Nu er vores big data analytics-fællesskab begyndt at bruge Apache Spark i fuld gang til big data-behandling. Behandlingen kunne for ad hoc-forespørgsler, forudbyggede forespørgsler, grafbehandling, maskinlæring og endda til datastreaming.
Derfor er forståelsen af Spark Job Submission meget afgørende for fællesskabet. Forlængelse til at dele med dig erfaringerne fra de trin, der er involveret i Apache Spark Job Submission.
Grundlæggende har den to trin,

Jobafsendelse
Spark-job indsendes automatisk, når en handling som count () udføres på en RDD.
Internt runJob() for at blive kaldt på SparkContext og derefter kalde på til skemalæggeren, der kører som en del af aflederen.
Planlæggeren består af 2 dele – DAG Scheduler og Task Scheduler.
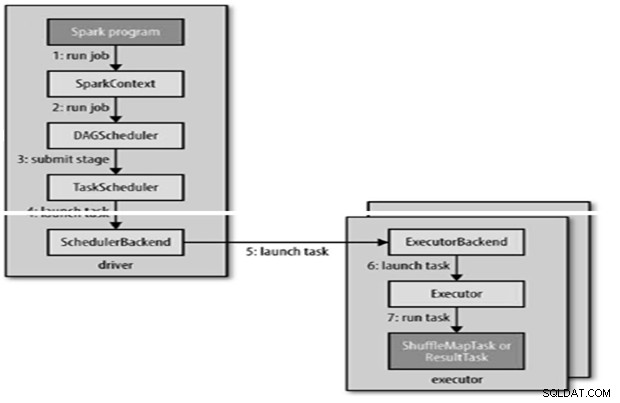
DAG Construction
Der er to typer DAG-konstruktioner,

- Simple Spark-job er et job, der ikke behøver en shuffle, og derfor kun har et enkelt trin, der består af resultatopgaver, f.eks. job, der kun er kort i MapReduce
- Kompleks Spark-job involverer grupperingsoperationer og kræver et eller flere blandetrin.
- Sparks DAG-planlægger gør jobbet til to trin.
- DAG-planlæggeren er ansvarlig for at opdele et trin i opgaver til indsendelse til opgaveplanlæggeren.
- Hver opgave får en placeringspræference af DAG-planlæggeren for at give opgaveplanlæggeren mulighed for at drage fordel af datalokalitet.
- Børnestadier indsendes først, når deres forældre har fuldført.
Opgaveplanlægning
- Opgaveplanlæggeren sender et sæt opgaver; den bruger sin liste over eksekvere, der kører for applikationen og konstruerer en kortlægning af opgaver til eksekvere, der tager placeringspræferencer i betragtning.
- Opgaveplanlæggeren tildeler til udførere, der har frie kerner, hver opgave tildeles en kerne som standard. Det kan ændres med parameteren spark.task.cpus.
- Spark bruger Akka, som er aktørbaseret platform til at bygge meget skalerbare begivenhedsdrevne distribuerede applikationer.
- Spark bruger ikke Hadoop RPC til fjernopkald.
Opgaveudførelse
En eksekutør kører en opgave som følger,
- Det sikrer, at JAR- og filafhængighederne for opgaven er opdaterede.
- Afserialiserer opgavekoden.
- Opgavekoden udføres.
- Opgaven returnerer resultater til chaufføren, som samles til et endeligt resultat for at returnere til brugeren.
Reference
- The Hadoop Definitive Guide
- Analytics &Big Data Open Source-fællesskab
Denne artikel blev oprindeligt vist her. Genudgivet med tilladelse. Indsend dine ophavsretsklager her.