagelsen ikke til den officielle stil. Når man læser sådanne tekster, kan der være en fornemmelse af, at koden er skabt af en amatør (der kan stadig være et problem). Metoden kan omskrives som følger, hvis den tager en boolsk værdi:
public void Process(bool value){ if (value) {// Gør noget. } andet {// Gør noget. }} Her er endnu et eksempel på refactoring, hvis du stadig skal tage en streng:
public void Process(string value){ bool bValue =false; if (!bool.TryParse(value, out bValue)) { throw new ArgumentException($"The {value} is not boolean"); } if (bVærdi) { // Gør noget. } andet {// Gør noget. }} Det anbefales at udføre refactoring med den svære at læse kode, for eksempel når dens vedligeholdelse og kloning fører til flere fejl.
Skørhed
Et programs skrøbelighed betyder, at det nemt kan gå ned, når det ændres. Der er to typer nedbrud:kompileringsfejl og runtime-fejl. De første kan være en bagside af stivhed. Sidstnævnte er de farligste, da de forekommer på klientsiden. Så de er en indikator for skrøbeligheden.
Ingen tvivl om, at indikatoren er relativ. Nogen retter koden meget omhyggeligt, og muligheden for dens nedbrud er ret lav, mens andre gør dette i en fart og skødesløst. Alligevel kan en anden kode med de samme brugere forårsage en anden mængde fejl. Sandsynligvis kan vi sige, at jo sværere det er at forstå koden og stole på programmets udførelsestid frem for kompileringsstadiet, jo mere skrøbelig er koden.
Derudover går den funktionalitet, der ikke skal ændres, ofte ned. Det kan lide under den høje kobling af logikken af forskellige komponenter.
Overvej det særlige eksempel. Her er logikken for brugerautorisation med en bestemt rolle (defineret som den rullede parameter) til at få adgang til en bestemt ressource (defineret som resourceUri) placeret i den statiske metode.
static void Main(){ if (Helper.Authorize(1, "/pictures")) { Console.WriteLine("Autoriseret"); }}class Helper{ public static bool Authorize(int roleId, string resourceUri) { if (roleId ==1 || roleId ==10) { if (resourceUri =="/pictures") { return true; } } if (rolleId ==1 || rolleId ==2 &&ressourceUri =="/admin") { return true; } returner falsk; }} Som du kan se, er logikken kompliceret. Det er indlysende, at tilføjelse af nye roller og ressourcer nemt vil bryde det. Som følge heraf kan en bestemt rolle få eller miste adgang til en ressource. Oprettelse af ressourceklassen, der internt gemmer ressource-id'et og listen over understøttede roller, som vist nedenfor, ville reducere skrøbeligheden.
static void Main(){ var picturesResource =new Resource() { Uri ="/pictures" }; picturesResource.AddRole(1); if (picturesResource.IsAvailable(1)) { Console.WriteLine("Autoriseret"); }}klasseressource{ privat liste _roles =ny liste(); offentlig streng Uri { få; sæt; } public void AddRole(int roleId) { _roles.Add(roleId); } public void RemoveRole(int roleId) { _roles.Remove(roleId); } public bool IsAvailable(int roleId) { return _roles.Contains(roleId); }} I dette tilfælde, for at tilføje nye ressourcer og roller, er det slet ikke nødvendigt at ændre autorisationslogikkoden, det vil sige, at der faktisk ikke er noget at bryde.
Hvad kan hjælpe med at fange runtime-fejl? Svaret er manuel, automatisk og enhedstest. Jo bedre testprocessen er organiseret, jo mere sandsynligt er det, at den skrøbelige kode vil forekomme på klientsiden.
Ofte er skrøbelighed en bagside af andre identifikatorer af dårligt design, såsom stivhed, dårlig læsbarhed og unødvendige gentagelser.
Konklusion
Vi har forsøgt at skitsere og beskrive de vigtigste identifikatorer for dårligt design. Nogle af dem er indbyrdes afhængige. Du skal forstå, at spørgsmålet om designet ikke altid uundgåeligt fører til vanskeligheder. Det peger kun på, at de kan forekomme. Jo mindre disse identifikatorer overvåges, jo lavere er denne sandsynlighed.